 夜雨聆风
夜雨聆风本文是《把 AI 关进笼子,让它替我合并一万个文件》系列第 3 篇。
你的 fork 里有一段企业定制的认证逻辑。半年前为了防 XSS,你特意把 token 从 localStorage 挪进了 HTTP-only Cookie,还在旁边留了一行注释:“企业安全要求,防止脚本偷 token”。
这次合并 upstream,AI 扫到这个文件,发现上游改得挺多。它大手一挥:整文件采用 upstream 版本。你的定制,没了。代码还能跑,测试还绿,PR 看着漂漂亮亮,“合并完成”四个字闪着自信的光。
三个月后线上出事,你才想起来:那行注释当初是怎么写的来着?
AI 没有“丢失感”——它不知道自己在丢东西
这是整个系列的母题,也是这篇要正面硬刚的那个核心恐惧。
第 2 篇我们聊了“谁来审、怎么制衡”——让执行官闷头干活、审判官冷面找茬,两个 AI 互相不留情面。但你可能会问:审判官也是个 LLM 啊,它凭什么比执行官更靠谱?它会不会也看漏?
会。所以这一篇我要把审判官手里那把真正的刀亮出来——它最锋利的武器,根本不是 LLM 的“判断力”,而是一排冷冰冰的确定性工具。
这套系统的信条很轴,就一句话:
LLM 负责理解语义,工具负责证伪。
工具说“你丢了”,AI 再能解释也没用。这叫 VETO——一票否决。但这票否决权不握在任何一个 LLM 手里,它握在一堆纯 Python 写的扫描器手里。工具说不行,就是不行,不接受 AI 狡辩。
“不丢失”这件事,靠 AI 自觉是幻想。它得靠两根支柱撑着:事前画地图(决定哪些能自动合、哪些必须送人工),和事后证伪(六种丢失套路,逐一拿确定性工具去抓现行)。下面分开说。
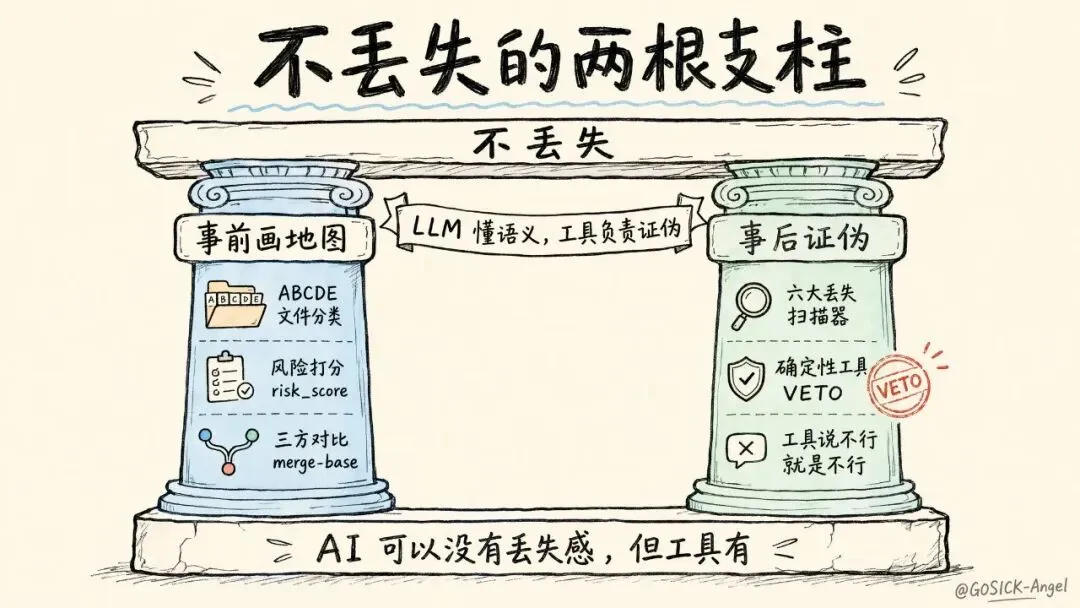
支柱一:事前画地图——没带地图就别进原始森林
我在第 1 篇讲过那个最惨的坑:第一周没建地图就出发,一周后一统计,前端漏合 1107 个文件、后端漏合 867 个,约等于白干。
所以现在第一件事永远是给每个文件贴通行证颜色。这活儿在系统里叫文件分类器(file_classifier.py),它给每个有差异的文件贴一个 ABCDE 标签:
| A | ||
| B | ||
| C | ||
| D | ||
| E |
分类只解决“这是什么文件”,还不够。系统接着给每个文件算一个危险系数——就像机场安检,按行李可疑程度分流,越可疑越要开箱。这个数叫 risk_score(风险分),0 到 1,越高越可能出事。
风险分怎么算:五个因素加权
别以为这分是 LLM 拍脑袋给的。它是一个写死的加权公式,每一项都能复现:
注意冲突密度权重最高(0.35)——两边在同一片区域里互相踩,这是最容易丢东西的地方。
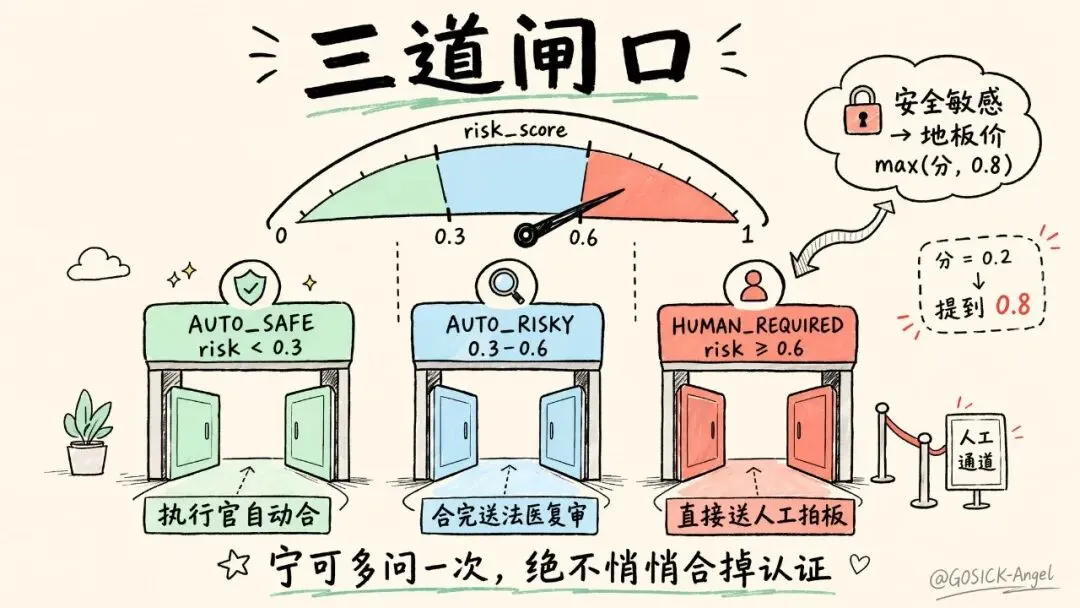
分级路由:三道闸口
算完分,文件就被分进不同的 RiskLevel(风险等级),决定它走哪条路:
• AUTO_SAFE( risk < 0.3):低风险,执行官自动合,过完批次审查就放行。• AUTO_RISKY( 0.3 ≤ risk < 0.6):中风险,执行官先试着合,合完必须送冲突分析师(那个“法医”)复审。• HUMAN_REQUIRED( risk ≥ 0.6,或安全敏感):高风险,根本不进执行官,直接生成一张人工决策单,挂起等你拍板。
这里有个我特别想强调的细节——安全敏感文件的“地板价”。
只要一个文件命中了安全敏感规则(比如认证、加密、权限相关),它的风险分会被强行抬到 max(原分, 0.8)。哪怕公式算出来只有 0.2,也会被顶到 0.8,直接进 HUMAN_REQUIRED。
为什么这么狠?回到开篇那个 Cookie 认证。宁可多打扰你一次,绝不悄悄帮你合掉一段认证逻辑。 多问一句,最多浪费你三十秒;合错了,是线上 XSS。这笔账,系统替你算过了。
(顺带一提,还有 DELETED_ONLY 纯删除、BINARY 二进制、EXCLUDED 排除项这几类——锁文件、node_modules 这种直接跳过不浪费算力,纯删除则一律拉去问人”这个真要删吗”。)
三方对比:把案发前的现场也调出来
地图还有最后一块拼图,也是整个判断的基石:三方对比。
大多数人(和大多数 AI)看冲突只看“两边 diff”——你的版本 vs upstream 的版本。这就像庭审只听原告被告各说一句话,谁也不知道争的到底是不是同一件事。
正确的做法是同时调出三个版本:共同祖先(merge-base,也就是案发前的现场)、upstream 版本、你当前分支的版本。
MERGE_BASE=$(git merge-base HEAD upstream/main)git show "$MERGE_BASE":path/to/file > /tmp/basegit show upstream/main:path/to/file > /tmp/upstreamgit show HEAD:path/to/file > /tmp/currentdiff3 /tmp/current /tmp/base /tmp/upstream把“案发前现场”调出来,你才知道是谁动的、为什么动。
我合并时碰到过一个函数:upstream 重构了它,我也改了它(加了企业功能)。只看两边,感觉冲突复杂到想关电脑。三方一看——upstream 改的是上半段,我改的是下半段,根本不冲突,直接两边都留就行。
反过来也成立:只看两边,你会把“其实没事”误判成“大冲突”;也会把“真的丢了”看成“没事”。三方对比,是“不丢失”的判断底座。
支柱二:事后证伪——六种偷偷丢功能的套路
地图画好、文件合完,是不是就稳了?不。执行官是个闷头干活、不爱回头检查自己漏了啥的实习生。它合完一句“完成”,但它真不知道自己丢了什么。
所以审判官登场。它的第一关不是 LLM,是一条确定性流水线——六个扫描器,专治六种 AI 抓不住、工具能抓住的丢失套路。任何一个扫描器报警,直接 VETO,不商量。
我给它们起了俗名,一个一个讲清楚治什么病。
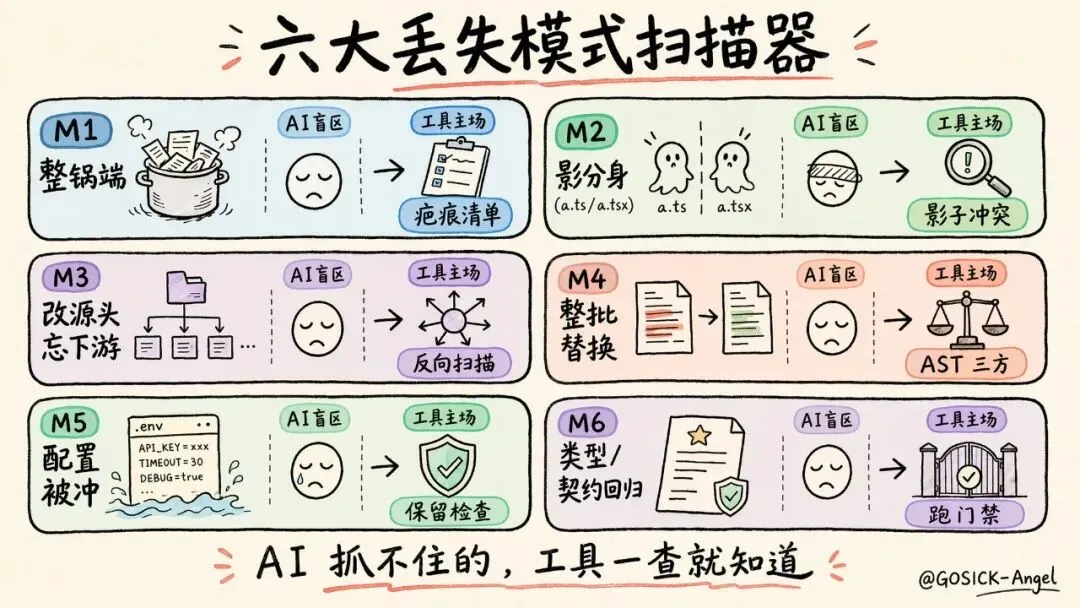
M1 · “整锅端”——定制被整文件覆盖
套路:upstream 改了一个文件,AI 嫌逐行合麻烦,整文件采用 upstream 版本。你 fork 里那段定制,连汤带肉一起被端走了。开篇那个 Cookie 认证就是死在这儿。
为什么 AI 抓不住:LLM 不知道这个文件的历史。它不知道半年前你专门写过一个 commit 把这段逻辑 restore 回来过。这段历史,对它是个盲区。
怎么治:scar_list_builder(疤痕清单)。系统会从 git 历史里挖出那些 restore / 兼容修复 / revert 的痕迹——这些“疤痕”标记着“此处曾有定制,且曾被覆盖、又被救回”。合并后一旦发现疤痕对应的代码又没了,立刻报警。
M2 · “影分身”——同名不同扩展名的隐形撞车
套路:a.ts 和 a.tsx 同时存在;或者 upstream 把目录结构调了,utils/foo.js 搬成了 utils/foo/index.js。git 和 LLM 都把它们当成两个毫不相干的文件,结果一个旧的一个新的并存,运行时到底加载哪个全凭玄学。
这种叫影子冲突(shadow conflict)——同名不同后缀、或目录布局变化造成的隐形撞车。
为什么 AI 抓不住:在 LLM 眼里 a.ts 和 a.tsx 就是两个不同的字符串,它没有“这俩其实是同一个模块的两个分身”的概念。
怎么治:shadow_conflict_detector(影子冲突探测器)。它专门按一套命名/布局规则去配对这些“影分身”,揪出并存的隐形冲突。
M3 · “改了源头忘了下游”——接口变了,调用方没跟上
套路:upstream 把一个函数的签名改了,比如多加了个必填参数。AI 老老实实把这个函数本身改对了——然后就完事了。但项目里还有十几处在调用这个函数,那些调用方一个都没改。编译/类型检查这才开始哭。
为什么 AI 抓不住:LLM 只盯着 diff 给它看的那几个文件。它不会主动反向 grep——不会回头去搜“到底谁在调我这个函数”。这一步它经常忘,因为它的注意力只在“眼前这块改动”上。
怎么治:两个工具搭配。interface_change_extractor(接口变更抽取器)先识别出“哪些函数/接口的签名变了”,然后 reverse_impact_scanner(反向影响扫描器)反过来 grep 整个代码库——谁在调它?这些调用方同步改了吗?工具不会忘,因为反向扫描本来就是它存在的全部理由。
M4 · “整批替换”——顶层注册/调用被一锅换掉
套路:一个模块顶层有一长串 register_route(...) / app.use(...) 这类注册调用。AI 在合并时把这一整块换成了 upstream 的版本,你 fork 里额外注册的那几条路由,悄无声息消失。
为什么 AI 抓不住:这种丢失发生在“整块被替换”的粒度上,单看某一行没问题,整块对比时 LLM 又容易当成“upstream 重写了这块,那就用它的”。
怎么治:three_way_diff(三方差异,AST 级别)。它不是行级 diff,而是在语法树层面做三方对比——能看出“你这边有 5 条注册、upstream 有 8 条、合并结果只剩 8 条”,那你独有的那几条去哪了?报警。
M5 · “配置必保留行被冲掉”
套路:你的 Dockerfile、docker-compose.yaml、CI 配置里有几行是企业环境的命根子(某个内网源、某个必须设的环境变量)。upstream 更新了配置文件,AI 采纳上游版本,你那几行命根子没了。代码层面毫无察觉,部署时直接炸。
为什么 AI 抓不住:哪些配置行“必须保留”,是你的业务知识,不是代码里能读出来的。LLM 没这个先验。
怎么治:config_line_retention_checker(配置行保留检查器)。你在配置里声明“这些行/模式必须存在”,合并后它逐条核对保留率,少一行报警一行。
M6 · “类型/API 契约回归”——它不会主动跑 tsc
套路:合并后,整个项目的类型契约悄悄破了。函数返回类型对不上、import 路径失效、API 形状变了。我自己手工合那次,前端合完一跑 type-check,蹦出来 1367 个类型错误。
为什么 AI 抓不住:LLM 不会主动去跑 tsc、跑 pytest。它读 diff、它推理,但它不会真的执行一遍编译器。而编译器是唯一能 100% 确定“契约破没破”的东西。
怎么治:gate_runner(门禁执行器)配上可插拔的 baseline 解析器。它真的去跑 tsc / pytest / mypy,然后解析输出。
这里有个让我特别舒服的设计——baseline-diff 门禁:它只盯这次新引入的错误。仓库里原本就有的 100 个旧错误,不算你头上;只有这次合并新增的才会拦你。免得你被存量历史债卡死,根本动不了。
我手工那次的前端,就是靠这种“只追增量”的门禁,把 1367 个类型错误分八个阶段、一点点干到了 0。每个阶段干净通过再往前走,绝不带着烂账前进。
为什么“工具能逮住 AI 逮不住的”
把上面六条串起来,你会发现 AI 的盲区高度一致,全是同一类毛病:
scar_list_builder | |
shadow_conflict_detector | |
reverse_impact_scanner | |
three_way_diff | |
config_line_retention_checker | |
tsc / pytest | gate_runner |
LLM 的强项是”理解语义”——读懂这段代码想干嘛。但历史、反向引用、跨文件一致性、真实编译结果这四样,是确定性工具的主场。让 LLM 干它擅长的,让工具补它结构性的盲区,两边各管各的,这比”再加一个审查 LLM”稳 10 倍、便宜 100 倍。
一个彩蛋:可插拔解析器 = “零仓库知识”
刚才说 M6 用了“可插拔 baseline 解析器”。这背后是这套系统一条很硬的原则——源码里不许出现任何项目专属知识。
Python 项目用 pytest / mypy 的解析器;Go 项目加一个 go_test 解析器;Rust 项目加 cargo_test。加新语言不用改系统一行源码,靠 entry_points 插件挂进去就行。
换句话说,这套“证伪”机制不绑死任何语言、任何仓库。它对你的项目一无所知——所有项目专属的东西,都从 YAML 配置喂进去,而不是焊死在代码里。这条原则怎么贯穿全系统、怎么把它做成“给同行的工程手艺”,我留到第 6 篇细讲。
小结:让工具替 AI 证伪它自己看不见的丢失
回到开篇那行 Cookie 注释。在这套系统里,它的命运会完全不同:
1. 文件命中安全敏感规则 → 风险分被顶到 0.8 → 直接送你人工拍板,根本不会被 AI 自动合掉; 2. 就算它侥幸没被识别为敏感、被 AI 合了 → scar_list_builder发现这段定制曾被 restore 过、现在又没了 → VETO;3. 就算疤痕也漏了 → gate_runner跑一遍门禁,类型/契约一破 → 还是 VETO。
三道闸,环环咬死。AI 可以没有“丢失感”,但工具有。 这就是把它关进笼子的核心手艺:不指望 AI 自觉,而是让一排确定性扫描器替它证伪——你说你合好了?工具核一遍再说。
这套东西已经开源,包名 code-merge-system:
pip install code-merge-systemmerge upstream/main --dry-run # 先只画地图、只看计划,一个文件都不动--dry-run 会把上面那张风险地图、ABCDE 分类、六大扫描的结果全列给你,但不写任何文件——先看看它眼里你的 fork 长啥样,再决定要不要让它动手。首次运行会弹个浏览器向导带你配好。觉得哪个扫描器逻辑不对、或者你那门语言的解析器还没人写,欢迎来 GitHub 拍砖、提 issue。
下一篇我们聊聊怎么让每一步都不可逆地踩实——执行官动手前为什么必须“先存档再打 Boss”,干砸了怎么瞬间读档回滚。
