 夜雨聆风
夜雨聆风你改了三遍,反复送检,以为这次稳了——然后知网给你打了40%。
你去查格子达,它显示16%,你松了口气,觉得没问题。结果学校用的是知网,你白改了。
这不是个例,这是2026届毕业生正在集体踩的坑。
一组数据,先让你清醒
今年1月9日,知网AIGC检测正式进入4.0时代。5月初,格子达完成产品史上规模最大的一次迭代,宣称已覆盖全球99%主流大模型,并首次引入AI图片识别。
两套系统,前后只隔4个月,全部翻新。
但升级到底意味着什么?先看一组真实测试数据。
同一篇豆包生成的1000字论文绪论,原文不改,分别送进国内五大检测平台:
格子达:16.27%

知网:40.5%
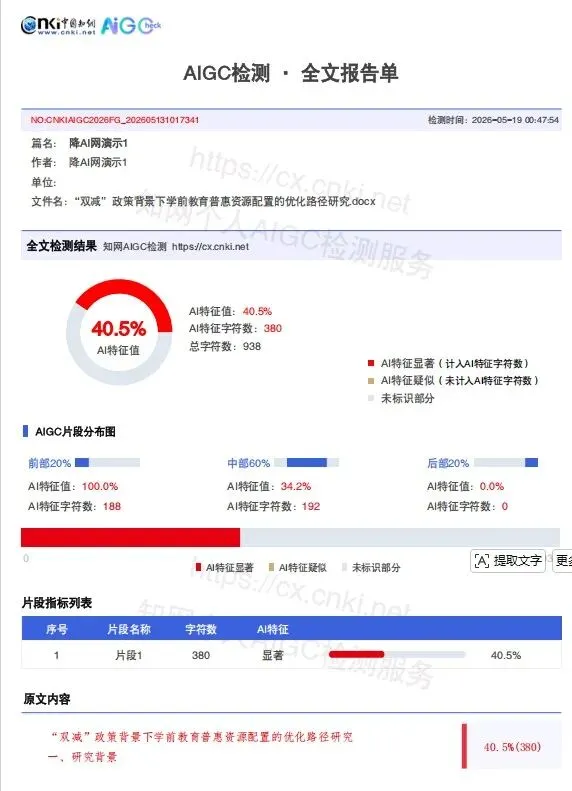
维普:54.23%
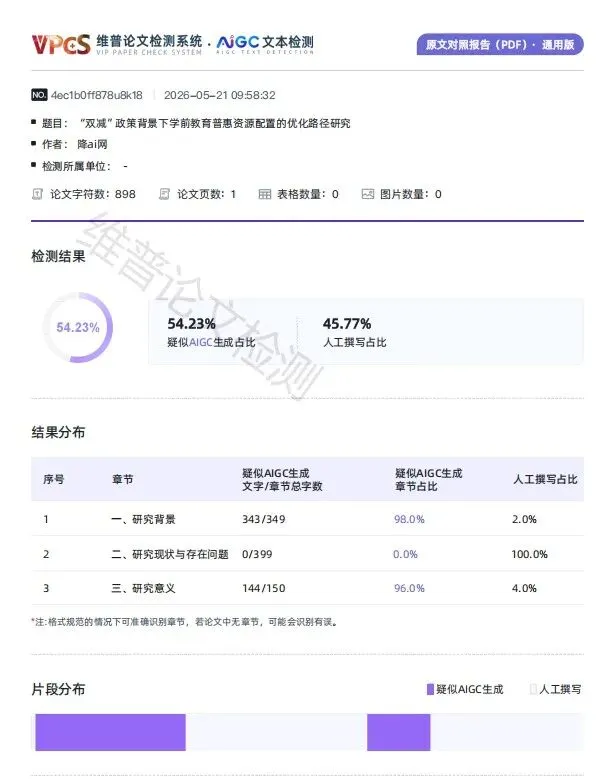
PaperPass:97.3%

朱雀:100%
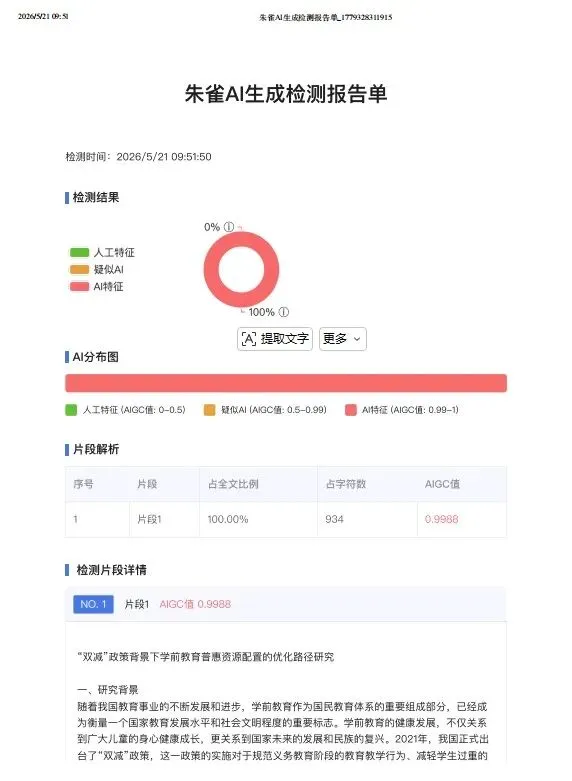
同一段文字,五家平台之间相差84个百分点。更关键的是:这组数据是在两次升级生效之后采集的。
这背后藏着一个大多数同学没意识到的事实——AI检测从来不是一道有唯一正确答案的考题,它是若干套不同算法对同一段文本的不同感知。
知网4.0到底改了什么?
官方公告点了三个方向:
构建"文本—语义—逻辑"三层联动的AI特征识别框架
针对"人写一段、AI写一段"的混写场景强化抗干扰能力
对英文文献识别进行专项优化
翻译成大白话: 知网在让自己对"AI痕迹"的辨认变得更深、更细、更难骗——它在挖深度。
格子达5月这次升级改了什么?
将GPT、Gemini、Claude、文心、通义等主流大模型全部纳入特征建模,覆盖率达99%
通过对抗训练将误判率压低3%以上
首次引入论文图片AI识别
翻译成大白话: 格子达在把"AI生成"的覆盖范围铺得更广、把判断边界画得更稳——它在拓广度。
两家都在迭代,但走的路完全不同。这就解释了为什么同一篇豆包绪论,在知网是40.5%,在格子达只有16.27%——不是谁靠谱谁不靠谱,是两家手里拿的是两把不一样的尺。
2026年降AI,有一条新规则必须记住
去年,很多同学拿一份维普报告改一改,送去知网也能勉强混过——因为那时候各家算法都比较粗糙,识别套路接近。
今年这条路彻底走不通了。
学校用知网,你照着格子达报告动手,几乎一定卡在4.0的"逻辑层"——你根本没改它真正在意的那类特征。学校用格子达,你拿知网报告参考,多半也躲不过"99%模型覆盖"的大网。两家盯的维度根本不在同一套坐标系里。
2026年降AI唯一能跑通的逻辑只有一条:直接用学校那家、最新版的检测报告作为操作蓝本,专门针对那一家的算法精准下手。
操作顺序就三步:第一,确认学校用哪家检测系统;第二,拿那家最新版的检测报告;第三,只改报告里被标红的句子。
两种方案的真实对比
方案一:DeepSeek + 降AI提示词(手动流程)
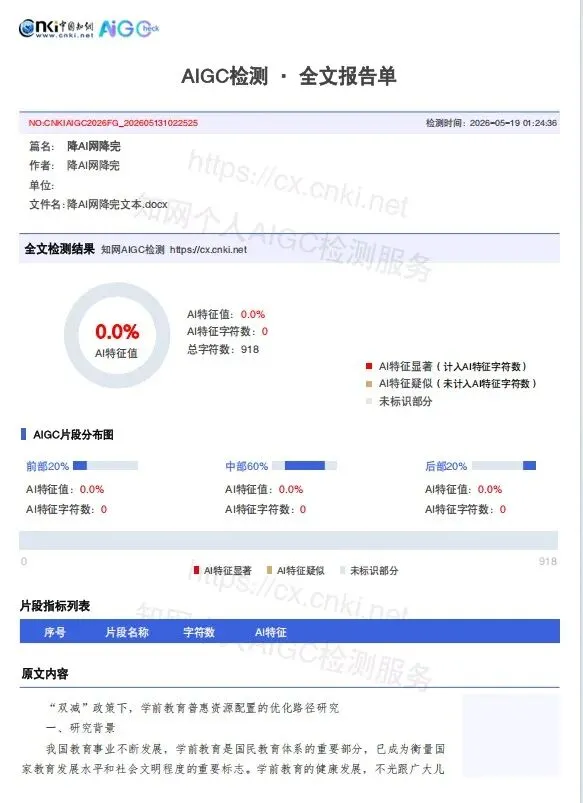
把知网40.5%的报告打开,逐段抠出标红内容,贴进DeepSeek配合提示词重写,再手动塞回原文,全程约38分钟。最终送检结果:0%。
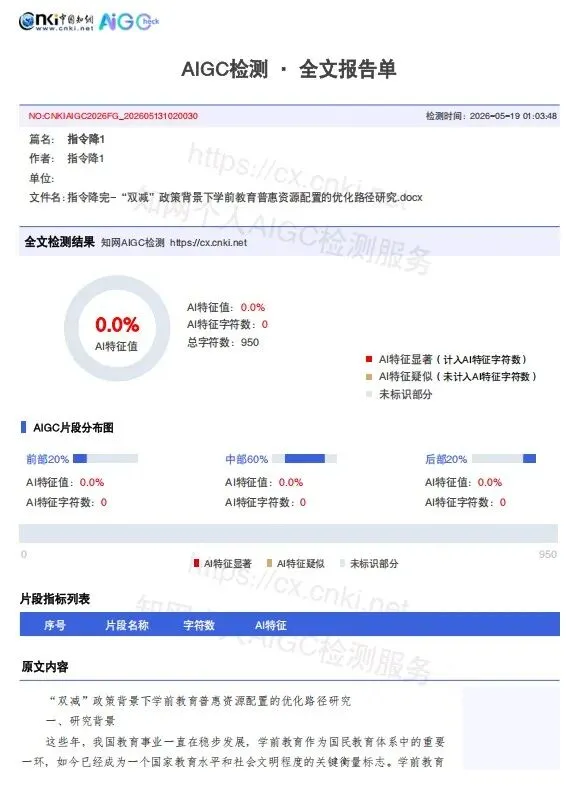
方法能跑通,但也有它的适用边界:全程手动耗时较长;学术专业感有一定损耗;结果无法提前预判,需要反复送检确认。如果你时间充裕、论文体量小,这套流程完全可以自己走通。
热门提示词如下:你是专业的降低AIGC率的工具,请帮我根据以下提示词修改论文,可以调整句式,可以适当的口语化,但不丢失专业性。重点是降低AIGC率!改写过程中,所有专有名词必须完整保留。遇到专有名词太多、不好调整的句子,就直接简化、压缩长度;如果句子里专有名词很少,就尽量扩展内容、把语句写详细。总之,就是在保证专有名词不变、中心思想不变的前提下,用同义表达替换。
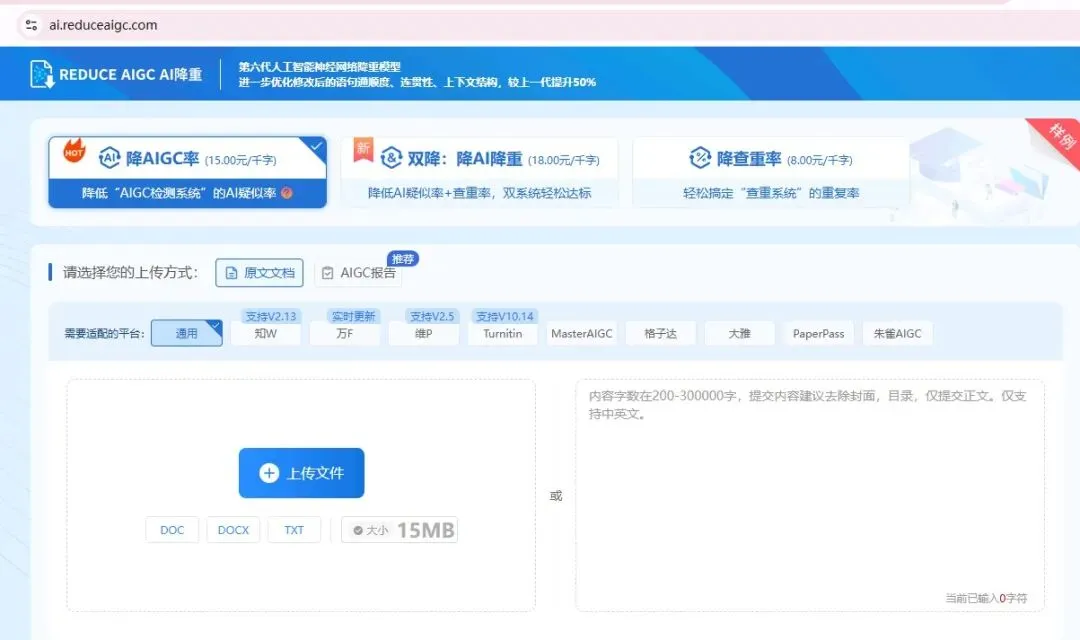
方案二:Reduce AIGC(专用工具)
将知网40.5%的检测报告PDF整个上传,系统自动解析、精准锁定被标红的句子,只改这些位置,专业术语、引用文献、研究方法段原样保留。处理完送回知网:0%。全程不到5分钟,一次过关。
两套方案的核心差异只有一点——DeepSeek是通用大模型,不认识你学校用的那把尺;Reduce AIGC是专门对着那把尺做的工具。时间紧、论文体量大的同学,这个差距会被放得很大。
知网4.0的"逻辑层识别"也好,格子达的"99%模型覆盖"也好,本质上都在传递同一个信号——2026年的AI检测,已经精细到必须用专门针对它的工具才能应对。
随便丢给大模型改一改的粗糙年代,已经翻篇了。
算法可以一直变,原则只有一条:用学校那家的报告,针对性下手。
你身边有没有还在用"乱改法"、拿错平台报告凑活的同学?把这篇转给他,能实实在在帮他省掉一次踩坑的代价。
