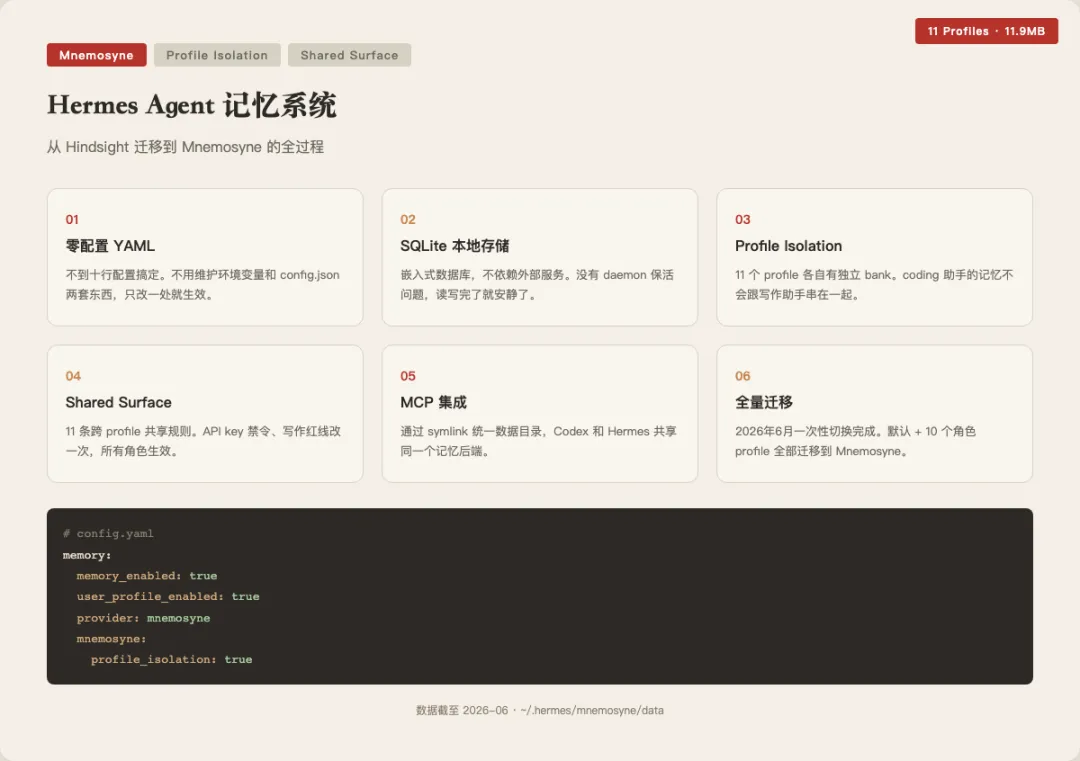
我给 10 个 AI 助手每人装了一套私人记忆系统:Hermes试试Mnemosyne记忆系统,和 Claude Code 、codex共享一套记忆你有没有过这种体验——跟 AI 助手聊了半天,下一次打开对话它什么都不记得了?这个问题我折腾了大半年。最夸张的时候同时维护着两份配置文件,漏改一处整个记忆系统就罢工。后来发现根源出在记忆系统本身。说的不是模型的上下文长度。模型上下文再长,关了对话就清空了。说的是「持久记忆」——AI 助手能跨对话记住你是谁、你的偏好、你项目的上下文、哪些事情绝对不能碰。市面上跑持久记忆的方案不少,踩了一圈坑之后,最后落脚在一个叫 Mnemosyne 的东西上。这篇文章就是把整个切换过程拆开给你看。最早用的方案叫 Hindsight,一个本地运行的记忆 daemon。想法挺好的——所有数据都存在本地,不联网,隐私有保障。但实际用起来,配置方式很折磨人。Hindsight 的配置散落在两处:一个在 hermes.env 环境变量,一个在 config.json 文件里。两处的配置必须保持同步,但没有任何机制帮你检查一致性。我经常改了 .env 忘了改 config.json——结果 daemon 启动正常,但记忆的读写全都走错了参数。排查这种问题你得同时盯着两个文件对照着看。更烦人的是 Hindsight 的 daemon 有个 idle_timeout 机制。一段时间没交互,它就自动退出了。下次你再跟助手说话时,记忆系统其实已经离线——但没有提示告诉你「我不在了」。你自以为助手记住了你的偏好,实际上它是一张白纸。这个状态持续了几个月。每次遇到问题我都在想:有没有一个方案,能只写一处配置,不用管 daemon 保活,拆箱就能用?Mnemosyne 是 Hermes Agent 生态里的一个记忆插件,跟 Hindsight 是同类产品,但设计理念完全不一样。首先,零配置。不用配环境变量,不用管 config.json。装好插件,在配置里把 provider 改成 mnemosyne,打开几个开关,就完了。配置块就长这样:memory: memory_enabled: true user_profile_enabled: true provider: mnemosyne mnemosyne: profile_isolation: true auto_sleep: true
其次,它用 SQLite 做后端——就是每个程序员都认识的那个嵌入式数据库。数据存本地,不依赖任何外部服务。你不需要运行一个 daemon,也不用担心它什么时候会挂。SQLite 就是存文件,读写完了就安静了。第三,它原生支持 profile isolation。这个概念后面展开说,简单讲就是:如果你有多个 AI 助手角色,每个人的记忆是分开的,不会串。今年 6 月我把全部助手切到了 Mnemosyne。包括默认角色在内的 11 个 profile,一次性迁移。切完后我验证了状态,命令很简单:输出很干净:provider: mnemosyne,profile_isolation: True,状态 available。没有 daemon 进程要查,没有心跳要配。~/.hermes/mnemosyne/data/mnemosyne.db 11.9MB(主数据库) ~/.hermes/mnemosyne/data/banks/ ← 每个 profile 一个 bank ~/.hermes/mnemosyne/data/shared/ ← 共享表面层
主数据库 11.9MB,不大不小。存了几个月跨对话的记忆,包括所有 profile 的长期数据。如果你只有一台助手,记忆问题很简单:存起来、读出来就行。但如果你有多个助手呢?你的主力调度助手、写代码的那个、做调研的那个、写作的那个——每个角色都有自己需要记住的东西。Mnemosyne 用了一个双层结构来解决这个问题。第一层,profile isolation。每个 profile 有自己独立的记忆 bank。你的 coding 助手不需要知道公众号的写作红线,你的写作助手也不需要知道项目代码的接口定义。各自记各自的事,互不干扰。第二层,shared surface。这是一个所有 profile 共享的记忆层,目前有 11 条记录。共享层放的是「全局规则」——所有助手都必须遵守的东西。比如 API key 禁令(任何场景不得输出密钥)、写作红线(禁用词列表、感叹号禁令)、文件输出规范。这些规则如果放到每个 profile 单独维护,改一次就得同步 11 遍,太容易漏了。放到 shared surface 里,改一次所有 profile 都生效。目前有 10 个 profile 各自有独立 bank:auditor、coder、commander、designer、engineer、light、operator、project_manager、researcher、writer,加上默认的 hermes 一共 11 个。各自管各自的,在共享层保持一致。结构上更巧妙的是,Mnemosyne 的数据目录通过一个 symlink 统一到了一处:~/.hermes/mnemosyne/data → /Users/xxx/Documents/Codex/mnemosyne-data
你的主力调度和编码助手共享同一个记忆后端。它们看到的是同一套 profile bank 和 shared surface。跨助手的记忆查询通过 MCP 服务实现,两端都连同一个数据源,不需要手动同步。就是一个 SQLite 文件,多个消费者。切到 Mnemosyne 之后,我最明显的感觉就是「不用管了」。之前隔三差五要去检查 Hindsight 的 daemon 还在不在,两个配置有没有漂移。现在完全不用操这个心——配置改一次就行,数据库文件不想理它也可以不理它。profile isolation 的好处是立竿见影的。有一次写作助手需要查一条 API 调用的历史记录,它去自己的 bank 里没找到。但如果 isolation 没开,它可能会翻到 coding 助手的记忆,看到一个完全不同的上下文,然后混淆。现在各自的书架是分开的,查不到就是查不到,反而清晰——它知道该去哪个文件找,而不是在一堆杂物里乱翻。共享层这个东西比较隐蔽,不容易直接感知。它的作用更像一条底线:你不需要告诉每个助手「别把 API key 泄露出去」,因为它从共享层已经知道了。启用新助手的 onboarding 成本几乎降到了零。唯一要注意的是 sharedsurfaceread 的开关默认是关的——你的 profile 可以共享东西出去,但默认不会读到其他 profile 写进来的共享内容。这个设计很合理:共享是显式的,不是自动的。我的建议是:如果你只有一个助手、用量不大,用什么记忆系统差别不大。但如果你跟我一样,有多个角色在跑、每天几十上百次对话、助手之间偶尔需要共享知识,Mnemosyne 值得一试。零配置、SQLite 后端、profile isolation、shared surface——这四个特性刚好踩在我之前踩过的每一个坑上。从双配置地狱到只需要一个 YAML 块,这个变化虽然不性感,但每天用下来确实省事。回到开头那个问题:你跟 AI 助手聊了半天,下一次对话它还记得吗?现在可以回答了。开个新对话,它记得你是谁、你喜欢什么、你的写作风格、哪些话不能说。11.9MB 的数据,换来了一个不会「金鱼记忆」的助手军团。如果你也在折腾 AI 助手的记忆配置,欢迎在评论区聊聊你的方案——这个领域还远没到「标准答案」出现的时候。如果这篇文章对你有帮助,可以点个「在看」让更多人看到。也欢迎在评论区聊聊你用的记忆方案,或者踩过什么坑——
 夜雨聆风
夜雨聆风