 夜雨聆风
夜雨聆风这篇是对上篇技术选型的补充AI产品经理核心工作流程---技术选型
全景地图:AI 产品经理要做的技术方案选择
知识检索 | |
Agent架构 | |
多Agent | |
能力接入 | |
存储选型 | |
模型调用 | |
部署架构 | |
框架工具 | 低代码平台: Dify/Coze/FastGPT |
安全合规 |
一、知识检索方案选型(RAG 类型)
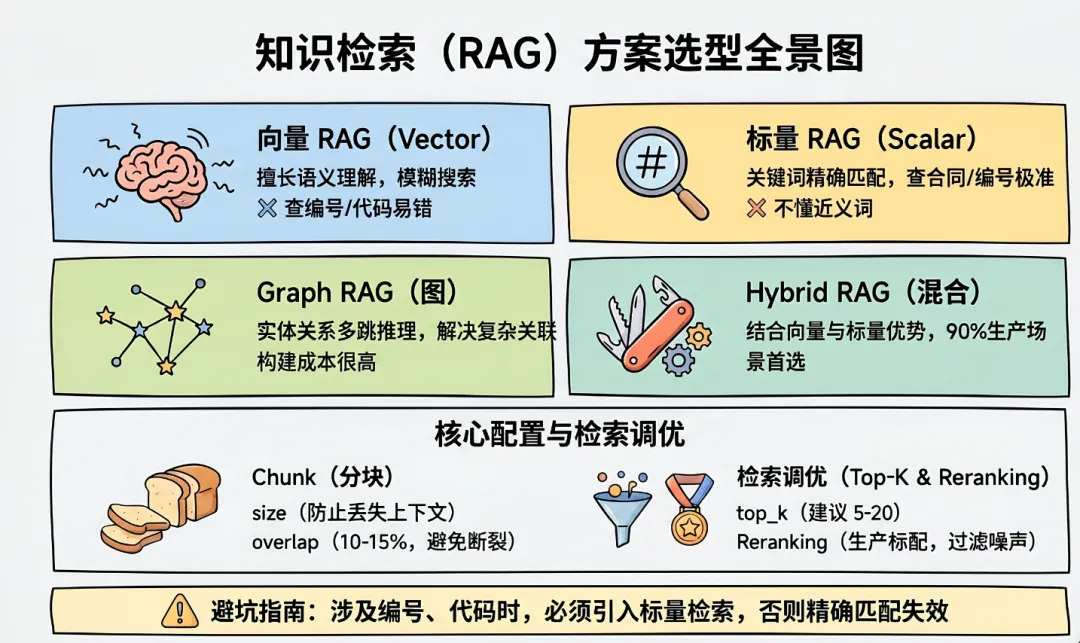
1.1 几类 RAG 的核心差异
| 向量 RAG | ||||
| 标量 RAG | ||||
| Graph RAG | ||||
| Hybrid RAG |
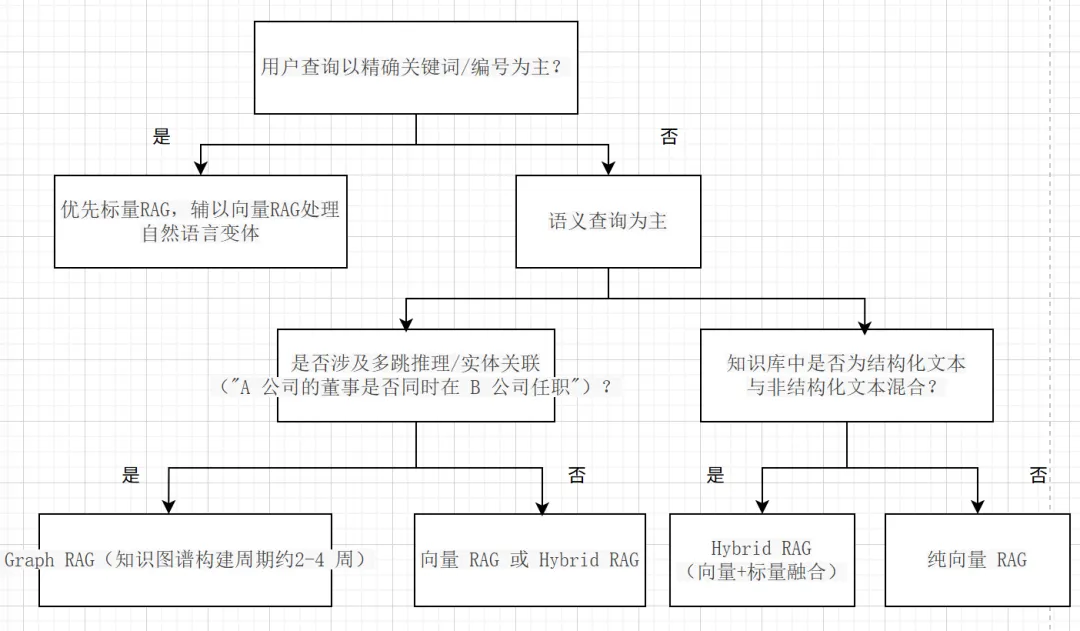
1.2 选型判断树
1.3 业务场景对应方案
| 客服知识库问答 | ||
| 法律合同审查 | ||
| 企业内部合规问答 | ||
| ICP 备案知识库 | ||
| 代码仓库文档检索 | ||
| 医疗病历知识问答 | ||
| 电商商品推荐语义检索 |
1.4 产品经理需了解的 RAG 配置参数
Chunk 策略:- chunk_size:分块大小,太小丢上下文,太大引入噪声- overlap:相邻块重叠,建议 10-15%,避免语义在边界断裂- 分块方式:按句子/段落/语义/固定长度,不同文档类型策略不同检索参数:- top_k:召回候选数量,生产环境建议 5-20,太多引入噪声,太少漏召关键信息- 重排(Reranking):粗召回后通过 Cross-Encoder 模型对候选结果做精准二次排序,优化内容相关性与逻辑顺序,线上生产场景建议标配启用,显著提升问答准确率- 相似度阈值:低于阈值的结果不注入 Prompt,避免垃圾召回产品经理控制点:chunk 策略和 top_k 是产品经理可以提业务需求的参数1.5 常见错误
1、用纯向量 RAG 处理编号/代码查询向量模型把"合同编号A20240101" 和"A20240102" 的相似度打得很高,导致精确检索失效;
2、不做 Reranking 直接把 top-20 全塞进 Prompt 召回 20 条但只有前 3 条相关,模型被后 17 条噪声干扰,回答质量反而下降,且 token 消耗翻 5 倍;
3、Graph RAG 选型后低估构建成本,知识图谱从零构建,1 万条文档可能需要 2-4 周(含实体抽取、关系标注、图谱校验),需注意项目的里程碑时间表;
二、Agent 架构选型
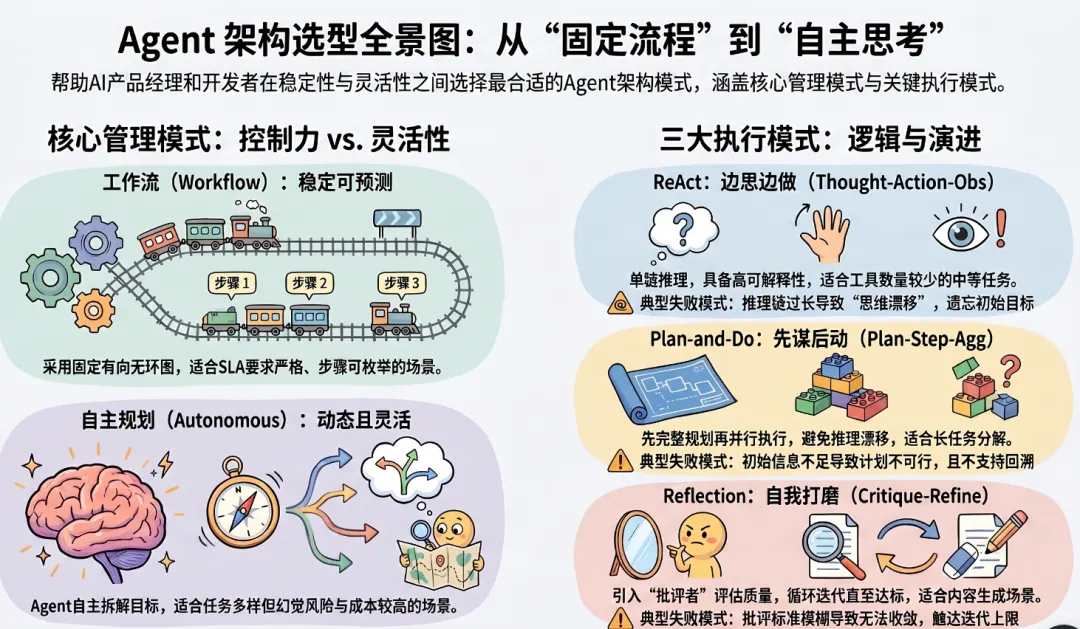
2.1 两大核心模式
| Workflow 工作流 | |||
| 自主规划 |
2.2 三大执行模式详解
ReAct(Reasoning + Acting)
流程:Thought → Action → Observation → Thought → Action → ...特点:- 每一步先思考(Thought),再执行(Action),观察结果(Observation)后继续- 思考过程可追溯,便于调试和问题定位- 单链推理,不支持并发工具调用适用场景:- 单任务链式推理(查信息→处理→输出结果)- 需要可解释性的场景(金融/医疗/合规)- 工具数量 < 10 的中等复杂度任务典型失败模式:推理链过长导致"思维漂移",前几步的上下文被遗忘,越往后越偏离原始目标Plan-and-Do(规划后执行)
流程:Plan → Step1 → Step2 → Step3 → Aggregate特点:- 先完整规划,再按计划执行,不在执行中修改计划- 规划阶段可以并行化步骤- 适合长任务分解,避免 ReAct 的中途漂移适用场景:- 研究报告生成(先列提纲,再逐节撰写)- 多步骤数据处理(先设计执行步骤,再执行)- 需要跨多个数据源整合的分析任务典型失败模式:计划制定时信息不足,导致后续执行发现计划不可行,需要回溯重规划(但 Plan-and-Do 不支持回溯)Reflection(反思迭代)
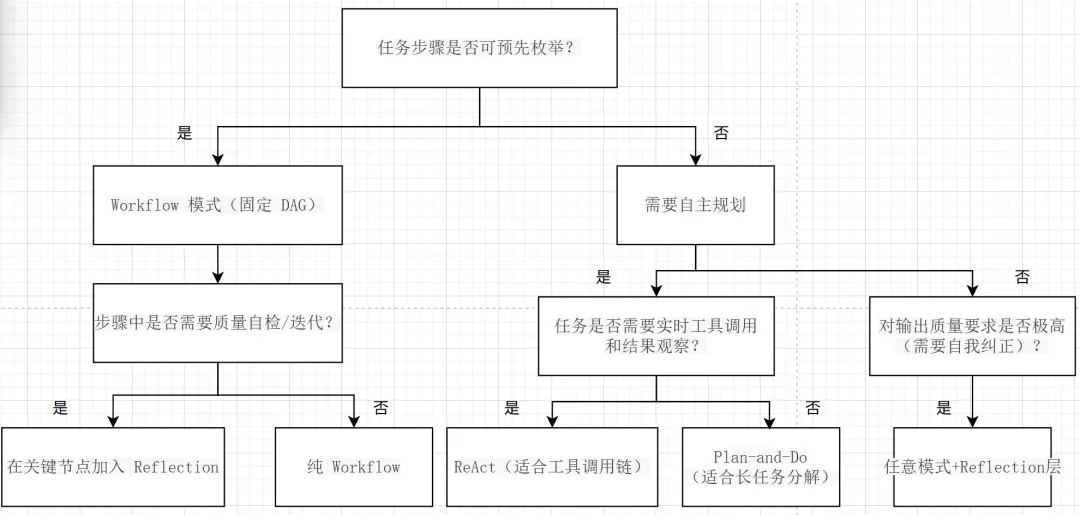
流程:Execute → Critique → Refine → Execute → ...特点:- 执行后有专门的"批评者"评估输出质量- 输出不满足标准时自动触发修改迭代- 可以配置最大迭代次数(防止死循环)适用场景:- 内容生成(文案/报告/代码),需要质量自检- 数据清洗(初次处理后自检格式/完整性)- 翻译/改写(反复修改直到满足风格要求)典型失败模式:批评标准定义模糊,导致 Reflection 无法收敛,触达最大迭代次数仍未满足质量要求2.3 Agent 选型判断树
2.4 能力接入方式:Skill vs MCP vs Function Calling
这是 AI 产品经理高频面对但缺乏系统认知的选择点。
| Function Calling | |||
| Skill | |||
| MCP | |||
| Plugin |
核心判断原则:
1)单 Agent 调用少量工具 → Function Calling,最简单
2)多 Agent 共享同一批能力 → Skill,避免重复开发
3)多 Agent 异构协同、跨系统调度 → MCP,统一协议
4)向外部开放能力/接入外部能力市场 → Plugin
三、Multi-Agent 架构选型
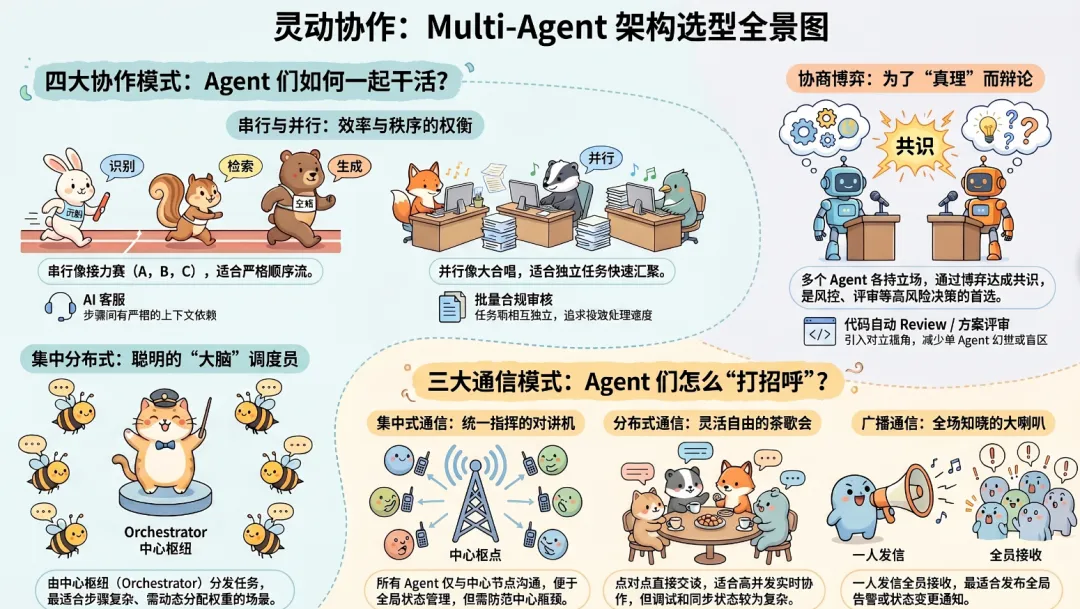
3.1 四种协作模式
| 串行 | |||
| 并行 | |||
| 集中分布式 | |||
| 协商博弈 |
3.2 通信模式选型
| 集中式通信 | |||
| 分布式通信 | |||
| 广播通信 |
3.3 Multi-Agent 选型判断
任务是否可以并行分解(子任务之间无数据依赖)?├── 是 → 并行模式,主 Agent 汇聚结果└── 否 → 有依赖顺序 ├── 步骤数 ≤ 5,依赖关系清晰? → 串行模式 └── 步骤复杂,需动态任务分配? → 集中分布式(Hub-Spoke)对结论可信度要求极高(如风控决策、合规审查)?└── 是 → 在最终决策节点引入协商博弈模式(2-3 个 Agent 各自独立评估)3.4 业务场景对应方案
| AI 客服 Agent | ||
| 投资研报生成 | ||
| 代码自动 Review | ||
| 运营调度平台 | ||
| ICP 备案批量审核 |
四、存储与检索架构选型
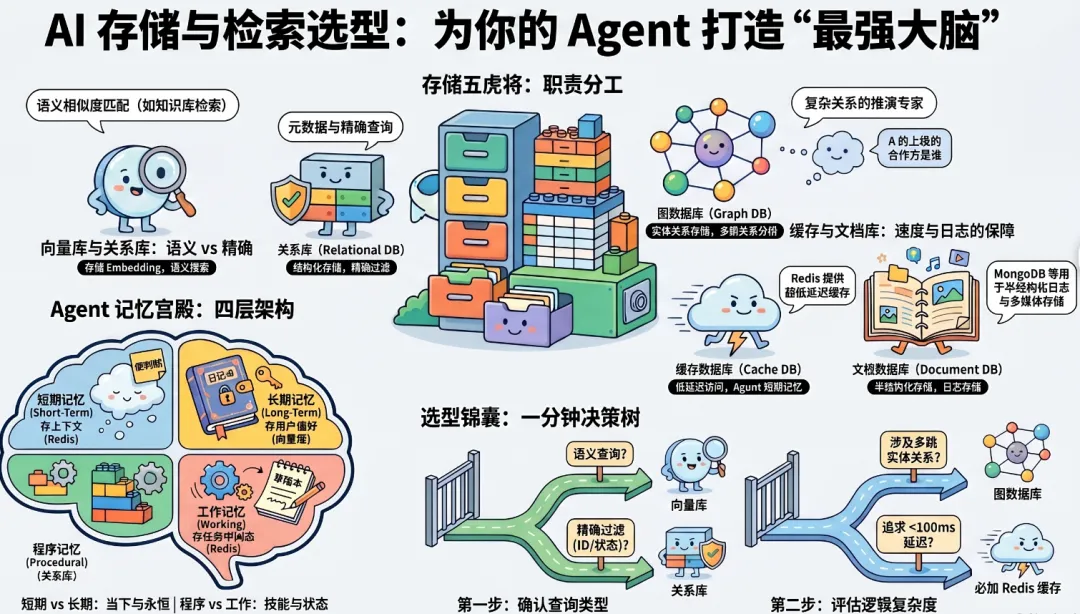
4.1 五类存储的职责分工
| 向量数据库 | |||
| 关系型数据库 | |||
| 图数据库 | |||
| 文档数据库 | |||
| 缓存数据库 |
4.2 Agent 记忆架构选型
Agent 的记忆系统是 AI PM 容易漏设计的核心组件:
| 短期记忆 | |||
| 长期记忆 | |||
| 程序记忆 | |||
| 工作记忆 |
4.3 选型判断要点
问题是语义查询("帮我找关于退款的规定")?└── 是 → 向量数据库必选查询中涉及精确过滤(用户ID + 时间范围 + 状态)?└── 是 → 关系型数据库必选,可与向量库组合使用查询涉及多跳关系推理("A 的上级是谁的合作方")?└── 是 → 图数据库高频读取,延迟要求 < 100ms?└── 是 → 加 Redis 缓存层,不要直接查向量库/关系库五、模型调用方式选型
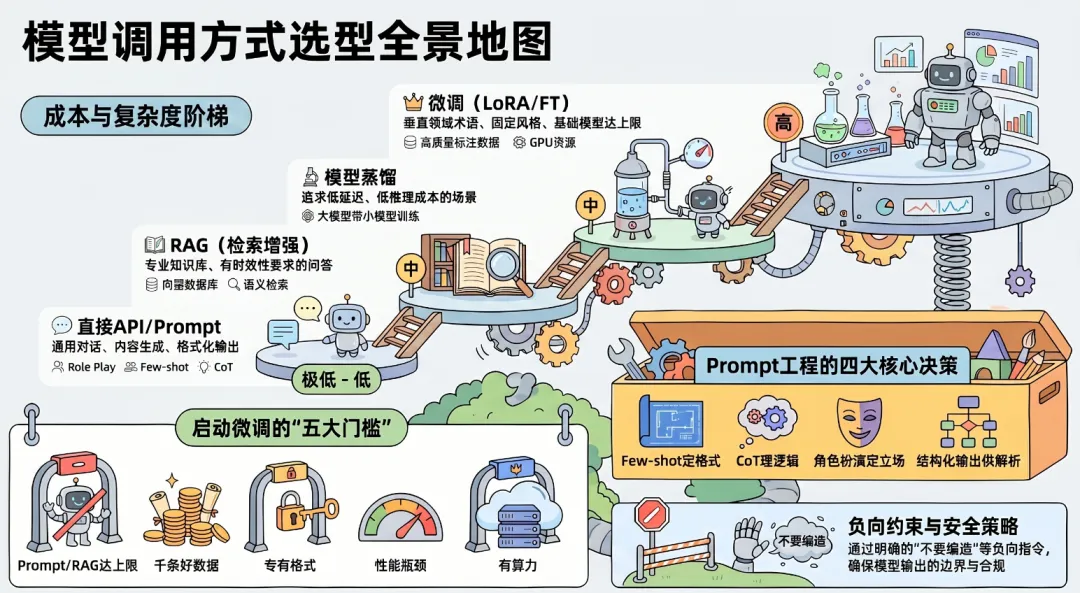
5.1 四种调用策略
| 直接 API 调用 | |||
| Prompt Engineering | |||
| RAG 增强 | |||
| Fine-tuning 微调 | |||
| 蒸馏 | |||
| LoRA/PEFT 参数高效微调 |
5.2 微调决策门槛
微调启动的判断条件(需要同时满足 3 项以上):
5.3 Prompt 工程核心决策
| Few-shot | ||
| Chain-of-Thought(CoT) | ||
| 角色扮演 | ||
| 结构化输出 | ||
| 负向约束 |
六、部署架构选型
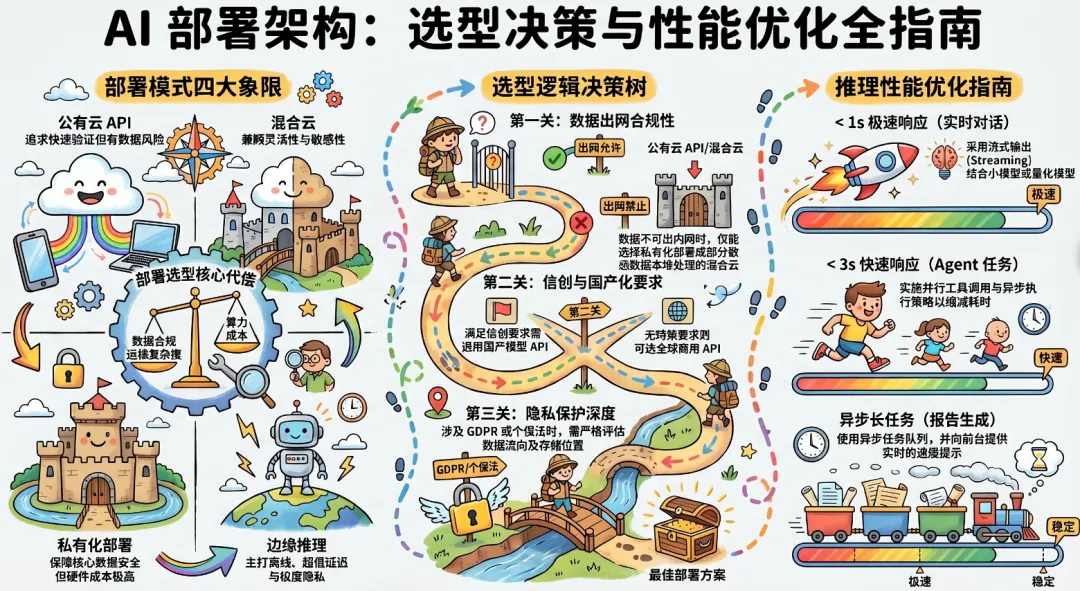
6.1 四种部署模式
| 公有云 API | |||
| 私有化部署 | |||
| 混合云 | |||
| 边缘推理 |
6.2 部署选型决策树
数据是否可以出企业内网?├── 否 → 私有化部署(或混合云,非敏感部分用云)└── 是 → 是否有明确的信创/国产化要求? ├── 是 → 使用满足信创认证的国产模型公有云 API └── 否 → 可使用全球范围商用 API(GPT/Claude 等) 但需确认:数据是否涉及个人隐私(GDPR/个保法)?6.3 推理性能选型要点
七、框架与工具链选型
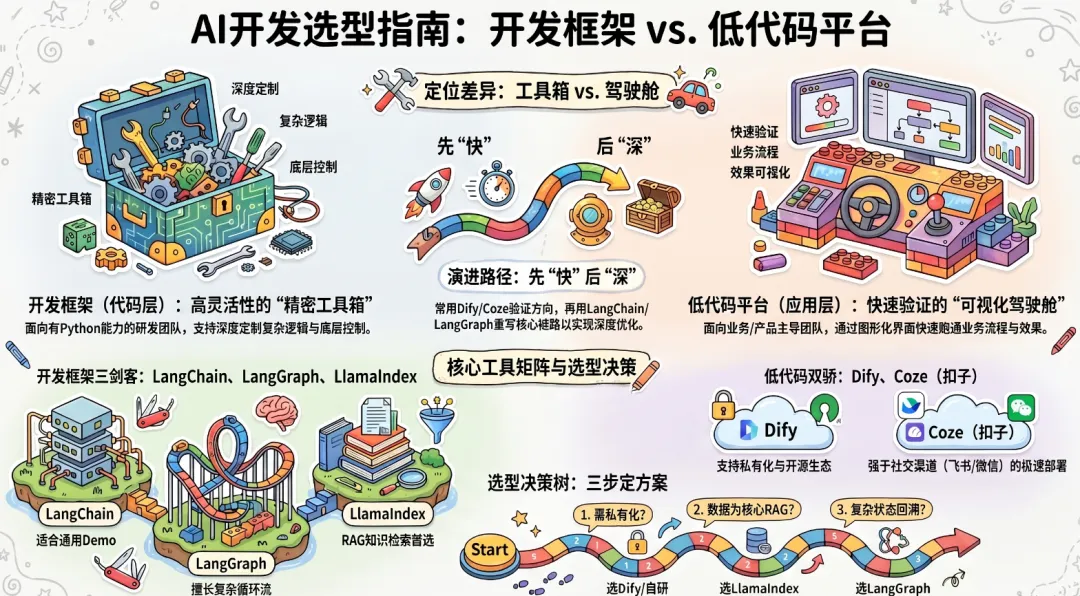
框架与工具链分两个层次:开发框架(代码层,工程师使用)和低代码平台(产品层,业务同学也可参与),两者不是竞争关系,而是面向不同技术能力和复杂度需求的不同选择,也是项目不同阶段验证效果的不同方式。
MVP 阶段优先用低代码平台快速跑通业务逻辑,验证效果后再评估是否需要迁移到开发框架做定制化深化。很多团队在 Dify/Coze 上验证了方向后,才决定要不要用 LangChain/LangGraph 重写核心链路。
7.1 开发框架选型
开发框架面向有 Python/工程能力的研发团队,适合对灵活性和定制性要求高的场景。
| LangChain | ||||
| LangGraph | ||||
| LlamaIndex | ||||
| AutoGen | ||||
| MetaGPT | ||||
| 自研框架 |
开发框架选型判断树:
核心场景是什么?├── 知识库/文档问答/RAG → LlamaIndex(数据处理能力最强)├── 通用 Agent/工具调用/快速 Demo → LangChain├── 复杂 Agent 工作流(有循环/条件分支/状态管理) → LangGraph├── Multi-Agent 协同(多角色协作/代码执行) → AutoGen├── 模拟软件开发团队流程 → MetaGPT└── 平台级/高度定制化/长期演进 → 自研框架(需充分评估成本)7.2 低代码 AI 开发平台选型
低代码平台面向业务团队主导、技术资源有限或需要快速验证的场景,产品经理和运营同学也能参与搭建和调试。
| Dify | ||||
| Coze(扣子) | ||||
| FastGPT | ||||
| 百炼/文心智能体 |
低代码平台选型判断树:
是否有私有化部署要求(数据不能出内网)?├── 是 → Dify(开源,支持私有化)或 FastGPT(知识库场景)└── 否 ├── 是否有国产化/合规要求? ├── 是 → 云厂商 Agent 平台(百炼/文心智能体等) └── 否 → Dify(灵活性和开源生态最佳)八、向量化(Embedding)模型选型
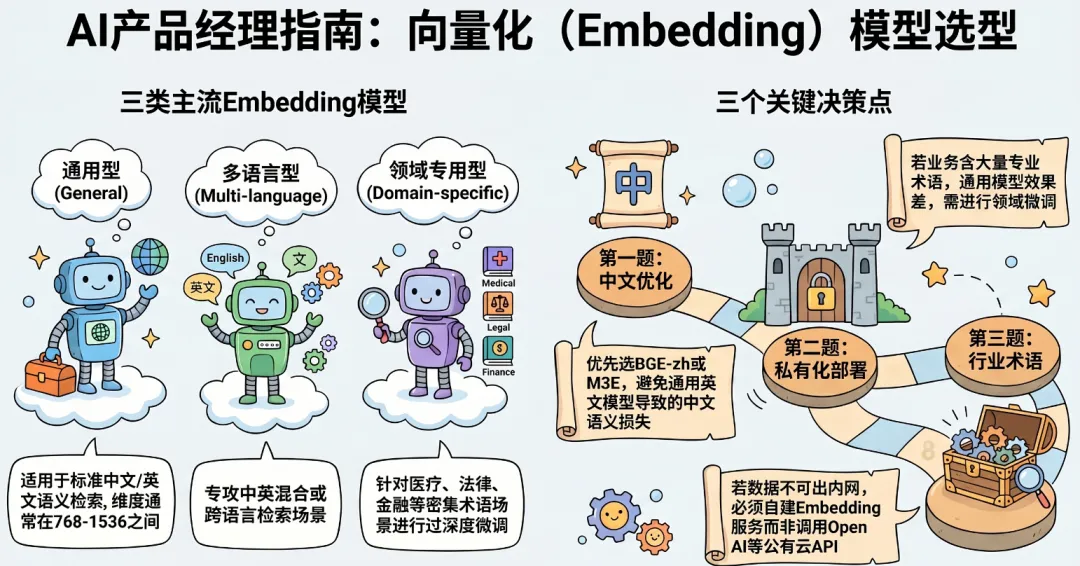
8.1 三类 Embedding 模型
| 通用 Embedding | |||
| 多语言 Embedding | |||
| 领域专用 Embedding |
8.2 关键决策
九、安全与合规架构选型
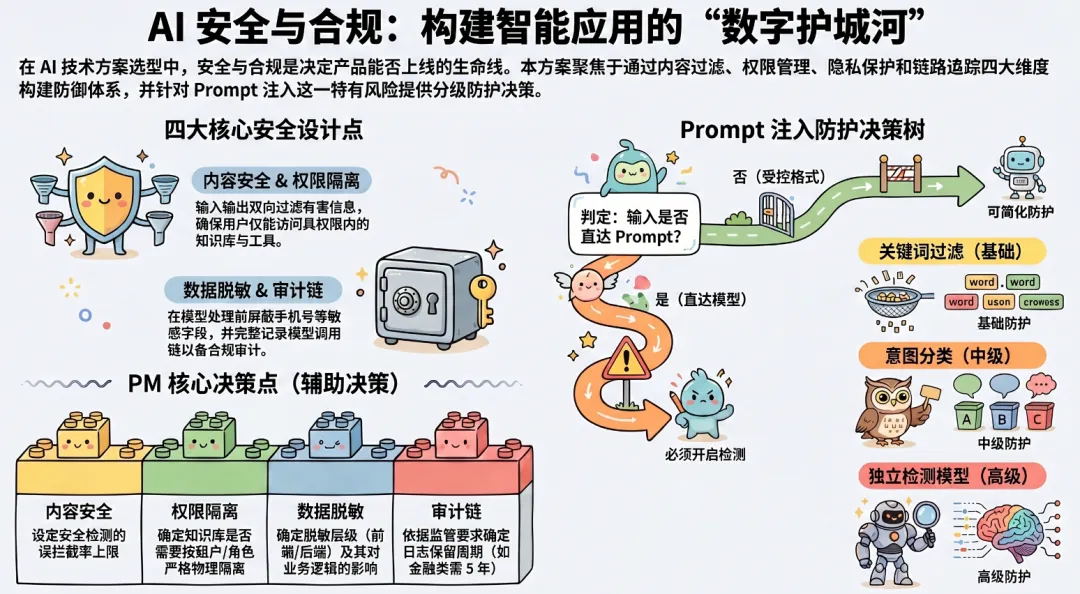
9.1 四个核心安全设计点
| 内容安全 | ||
| 权限隔离 | ||
| 数据脱敏 | ||
| 审计链 |
9.2 Prompt 注入防护决策
用户输入是否会直接进入 Prompt?├── 是 → 必须做 Prompt 注入检测(防止用户通过输入控制模型行为)│ - 简单方案:关键词过滤 + 长度限制│ - 中级方案:输入意图分类(正常请求 vs 攻击尝试)│ - 高级方案:独立安全检测模型 + 人工审核队列└── 否(输入来自内部系统/受控格式) → 可简化安全措施十、综合选型决策矩阵
当面对一个新 AI 功能需求时,PM 应该用这张矩阵快速定位需要决策的选型点:
十一、AI 产品经理的选型工作规范
11.1 选型文档应包含的内容
1. 背景与约束(合规/成本/工期/研发能力)2. 候选方案列表(不超过 3 个,已排除不合规/超预算方案)3. 评估维度与权重(效果/成本/工期/可维护性,权重需要与业务方对齐)4. POC 验证结论(必须有,不能只靠理论对比)5. 最终选型结论 + 放弃方案的原因6. 风险清单(如:向量库版本稳定性、微调数据质量风险)7. 回退方案(如果选型失败,备选方案是什么)11.2 产品经理在选型中的责任边界
提供清晰的业务约束(上线时间、数据范围、安全要求) 要求研发给出 2-3 个候选方案及 POC 数据 在效果验收标准上做决策(什么样的效果算"达标") 推动选型决策记录,不要停留在口头讨论
