 夜雨聆风
夜雨聆风过去评估一家企业风险,需登录工商、司法、舆情、关联方四个平台,复制粘贴六次,耗时15~30分钟。今天输入一个企业名称,剩下的交给 AI Agent。
这是效率的跃迁,更是数据服务逻辑的根本重塑。但为什么传统模式走到今天非变不可?答案藏在企业数据消费的三个阶段里。
一、数据服务的「三阶段进化」
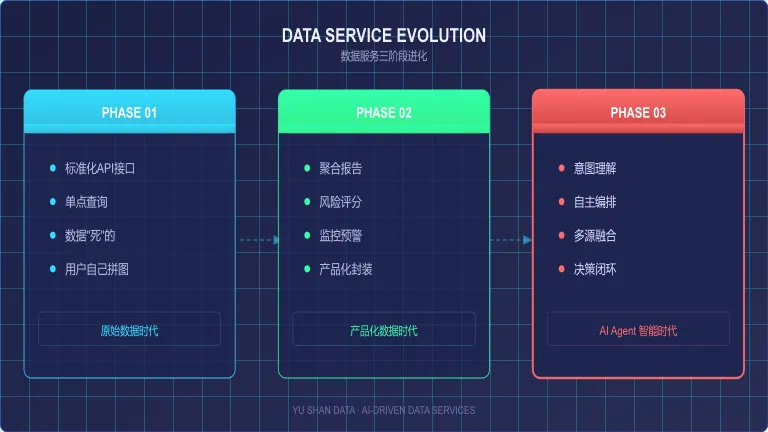
1.0 原始数据时代
标准化API接口,数据是「死」的,查询是「点状」的。一次完整风控评估需调用6~8个API、跨4~5个平台,数据准备工作占流程70%以上。这个阶段的瓶颈不在于数据量不够,而在于「查得到不等于用得上」——企业拥有多个数据源,却需要大量人力做搬运和格式转换。
2.0 产品化数据时代
聚合报告、风险评分等产品出现,试图将原始数据加工为可直接消费的成果。但产品固定、需求多变,不同行业甚至同一企业不同部门的风控粒度要求各异——销售部门关心关联交易,合规部门关注行政处罚,财务部门聚焦债务结构。定制化的边际收益递减,据Gartner统计,企业仍有63%的时间花在数据准备而非分析决策上。这说明:数据产品的「塑形」成本始终存在,只是从甲方转移到了乙方。
3.0 AI Agent 智能时代
数据从「被查询」变为由 Agent 自主编排的动态资源。感知(LLM理解意图)→ 编排(Agent调度多源)→ 分析(融合推理)→ 行动(触发后续流程)。这背后的核心变化是:数据的消费方式从「人找数据」变成了「数据找人」。Agent 不再是一套固定的流程引擎,而是根据每一次查询的上下文,动态决定调哪些接口、做什么推理、输出什么格式的结果。
一次典型的风控请求,Agent 可能在毫秒级完成以下推演:用户的真实意图是什么?需要哪几类数据才能形成判断?这些数据之间是否存在矛盾?需要追加哪些交叉验证?——这个「思考—行动—验证」的闭环,正是传统API接口时代无法实现的能力。
二、AI Agent 如何重构数据服务链路
传统方式:查工商→ 切司法 → 关联方 → 搜舆情 → 汇总Excel → 人工判断 → 录入CRM。15~30分钟,跨4~5个系统。每一步都是一次人工上下文切换——从一个系统的查询结果里提取关键字段,再粘贴到另一个系统的搜索框,大脑需要持续在不同维度的数据间做"翻译"。
Agent方式:输入「评估供应商A的准入风险」→ Agent自动拆解任务 → 并行调用工商、司法、风险、关联方API → 交叉验证 → 生成评估报告 → 写入CRM。1~3分钟,0次系统切换。
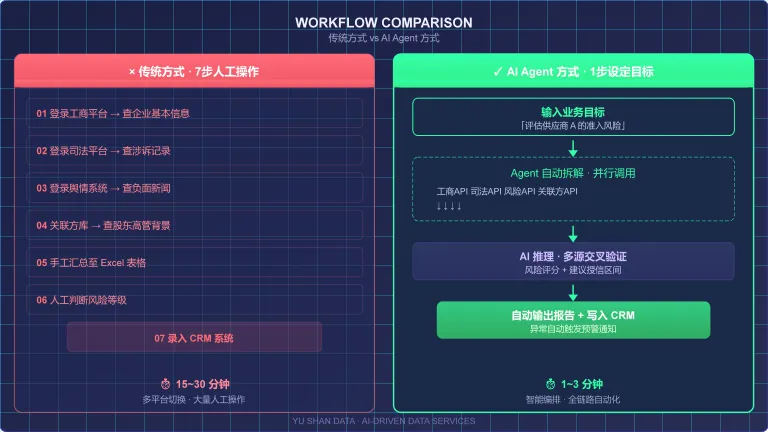
▲传统方式 vs AI Agent 方式工作流对比
最根本的变化:业务语言与数据语言之间不再需要翻译。传统模式下,风控人员需要知道哪些数据接口可用、各自能返回什么字段、如何拼接字段才能得到想要的信息。Agent 模式下,这些数据调用细节被封装在 Agent 的「工具箱」里,用户只需要说出业务目标。
不仅如此,Agent 的工作方式具有传统接口无法比拟的优势——迭代收敛。传统方式的每一步依赖人工判断,一旦中间某个环节出错(如查到的工商信息与实际情况不符),整条链路需要人工回退重来。Agent 则具备自我修正能力:如果某次查询返回空结果或异常数据,Agent 会尝试备选策略(如更改查询参数或换用备用数据源),并在后续步骤中标记这条数据的置信度。
三、为什么是现在?
三个关键技术的同步成熟,共同催生了这一变革窗口。
LLM意图理解:过去的规则引擎需要精确关键词匹配,「查一下某公司的关系户」这样的模糊指令无法执行。LLM可以从自然语言中准确提取实体、意图和约束条件——输入「看下某科技公司有没有什么负面新闻,重点查去年以来的」,LLM 能自动解析出:目标实体=某科技公司、查询类型=司法涉诉与舆情、时间范围=近一年。任务分解准确率已超过92%。
Agent自主编排: Hermes Agent 等框架采用 ReAct 模式——思考→行动→观察→再思考。这意味着 Agent 不像传统工作流那样按固定剧本执行,而是像分析师一样根据中间结果动态调整后续步骤。如果第一步发现目标企业没有直接风险,Agent 可以主动扩展到关联方层面做深挖;如果发现数据冲突(如工商登记的注册资本与年报披露存在出入),Agent 会标记差异并建议交叉验证,而非机械地汇总。
RAG多源融合:传统的向量检索只能做语义相似度匹配,而 Graph RAG 将企业信息建模为知识图谱——从目标企业到高管,到关联企业,再到风险事件,实现了多跳推理。这意味着 Agent 不仅能回答「某公司有什么风险」,还能回答「某公司实控人的其他企业是否有风险传导可能」——后者正是企业风控中最常见、最耗时、最需要专业判断的场景。
这三种能力在2023年后同时进入可用状态,使数据服务从「查询」跃迁为「决策」。这不是渐进式改良,而是范式转换。
四、实战:企业风控审批
输入「核查某公司实控人及关联风险」→ Agent 自动执行以下链路:
① 工商查询(获取基本信息)→ ② 股权穿透(实控人持股60%,实际控制75%)→ ③ 关联方查询(实控人名下5家企业,1家曾有诉讼已结案)→ ④ 司法涉诉(目标公司无被执行记录)→ ⑤ 舆情分析(获高新认定)→ ⑥ 综合评估(评分82/100,建议授信区间)→ ⑦ 写入CRM。
7步压缩为1步,效率提升5~15倍。
但值得注意的是,效率提升只是表面价值,真正的质变在于决策质量的可追溯性。传统人工模式下,风控人员的判断链条是隐性的——为什么通过了这笔授信?依据了哪几条数据?不同数据之间权重如何分配?这些信息通常只存在于审批人的大脑或零散的笔记中。而 Agent 的每一次推理路径都可以完整记录与回溯,这不仅便于合规审计,更能持续优化风控模型。
五、三层架构与安全
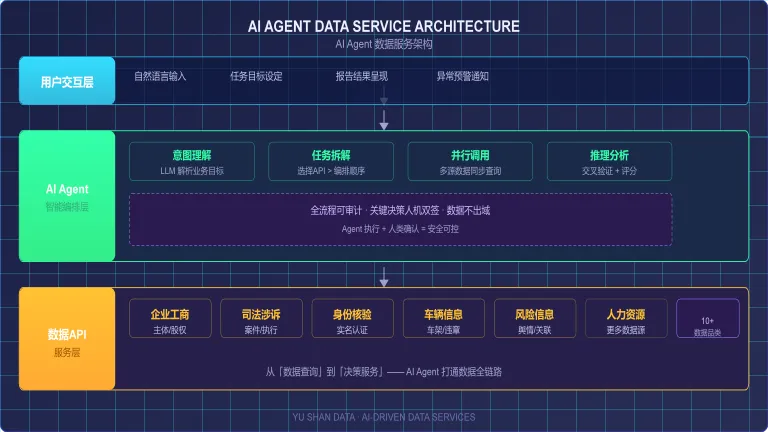
▲AI Agent 数据服务三层架构图
API接入层:每个API提供结构化Function Calling Schema,决定Agent调用质量。Schema 的精确度直接影响 Agent 能否「一次正确」地调用数据接口——接口参数的描述越清晰,Agent 的幻觉率越低。
推理编排层: ReAct模式 + 异常处理。异常处理不仅是「重试3次」,更包含智能策略——超时则切换备用接口、缺失字段则用同类数据源补位、数据冲突则启动交叉验证子流程。这套机制的成熟度,决定了 Agent 能否在复杂业务场景中稳定运行。
缓存控制层:高频查询命中缓存降成本40%~60%。这里的缓存策略并非简单的TTL过期,而是包含语义缓存——如果用户问「某公司的法人是谁」和「某公司法定代表人信息」,Agent 能识别为同一查询意图,直接从缓存返回结果,无需重复调用API。这对于同一企业被多次查询的典型场景(如尽调报告多轮审核)效果显著。
安全体系:① 数据不出域——SLM内网部署,单台服务器无需GPU;② 关键决策人机双签——Agent 完成初筛后,重大审批仍需人工确认;③ 全链路审计日志——每一次API调用、每一步推理、每一次异常处理均记录在案;④ 异常自动熔断——当某数据源连续返回异常,系统自动隔离该源并触发告警。
六、从数据服务到决策服务
过去十年,核心价值是连接——API是桥。未来十年,核心价值是理解——Agent是桥。
范式转换:从「数据→查询→分析→决策」变为「业务目标→Agent理解→融合分析→决策行动」。区别在于前端——前者从数据出发,用户先想"我能查到什么"再决定怎么做;后者从业务出发,用户只需要想"我想达成什么结果"。
这种转换的深层影响不止于效率。当数据消费的门槛被拉低到自然语言层面,企业内部原本需要专门培训才能使用的数据工具将全面下沉到业务一线。这意味着:市场部可以自主查询行业对标数据,风控可以实时监控供应链风险,产品经理可以即时评估竞品动态——每个角色都获得了数据驱动的能力,而不再依赖数据中台团队的「排期支持」。
当竞争对手将决策周期从天缩短到分钟,差距不再是快慢,而是能做与不能做。在未来一到两年内,能够将核心业务流程 Agent 化的企业,将获得不可逆的竞争领先——因为数据不再需要被人"翻译"两遍才能产生价值。
羽山数据为数百家金融、政务客户提供数据API及AI Agent决策支持。十余年数据服务经验+AI Agent,从数据到决策一站式方案。如果您对企业数据API的Agent化改造、风控场景的自动化落地,或是如何在保障数据安全的前提下实现从「查一次」到「管全程」的跃迁遇到了瓶颈,欢迎与我们交流探讨~
商务合作 : 朱经理
Email : zhutingting@yushanshuju.com
公司官网 :https://www.usendata.com
地址 :上海市虹口区飞虹路118号瑞虹企业天地T2-1719

扫码添加我的企业微信
