 夜雨聆风
夜雨聆风有人从泄露的源码里提炼出了一整本书。
一本从源码里长出来的书
张汉东(@ZhangHanDong)做了一件很酷的事。
Claude Code v2.1.88 的 TypeScript 源码因为 source map 泄露而可被还原。他没有只是看看,而是让 Claude Code 从源码中提炼出一整本书——《驾驭工程》(别名《马书》),30 章 7 篇,覆盖架构、提示工程、上下文管理、缓存、安全、高级子系统和经验教训。
这本书揭示了 AI 编码 Agent 的内部运作机制,以及 Anthropic 工程师在设计 Claude Code 时的每一个关键决策。

以下是其中最值得关注的发现。
秘密一:89 个 Feature Flag 揭示的产品路线图
Claude Code 的源码中有 89 个构建时 Feature Flag(通过 Bun 的 feature() 函数实现编译时死代码消除)。
这些 Flag 不是随意的——它们揭示了一个清晰的产品进化路线图:
| 旗标集群 | Flag 数量 | 引用量 | 指向 |
|---|---|---|---|
| KAIROS 家族 | 6 | 84+ | 完整的"助手模式"——后台自主运行、记忆整理、推送通知、GitHub Webhook 集成 |
| 多 Agent 编排 | 3 | 90+ | Worker 分配、队友记忆共享、Unix Domain Socket 进程间通信 |
| 远程与分布式 | 4 | — | 远程控制和分布式执行——从本地 CLI 扩展为 Agent 平台 |
| 上下文优化 | 3 | — | 三种不同粒度的上下文管理策略 |
| 分类器体系 | 2 | 102 | 转录分类器(69 处) + Bash 分类器(33 处)——自动模式的核心 |
启示: 89 个 Flag = 89 个正在探索的方向。Claude Code 明显还处在快速迭代阶段。

秘密二:YOLO 分类器——用 AI 审核 AI
Claude Code 的权限系统里有一个叫 YOLO 分类器的组件——它用 AI 来决定 AI 的操作是否安全。
工作原理
安全白名单短路 → 只读操作零成本放行
↓ (不确定的操作)
二阶段 XML 分类器:
阶段 1:快速判定(max_tokens: 64,亚秒级)
阶段 2:深度推理(max_tokens: 4096,含 <thinking> 链式思考)
↓
不确定时默认阻止
↓
连续 3 次或总计 20 次拒绝后 → 回退到用户手动确认核心原则
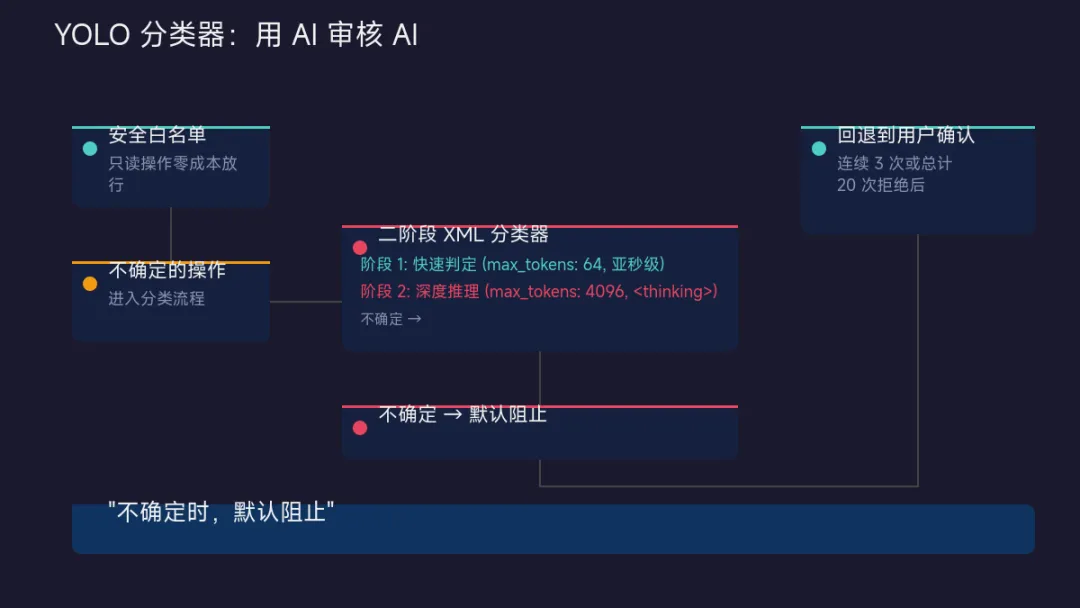
"不确定时,默认阻止。"
它的设计思路是保守的、渐进式的——先让 AI 筛,不确定就拦下来交给人。
四种权限策略
| 策略 | 实现 | 触发条件 |
|---|---|---|
| 无条件注册 | 核心工具始终可用 | 基础操作 |
| Feature Flag 守卫 | 构建时消除整个模块树 | 实验性功能 |
| 环境变量守卫 | USER_TYPE === 'ant' | Anthropic 内部用户先验证 |
| 运行时函数守卫 | 条件性启用 | 按代码库状态动态切换 |
秘密三:缓存五原则——API 成本降低 90%
Claude Code 的提示词缓存系统被 Anthropic 当成核心基础设施来建设。Lance Martin 总结了五条原则:
原则一:静态在前,动态在后
稳定内容(系统提示词、工具定义)放前面,高频变化的内容放后面。
原则二:用消息传递更新,不编辑提示词
追加 <system-reminder> 消息,而不是修改已有的系统提示词。编辑会打断缓存前缀。
原则三:不切换模型
缓存是模型特定的。切换模型 = 缓存全部失效。需要便宜模型时用子 Agent,不切主模型。
原则四:谨慎管理工具
工具定义在缓存前缀中。增删工具 = 前缀失效。用 tool search 动态追加。
原则五:更新断点
多轮应用中把缓存断点移到最新消息,利用自动缓存。
最骚的操作

- • Beta Header 锁存 — 一旦发送过某个 beta header,永远继续发送。取消会改变请求签名,导致缓存失效
- • 日期记忆化 — 会话跨越午夜不改日期字符串,避免打断缓存
- • Agent 列表优化 — 从系统提示词移到 system-reminder,全球 cache_creation 降低了 10.2%
秘密四:六条驾驭原则

从全书 30 章中提炼出的核心原则:
| # | 原则 | 核心 | 反模式 |
|---|---|---|---|
| 1 | 提示词即控制面 | 行为引导通过自然语言,代码只管结构性约束 | 行为硬编码 |
| 2 | 缓存感知设计是刚需 | 每次提示词变更都有成本 | 提示词频繁变动 |
| 3 | 失败关闭,显式开放 | 默认最安全值,必须显式声明才允许 | 默认开放 |
| 4 | A/B 测试一切 | 先内部验证,通过数据确认再推广 | Big Bang 发布 |
| 5 | 先观察再修复 | 建立可观测性理解问题全貌 | 凭直觉修复 |
| 6 | 锁存以求稳定 | 一旦进入某状态不再摇摆 | 状态抖动 |
秘密五:上下文管理的工程细节
200K token 的上下文窗口听起来很大,但 Claude Code 的工程实践告诉我们:它远不够用。
| 指标 | 数值 |
|---|---|
| 系统提示词占用 | ~15-20K token |
| 自动压缩触发点 | ~167K(83.5%) |
| 压缩输出预留 | 20K token |
| 单工具结果上限 | 50K 字符 |
| 熔断阈值 | 连续 3 次失败 |

Claude Code 的设计哲学很简单:最便宜的 token 是你从未发送的那个。每个进入上下文的内容都有明确的 token 上限。
告知而非隐藏
截断时不是默默砍掉——而是告知模型"内容被截断了,完整信息在磁盘上的这个路径"。
这让模型可以在需要时主动获取完整信息,而不是在不知情的情况下基于不完整数据做决策。
写在最后
《马书》真正有价值的部分,是它把一个商业 AI 产品的工程实践提炼成了可复用的设计模式。
无论你是在用 Claude Code、Cursor、Copilot,还是在构建自己的 AI Agent——这些模式都适用:
- • 双层 Feature Flag 管理
- • 用 AI 审核 AI 的 YOLO 分类器
- • 缓存感知的提示词设计
- • 失败关闭的安全哲学
- • 为一切设定 token 预算
Claude Code 的源码告诉我们,最领先的团队已经在这样做了。
觉得这系列文章有帮助?关注「赛博虾条」,驭缰工程系列持续更新中。
这是驭缰工程系列的彩蛋篇。完整系列: ① 什么是 Harness Engineering? ② AGENTS.md 到底怎么写? ③ 用 Linter 驾驭 AI ④ AI 写的代码,你怎么知道是对的? ⑤ Ralph 循环 ⑥ Anthropic 的三智能体实验 ⑦ 熵管理 ⑧ 从今天开始:你的第一个实践
