 夜雨聆风
夜雨聆风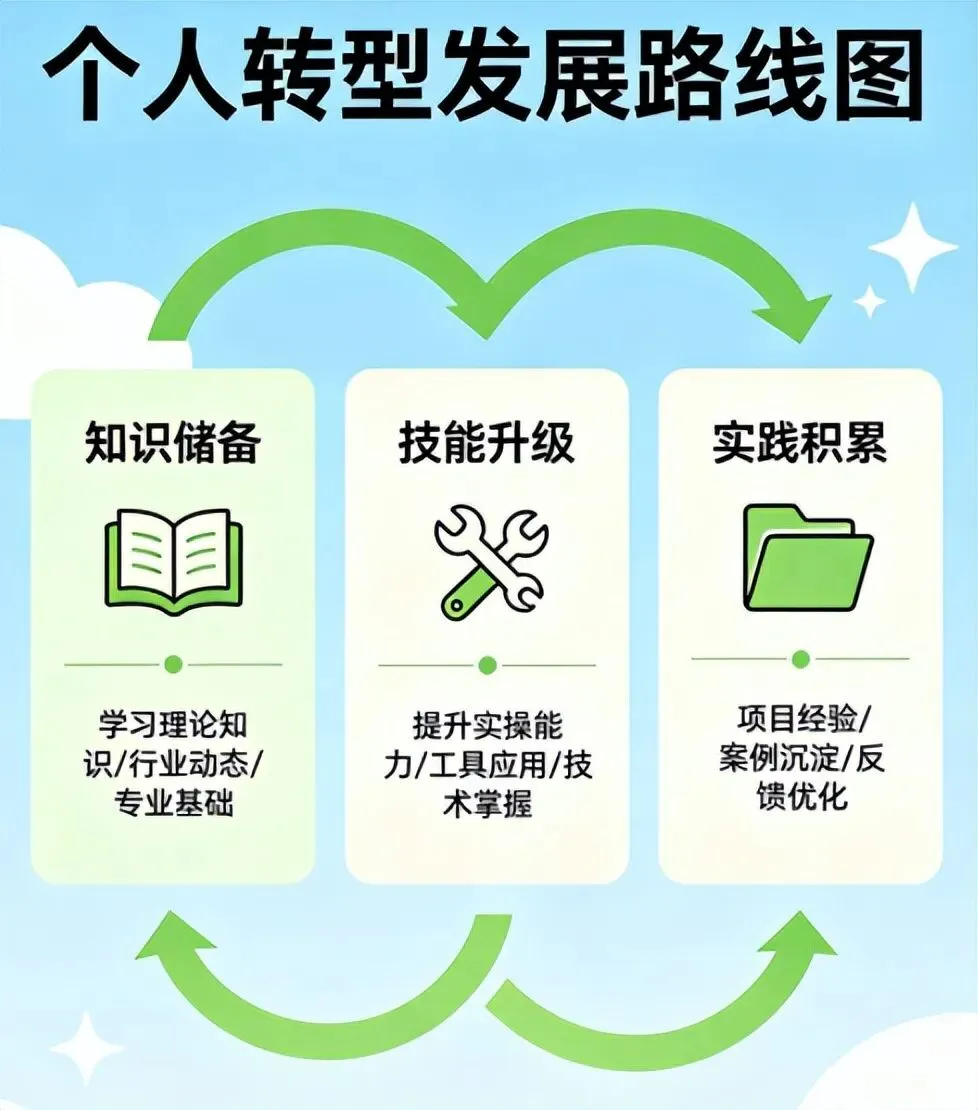
去年这时候,我还在为ERP系统的上线日夜赶工;现在,我已经带队跑完了三个AI落地项目。转变不是一蹴而就,但也没有想象中那么可怕。今天我把自己的踩坑经验和复盘笔记分享出来,希望能给你一些实在的参考。
一、先搞清“游戏规则”:传统项目和AI项目到底哪里不同?
刚开始接触AI项目时,我最大的困惑是:为什么需求总在变?为什么没有明确的上线标准?后来我才明白,传统项目像“盖房子”——图纸画好了,按图施工就行;AI项目更像“搞科研”——你得先假设、再实验、根据结果调整方向。
我用自己的话总结了一下核心差异:
对比项 | 传统项目 | AI项目 |
需求 | 客户基本知道要什么 | 客户只描述“感觉”,答案要一起找 |
成败标准 | 按时、按预算、按规格交付 | 模型准确率、业务提升、能不能解释得通 |
开发方法 | 瀑布、敏捷(有固定迭代节奏) | 高度实验性:假设→实验→分析→再假设 |
主要风险 | 范围蔓延、人员流失、技术债 | 数据脏乱差、模型偏见、上线后效果衰减 |
团队里都有谁 | 开发、测试、运维 | 数据科学家、ML工程师、业务专家(甚至律师) |
交付物 | 确定能跑的系统 | 概率输出的模型,需要持续喂养和监控 |
理解这六点差异,是转型的第一块基石。
二、我的转型三步走:知识→技能→实战
第一步:补课,但不是成为算法专家(3个月)
我给自己定的原则:不写模型代码,但要懂每一块“积木”是什么、怎么搭。学习资源我选了最“干”的:
- 免费但硬核
吴恩达《机器学习》课程(只看前四章就够PM用了) - 国内认证
中国人工智能学会的《AI项目经理认证培训》(偏实战,有案例拆解) - 每日15分钟
刷一遍“算法地图”小卡片(监督/无监督/强化学习、过拟合、A/B测试)
最重要的是理解AI项目全生命周期:业务问题定义 → 数据采集/清洗 → 特征工程 → 模型训练/调参 → 部署 → 监控/再训练每个环节的输入输出和卡点,我做成了一张A4纸贴在工位旁。
第二步:技能“换芯”,而不是重装(持续)
通用PM能力——风险、沟通、干系人管理——是金子,别扔掉。我做的只是给它们加了“AI滤镜”:
- 风险管理
原来担心“服务器宕机”,现在要加“训练数据泄露”“模型歧视”“概念漂移” - 进度管理
不再死磕“每个任务必须完成”,而是设置“实验探索期”和“收敛期” - 沟通
学会在业务方(要效果)和数据科学家(要算力/数据)之间当“翻译官”
推荐一个小工具:实验日志模板(见文末福利)。每次实验前写“假设→数据→参数→预期结果”,实验后记录“实际结果→偏差分析→下一步”。这能让你对项目进程保持掌控感。
第三步:从边角料项目做起(6个月)
不要一上来就抢核心AI项目。我主动申请负责一个“废弃需求”:用已有客服聊天记录做自动分类。数据量小,模型简单,但完整走了一遍流程。关键动作:
找公司的ML负责人当导师(每月请喝一次咖啡,带着具体问题去) 在Kaggle上组了个“虚拟项目队”,用公开房价数据集模拟两周迭代 每两周写一篇内部复盘,发在团队wiki上(后来被总监看到,给了真实项目)
三、AI项目经理的日常“三件套”
我现在每天的工作流是:
- 站会
问三个问题——昨天实验了什么结果?今天要验证什么假设?需要什么资源? - 审查实验日志
用MLflow看实验记录,用Weights & Biases对比不同参数的效果。 - 跨学科对焦
和业务方确认指标(比如“推荐点击率”还是“用户停留时长”更重要),和工程师确认数据管道稳定性。
工具不用多:
项目管理:Jira(我自定义了“实验-评估-转型”三种任务类型) 文档沉淀:Confluence(强制要求每次实验写“失败原因”,比成功结果更值钱) 沟通:钉钉建了“数据快反群”,算法、工程、业务都在里面@所有人
我还养成了一个习惯:给每个项目做一张“模型卡”——一页纸写明模型能做什么、不能做什么、什么情况下会出错、需要多少人肉监控。这既是对上汇报的利器,也是对自己的保护。
四、你的转型路线图:不是学AI,是重构角色
✅ 第一阶段:3–6个月,当个“翻译官”
不用会写代码,但要懂:特征工程 ≠ 数据清洗,是“把业务语言翻译成机器能听懂的话”F1值 ≠ 90%就OK,要看它在真实用户场景下是否误伤了老客户 必读:吴恩达《机器学习》第1–4章(只看概念,别做题) 认证:百度AI认证·项目经理方向(国内企业最认)
✅ 第二阶段:持续进行,练就“三双眼睛”
- 一双看数据
别信“准确率95%”,问:“这数据有没有去年双十一的样本?” - 一双看人
数据科学家说“这模型不行”,别急着催,问:“你试过哪些基线?失败的实验记录在哪?” - 一双看业务
把“模型性能”翻译成“每1%提升,能省多少客服人力?”
✅ 第三阶段:6–12个月,亲手带一个“小火苗”
不要等“公司给AI项目”,自己拉个5人小组:选一个小场景:比如“自动回复客户关于退货政策的咨询”用Kaggle公开数据集模拟写一份实验日志:假设→数据→参数→结果→洞察 找个AI团队的导师,每周喝一次咖啡,不谈技术,只问:“你最近一次被模型打脸,是什么时候?”
🛠️ 你的新工具箱:不是Jira,是实验操作系统
工具 | 用途 | 你该怎么做 |
MLflow | 记录每次实验的参数和结果 | 每次跑模型,都像写日记:“今天试了LR+TF-IDF,AUC=0.78,比上周差0.02,因为数据没去重” |
Jira(定制版) | 管理“实验任务”而非“功能开发” | |
模型卡 | 让AI透明化 | 每上线一个模型,必须附一张A4纸:“这个模型在哪些人群上表现差?为什么?” |
钉钉/Slack频道 | 建立“跨学科战地指挥部” | 命名:#AI-客服-转化-实验组,禁止说“你们数据不行”,要说“我们数据缺了什么?” |
五、加速转型的四个“捷径”(亲测有效)
- 认证不用多,但要认准
我考了AWS的“机器学习专业认证”(题库偏场景,PM友好)。国内可以考虑“华为云AI工程师”或“百度AI认证”,面试时有认知加成。 - 混对圈子
线上加入Datawhale(每周有案例拆解)、AI科技大本营(很多一手踩坑记录);线下一定要去一次世界人工智能大会(不是为了听论文,而是去交换名片,认识那些正在招AI PM的团队负责人)。 - 第一个项目选“高价值、低难度”
判断标准:业务方痛点明确、现有数据干净且充足、模型可以用现成算法(如逻辑回归/XGBoost)解决。避开“需要自研新模型”或“数据要从零采集”的项目。 - 学会说“不”
当业务方要求“准确率99%”时,告诉他:我们先用80%的模型上线,收集bad case,两周迭代一次。把不确定性变成迭代周期。
最后想对你说
技术领域的领导力,从来不是“我全懂”,而是搭一个能不断产出答案的框架,然后信任团队。你的项目管理经验就是最好的导航仪——它只是需要把地图从“确定性街道”切换到“概率性海域”。
转型路上,我最难熬的不是学不会概念,而是“习惯了一切有标准答案,却要拥抱模糊”。但当你第一次看到模型从垃圾数据里学出有用规律,那种成就感,比任何按时上线的项目都来得汹涌。
如果你正在经历数据质量崩盘、算法团队和业务方互怼、或者老板要求“下周就上线AI中台”——别慌,这些坑我全踩过。欢迎在评论区丢出你的具体挑战,我会挑三个最典型的,在下期文章里用我的真实案例拆解给你看。
