 夜雨聆风
夜雨聆风uni-app数据库设计与云开发实践
作者:雷达鸭技术团队系列定位:时间线·项目开发期 | 功能模块·用户认证关键词:uniCloud、NoSQL数据库、云函数、云对象、Schema设计、索引优化、触发器> 阅读时间:约 20 分钟系列导航:上篇·架构设计 → 下篇·功能实现 | 微信一键登录功能开发 | 专题:华为登录 · 数据库与云开发 · AI辅助开发实践雷达鸭App已首发华为应用商店
开篇:Serverless不是没有后端,是后端换了个写法
很多人对uni-app云开发有个误解:以为用了uniCloud就不需要设计数据库了,直接写代码往里塞数据就行。实际做下来你会发现,NoSQL数据库设计比关系型数据库更需要提前想清楚——没有外键约束、没有事务保证、没有JOIN查询,数据关系全靠你自己维护。
这篇文章把项目的数据库设计和云开发实践完整摊开——从集合设计到索引优化,从云函数架构到触发器使用,从开发踩坑到生产调优。
一、为什么选uniCloud而不是自建后端
先说结论:一个人做的项目,自建后端是奢侈。
对于雷达鸭这种日活几千级别的应用,uniCloud的免费额度完全够用。省下来的服务器成本和运维时间,可以全部投入产品迭代。
但云开发也有约束——数据库是NoSQL,没有SQL的灵活性;云函数有执行时间限制(默认10秒);冷启动延迟不可控。这些约束在架构设计时必须考虑进去。
二、数据库集合设计
2.1 核心集合总览
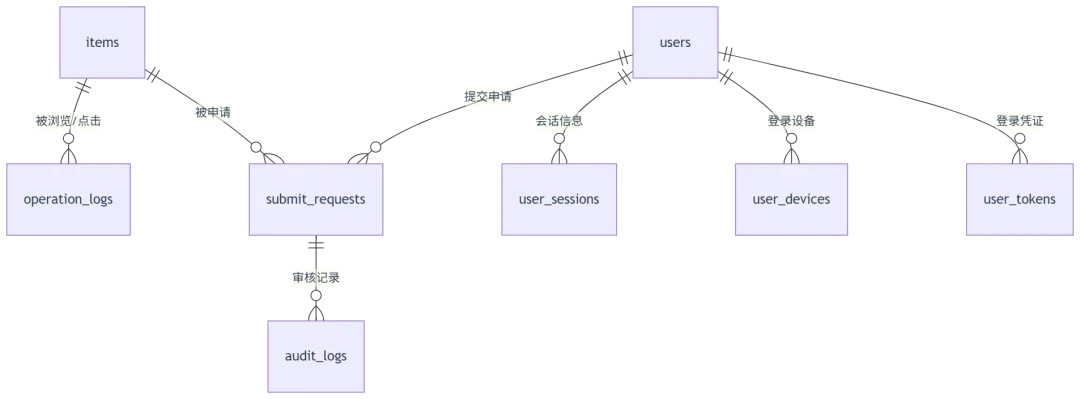
items | |||
submit_requests | |||
users | |||
user_tokens | |||
user_sessions | |||
user_devices | |||
content_list | |||
operation_logs | |||
audit_logs | |||
track_events | |||
payment_logs |
2.2 items(内容核心表)
这是整个应用最核心的数据表,存储所有内容条目的信息。
_id | |||
title | |||
cover_url | |||
summary | |||
category | |||
tags | |||
attributes | |||
tier | |||
business_mode | |||
redirect_url | |||
redirect_type | |||
is_owned | |||
owned_by | |||
status | |||
view_count | |||
click_count | |||
create_time | |||
update_time |
Schema配置示例:
{"bsonType": "object","required": ["title", "cover_url", "summary", "category", "redirect_url"],"properties": {"title": {"bsonType": "string","maxLength": 50,"description": "条目标题,必填,最多50字符"},"category": {"bsonType": "string","enum": ["type_a", "type_b", "type_c", "type_d", "type_e", "type_f", "other"],"description": "分类,必须是预定义值之一"},"status": {"bsonType": "string","enum": ["active", "hidden", "pending"],"defaultValue": "pending","description": "状态"},"create_time": {"bsonType": "timestamp","defaultValue": {"{Date.now()}_${Math.random().toString(36).substr(2, 8)}.jpg`
时间戳+8位随机字符串,冲突概率可以忽略。
六、生产环境优化清单
写在最后
数据库设计是整个项目的基础,改起来成本最高。我的经验是:先把核心查询场景想清楚,再设计集合和索引。不要一上来就画ER图,先把"首页要查什么数据"、“详情页要查什么数据”、"管理后台要查什么数据"列出来,然后反推集合设计。
NoSQL的设计思路和关系型数据库完全不同——关系型是先设计表结构再写查询,NoSQL是先想清楚查询场景再设计数据结构。顺序反了,后面填坑的成本会很高。
相关专题:第三方登录集成方案 — 用户表设计和多端登录的数据处理
参考资料:
uniCloud云数据库文档 uniCloud云函数文档 uniCloud云对象文档 NoSQL数据库设计最佳实践
