 夜雨聆风
夜雨聆风说实话,看到这个数字的时候,我愣了一下。
13.4%。
这是目前最强AI编程模型,在一个叫 FrontierCode 的新基准测试上,最难的那组题里,拿到的分数。
你没看错。不是93.4%,是13.4%。
这事让我想了很多。
因为我平时自己写代码,用的最多的就是Claude Code和Cursor。很多时候我觉得它写得挺好的,一个功能嗖嗖就出来了,跑起来也没什么问题。那种感觉就像突然有了一个全能实习生,什么都能干,什么都会。
但这个数字让我意识到,我可能一直被某种错觉笼罩着。
就是那种,能跑和能用之间好像隔着什么,但我一直没仔细想过,到底隔着什么。
然后FrontierCode把它翻出来,摆在桌上了。
先简单说一下FrontierCode是什么。
它是Cognition做的。Cognition就是做了Devin那家公司,号称AI程序员的那种。
这个基准的核心一句话就能说清楚。它不关心AI写出来的代码能不能跑通,它关心的是,如果这个代码是一个真人写的PR提交到开源项目里,维护者会不会点那个绿色的Merge按钮。
能跑和能合并,是两件事。生产级代码和Demo玩具,也是两件事。能跑和能合并,其实是两件事。
我以前也不太理解这两者到底差在哪,直到我看了FrontierCode的一个案例,一下子被击中了。
他们拿了一个真实的任务出来展示。Claude Opus 4.8写出来的代码,测试全过了,功能完全正确。
但Andrew He看了一下,说,不行。
Andrew He是谁呢。Codeforces全美第二的选手,两届IOI金牌得主,Cognition的联合创始工程师。
他指出的问题出在哪呢。
Ai生成的代码里面在有多个warning消息需要连续输出的场景下,Opus 4.8的写法是混用的。一部分用了新写的 LOG_WARNING(),另一部分直接调了 std::cerr。
这两者在当前场景下行为完全一样,都能正确输出。
但这里埋了一个隐形的假设。LOG_WARNING() 和 std::cerr 永远指向同一个输出流。
如果以后有人改了 LOG_WARNING() 的实现,不输出到 std::cerr 了怎么办。那些直接调 std::cerr 的代码就全断了。
功能没问题,测试全过了。
但就是不能被合并。
因为这个PR里,隐含了一个不该做的假设。
我读到这里的时候,感觉像是被一根针扎了一下。
这个问题,用传统基准测试永远测不出来。HumanEval不会管你,SWE-Bench也不会管你。你的测试全绿,你觉得自己牛逼坏了。
但真正的项目维护者扫一眼就知道,不够好,回去重写。
这就是能跑和能合并之间的距离。
你可能会问。那FrontierCode到底是怎么测的。
我仔细研究了一下它的设计,坦率的讲,这是我见过最较真的一套评估系统。

它有7个评估维度。
行为正确性、回归安全性、机械清洁度(编译/lint/风格检查)、测试正确性、作用域控制、代码质量、生态兼容性。
每一条都对应一个具体的评分方法,有些是自动化的确定性测试,有些是LLM打分的软性评估。
还引入了三种新的评分技术,我觉得设计得特别有意思。
第一个叫 Reverse-Classical,反向测试。
AI写的测试,你得能证明它是有意义的才行。怎么搞呢。把AI写的测试跑在还没修复的原代码上,那个测试必须失败。这样才能证明AI是真的理解了问题,而不是随手写了一个永远通过的假测试来刷分。
第二个叫 Code Scope,作用域控制。
一个PR只能动它该动的东西。不能顺手改了无关的文件,不能把整个项目翻个底朝天。这个检查分三层。文件级约束,哪些文件能碰。大小级约束,最多改多少行。语义级约束,改动必须在同一个函数范围内。
听起来很基础对吧。但我自己的经验是,用AI写代码的时候,最常遇到的就是它突然改了一个我不让它改的文件。一个简单的bug修复,它顺手把隔壁模块的缩进全改了。这种PR交上去,被骂是迟早的事。
第三个叫 Adaptive Classical Grading,自适应测试。
同一个任务,AI可能用完全不同的方式实现。传统单元测试太死板,会因为函数名不同这种细枝末节就判错。FrontierCode用了一套自适应机制,让LLM去动态调整测试环境,适配AI的具体实现方式,然后跑确定性测试。
坦率的讲就是,我不在乎你怎么实现的,我只看你最终的功能对不对。
但我觉得最让我震撼的还不是这些技术本身,而是FrontierCode背后那套质量控制流程。
这道题的每一道题,都不是程序自动生成的,而是由顶级开源项目的维护者亲手打造的,测的就是真实。
来自36个不同开源项目的20多位维护者,平均每道题投入了超过40个小时。他们要经历五轮流程。设计、hack报告、校准、评审、再评审。
hack报告这个环节特别有意思。维护者要故意装成一个懒惰的或者对抗性的程序员,写一些明显错误或者钻空子的解法,来测试评分标准能不能把它们拦住。同时还要写一个完全不同的合法解法,来测试评分标准是不是太死板了。
而且最骚的是,他们还会让Devin自己上,去找评分规则的漏洞。
每道题最后还要经过一个Cognition研究员的亲手终审。
40个小时,就为了一道题。
20多个顶级维护者,就为了给出一个标准。什么样的代码,值得被Merge。
我写这段的时候脑子里就一个想法。太特么赤鸡了。这大概是我见过最较真的一个benchmark。
也正是它敢说自己比SWE-Bench Pro的误判率低81%的底气所在。
好了,看看成绩单。
FrontierCode把150道题分成三个难度级别。Diamond是最难的50道,Main是最难的100道,也就是包含Diamond的。Extended是全部150道。
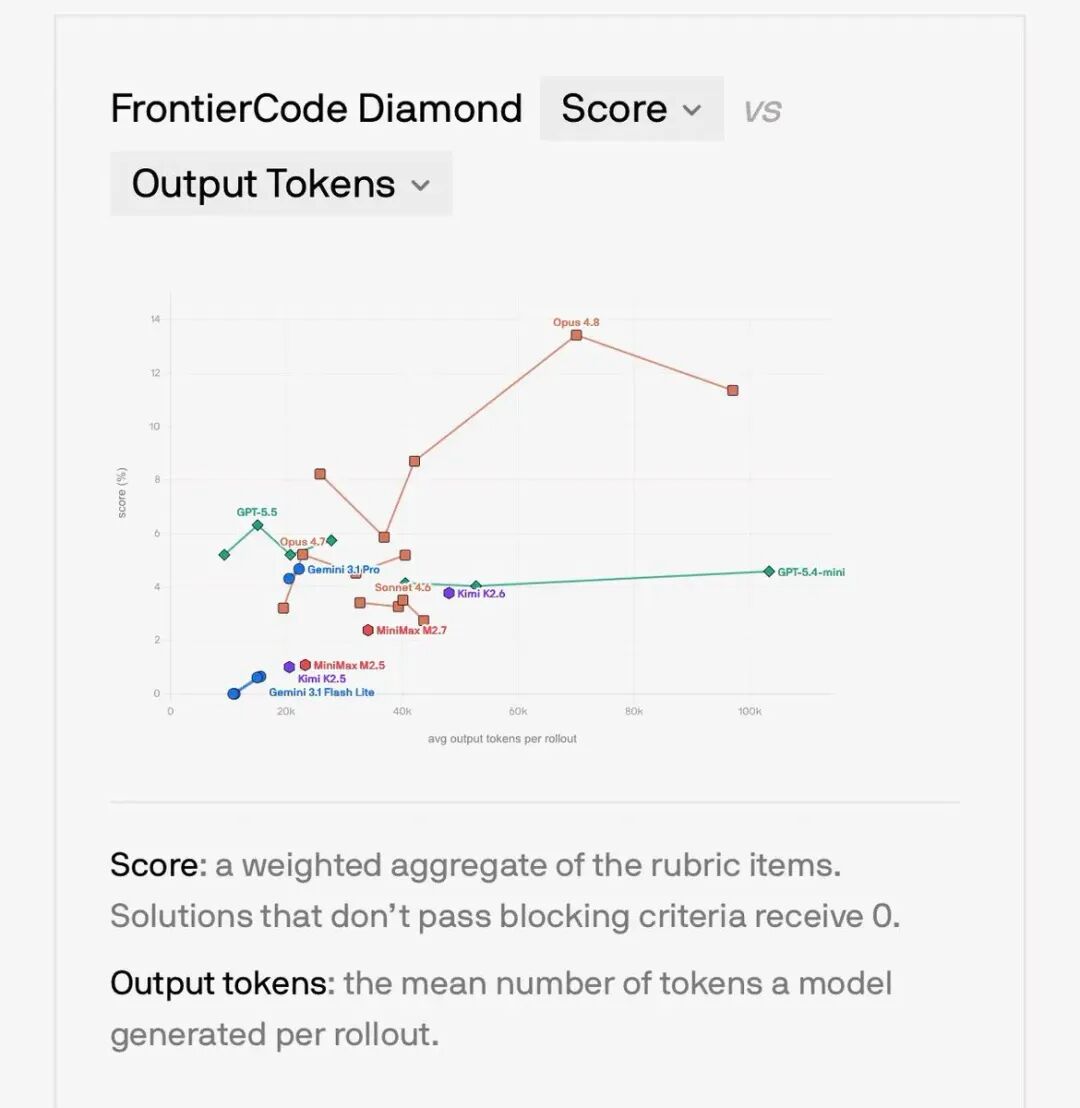
Diamond的成绩,我列一下。
Claude Opus 4.8,13.4%。
GPT-5.5,6.3%。
Gemini 3.1 Pro,4.7%。
Kimi K2.6,开源最强,3.8%。
我反复看了好几遍。
13.4%。最强的模型,在最难的题目上,没超过15%。
而且这不是那种,我故意把题出得超级难谁也做不出来的基准。每一道题都是从真实开源项目里提炼的真实任务。是有标准答案的,那些开源项目维护者自己也能写出来、能通过、能合并。
AI不是跟别的AI比,是跟真人的水平比。
这一比,差距就出来了。
当然,在Extended这个简单的级别上,Opus 4.8能拿到51.8%。也就是说一半以上的常规任务,AI已经能产出可合并的代码了。这本身也是一个很猛的里程碑。
但一上难度,断崖式下跌。
还有一个我觉得特别有意思的数据。GPT-5.5虽然只有6.3%,但它用的token是Opus 4.8的四分之一。
什么意思呢。
如果换算成性价比,GPT-5.5可能是最适合给普通开发者日常用的模型。质量不是最高的,但跑得快、成本低,日常任务够用。
这就引出了一个更现实的问题。在真正的生产环境里,你到底要的是最高质量,还是最高性价比。
这个问题的答案,可能每个团队都不一样。
我开始想另一个层面的东西。
FrontierCode的出现,其实标志着一个更大的转变。
我回想了一下AI编程benchmark的进化史,还挺有意思的。
最早是HumanEval,2021年OpenAI搞的。164道题,给你一个函数签名和一段说明,你把函数体写出来,能通过单元测试就算对。那时候能做到70%就已经封神了。
然后是SWE-Bench,进化了一步。不再让你写单个函数了,而是给你一个真实仓库里的真实issue,让你去修。这是从写代码到修代码的跨越。
接着有了DeepSWE、SWE-Bench Verified这些变体,层层堆叠。
但所有这些基准,共享同一个底层逻辑。只要测试通过了,你就对了。
FrontierCode打破了这一点。
它说,不行,还不够。你不仅要写对,还要写得符合这个项目的规范,写得经得起代码审查,写得让一个跟你没有私人关系的陌生人愿意点下那个Merge按钮。
这个转变,特别像应试教育和素质教育的区别。
HumanEval是选择题,答案对就给分。SWE-Bench是简答题,答到点上就给分。
FrontierCode是论文答辩。内容要对,格式要对,引文要对,逻辑要对,还要经得起导师的灵魂拷问。
而我们最强AI模型,在这套素质教育体系下,得分只有13.4%。
这个数字很扎眼,但我觉得是好事。
为什么。
因为只有当我们不再用简单的标准来衡量AI时,AI才有机会去突破简单的天花板。
你看看ImageNet的历史。准确率从70%涨到95%之后,整个计算机视觉领域开始反思一件很重要的事。准确率真的是唯一指标吗。这个反思催生了更复杂的评估体系,最终把整个领域往前推了一大步。
AI编程也一样。当所有模型都在HumanEval上刷到90%多的时候,这个基准已经失去了区分度。今天Claude和GPT都95%,明天Gemini也95%,大家看起来差不多得很,进步的边际越来越小。
你需要一个新的、更难的、更多维度的基准,来重新拉开差距。
FrontierCode就是这个新基准。
而且它带来的压力是很具体的。模型开发者现在不仅要优化能不能写对,还要优化写得好不好。这种压力会倒逼整个行业往前走。
回到我自己。
说真的,看到13.4%那个数字之后,我反而更踏实了。
不是因为AI不行,而是因为我现在更清楚地知道它到底哪里不行了。
知道短板在哪,比不知道要好一百倍。
作为一个天天用AI写代码的人,我的体感是这样的。在日常的、中等复杂度的任务上,Claude Code和Cursor已经帮我省掉了至少一半的时间。写测试、写样板代码、debug常见错误,这些它们干得特别好。
但在那些真正需要工程判断力的地方。一个类的设计是不是合理,一个接口的抽象层级对不对,一个改动对未来的影响。这些地方,AI还差得很远。
而这个差距,以前是模糊的。我只能凭一种,总觉得哪里不太对的体感去感受,说不清楚,也验证不了。
FrontierCode把这个差距量化了。
13.4%。
这就是当前最强AI在写出可合并代码这件事上的真实水平。
不高,但够真实。比那些九十几的注水分数,有价值得多。
我有时候觉得,AI的发展速度其实没有我们想象的那么快。
并不是今天还在画火柴人,明天就写出了一部红楼梦。每个领域的进步都是阶梯式的,需要一步一个脚印地去翻越。
HumanEval是一个台阶,SWE-Bench是一个台阶。
现在FrontierCode是下一个。
而这个台阶,说实话,还挺高的。
但换个角度想,这不也正是最让人兴奋的地方吗。
前方还有86.6%的巨大空间,等着被填满。
我们正在见证的,不是AI编程的终点,而是一段漫漫长路的开始。
大时代啊,朋友们。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
