 夜雨聆风
夜雨聆风现在谈大模型,最容易落入一个直觉:只要上下文更长、工具更多、架构再复杂一点,模型就会越来越像一个能长期共事的智能体。
我们把问题往前推了一步:AI 的短板不只是“记不住”,而是“不知道什么该临时放在眼前,什么该写进自己,什么又必须被忘掉”。

持续学习的难点,不是把更多信息塞进模型,而是建立一套有节奏的学习系统。它要能快速适应今天的任务,又不能因为今天的新东西,把昨天已经稳定掌握的能力冲掉。
问题不是记住,而是写进哪里
现在的大语言模型,大多把“训练”和“使用”切成两段。训练阶段,知识被压进参数;使用阶段,模型主要靠上下文窗口、检索和工具来补足新信息。

这带来两个相反的坏选择。
完全不更新参数,模型就只能把新知识堆在 token 空间里。上下文再长,也有边界;窗口一满,旧信息就会被挤出去。可如果频繁更新全部参数,又会遇到灾难性遗忘:学会今天的新任务,可能破坏昨天已经会的能力。
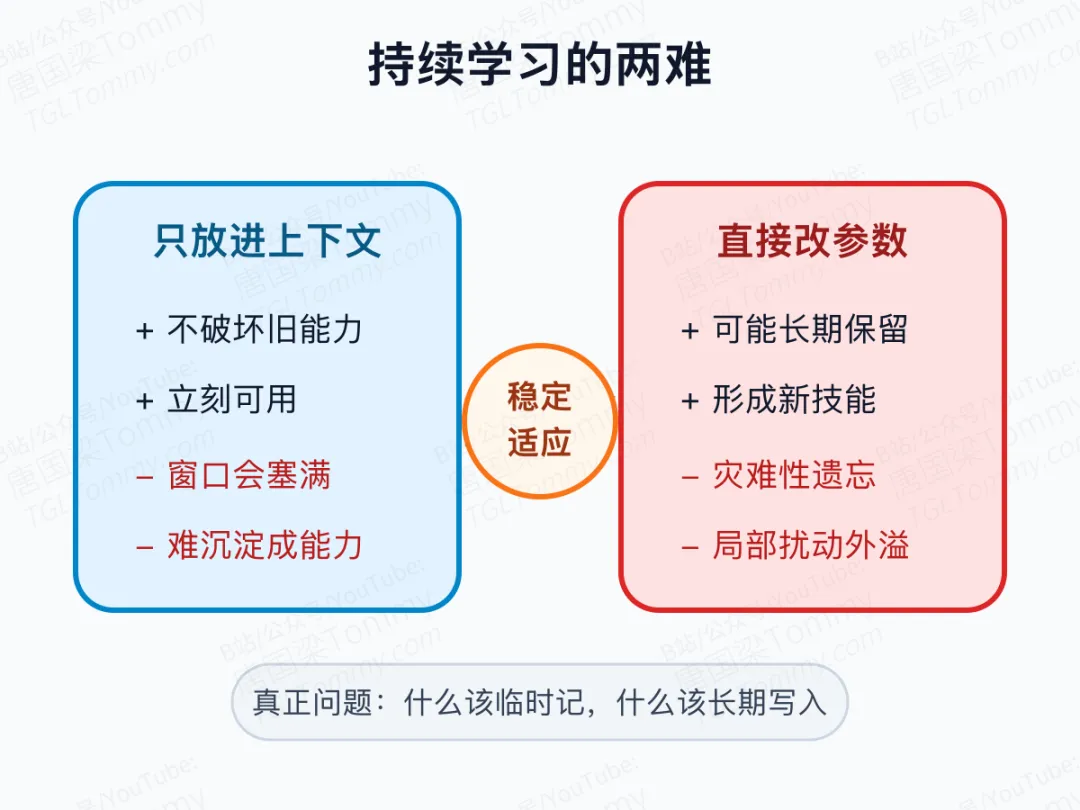
所以,持续学习不是“要不要更新模型”这么简单。更关键的问题是:哪些东西只该短暂记住,哪些东西值得沉淀,哪些东西必须在进入长期记忆前被过滤。
嵌套学习:把频率变成架构的一维
嵌套学习最有启发的地方,不是照搬人脑,而是借用一个原则:不同记忆本来就应该有不同更新速度。
人刚听到的一句话、今天形成的情绪、几周内养成的习惯、多年积累的世界观,并不在同一个节奏上变化。AI 如果只有一种更新频率,就很难同时拥有灵活性和稳定性。

放到模型里,这意味着不要只问“要不要多加几层”,而要问“哪些模块该快,哪些模块该慢”。注意力可以像极快的工作记忆,随每个 token 访问上下文;多个 MLP 或记忆模块则可以按不同间隔更新,有的捕捉高分辨率细节,有的保留更稳定的抽象。
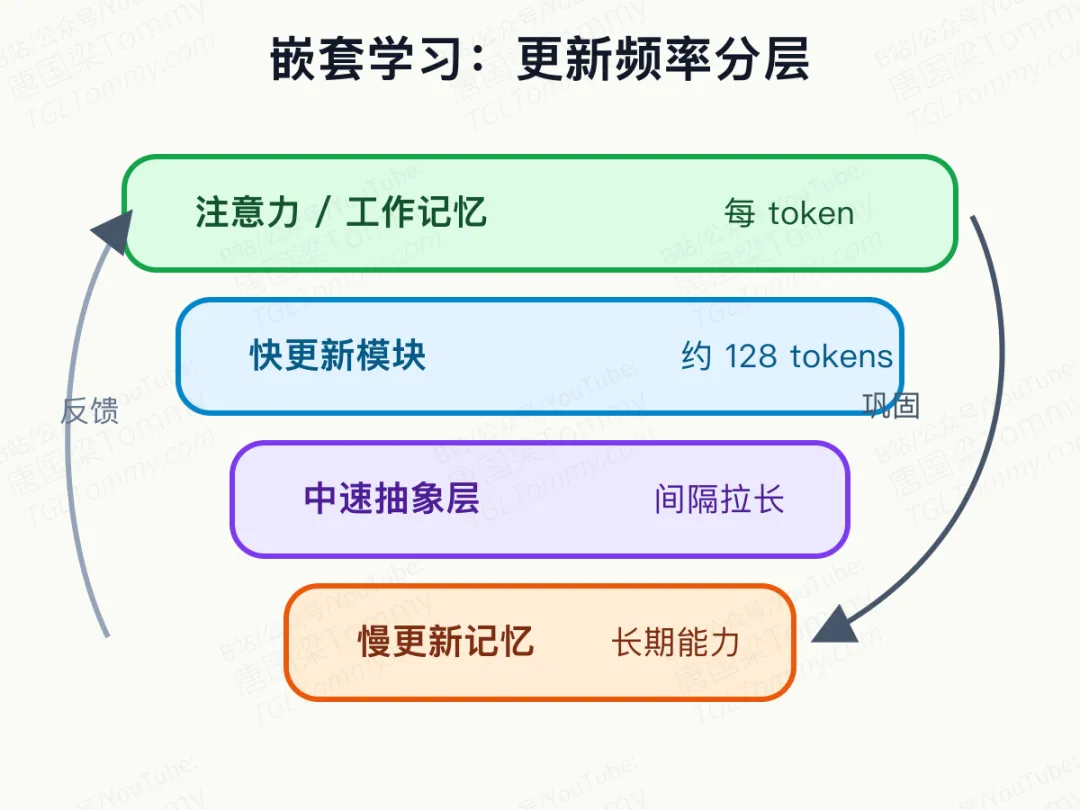
过去的模型扩展,常常把表达能力寄托在更多参数、更多层、更长上下文上。嵌套学习则提醒我们:时间结构本身也是表达能力的一部分。
注意力很强,但它太会原样保留
注意力机制像一个近乎“无限频率”的记忆模块。每来一个 token,它都可以回看上下文里的历史内容。这解释了为什么 transformer 在纯召回任务上非常强,比如从长文本里找一根针。
但强召回不等于好学习。

当任务需要压缩、筛选、抽象,完整保留一切反而会成为负担。噪声多的时候,模型不只是拿到信号,也会把无关 token 一起带进来。注意力对时间因果关系本身也并不天然敏感,还需要位置编码等机制补足。
这时,递归型、压缩型、自修改的记忆模块就变得有意思。它们不只是“存下内容”,还试图根据当前权重状态、历史输入和内部递归过程,决定自己该怎样更新。这里的野心不是做一个更花哨的注意力,而是让模型拥有更像“学习规则”的内部动态。
真正有意思的测试,不在常规表格里
常规语言建模指标当然重要,因为新结构不能把基础能力弄坏。但更能暴露差异的,往往是一些微观学习任务。

例如,把模型几乎没见过的语言的词典、语法和示例放进上下文,再要求翻译。只处理一种新语言时,很多模型还能应付;如果同时放入两种未见语言,要求区分两套词汇、两套规则、两种抽象结构,传统上下文学习就更容易混乱。
多频率层级在这里的价值,是帮助模型把信息分离、压缩、抽象,而不只是临时背下来。

带噪声的召回也是类似逻辑。纯 needle-in-a-haystack 很适合 transformer,因为答案就在上下文里。但如果 haystack 里有大量干扰,真正关键的能力就变成:哪些历史值得保留,哪些历史应该被压扁甚至丢掉。
持续学习的门槛,正在从“能不能看见更多”转向“能不能更好地忘记”。
架构和优化器的边界正在变模糊
这期讨论里还有一个更抽象但很重要的判断:许多机器学习组件,本质上都可以看作关联记忆。

注意力是在 token 之间做关联;反向传播则像在梯度和参数之间做一种上下文学习;优化器里的 momentum,也是在压缩一段梯度历史。模型结构处理 token 流,优化器处理梯度流,但它们都在做压缩、记忆和更新。
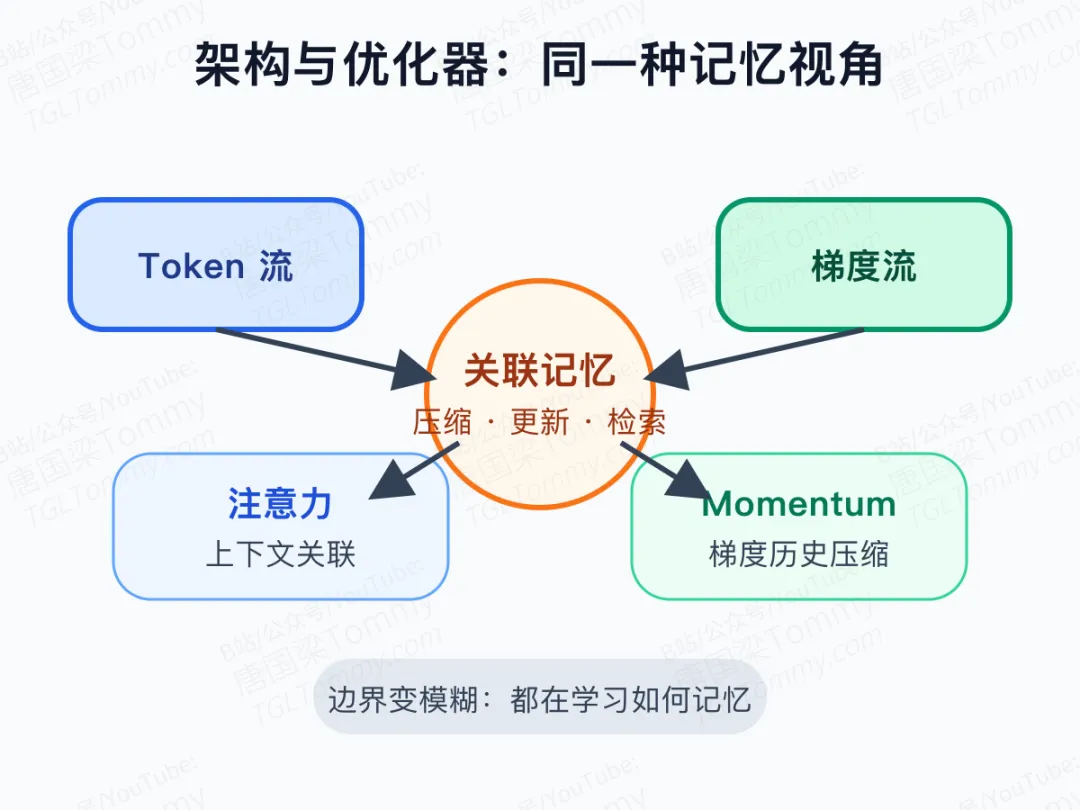
如果这个视角成立,多频率记忆不只属于架构,也可以迁移到优化器。一个带多个记忆尺度的优化器,可能同时把握损失地形的局部震荡和更长期趋势。这里没有必要把它夸成定论,但它确实说明,所谓“架构创新”有时只是更深层学习过程的一种表面形态。
会长期学习,也必须会拒绝学习
持续学习最像人的地方,可能不是会说话,而是需要“睡眠”。

这里的睡眠不是休息,而是离线整理。活跃阶段接收输入、完成任务、快速适应;离线阶段不接收外界信息,却可以把快层刚学到的东西,通过蒸馏转移给慢层。快层释放容量,慢层保留稳定行为,新知识才有机会从细节记忆变成抽象能力。

梦境则可以理解为另一种自我训练:模型根据最近经验生成合成文本,再用这些文本预测后续内容,测试自己是否真的吸收了新知识。它甚至可能把看似无关的概念组合起来,寻找更深层模式。
但越是诱人的方向,越危险。
一个会持续学习的模型,会越来越懂用户的表达习惯、价值偏好和工作方式。它可能变得更连贯,也更贴身;但同一机制也可能吸收隐私、错误信息、恶意输入和短期噪声。
真正的防线,不是禁止模型学习,而是让学习有门槛。快层可以先接触新信息,慢层不该立刻照单全收。巩固之前,需要一致性检查、噪声过滤和价值约束;对可疑样本,系统应该降低内部学习率,而不是让一次惊讶改写长期记忆。

这也是“架构幻觉”最值得警惕的地方。我们很容易把新模块、新名字、新曲线误认为突破本身,却忽略模型最终要面对的是持续互动中的脏数据、暧昧反馈和会变化的目标。如果没有时间尺度和写入边界,再漂亮的结构也可能只是把遗忘和污染推迟到下一层。
这才是持续学习最现实的结论:未来的性能提升未必只来自更大模型、更长上下文或更复杂架构,也可能来自更丰富的学习时间结构。
一个能长期共事的智能系统,应该知道什么时候快速适应,什么时候慢慢沉淀,什么时候主动遗忘。真正重要的问题不再是模型知道多少,而是它怎样学、怎样记、怎样忘,以及它会在长期互动之后,变成什么。
进阶学习
如果你正在关注大模型 Agent、强化学习后训练、RLHF、DPO、GRPO、RLVR 等前沿方向,欢迎学习我最新上线的精品课程:

这门课程围绕当前大模型 Agent 强化学习的核心技术路线展开,不只是介绍零散算法和论文概念,而是希望帮助学习者建立一套完整的技术地图:从基础原理、论文脉络、关键算法,到开源项目源码解析与工业级系统实践,逐步理解 Agent RL 为什么重要、如何演进,以及在真实应用中如何落地。
课程配套专属飞书知识库 《Agent RL 学习宝典》,包含学习路线、论文资料、项目说明、源码阅读辅助资料和后续持续更新内容,方便长期查阅和跟进前沿技术。
Agent RL 变化很快,但越是变化快,越需要一套系统的学习框架。如果你希望系统进入 Agent RL 方向,而不是停留在碎片化了解阶段,这门课会是一个很好的起点。
课程官网:https://www.tgltommy.com/p/agent-rl(国内访问需科学上网)
B站课堂:https://www.bilibili.com/cheese/play/ss842375604(点击左下角“阅读原文”直接跳转)
