 夜雨聆风
夜雨聆风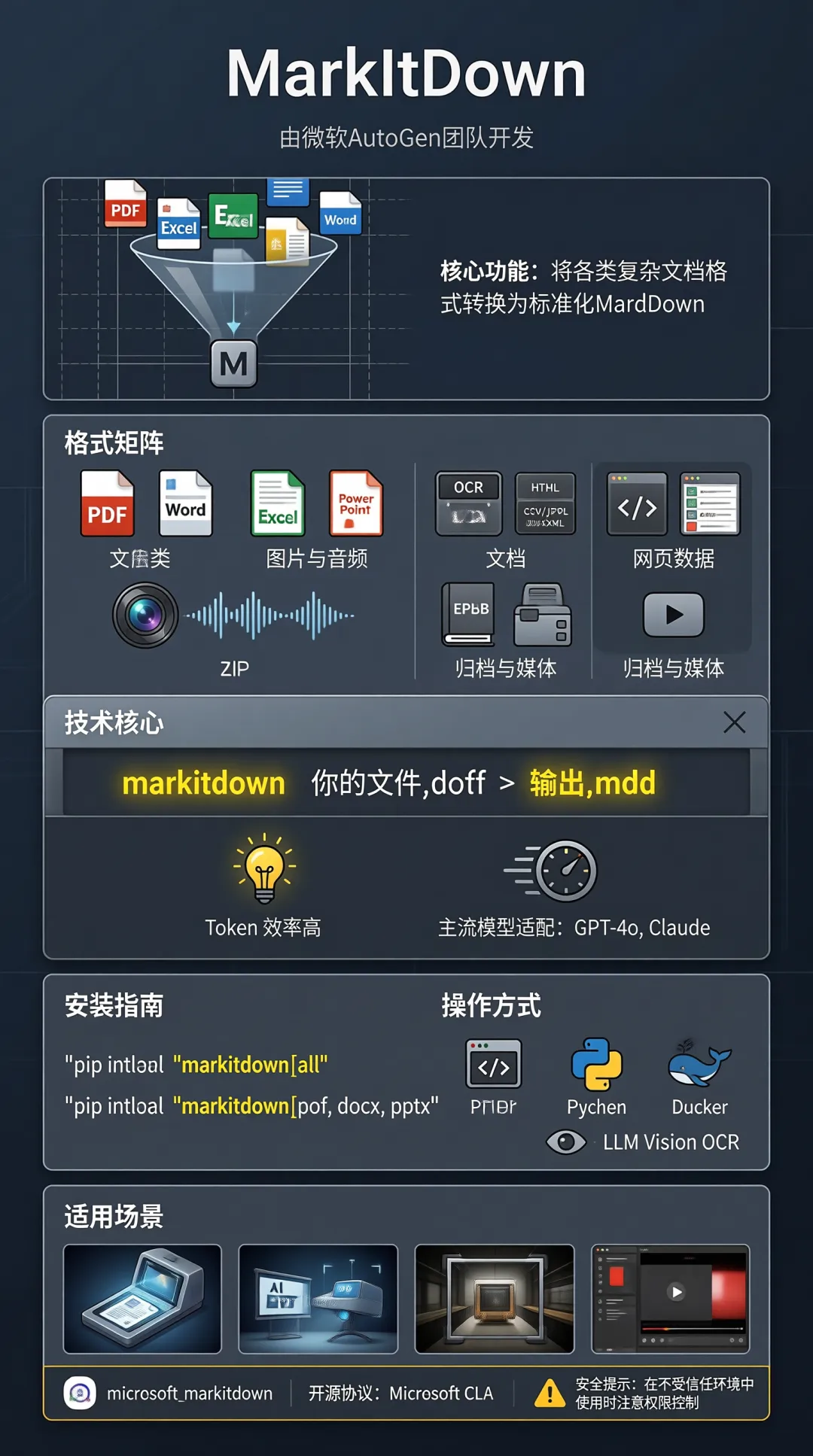
阅读时间:5分钟
你有没有遇到过这种情况?
收到一份 PDF 报告,想让 AI 帮忙总结,但 AI 读不了 PDF。
截图了一段 PPT,想转成文字,手动敲了半天。
下载了一个 Word 文档,想喂给 LLM,但格式不兼容。
现在有一个工具,可以把这些全部转成 Markdown——
而且是微软出品的。
MarkItDown 是什么?
MarkItDown是微软 AutoGen 团队开发的一个 Python 工具。
它的功能很简单:把各种格式的文件,转成 Markdown。
支持的格式:
一行命令搞定:
markitdown 你的文件.pdf > 输出.md为什么是 Markdown?
这里有个很聪明的设计选择。
Markdown 本身很接近纯文本,但又能保留文档结构——标题、列表、表格、链接都能保留。
更重要的是:主流大模型(GPT-4o、Claude 等)都是用 Markdown 训练的。
它们「说」 Markdown,「理解」 Markdown。
把文件转成 Markdown,扔给 AI 处理,效果最好。
而且 Markdown 的 token 效率也很高——同样内容,比 HTML、PDF 都省 token。
怎么安装?
# 安装全部格式支持pip install 'markitdown[all]'# 或者按需安装pip install 'markitdown[pdf, docx, pptx]'可选依赖:
[pptx] | |
[docx] | |
[xlsx][xls] | |
[pdf] | |
[audio-transcription] | |
[youtube-transcription] |
怎么用?
命令行
# 输出到标准输出markitdown 文件.pdf# 指定输出文件markitdown 文件.pdf -o 输出.md# 支持管道cat 文件.pdf | markitdownPython API
from markitdown import MarkItDownmd = MarkItDown()result = md.convert("test.xlsx")print(result.text_content)配合 AI 读图片
from markitdown import MarkItDownfrom openai import OpenAImd = MarkItDown( enable_plugins=True, llm_client=OpenAI(), llm_model="gpt-4o",)result = md.convert("document_with_images.pdf")print(result.text_content)图片里的文字也能提取,用 LLM Vision 做 OCR。
进阶:Azure 集成
如果你的文档比较复杂(扫描件、复杂表格),可以接入 Azure Content Understanding:
markitdown 文件.pdf --use-cu --cu-endpoint "<你的端点>"支持的功能: - 结构化字段提取(发票金额、日期、合同条款) - 视频/音频文件处理 - 自定义分析器
Docker 跑
docker build -t markitdown:latest .docker run --rm -i markitdown:latest < ~/你的文件.pdf > output.md适合谁用?
| 让 AI 读 PDF | markitdown report.pdf > text.md |
| 提取 PPT 文字 | |
| 处理截图/扫描件 | |
| 整理 YouTube 字幕 | |
| 构建 RAG 知识库 |
安全提示
⚠️ MarkItDown 会用当前进程的权限读写文件。
在不受信任的环境中使用时: - 只调用你需要的格式转换方法 - 不要直接把用户上传的文件扔进去 - 限制文件路径和网络访问范围
项目信息
一句话总结
MarkItDown 做了一件事:把所有格式的文件,变成 AI 最容易处理的 Markdown。
不管你是做知识库、做 AI 助手、还是只是想提取文档内容——
试试这个工具,效率提升很明显。

