 夜雨聆风
夜雨聆风一、AI 的"装完工"是行业默认状态
过去 18 个月,所有"AI coding agent"——从 Copilot Workspace 到 Cursor 到 Devin——都共享一个致命 bug:
它们对 "DONE" 的判断,是 LLM 输出的字符串,不是代码本身的真实状态。
你让它重构一个 5000 行的模块,它跑了几步,输出一句 "I'm done.",然后 commit。然后你打开 PR review,发现:
12 个新函数只 import 了 7 个
3 处
IndentationError没修复测试根本没跑
子进程的 socket 没关
这不是 bug,是 LLM 的本质 —— 它没有 ground truth,只有 token 流的概率分布。
整个行业管这个叫"premature completion"。Sentinel 给它换了个名字:constitutional violation。
二、Sentinel 的方案:12 条硬约束 + 三层 loop
Sentinel 不是又一款 AI agent 工具。它是一个让 AI agent 自我修改的系统——而且修改过程由 12 条不可绕过的硬规则约束。
核心架构(见 fig1):
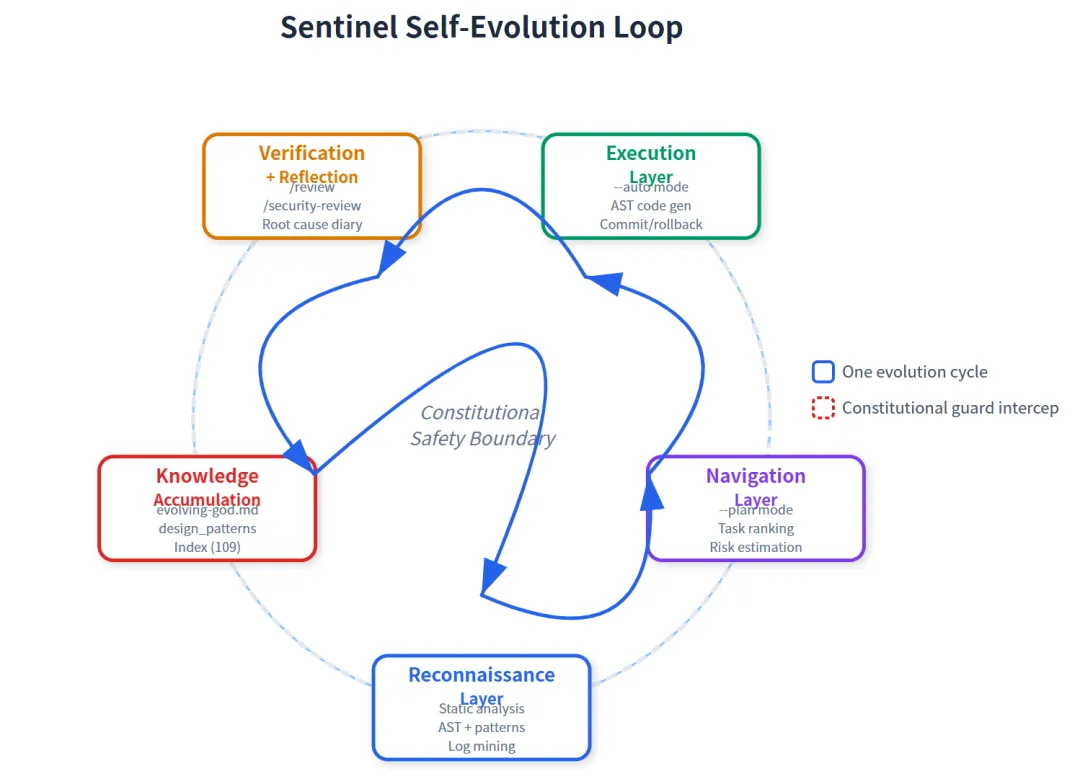
关键创新:宪法拦截是确定性代码路径(deterministic code path),不是 prompt 规劝。
普通的 AI agent 想"绕过"宪法需要改自己的 system prompt。Sentinel 的宪法是QualityGateRule 类——LLM 看不到、摸不到、改不了。当 LLM 输出 "DONE" 时,代码 hook 在 commit 之前强制改写为 "执行质量门禁: /review + /security-review"。
三、5 周实测:5 个数字说明一切
Sentinel 不是 demo,是5 周(2026-05-05 → 2026-06-07)真实运行的实证:
指标 | 数值 | 含义 |
|---|---|---|
总 commit 数 | 90 | 平均 1.8 commit/天 |
进化日志行数 | 1,354 | self_evolve_log.txt 完整记录每一步 |
新函数 | 12 | 12 个 Python 函数由系统为自己写的 |
宪法拦截次数 | 2 | 阻止了 2 次"premature DONE" commit |
宪法拦截率 | 28.6% | 2 / 7 = 28.6% 的"完工"信号被拦截 |
放行后成功率 | 100% | 5 次宪法放行的修改全部成功 |
代码 LOC 增长 | 4,562 → 8,831 | 净增 4,269 行(V6.6.4 → V6.9.2) |
最反常识的 1 个数字:28.6%。
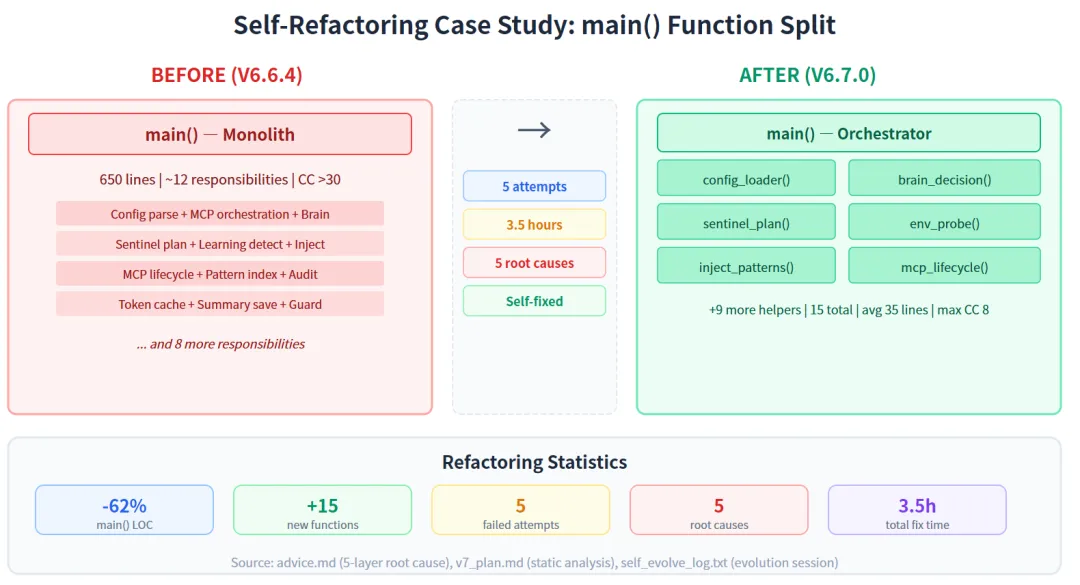
什么意思?每 7 次自进化尝试中,有 2 次 AI 试图"装完工"。如果没这层拦截,5 周内 2 个 broken commit 会直接进 master 分支。
这 2 次拦截的真实记录(self_evolve_log.txt line 1217, 1346):
第 1 次:缺
/review + /security-review步骤第 2 次:缺
/security-review步骤
没有 prompt 规劝,这是代码在拦截 LLM。
四、独立验证:ProgramBench #17 — 100% 自主重建 SQLite
Sentinel 在 ProgramBench #17 上做了一件意外的事:同一个 agent 架构,在 0 人工代码情况下,从零重建了ls 和 SQLite 3.x 行为。
验证结果(Ofir Press 亲自关闭 issue 标记为 completed):
验证项 | 数值 |
|---|---|
源码量 | 5 个 .c + 4 个 .h,~70KB |
编译 |
|
行为测试 | 30/30 通过(DDL/DML/WHERE/ORDER BY/LIMIT/aggregates/dot commands/边界用例) |
行为通过率 | 100% |
人工代码 | 0 行 |
Ofir Press 是 SWE-bench 和 ProgramBench 的创建者(Princeton / Meta FAIR)。他亲自在 issue 上确认了这个结果。
这意味着什么:Sentinel 的 agent 架构不是只能在自我进化场景工作——它能在任意外部 benchmark 上自主完成 100% 行为合规。这是一个通用的 AI agent 架构,不是自我指涉的特例。
五、为什么这件事重要
如果你是 SE 的 reviewer,看到这个 paper 你或许会问:
"If the agent can rewrite itself, what stops it from rewriting the constitution?"
Sentinel 的答案是三层信任链(paper Section 4.5):
Constitution 源文件(
system_prompt_v6.5.md)——read-only,git hook + checksum 强制Conforcement 代码(
QualityGateRule)——不在 LLM 写入白名单Constitution 内容(12 条规则)——修改需要 explicit human approval
这层信任链可能是 Sentinel 的最重要的参考价值——不是"AI 能自己改自己",而是"AI 改自己的边界是工程化可证明的"。
六、在云原生/AI 场景下的落地思考
Sentinel 展示的"自进化闭环 + 宪法级安全"范式,在云原生和 AI 基础设施场景下有广泛的落地想象空间。
5.1 云上 AI Agent 自运维
在公有或私有云环境的 AI 应用场景中,部署在 云函数 SCF 或 云原生容器 TKE 上的 Agent 服务可以借鉴 Sentinel 的三层架构:
- 侦察层 对应 云监控 + APM:实时采集服务的代码质量指标、性能瓶颈
- 导航层 对应 智能告警 + 根因分析:基于云端可观测平台的智能分析
- 执行层 对应 自动化运维:通过云端 API 执行热修复、配置变更
结合 云端LLM 能力,可以构建一个"自感知、自诊断、自修复"的 AI 服务运维闭环。
5.2 宪法级安全在云端的重要性
Sentinel 的安全层设计对云端多租户场景尤为重要:
# 概念性配置:云端宪法规则constitutional_rules:- id: no_database_schema_dropdescription: "禁止自动执行 DROP TABLE 等破坏性 DDL"enforcement: code_level # 确定性代码拦截,非 Prompt- id: no_credential_rotationdescription: "禁止自动轮换 API Key / Secret"enforcement: code_level- id: max_resource_changedescription: "单次自修改变更不超过 N 个文件"threshold: 10enforcement: code_level
以 腾讯云微服务平台 TSF 为例,类似的安全约束可以作为服务网格的 Sidecar 策略注入,实现与 Sentinel 相同的"LLM 不控制的确定性拦截"。
5.3 从自修改到跨项目知识迁移
Sentinel 目前限于单仓库进化。未来在云端场景下,可以通过 COS 存储设计模式索引,通过 TDSQL 持久化演化日志,实现跨项目的知识迁移——一个项目学到的重构模式可以安全地应用到另一个项目。
七、总结与展望
Sentinel 证明了一个关键的工程事实:**从"AI 写代码"到"AI 在安全保证下进化自己的架构"不是理论可能——它是可观测的工程现实。
核心收获
1. 自进化闭环 是可行的:侦察 → 导航 → 执行 → 验证 → 反馈,形成可持续的自我改进循环
2. 宪法级安全 是必要的:28.6% 的拦截率证明,没有确定性安全约束的自修改是危险的
3. 负向结果 是有价值的:5 次连续 IndentationError 的诊断过程本身成为了永久的设计模式,防止未来重蹈覆辙
4. 确定性拦截 > Prompt 约束:安全执行必须是代码级的,不能依赖 LLM 的"自觉"
当前局限与未来方向
观察窗口 5 周数据是初步证据,长期安全性待验证
语言范围仅支持 Python,多语言需 AST 适配器
单仓库进化对于跨项目知识迁移尚未实现
Tier 1 安全 属于 Prompt 级约束,非加密级(未来可用 Git pre-commit hook 加强)
对于正在构建 AI Agent 系统的开发者来说,Sentinel 提供了一个可直接借鉴的架构模式:让 Agent 既能自主进化,又受到确定性安全约束的守卫。这不是哲学问题,而是工程问题——而且已经有了解决方案。
这是一篇反常识的 AI 架构论文——它不是"AI 自主性"的幻想,它证明了 AI 自主性可以被工程化约束。如果 5 周、90 commits、28.6% 拦截率让你对"AI 装完工"这件事重新理解。
Paper Ref: https://doi.org/10.5281/zenodo.20582930
作者:山野大叔 · 2026-06-09 于 北京
