 夜雨聆风
夜雨聆风如果你已经在日常工作中使用 Cursor、Claude Code 或 GitHub Copilot,你可能有一种直觉感受:写代码确实快多了,但公司产品的发布节奏,似乎没有按比例加速。
这不是你的错觉。
2026年5月,美国国家经济研究局(NBER)发布了一项迄今最大规模的 AI 编程工具生产率追踪研究——追踪超过十万名 GitHub 开发者,结合 AI 工具遥测数据,系统测量了从「自动补全」到「自主 Agent」三代工具的真实效应。
研究的核心发现令人深思:任务级的生产率提升是真实的、显著的;但这些红利在穿越真实的软件开发流水线时,被大幅衰减——任务级的 +180% 增益,到达发布环节只剩 +30%,不足六分之一最终体现在真正"上线"的软件中。
提交量暴增,发布量未能跟上——这两者之间的鸿沟,正是这项研究想要解剖的。
这项研究做了什么
论文全名为《Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools》,作者为 Mert Demirer、Leon Musolff、Liyuan Yang(Demirer 与 Musolff 均为微软研究顾问),以 NBER 工作论文形式于 2026 年 5 月发布。
研究方法的核心是事件研究法(Event Study):追踪开发者在采用 AI 编程工具前后的行为变化,同时结合工具遥测数据进行匹配分析,从而剔除选择偏误——那些率先采用 AI 工具的开发者,本来就可能更高效、更活跃,如果不做对照,数据会被严重高估。
数据覆盖 GitHub 上超过 10 万名真实开发者,是目前已知规模最大的同类实证研究。
更重要的是,研究没有止步于「代码提交量」这一个指标,而是沿着真实的软件开发流水线,逐级测量了生产率效应:
- 任务级
:个人代码提交(commit)活动 - 项目级
:代码合并(PR merge)与项目推进 - 发布级
:真实软件版本发布(release) - 市场级
:App 上架数量、用户参与度
这个多层次的设计本身,就暗含了研究者的判断:「写了更多代码」和「交付了更多产品价值」,是两回事。
三代工具的生产率跃迁
研究将 AI 编程工具按演化代际划分为三代,与行业直觉高度吻合。
第一代:自动补全工具(以 GitHub Copilot 为代表)
核心能力是基于上下文的代码补全,开发者打出前几个字符,工具预测并补全剩余部分。这是「辅助」而非「代理」的逻辑,人类始终在主导每一行代码的生成。
NBER 数据显示:这一代工具给开发者的任务级 commit 活动带来了 +40% 的累计增长。
第二代:交互式编程 Agent(以 Cursor、GitHub Copilot Chat 为代表)
引入了对话式编程能力:开发者用自然语言描述需求,Agent 生成整个函数、模块乃至重构方案。开发者的角色从「写代码」转变为「审代码」。
任务级增长效应:+140%,比第一代翻了近三倍。
第三代:自主编程 Agent(以 Claude Code、Devin 为代表)
能够接受高层次的任务描述,自主规划、搜索、执行,甚至运行测试并迭代修复。整个功能实现可以交给 Agent 独立完成,人类在某些场景下只需提供目标和验收标准。
任务级增长效应:+180%。
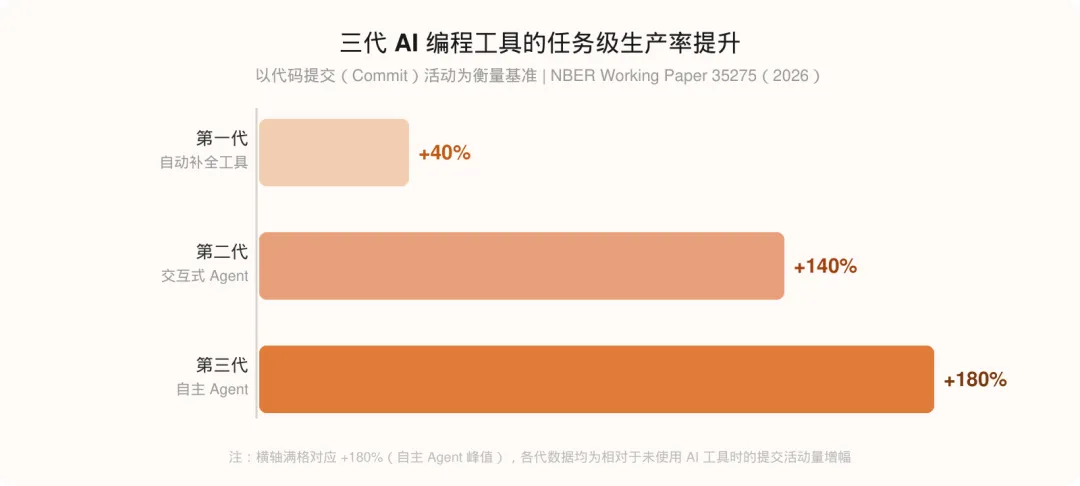
从 +40% 到 +140% 到 +180%,每一代工具都带来了显著的跃升。如果只看这一层,「AI 编程工具的生产率革命」论据充分。
但研究的关键贡献,在于它追问了下一个问题。
生产率红利在流水线中蒸发
软件开发不只是「写代码」。一行代码从敲下键盘到真正被用户使用,要经历代码审查、CI/CD 测试、产品验收、版本管理、灰度上线……每一个环节都是过滤器。
NBER 的数据揭示了一个清晰的衰减模式:
| +180% | |||
| +50% | |||
| +30% | |||
在自主 Agent 产出的所有「生产率红利」中,只有约六分之一(+180% 衰减至 +30%)能够穿越整个流水线,真正体现在上线的软件里。到了市场端,这个数字接近于零。
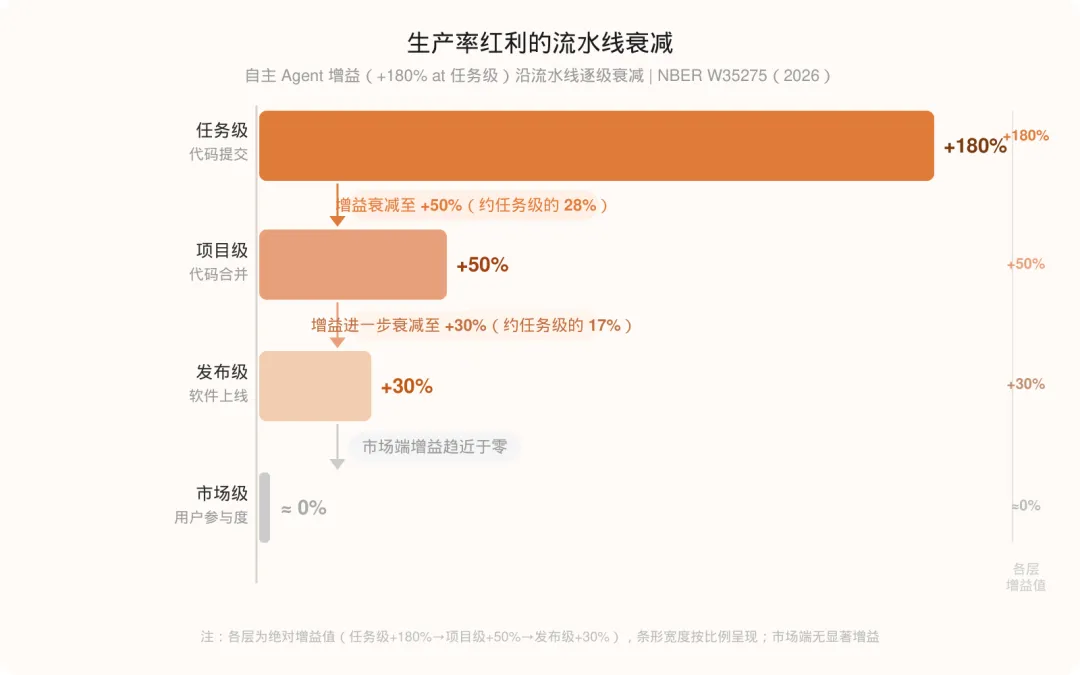
这不是技术失灵,而是系统结构的必然结果。
衰减在哪里发生?
1. 代码审查的人力瓶颈
Agent 生成代码的速度,已经远超人类审查的速度。当一个开发者每天提交的 PR 数量从 2 个变成 10 个,审查者的处理能力并没有同步提升。PR 积压、延迟合并、甚至被放弃,这些都在现实团队中大量发生。
审查者成了流水线上最脆弱的那个节点。
2. 代码质量的隐性摩擦
AI 生成的代码在「能跑」和「能用」之间存在差距。测试覆盖率、可维护性评审、安全漏洞扫描……每一个质量门槛都是过滤节点。越靠近生产环境,质量要求越高,摩擦系数越大。
短期内通过 CI 的代码,不一定经得住时间检验。
3. 产品决策的上游依赖
更多的代码提交,未必对应更多有价值的功能。在 Agent 模式下,开发者可能更容易「做」一件事,但「做什么」的判断仍然依赖人类。当工具让执行变得廉价,需求确认、优先级判断这些上游决策反而更加凸显其价值——它们决定了大量 Agent 工时最终对准哪个方向。
互补而非替代:一个关键数字
研究还测量了一个重要参数:AI 与人类工作量之间的替代弹性(Elasticity of Substitution),测量结果为 0.25。
这个数字如何理解:弹性越接近 0,越意味着「互补」;越接近 1,越意味着「替代」。0.25 代表 AI 编程工具与人类开发者之间是强互补关系——AI 放大了人类的产出,但并没有在大规模上取代人类劳动。
这对于理解「为什么红利难以完全交付」至关重要:即使在自主 Agent 时代,AI 的角色仍然是增强器(amplifier),而非替代者(substitute)。
人类开发者在流水线中仍然是不可缺少的节点——无论是代码审查、架构决策,还是产品判断。这些节点的处理速度和质量,构成了整体流水线的吞吐上限。
AI 工具让个体的「产能」大幅提升,但整个组织的「吞吐量」取决于最慢的那个环节。这是一个经典的系统动力学约束,不是写更多代码就能解决的。
市场端的真实故事
研究将分析延伸到了市场端,考察 AI 编程工具普及后软件市场的实际变化。
结果是中性的,甚至令人有些意外:
- App 上架数量
:在四个主要 App 市场中有中等程度的增长 - 用户总体参与度
:没有显著变化
更多的应用上架了,但用户总时长并没有增加。这说明 AI 工具带来的供给侧扩张,并没有同步带来需求侧的增长。
换句话说:AI 工具让「做软件」变得更容易,但它无法创造用户需求。发现真实问题、构建产品价值、找到产品市场契合点——这些依然是纯人类的游戏。
这个发现对独立开发者尤其值得警醒:更多的 AI 生成代码不等于更好的产品,更好的产品不等于更多的用户。分发、营销、产品价值这些非代码问题,AI 工具几乎帮不上忙。
对从业者的几点推论
这项研究的价值,不在于告诉我们 AI 工具「没用」——恰恰相反,+180% 的任务级提升是真实存在的,不容忽视。它的价值在于帮助我们更精确地理解红利在哪里,以及为什么无法完全兑现。
不要用 commit 数量衡量 AI 工具的团队价值
任务层面的指标在个人评估上是有效的,但会系统性高估整体收益。真正值得追踪的是 PR 合并周期、发布频率、线上 bug 率这些下游指标。
代码审查能力成了新的关键瓶颈
在自主 Agent 时代,团队的代码审查能力是当前的主要约束。值得认真投资的方向:AI 辅助审查工具(如 CodeRabbit)、强化 CI/CD 质量门禁、或者调整 PR 粒度规范,让每个 PR 更小、更聚焦、更易审查。
上游决策的价值相对上升
当执行变得廉价,方向判断的价值相对上升。产品经理、技术 Lead 在需求澄清、优先级排序上的质量,会越来越直接影响整体产出比——方向错了,Agent 执行的浪费成本也是真实的。
用「互补」而非「替代」建立心智模型
替代弹性 0.25 告诉我们:现阶段 AI 编程工具最好被理解为「杠杆」而非「替代」。用对了,单个工程师的影响力可以数倍放大;但前提是,这个工程师本身的判断力和系统视角是可靠的。杠杆放大的是两端——包括错误方向的努力。
供给增加不等于需求增加
如果你正在用 AI 快速构建产品,市场端的发现提醒我们:构建速度加快了,但市场验证的速度并没有。更快的构建周期,应该被用于更快地测试假设、获取用户反馈,而不仅仅是堆砌功能。
结语
NBER 这项追踪十万开发者的实验,给出了一个来自大数据的诚实答案:AI 编程工具的生产率提升是真实的,也是分层的。
从自动补全的 +40%,到交互式 Agent 的 +140%,到自主 Agent 的 +180%——任务层面的跃升确实发生了,也将继续发生。
但从「更多提交」到「更多上线」,从「更多上线」到「更多用户价值」,整条链路上存在系统性的衰减。衰减的根源不在工具本身,而在于围绕代码的人类流程、组织决策和市场现实。
如果说过去五年 AI 编程工具重塑了「写代码」的方式,那么接下来更有意思的问题可能是:
如何重新设计整个软件开发的流程,让 +180% 的任务级红利,能更多地穿透流水线,真正抵达用户手中?
这是工具之外的问题,也是每个工程团队、每家科技公司,此刻真正需要思考的问题。
来源:Mert Demirer, Leon Musolff, Liyuan Yang, "Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools", NBER Working Paper 35275, 2026年5月。
欢迎关注AI觉醒观测者。
