 夜雨聆风
夜雨聆风arXiv新论文 · 可复现研究 · 编辑部AI治理
AI 时代,论文不只要给人看,还要让机器跑得起来
当 AI 智能体成为论文的新读者,科技期刊编辑部要重新理解可读、可复现和可验证。
主判断
AI 对学术出版的影响,不只在写作端,也会倒逼论文的证据链、补充材料和复现信息变得更可检查。
arXiv 近期更新了一篇和学术出版关系很近的预印本:Jiachen Liu 等人的《The Last Human-Written Paper: Agent-Native Research Artifacts》。
单看题名,容易把它理解成一篇关于“人类还会不会写论文”的文章。读完全文会发现,作者讨论的重点其实更贴近编辑部的日常工作:当科研智能体开始阅读论文、复现实验、检查证据、继续扩展研究时,传统 PDF 论文还能不能作为主要的科研交流载体。
这个问题已经不只属于计算机科学。过去,编辑部判断一篇稿件是否清楚,主要看审稿人能否读懂研究问题、方法路径、实验结果和结论边界。现在,多了一个新的读者:能够调用代码、追踪数据、比对实验步骤的 AI agent。它读论文时,会沿着正文继续追问:运行环境在哪里,参数表在哪里,数据版本能否定位,失败实验有没有记录,每个主要论断对应哪一份原始输出。
对编辑部来说,这意味着“可读”和“可执行”开始分开。稿件写得顺,不等于研究材料能被机器查下去、跑起来。
第 一 部分
传统论文丢掉了哪些复现线索
《The Last Human-Written Paper》提出的核心对象叫 Agent-Native Research Artifact,简称 ARA。可以译作“面向智能体原生的研究成果物”。它处理的重点,是研究成果交付给后续读者时,材料结构是否足够完整。
传统论文通常是一条线:引言提出问题,方法说明路径,实验展示结果,讨论解释意义。这种写法方便同行阅读,也方便期刊控制篇幅。可真实研究很少按这条线发生。一个项目里,经常有被否定的假设、没跑通的代码、后来放弃的参数组合、解释不住的数据点,以及中途改变方向的判断。
论文发表时,这些内容大多被裁掉。作者把这种从研究过程到发表文本的信息损耗称为 Storytelling Tax,直译是“叙事税”。研究过程被整理成一条顺畅的成功路径,失败路线和转向理由从正文里消失。人类读者读起来轻松,后续想复现或扩展的智能体却少了很多路标。论文中的这张图,把这种压缩关系画得很直观:左边是真实研究过程,右边是发表出来的线性故事。
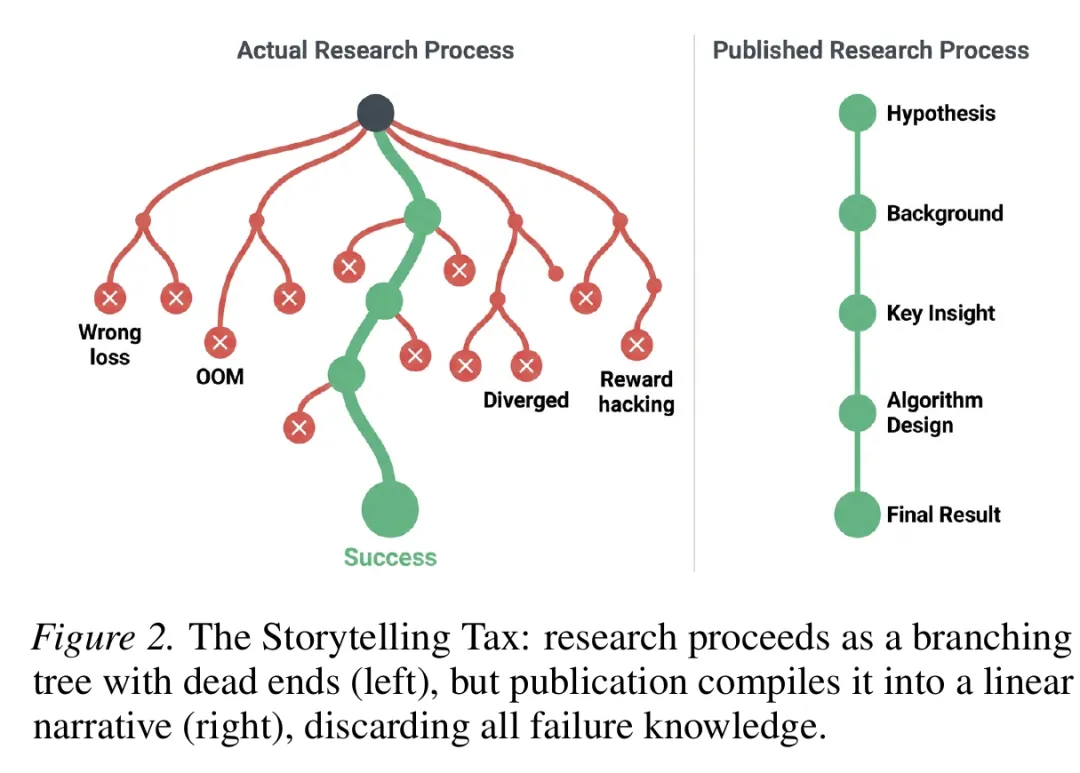
图 1 论文所谓“叙事税”:真实研究过程往往是分叉树,发表论文则被整理成一条顺畅路径。图源:Liu et al., arXiv:2604.24658v3。
另一项成本是 Engineering Tax,即“工程税”。很多论文已经写到足以让审稿人判断其方法和结果,却没有写到足以让机器执行。运行环境、依赖版本、核心超参数、评价协议、日志口径、代码入口、实验矩阵,这些细节在正文中常被压缩成一句话,或者散落在仓库和补充材料里。
这也是编辑部经常遇到的情况:作者提供了代码链接,审稿人也能理解论文方法,但真要复现时,仍然需要猜文件、猜参数、猜数据预处理口径。代码开放只是入口。没有论断、实验、参数、数据、代码和证据之间的对应关系,开放仓库也可能变成另一组难以核查的附件。
第 二 部分
ARA 把论文改造成研究包
ARA 的设想并不要求取消论文。更准确地看,它把论文从“唯一成果物”改成研究包的一种阅读界面。人仍然可以读正文,机器则能读取背后的结构化材料。
作者把 ARA 设计成四层。第一层是科学逻辑层,记录核心论断、假设、方法、实验与结论之间的关系。编辑部可把它理解为论证链条:稿件说了什么,每一句关键判断由哪一组实验支撑。
第二层是可执行代码层。这里不只放代码文件,还包括环境、依赖、入口命令、配置、随机种子、评价脚本等执行规格。编辑初审如果只问“有没有代码”,信息还不够;更该问的是,作者提供的材料能不能按说明跑到论文声称的结果附近。
第三层是探索图层。它保存研究过程中试过什么、放弃什么、为什么改变方向。过去,这类内容通常被视为论文之外的过程材料。到智能体参与科研时,未采用路径可能帮助后续 agent 避免重复试错,也能帮助审稿人判断作者是否充分比较过关键方案。
第四层是证据层。每个主要论断都要能指向原始输出、日志、图表数据或实验记录。编辑部最熟悉的断点也常在这里:正文结论写得很满,图表也完整,但读者很难追到原始数据、代码文件和实验编号。
作者在论文里给出了一张跨层关系图。它的价值不在于目录名本身,而在于把“结论—代码—过程—证据”放进同一个可追踪结构里。
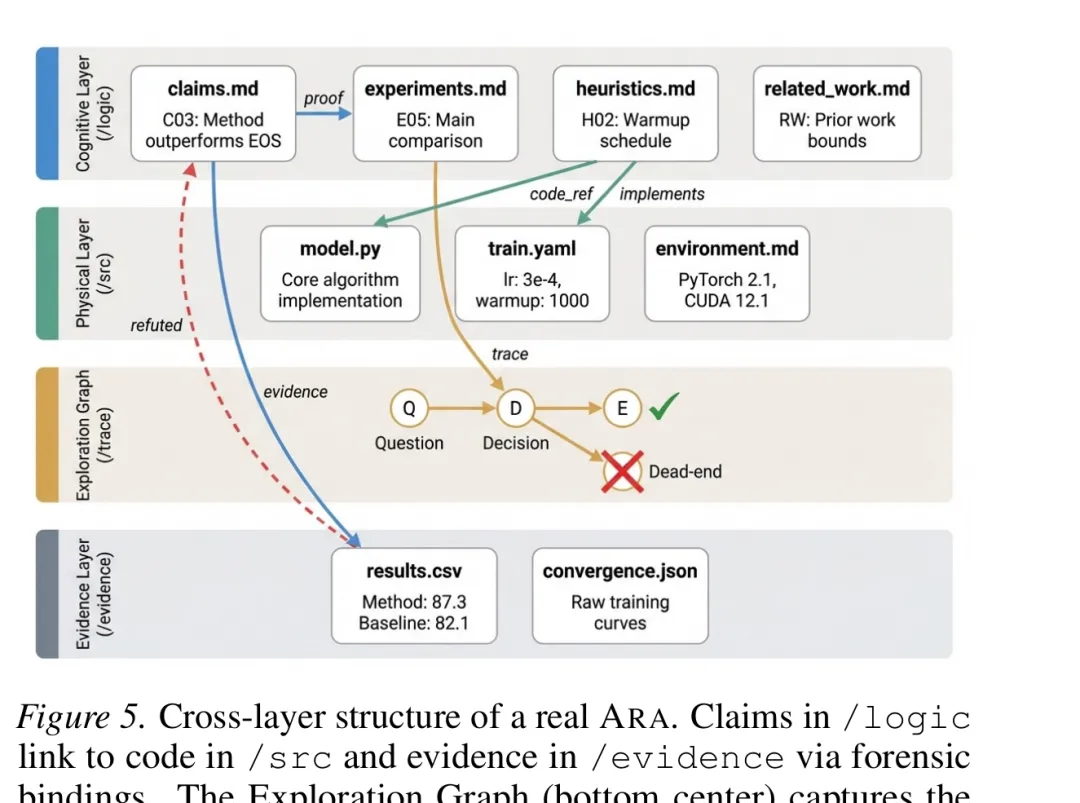
图 2 ARA 不是把附件堆在一起,而是把论断、代码、探索轨迹和证据节点连成可查询结构。图源:Liu et al., arXiv:2604.24658v3。
用期刊工作语言转译,ARA 要求作者交付四类关系:论断之间有逻辑,实验步骤能执行,研究过程可追踪,证据节点能对应。PDF 仍然重要,但它不再承担全部信息。
第 三 部分
几组数字值得冷静看
这篇论文有几组数据,适合编辑部放进自己的投稿规范讨论中,但不能把它们理解为所有学科的通用结论。
作者将 PaperBench 中 23 篇 ICML 2024 论文的 8,921 条专家标注复现要求,与原 PDF 内容进行对照。论文报告称,只有 45.4% 的复现要求在 PDF 中被完整说明;代码开发类要求的充分说明比例为 37.3%;在缺口类型中,缺失超参数占 26.2%。论文把这组结果画成 Figure 3,直观展示了“工程税”到底落在哪里。
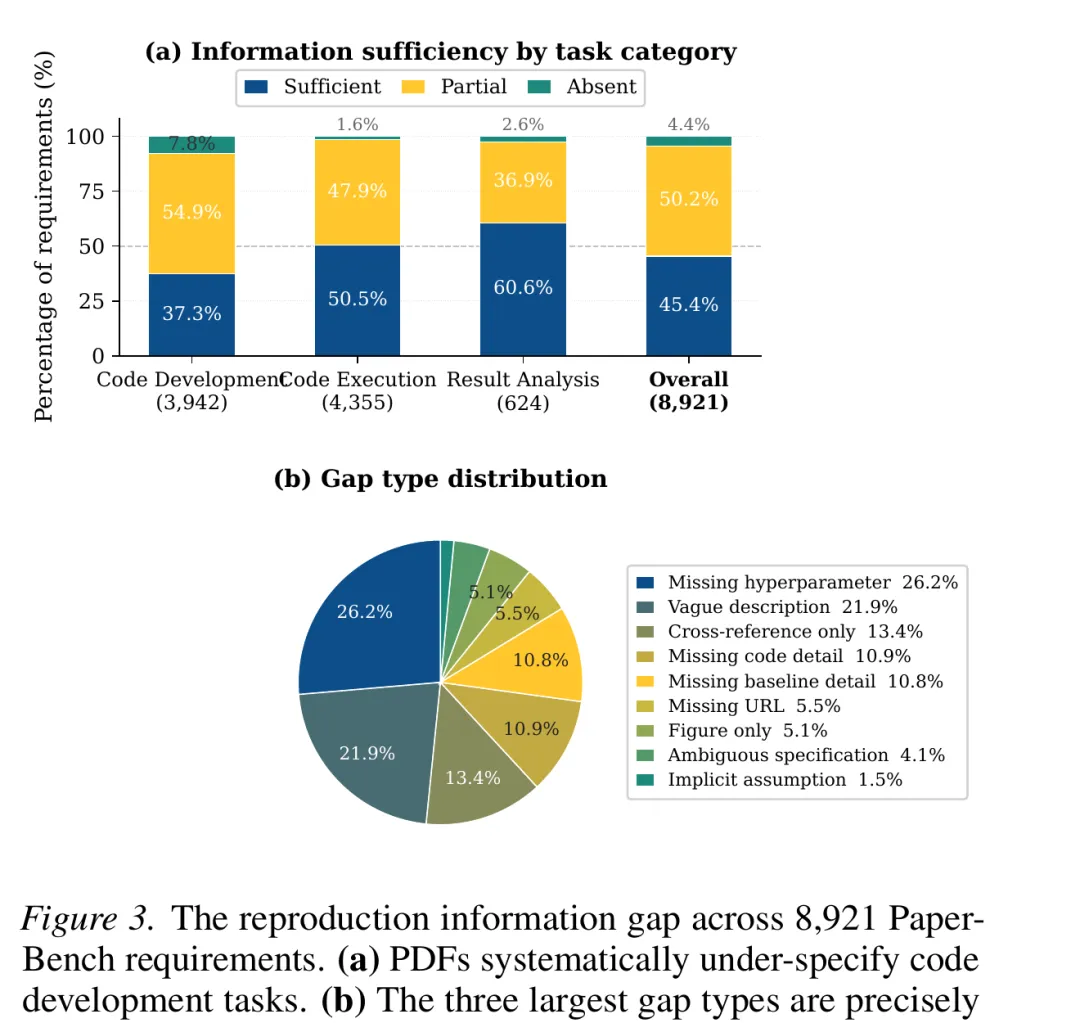
图 3 论文统计的复现信息缺口:传统 PDF 中仍有大量执行规格没有被完整说明。图源:Liu et al., arXiv:2604.24658v3。
这个结果提示的,并不是“作者没有写论文”这么简单。更常见的情况是,很多执行规格没有进入论文主叙事。审稿人可以顺利理解方法,机器却无法稳定定位复现所需材料。编辑部的检查重点,也就从“附件是否上传”延伸到“正文、附件、代码、数据和证据能否互相指认”。
论文还做了智能体理解与复现实验。在 450 个问答任务中,ARA 使智能体问答准确率从 72.4% 提升到 93.7%。在复现实验中,ARA 的难度加权复现成功率为 64.4%,基线 PDF 加 GitHub 组合为 57.4%。
这两组提升说明,结构化研究包能降低智能体理解和复现的摩擦。与此同时,57.4% 到 64.4% 的变化也提醒我们:ARA 只是改善材料组织方式,不能替代研究本身的严谨性。原始实验没有记录,环境没有保存,消融没有做过,后处理工具也补不回来。
论文还引用 RE-Bench 相关分析:基于 21 个前沿模型的 24,008 次 agent runs,失败运行占总美元成本 90.2%,占 tokens 59.2%。这组数字让“失败路径”有了新的出版含义。过去,失败实验常被正文删除;将来,它可能成为下一轮机器研究最想检索的材料。
边界也要讲清楚。arXiv:2604.24658v3 仍是预印本,评估主要集中在机器学习论文和可计算复现场景。湿实验、材料合成、临床研究、纯理论学科能否采用 ARA 这类结构,还需要分学科验证。ARA Compiler 也只能整理已有材料,无法从缺失的 PDF 中补出环境、数据版本和消融实验。生产级应用还涉及沙箱执行、隐私保护、异常检测、探索图访问控制和 schema 迁移。
编辑部可以把这篇论文看作一个提醒,不宜直接当成现成标准。
第 四 部分
AIGC 声明要覆盖研究流程
近两年,许多期刊谈 AIGC 治理,关注点集中在文本:作者有没有用大模型写作,声明应该怎么写,AI 生成文本能不能检测。文本当然要管,但只盯文字痕迹,会把问题看窄。
ARA 这篇论文把视线移到研究对象本身。AI 工具可能参与代码生成、数据清洗、实验调参、图表制作、文献整理和结果解释,也可能参与后续审稿预检与复现验证。编辑部需要知道的,不只是某一段文字由谁生成,还包括 AI 在研究流程里介入了哪些环节,产生了哪些结果,留下了哪些可核查材料。
这提示编辑部可以把 AIGC 流程声明从文本层面向研究流程延伸。过去常见写法是“本文使用生成式 AI 进行语言润色”。更有用的版本,是要求作者说明 AI 是否参与代码编写、数据处理、参数搜索、统计分析、图表生成、文献筛选和审稿回复准备。不同环节对应不同责任,不能用一句“AI 辅助写作”全部带过。
编辑部还要追问责任链条。如果 AI 生成了代码,谁运行并验证过?如果 AI 参与数据清洗,清洗规则是否留下记录?如果 AI 协助筛选文献,被排除文献有没有理由说明?这些内容未必都进入正文,但应进入投稿材料和编辑部核查流程。
第 五 部分
补充材料需要变得可检查
很多期刊已经要求数据可用性声明、代码链接和补充材料。实际问题在于,这些材料经常各说各话:正文使用一套图表编号,代码仓库使用另一套文件名,补充表格又是另一套口径。审稿人靠经验还能勉强读,机器预检和后续复现会遇到很高摩擦。
编辑部可以先做轻量改造,不必一开始建设完整 ARA 系统。
第一步,把可复现信息清单写进投稿须知。对计算类、工程仿真类、数据密集型稿件,至少要求作者列明数据来源、数据版本、预处理步骤、运行环境、依赖版本、核心超参数、随机种子、评价协议、主要消融实验和失败运行说明。清单本身不复杂,关键是让作者在投稿前按项准备。
第二步,试点“论断—证据映射表”。每个主要结论对应一行,列出支撑它的图表编号、实验编号、数据文件、代码文件、运行命令或补充材料位置。编辑初审可以用它定位证据断点,外审专家可以用它快速核查关键结论,后续引入机器预检也有基础材料。
第三步,允许作者提交简短的“未采用路径说明”。不需要把所有失败实验写成长文,只说明关键未采用方案、失败原因,以及它对最终方法选择的影响。对人工智能、算法、工程设计、生物信息学等迭代明显的稿件,这类材料往往比一段笼统讨论更有判断价值。
这些动作的共同点,是把补充材料从“上传了什么文件”推进到“这些文件能否支撑正文论断”。这是编辑部可以立刻调整的工作标准。
第 六 部分
机器预检只能放在闸门位置
论文还设想了 ARA-native Review System,并把 ARA Seal 描述为三层验证:Level 1 检查结构完整性,Level 2 进行论证严谨性审核,Level 3 做预算约束下的方向性执行复现。这个思路对编辑部有参考价值,因为它把一部分机械核查前移了。论文中的审稿流程图很像一个投稿前后的质量闸门:机器先把材料结构和证据链查一遍,再把更需要判断的问题交给人。
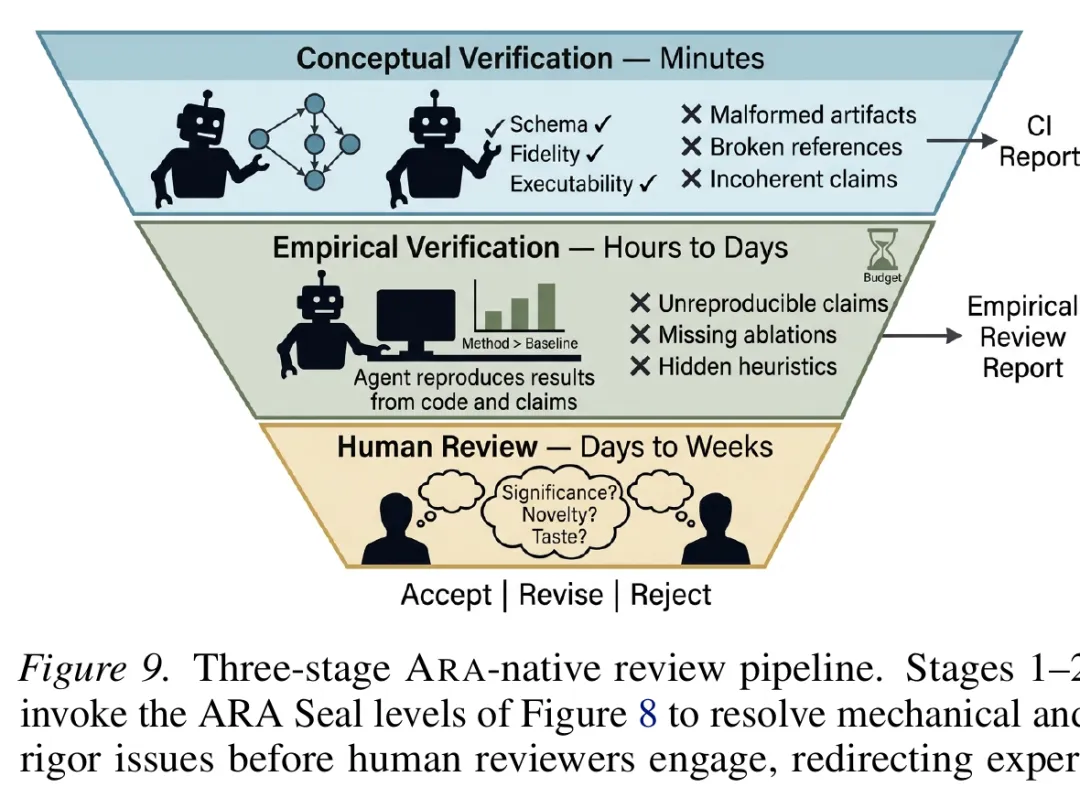
图 4 ARA-native review 的基本思路:机器先做结构、证据链和执行层面的闸门检查,人类审稿保留价值判断。图源:Liu et al., arXiv:2604.24658v3。
按论文设想转化到编辑部预检,机器更适合先查文件是否齐全、链接是否有效、README 能否定位运行步骤、图表数据是否能找到来源、主要结论是否有证据节点、代码能否在沙箱中做方向性运行。这些工作琐碎、耗时,却很适合作为投稿预检。
机器不能替代专家判断研究问题是否有发表价值,方法是否有新意,伦理边界是否清楚,结论是否经得起领域知识检验。论文自己的实验也给出提醒:Rigor Auditor 在 mutation benchmark 上总体检测率为 82.6%,但对 orphan experiment 的检出率只有 22%。自动工具能发现一部分结构问题,也会漏掉关键断点。
所以,机器预检更适合放在闸门位置。它提供问题清单、证据断点和复现风险提示,帮助编辑和审稿人更快进入实质判断。录用、退稿和创新性评价,仍应由人类专家负责。
这里还有保密问题。未发表稿件、原始数据和审稿意见都具有敏感属性。任何机器预检都要先明确本地化部署、权限控制、日志留存、数据删除和供应商责任。为了省时间把稿件直接上传到来路不明的外部工具,只会增加新的治理风险。
第 七 部分
国内期刊可以从小清单开始
完整 ARA 对多数中文科技期刊来说门槛很高。投稿系统、数据仓储、代码执行环境、审稿流程、版权和隐私规则,都需要逐步调整。可这不妨碍编辑部先把最低标准立起来。
投稿须知可以增加“可复现信息清单”。计算类、工程仿真类、数据密集型稿件,要求列出数据来源、代码位置、运行环境、依赖版本、核心参数、随机种子和评价协议。
一两个栏目可以试点“论断—证据映射表”。这张表把正文中的关键结论同背后的图表、实验、数据、代码连起来。它既服务初审,也服务外审。
AIGC 声明可以从文本生成扩展到研究流程使用。作者除了说明有没有用 AI 润色,还要说明 AI 是否参与代码、数据、实验、图表、文献和统计分析。
编辑部内部可以建立“复现失败类型库”。比如缺超参数、缺数据版本、代码不可运行、图表无原始数据、实验矩阵不完整、README 没有入口命令。积累半年后,编辑部就能看清本刊最常见的复现缺口,投稿须知也能跟着调整。
笔者认为,这篇预印本给科技期刊留下的启发,并不该落在“人类论文何时消失”这类预测上。更现实的问题是:当论文的读者同时包括审稿人和科研智能体,编辑部是否还只检查“写清楚了没有”。
下一步,可以从一张可复现信息清单开始,从一份论断—证据映射表开始,从一次代码和数据链接预检开始。
让稿件被人读懂,也让机器有路可查、有步骤可跑。这会成为 AI 时代期刊质量控制的一道新门槛。
参考来源
● arXiv: The Last Human-Written Paper: Agent-Native Research Artifacts
https://arxiv.org/abs/2604.24658
● arXiv PDF: The Last Human-Written Paper: Agent-Native Research Artifacts
https://arxiv.org/pdf/2604.24658
● GitHub: Agent-Native-Research-Artifact(arXiv 摘要页链接为 Orchestra-Research/Agent-Native-Research-Artifact,当前访问会跳转到 AmberLJC/Agent-Native-Research-Artifact;PDF 首页代码行也写 AmberLJC)
https://github.com/AmberLJC/Agent-Native-Research-Artifact
● PaperBench
https://github.com/openai/preparedness/tree/main/project/paperbench
● RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
https://metr.org/blog/2024-11-22-evaluating-r-d-capabilities-of-llms/
● METR: AI R&D Evaluation Report
https://metr.org/AI_R_D_Evaluation_Report.pdf
让稿件被人读懂,也让机器有路可查、有步骤可跑。这会成为 AI 时代期刊质量控制的一道新门槛。
