 夜雨聆风
夜雨聆风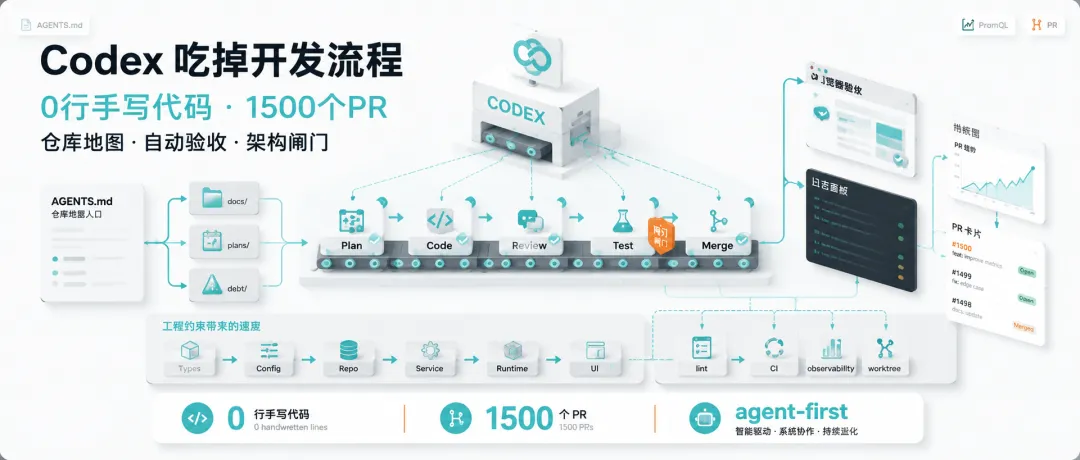
过去两天,HN 上最值得开发者认真看的 AI 热文,不是某个模型榜单,也不是“程序员会不会失业”的老问题,而是 OpenAI 公开的一篇工程复盘:他们用 Codex 做了一个内部产品,约束非常狠。
0 行人工手写代码。
五个月左右,仓库膨胀到百万行量级,约 1500 个 PR 被打开并合并。最早只有 3 个工程师驱动 Codex,平均每个工程师每天推进 3.5 个 PR;后来团队扩到 7 人,吞吐还在继续增长。
这篇文章真正有价值的地方,不是炫耀“AI 写代码多快”,而是把一个现实问题摊开了:当 Agent 真的能持续写代码,工程师的工作会从“自己下场写”变成“搭环境、写规则、建反馈回路、清理熵增”。
说白了,Codex 不是替你省掉工程能力。它会逼你把工程能力写进仓库。
别再把 Agent 当聊天框了:OpenAI 这次玩的是“开发系统”
很多团队用 AI 编程,还停在这个姿势:
小需求能跑,大项目很快露馅。Agent 找不到入口,测试跑不起来,日志看不懂,UI 没法验证,文档又长又旧。最后人类一边抱怨 AI 不靠谱,一边继续复制粘贴上下文。
OpenAI 这次做法完全不同。
他们不是让 Codex 在一个混乱仓库里“更努力”,而是反过来改造仓库,让 Codex 能稳定工作。文章里有一句判断很关键:人类掌舵,Agent 执行。
这里的“掌舵”不是写几句 Prompt,而是设计一套让 Agent 能看懂、能验证、能循环修正的工程环境。
这就是 Harness Engineering 的核心:别只训练模型,先把模型运行的“赛道”铺好。
第一刀砍向 AGENTS.md:它不该是百科全书
很多人会把 AGENTS.md 写成一个巨型说明书,恨不得把技术栈、目录规范、业务规则、历史决策、常见坑全部塞进去。
这看起来勤奋,实际很危险。
OpenAI 的经验很直接:上下文是稀缺资源。一个巨大的指令文件会挤掉真正的任务、代码和相关文档。更麻烦的是,当所有规则都被写成“重要”,Agent 反而分不清优先级。
他们最后采用的方式是:
也就是说,AGENTS.md 不是百科全书,而是目录页。
一个可落地的结构可以这样做:
这里别追求一口气写完。真正有用的是“渐进披露”:Agent 先读短入口,再沿着链接找到更深的规则。
让应用对 Agent 可读:UI、日志、指标都必须能被它直接碰到
OpenAI 复盘里最有实操价值的一点,是他们把 QA 能力也塞给了 Codex。
他们让应用可以按 git worktree 独立启动。这样每个改动都有自己的隔离实例,Agent 不会把一个任务的环境污染到另一个任务。
然后他们接入 Chrome DevTools Protocol,并写了处理 DOM 快照、截图、导航的技能。这样 Codex 不只是“改完代码”,还能自己打开页面、复现 Bug、验证修复。
观测体系也一样。每个 worktree 都有临时的本地 observability stack,任务结束就销毁。Codex 可以用 LogQL 查日志,用 PromQL 查指标。于是下面这种验收条件就变得可执行:
这才是真正的 Agent 验收。
不是让模型“相信自己改好了”,而是让它能看到运行结果。
如果你的团队现在还在让 Agent “猜页面应该长什么样”,优先补这一层,比继续调 Prompt 更有用。
架构不能靠口头品味:边界要写成 Lint 和结构测试
OpenAI 的另一个结论很硬:文档本身守不住架构。
Agent 生成代码的速度越快,架构漂移也越快。只靠 review 说“这里不符合团队风格”,最后会把人拖死。
他们的做法是把关键边界写成机械规则。比如业务域内部只能按固定层级依赖:
跨域能力,比如 auth、connectors、telemetry、feature flags,必须通过明确的 Providers 进入。其他依赖方向直接禁止。
这类规则适合写成:
关键点在最后一行:lint 报错信息要写给 Agent 看。
不要只报:
更有用的是:
这不是吹毛求疵。Agent 看到可执行的修复路径,下一轮就能自己改回来。
PR 吞吐上来后,合并策略也要变:别用低吞吐时代的门禁卡死自己
这点容易有争议。
OpenAI 的仓库采用的是相对少的阻塞式合并门禁。PR 生命周期很短,测试偶发问题经常用后续 Agent run 修复,而不是无限阻塞当前进度。
这不适合所有团队直接照搬。金融核心链路、医疗、支付、基础设施变更,不能因为“Agent 修得快”就放松验证。
但它提醒了一个事实:当 Agent 生成、修复、补测的速度远高于人类注意力时,流程瓶颈会迁移。
你要重新区分哪些门禁必须阻塞,哪些问题可以异步回收。
别把所有问题都做成红灯。红灯太多,团队最后会无视红灯。
真正要抄的是这 7 个动作,不是“0 行手写代码”
如果你的团队想试 Harness Engineering,我不建议一上来立下“从今天开始不准手写代码”这种规矩。
那很容易变成表演。
更现实的路线是先做 7 件事:
AGENTS.md 缩成导航页,控制在 100 到 200 行。docs/architecture,写清楚模块边界、依赖方向和例外规则。plans/active/*.md,把进度、决策、风险放进仓库。最小起步可以是这样:
然后把 AGENTS.md 改成这种形态:
这比塞 2000 行规则有效。
最容易被忽略的成本:Agent 也会制造熵增,必须有“垃圾回收”
OpenAI 文章里有个细节很真实:他们早期每周五要花 20% 时间清理所谓的 AI slop。
这件事一点不意外。
Agent 会复制仓库里已有模式,好的坏的都会复制。一个临时 helper、一个绕过类型的写法、一个含糊的文档,只要出现一次,后续就可能扩散。
他们后来做的是把“黄金原则”写进仓库,再安排后台 Codex 任务定期扫描偏离,开小 PR 修复。大多数清理 PR 可以一分钟内完成 review,甚至自动合并。
你可以从这几个清理任务开始:
这一步不是锦上添花。Agent 规模化以后,熵增速度会比以前快很多。
我的判断:以后拼的不是谁会用 AI,而是谁的仓库更适合 AI 干活
这篇 OpenAI 复盘的重点,不是“程序员不用写代码了”。
更准确的说法是:当代码生成成本下降,工程系统的质量会被放大。
仓库结构混乱,Agent 会混乱得更快。文档过期,Agent 会把过期信息执行得更勤快。没有测试和观测,Agent 会更自信地把错误合进去。
反过来,如果你的仓库边界清楚、启动简单、日志可查、UI 可验、规则可机械执行,Agent 的能力就会被放大。
真正的分水岭不在 Prompt。
在仓库本身。
参考来源:
