 夜雨聆风
夜雨聆风前几年大家最兴奋的,是模型突然会写代码、会画图、会回答专业问题。
先跑起来再说,先做出效果再说,边界和流程可以以后再补。
但今天的新消息,味道变了。
GitHub 的 Spec Kit 把 AI 编码拉回先写规范、再做计划、再拆任务的老路。OpenCV 5 重写 DNN 引擎,把 Transformer、视觉语言模型和大语言模型装进一套用了很多年的计算机视觉工具链。Hugging Face 上的 Job Searcher 没有追求一个无所不能的大模型,而是用教师模型、LoRA 微调和清晰评分标准,专门做好职位匹配。
另一边,Anthropic 在测试 Claude 能不能读懂化学家的 NMR 谱图时,特意选择训练截止日期之后发布的化合物,避免模型靠记忆蒙混过关。
甚至连今天的一个奖项都在提醒大家同一件事。
ResNet 获得 CVPR 2026 时间检验奖。
不是刚发布时的热搜,不是演示视频里的惊艳,而是十年之后,大家再看它到底留下了什么。
我觉得今天真正该盯的,不是哪一个模型又多会了一项能力。
而是 AI 开始从野蛮生长,走进一套更严肃的秩序里。
先把需求说清楚,先把专业工具接好,先把评价标准定下来,然后再谈它能不能真的干活。
热闹还在继续。
但决定 AI 能不能留下来的,开始不是热闹了。
01|AI 写代码,先被 GitHub 按回了需求文档
GitHub 的 Spec Kit 正在推动一种规范驱动的 AI 开发方式。
它的流程很朴素,先定义产品要做什么,再澄清缺口,制定技术计划,拆成任务,最后才让智能体执行。
你没看错。
AI 编程绕了一大圈,又回到了先把需求写明白。
过去一段时间,大家很容易被一种爽感带着走。打开编辑器,扔进去一句需求,看着智能体连续创建文件、安装依赖、跑起页面,几分钟就有东西能点。
这种体验当然很爽。
问题是,代码生成得越快,错误方向造成的返工也越快。
需求里少一个边界条件,模型不会停下来替你召开需求评审。权限规则没有说清楚,它也可能先做出一条看起来能跑的主流程。等产品真的接上数据、用户和钱,前面省下来的十分钟,后面可能变成几天的修补。
Spec Kit 做的事,就是在智能体动手之前,先放一道闸门。
规范不再只是写给人看的文档,而是给 AI 读取的执行合同。它支持 Copilot、Claude Code、Codex、Gemini、Cursor、Qwen 等三十多种智能体集成,项目也已经获得超过十万 GitHub 星标。
这套方法还有一个很现实的好处。
人和智能体终于能围绕同一份东西讨论。产品改了什么,技术方案为什么调整,任务有没有漏掉,验收到底看什么,不再散落在十几轮聊天记录里。
模型可以换,编辑器也可以换,但项目对问题的理解不会跟着聊天窗口一起消失。
这组数字很有意思。
开发者不是不想让 AI 写代码,恰恰相反,大家想让它写得更多。
所以才更需要先把什么能写、写到哪里、怎样算完成说清楚。
以前规范常被嫌慢,现在生成速度太快,规范反而成了控制成本最低的东西。
今天第一层变化就在这里。
AI 编码真正成熟的标志,不是它一口气写出多少文件,而是它在动手之前,愿不愿意先尊重问题本身。

02|小模型开始被训练成专科生,而不是假装全都会
用户上传简历,设定职位类型、地点和工作方式等偏好,系统会生成搜索查询,抓取职位,再从技能匹配、经验相关性、教育背景、行业契合度和资历对齐五个维度打分。
最后给你的不是一大片岗位链接,而是一份带理由的候选清单。
真正有价值的地方,不只是它能帮人找工作。
而是它没有把所有任务都压给一个昂贵的大模型。
项目先用 DeepSeek V4 Pro 作为教师模型生成训练数据,再对 Qwen3-8B 做 LoRA 微调。训练在 Modal 的一张 A100 上完成,推理则部署到 Hugging Face ZeroGPU Space,并用 llama.cpp 输出流式结果。
大模型负责教,小模型负责长期干活。
场景先被拆清楚,评分标准先被定清楚,然后模型只学这一件事。
这跟过去那种把简历和职位描述一起扔进聊天框,问一句合不合适,完全不是同一种产品思路。
聊天框给你的可能是一段听起来很合理的话。
Job Searcher 更像一条小型生产线。搜索从哪里来,岗位按什么维度判断,结果怎样排序,推理部署在哪里,每一环都被固定下来。
这种结构还有个好处。
某一环出问题时,开发者知道该去改搜索、评分、训练数据还是部署,而不是重新向一个大模型祈祷。
一个产品能被拆开检查,才有机会被持续修好。
说真的,很多 AI 产品最后拼的并不是谁接入了最贵的模型。
拼的是谁愿意把一个模糊需求,拆成可训练、可检查、可重复的步骤。
这也是今天第二层变化。
通用模型负责提供能力,真正落地的产品负责给能力装上专业习惯。
模型不需要在每个问题上都像天才。
它只需要在用户真正要完成的那件事上,稳定地像个熟练工。

03|进入专业现场之后,演示得像不算数
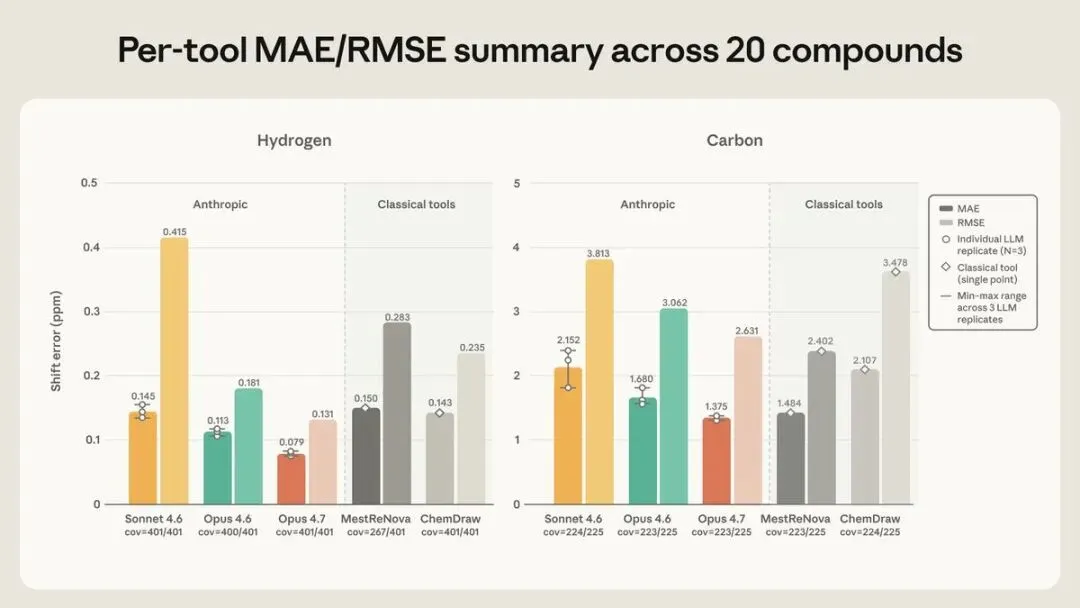
Anthropic 正在和化学家合作,测试 Claude 处理 NMR 谱图的能力。
NMR 是化学家判断分子结构时常用的分析输入。研究里既测试从分子结构预测谱图,也测试反过来从实验谱图推断结构,并把 Claude Opus 4.7、Opus 4.6、Sonnet 4.6 与 ChemDraw、MestReNova 这些专业软件放在一起比较。
但我更在意一个小细节。
测试使用的二十个化合物,来自模型训练截止日期之后发布的 ChemRxiv 预印本。
原因很直接。
不能让模型靠见过答案,假装自己会做题。
这就是专业现场和产品演示最大的区别。
而且这里没有一个简单的总分能替代全部判断。
正向预测和反向解析是两类任务,不同模型和专业软件也各有适用范围。把它们分开测,才不会用一项漂亮结果遮住另一项短板。
演示只要挑一个效果最好的例子,观众会惊叹就够了。专业工作不行,样本怎么选、对照是谁、任务边界在哪里,都要经得住追问。
化学里的错误,也不是多改一版文案那么轻。
分子结构的判断差一点,后面的实验方向就可能完全不同。人在这里不会因为模型说话很流畅,就把专业判断交出去。
所以 AI 进入化学、医疗、法律、金融这些领域时,能力只是门票。
真正的门槛是证据。
你得证明它面对没见过的材料还能工作,证明它跟现有专业工具比较时到底强在哪里,也得把不能做的部分留给专业人员。
今天第三层变化,是大家开始更认真地区分会说和会做。
模型能讲出一段专业术语,已经不稀奇了。
能在新的、可核验的专业样本上交出结果,才有资格进入现场。
04|最后留下来的,往往不是最会制造惊叹的东西
OpenCV 5 正式发布。
这次它采用新的基于图的 DNN 引擎,ONNX 算子覆盖率从 4.x 版本不到百分之二十三,提高到超过百分之八十,并原生支持 Transformer、视觉语言模型和大语言模型。
OpenCV 不是新面孔。
它的 GitHub 星标超过八万六千,每日安装量超过一百万次。很多人第一次写计算机视觉程序时,就用过它读图片、处理摄像头、做检测和变换。
现在,大模型没有把这套老工具链扫进历史。
反而要进入它。
因为真实系统不可能只有模型。摄像头怎样接入,图像怎样处理,算子怎样兼容,硬件怎样加速,Python 接口怎样使用,这些不够性感的细节,决定了模型最终能不能被装进产品。
另一条消息更有时间感。
阶跃星辰首席科学家张祥雨参与的 ResNet 论文,获得 CVPR 2026 时间检验奖。
一篇研究刚出来时,可以靠新鲜感引发关注。
十年后还能被整个行业持续使用,才说明它真的改写了后来者的路径。
我很喜欢时间检验奖这个名字。
AI 圈每天都有新模型、新榜单和新纪录,速度快到人很容易把发布当成完成。
但发布只是开始。
能被工具链接住,能被开发者反复调用,能在十年后仍然解释行业为什么走到这里,才是另一种更难的成功。
所以今天最后一层变化,是 AI 开始重新尊重那些慢东西。
规范、专业知识、工程兼容、可核验测试,还有时间。
它们不会在演示视频里抢镜。
但它们决定一项技术能不能从热点,变成基础设施。

所以回到今天这批热点,我更愿意把它们看成一个阶段变化。
AI 没有变慢。
只是所有人终于开始认真处理速度带来的后果。
代码写得太快,就先把规范立起来。模型太通用,就把任务拆细,把小模型训练成专科生。专业能力太容易被演示包装,就用新样本、老工具和清楚的对照去检验。新模型太多,就让工具链和时间决定谁真正留下。
这不是给 AI 踩刹车。
这是给它铺路。
野蛮生长能制造奇迹,但只有规则、证据和工程,能把奇迹变成日常。
今天最值得记住的,不是 AI 又学会了多少新动作。
而是它开始被要求,为自己的每一个动作负责。
当 AI 从炫技走向守规矩,你觉得最先被重写的会是软件开发、求职服务,还是专业研究?
🔥 今日话题|你现在用 AI 做事时,最缺的是更强的模型,还是更清楚的流程和评价标准?
👇 点个「在看」,转给那个已经开始让 AI 干活,却还没给它立规矩的人。
