 夜雨聆风
夜雨聆风每个索引阶段是一个 Workflow,每个 Workflow 包含多个 Step。Step 之间有依赖关系,没有依赖的可以并发执行。
阅读提示
适合谁看:想深入理解 GraphRAG 内部实现、优化索引性能的工程师 看完能做什么:理解 Workflow/Step 抽象、异步并发控制、错误恢复机制 不适合谁:只想用 API 不关心内部实现的人
先给结论
Workflow 的 Step 依赖通过拓扑排序解析,无依赖的 Step 并发执行 异步并发用 Semaphore 控制,避免同时太多 LLM 调用 大数据集索引时内存压力大,需要控制并发数或分批处理
前 11 天讲了 GraphRAG 怎么用,今天开始讲它怎么实现的。
为什么要看源码?因为当你遇到性能问题、需要优化索引速度、或者想扩展自定义功能时,光会用 API 不够,得理解内部机制。
今天先拆核心包(packages/graphrag/)的 Index Pipeline,搞清楚 Workflow 和 Step 的抽象设计,以及异步并发控制怎么做的。
01 先看全局:核心包的 5 层架构
 图 1|核心包模块结构图
图 1|核心包模块结构图
从上到下 5 层,每层职责清晰:
API 层:对外暴露的入口。index.py 的 build_index() 负责索引,query.py 的 global_search() / local_search() / drift_search() 负责查询。
Pipeline 层:Workflow 调度器。Pipeline.run() 负责解析 Workflow 依赖、拓扑排序、并发控制。
Workflow 层:每个索引阶段是一个 Workflow。TextUnitWorkflow 负责文本切分,EntityWorkflow 负责实体抽取,RelationWorkflow 负责关系抽取,CommunityWorkflow 负责社区检测,EmbeddingWorkflow 负责向量化。
Step 层:每个 Workflow 包含多个原子 Step。比如 EntityWorkflow 包含 extract_entities() Step,每个 Step 声明自己需要什么输入、产出什么输出。
基础设施层:LLM 调用、Storage、并发控制、配置管理。
关键抽象接口:
Workflow:定义一组 Step 及其依赖关系Step:原子执行单元,声明输入/输出契约TableProvider:存储抽象,支持不同后端
02 Workflow 的 Step 依赖怎么解析
每个 Workflow 内部的 Step 之间有依赖关系。比如"实体抽取"Step 依赖"文本切分"Step 的输出。
依赖解析的流程:
声明依赖:每个 Step 声明自己需要的输入(比如 text_units)构建依赖图:根据输入/输出关系构建有向无环图(DAG) 拓扑排序:对 DAG 做拓扑排序,确定执行顺序 识别并发:拓扑排序后,同一层级的 Step 可以并发执行
举个例子:
# Step 定义示例classExtractEntitiesStep(Step): input_types = ["text_units"] # 需要 text_units 作为输入 output_types = ["entities"] # 产出 entitiesclassExtractRelationsStep(Step): input_types = ["text_units"] # 也需要 text_units output_types = ["relations"] # 产出 relations这两个 Step 都依赖 text_units,但彼此不依赖,所以可以并发执行。
03 异步并发控制:Semaphore 机制
GraphRAG 用 Python 的 asyncio 做异步并发,用 Semaphore 控制最大并发数。
# 简化的并发控制逻辑semaphore = asyncio.Semaphore(max_concurrent)asyncdefrun_step(step):asyncwith semaphore:returnawait step.execute()为什么需要 Semaphore?
避免 LLM 限流:同时太多请求会触发 API 限流 控制内存:每个 Step 执行时需要加载数据到内存 公平调度:避免某些 Step 长时间占用资源
实测数据:
max_concurrent=5:适合小数据集(< 100 篇文档)max_concurrent=10:适合中等数据集(100-1000 篇)max_concurrent=20:适合大数据集(> 1000 篇),需要足够内存
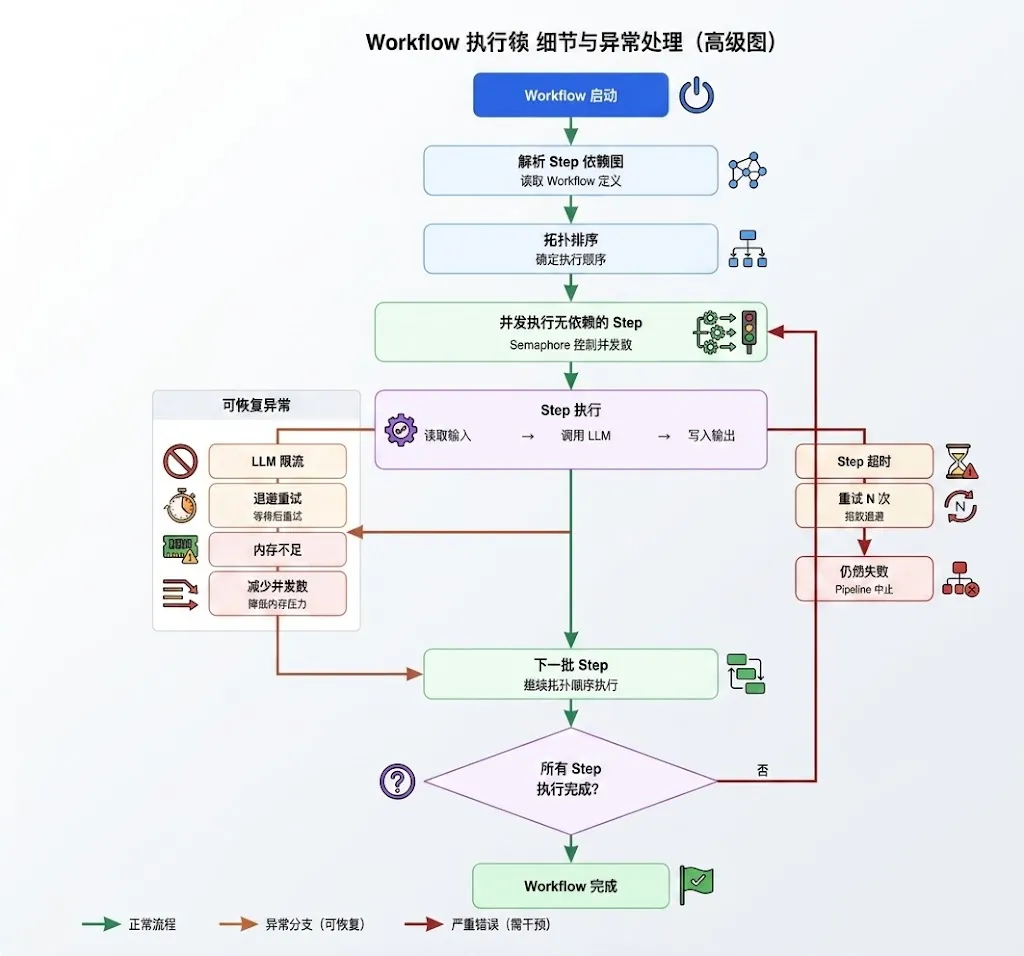 图 2|Workflow 执行细节与异常处理
图 2|Workflow 执行细节与异常处理
04 错误恢复:重试和回退
Step 执行可能失败,GraphRAG 有 3 层错误恢复:
Step 超时:设置超时时间,超时后重试 N 次,每次用指数退避(1s, 2s, 4s, ...)。如果 N 次都失败,Pipeline 中止。
LLM 限流:API 返回 429 时,等待一段时间后重试。等待时间根据 API 响应的 Retry-After 头决定。
内存不足:检测到内存压力时,自动减少并发数。如果还是不够,Pipeline 中止并报错。
# 简化的重试逻辑asyncdefexecute_with_retry(step, max_retries=3):for attempt in range(max_retries):try:returnawait asyncio.wait_for(step.execute(), timeout=300)except asyncio.TimeoutError:if attempt < max_retries - 1:await asyncio.sleep(2 ** attempt) # 指数退避else:raiseexcept RateLimitError:await asyncio.sleep(retry_after)05 Index Pipeline 的 Workflow 执行顺序
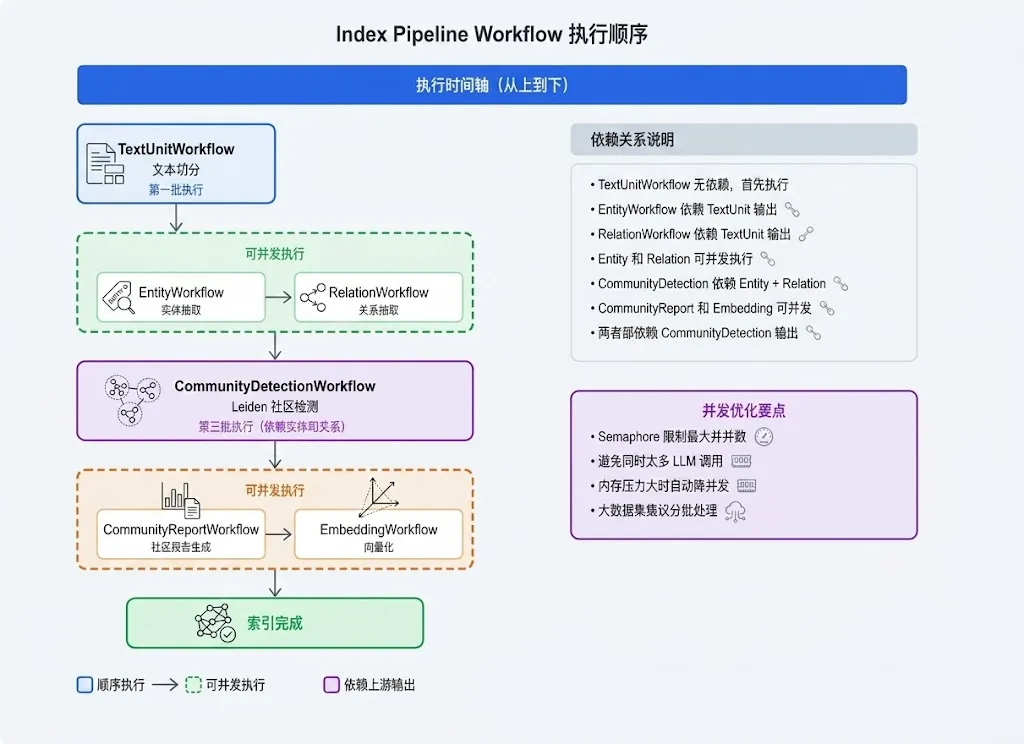 图 3|Index Pipeline Workflow 执行顺序
图 3|Index Pipeline Workflow 执行顺序
从图中可以看到,Index Pipeline 分 4 批执行:
第一批:TextUnitWorkflow(文本切分)。无依赖,首先执行。
第二批:EntityWorkflow + RelationWorkflow(实体/关系抽取)。依赖 TextUnit 输出,可以并发执行。
第三批:CommunityDetectionWorkflow(社区检测)。依赖 Entity 和 Relation 输出,必须等第二批完成。
第四批:CommunityReportWorkflow + EmbeddingWorkflow(报告生成/向量化)。依赖 CommunityDetection 输出,可以并发执行。
并发优化的关键:识别哪些 Workflow 可以并发。在上面的例子中,第二批和第四批都有并发机会,能显著缩短总执行时间。
06 大数据集的内存控制
索引大数据集时,内存是主要瓶颈。每个 Step 执行时需要把数据加载到内存,如果数据量太大,可能 OOM。
内存控制策略:
1. 控制并发数
减少 max_concurrent,让同时在内存中的数据量变小。
2. 分批处理
把大数据集分成小批,每批独立索引,最后合并结果。
3. 流式处理
对于超大数据集,用流式处理避免一次性加载全部数据。GraphRAG 的 TableProvider 支持流式读取。
4. 及时释放
Step 完成后及时释放不再需要的数据。Python 的 GC 会自动处理,但显式 del 可以更快释放。
实测数据:
100 篇文档:内存约 500MB 1000 篇文档:内存约 2GB 10000 篇文档:内存约 8GB+,需要分批处理
07 Query Engine 的策略模式
Query Engine 用策略模式实现 Global/Local/DRIFT 三种查询方式。
# 简化的策略模式classQueryEngine:def__init__(self, strategy: QueryStrategy): self.strategy = strategyasyncdefquery(self, question: str):returnawait self.strategy.execute(question)# Global Search 策略classGlobalSearchStrategy(QueryStrategy):asyncdefexecute(self, question):# 1. 获取所有 community_reports# 2. Map: 每个 report 独立生成局部回答# 3. Reduce: 汇总所有局部回答 ...# Local Search 策略classLocalSearchStrategy(QueryStrategy):asyncdefexecute(self, question):# 1. 从问题中提取实体# 2. 在图谱中定位实体# 3. Fan-out 到 1-hop 邻居# 4. 收集关联 text_chunks# 5. 组装上下文,LLM 生成答案 ...这种设计的好处:
新增查询方式只需实现新的 Strategy 不同查询方式可以独立优化 测试时可以 mock 策略
08 工程实践:怎么基于源码做优化
优化 1:调整并发数
如果索引速度慢,先检查是不是并发数太小。在 settings.yaml 里调整:
parallelization:max_concurrent:10# 默认是 25,可以根据机器配置调整优化 2:跳过不需要的 Workflow
如果你不需要 Embedding(只用 Global Search),可以跳过 EmbeddingWorkflow。
优化 3:自定义 Step
如果默认的实体抽取不够好,可以自定义 Step 替换它。继承 Step 类,实现自己的逻辑。
优化 4:监控和日志
在 Pipeline 层加监控,记录每个 Step 的执行时间、Token 消耗、错误率。这些数据对优化很有价值。
如果你只是用 GraphRAG,不需要看源码。但如果你想优化性能、扩展功能、或者排查疑难问题,源码是必须看的。
今天拆了 Index Pipeline 的 Workflow/Step 抽象、异步并发控制、错误恢复机制。下一篇会拆 Query Engine 的实现细节,看看 Global/Local/DRIFT 三种策略具体怎么工作。
如果这篇帮你理解了 Workflow 和 Step 的协作机制,欢迎点个赞。
如果你在索引大数据集时遇到了性能问题,欢迎在评论区描述现象和数据规模,我可以帮你分析瓶颈在哪。
参考链接
[GraphRAG GitHub 仓库] (https://github.com/microsoft/graphrag) [Python asyncio 文档] (https://docs.python.org/3/library/asyncio.html)
