夜雨聆风
夜雨聆风预计阅读时间:10分钟(超干货)

AI 爬虫 和 AI 代理,日常聊天中大家都叫它们“AI 机器人”,但它们的用途、流量特征、身份识别方式、乃至防御策略都截然不同。把两者混为一谈,是当前网站运营者最常犯的错误。
AI 爬虫 vs AI 代理:真正的区别
AI 爬虫本质上是一个集中式的收集器。它的任务是广泛发现、索引和抓取网页内容,用于训练、搜索或检索。它通常运行在供应商自己控制的基础设施上,一般会有公开文档,并且在大多数情况下,它会主动表明自己的身份。
目前主流 AI 厂商都在不同程度地公开其爬虫的身份信息以及运行所使用的基础设施。例如:
OpenAI 按角色区分了机器人:GPTBot 用于训练相关的抓取,OAI-SearchBot 用于在 ChatGPT 搜索结果中展示网站内容,ChatGPT-User 则用于用户指令触发的抓取。每个机器人都有各自的用户代理字符串、robots.txt 使用说明以及公布的 IP 地址列表。
Anthropic 也类似,区分了 ClaudeBot、Claude-User 和 Claude-SearchBot,每个角色对应不同的产品功能,同样有 robots.txt 行为说明。
Google 作为这个领域的老牌玩家,多年来一直发布爬虫目录,现在已经明确区分了通用爬虫、用户触发的抓取器以及用户触发的代理。验证方式支持反向+正向 DNS 查询和发布的 JSON 格式 IP 地址段。
AI 代理则是另一种“生物”。它不是为了爬取整个网络,而是为了完成某个具体任务。它会点击、执行 JavaScript、填写表单、保存 Cookie、在多步骤工作流中穿行——整体行为更像一个浏览用户,而不是一个建立索引的机器人。OpenAI 的 ChatGPT 代理就是一个典型的例子:它能够浏览网站、使用可视化浏览器,并代表用户执行操作。
关键点在这里:当前的 AI 代理其实分为两种,但其中只有一种比较容易识别。
第一种是声明式代理,厂商为其构建了加密身份。ChatGPT 代理就属于这一类,它对每一个外发的 HTTP 请求都进行签名。
第二种,规模要大得多,它们本质上还是浏览器自动化,但行为方式很像 AI 代理。这类系统基于浏览器或其模拟器,执行的是目标驱动的工作流。它们可能运行在无头浏览器上,也可能通过自动化框架来调度,但通常没有任何厂商提供的可信身份证明。从行为上看,它们就是代理;但从防御角度看,它们看起来很像真实用户。
顺便纠正一个常见的误解。AI 爬虫并不总是来自一小撮固定的 IP 地址,AI 代理也不总是来自最终用户的笔记本电脑。更准确的理解是:爬虫通常来自厂商的集中式基础设施,并且会以某种形式公布自己的身份;而代理通常是用户发起的,但执行时可能位于厂商托管的基础设施、远程浏览器或自动化环境中,而不是用户自己的设备上。ChatGPT 代理所使用的白名单模式(依赖签名请求和公钥发现机制)也强烈表明,它运行在受控的代理基础设施之上,而不是来自随机电脑的随机流量。
为什么同一套防御手段不能两者兼顾
一旦你认识到这两种流量属于不同类别,那么“一刀切”式的防御为什么会失效,就显而易见了。
爬虫相对容易分类。它们覆盖面广、有公开文档、厂商希望你能够识别它们,而且它们的基础设施相对稳定。我们在上一篇文章中讨论的分层模型——robots.txt 加上用户代理匹配再加来源验证——对于爬虫来说效果不错。
但代理几乎违背了所有这些假设。它们的活动是窄带、任务驱动的,而不是广撒网式的。它们的流量看起来几乎和真实用户会话一模一样。它们可能不会干净利落地自报身份。即便它们会自报身份,光靠一个用户代理字符串也毫无意义,因为任何人都可以发送 User-Agent: ChatGPT。如果你的防御体系把声明式爬虫、签名代理和未签名的代理类自动化一视同仁,那么结果要么是误伤大量真实用户,要么是漏掉很多隐匿的自动化流量——通常两种情况会同时发生。
因此,任务分裂为两个问题:识别爬虫,以及识别代理。它们需要各自不同的应对方案。
识别 AI 代理
这一步才是真正困难的地方,也是大多数防御体系的短板所在。
对于声明式代理,加密请求验证是目前使用更多的身份验证手段。这类机制通常被统称为 Web Bot Auth 风格,基于 HTTP 消息签名标准构建。其原理并不复杂:代理使用私钥对每个外发的 HTTP 请求进行签名;网站则通过厂商公开的、存放在知名 URL 下的公钥来验证签名。签名验证通过,身份就是真实的;通不过,就不是。
OpenAI 的 ChatGPT 代理就是这一方案的具体实现。一个经过签名的请求会附带一组与签名相关的 HTTP 头,接收端的边缘节点会实时对这些头进行验证。简化的示意大致如下:
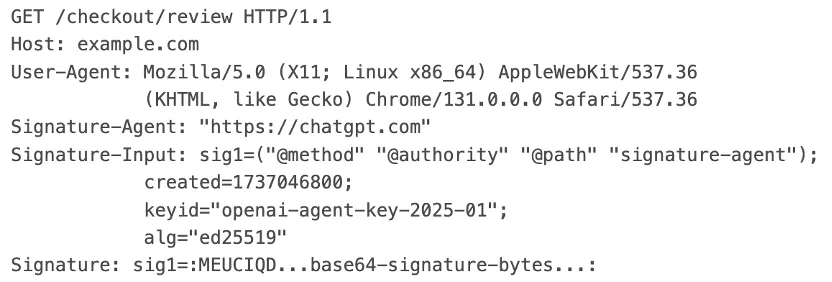
注意这里的 User-Agent。它看起来就是一个普普通通的 Chrome 浏览器——因为在实际场景中,绝大多数类似代理的流量在用户代理层面就是这样的。这也是爬虫与代理之间一个关键的运维差异。像 GPTBot 这样的爬虫,很乐意告诉你它是 GPTBot。而一个代理——无论是否声明——通常驱动的是真实的浏览器引擎,因此携带的也是真实的浏览器 User-Agent。身份信息(如果存在的话)存在于签名头中,而不是 User-Agent 字段里。
接收端的边缘节点会从厂商的知名端点获取公钥,根据所列字段重建签名基础串,然后验证签名。验证不通过,就不予信任。这比单纯检查 User-Agent 要强大得多——因为密码学不关心 User-Agent 字符串里写的是什么。
对于未签名或仅有松散声明的代理类自动化——这其实占据了当前真实世界中绝大多数代理流量的份额——加密手段无法使用。此时,防御就必须转向行为和运行时的范畴:客户端执行环境校验、JavaScript 运行时指纹、TLS 与 HTTP 层签名、HTTP 头顺序、微操作熵值、会话旅程建模、基于会话级特征向量的异常检测……这些手段单独拿出来都不足以确证身份,但组合在一起,就形成了一个难以在整个工作流中被持续伪造的概率化身份。这本质上就是我们之前写过的分层行为检测理念,应用到了代理形态的流量上。
用最简洁的方式总结两条路径:
爬虫通过声明的身份和基础设施来暴露自己。
代理在有加密证明时通过密码学手段证明自己;在没有证明时,则通过工作流行为来暴露身份。
精准识别只是第一步
有一个问题很少被问起:当你正确识别出一个请求来自 AI 代理之后,接下来该怎么办?放行吗?
识别和信任不是一回事。 一个经过密码学验证、确实是真实 ChatGPT 代理的请求,在您的网站上可能做着完全合法的事情——比如代表用户查看某个商品、预订机票、比价、填写用户明确要求它填写的表单。但也可能做着您绝不希望任何自动化程序做的事:抓取整个商品目录、探测结账流程以获取价格信息、信用卡测试、囤积库存,或者为攻击做侦查。
身份本身并不能告诉您,到底发生的是哪一种情况。目标才能。
因此,在完成“爬虫 vs 代理”的分类之后,下一个合乎逻辑的步骤就是代理意图分类。这个代理到底想在我的网站上做什么?它是一个执行用户委托任务的正向行为者?一个做着普通浏览或研究的中性行为者?还是一个将代理框架用作抓取或欺诈工具的恶意行为者?这个问题的答案应该驱动响应策略,而不仅仅是身份本身。一个验证通过的代理,如果带有恶意目标,不应该仅仅因为签名校验通过就获得通行证。一个未签名的代理,如果目标明显是良性的,也不应该仅仅因为无法证明自己是谁就被硬性拦截。
这对网站运营意味着什么
实际可行的结论是:防御策略必须升级。大多数网站为上一代机器人,甚至为那些声明式的 AI 爬虫所搭建的工具和流程,根本就不是为这种新型流量类别设计的。网站运营者现在需要花时间做好两件事:第一,搞清楚实际访问你应用的到底是什么——是爬虫、签名代理、类代理自动化,还是真实用户;第二,针对每一类流量采取与之匹配的响应策略。
这意味着你需要:
在边缘节点支持 Web Bot Auth 验证;
保持爬虫 IP 和 DNS 情报的持续更新;
调优行为模型,使其能识别工作流驱动的自动化(而不仅仅是大规模抓取);
对签名验证通过的声明式代理,将其视为更接近可信伙伴;对未签名的类代理流量则保持适当的怀疑态度。
你可以自己搭建这一整套体系——工程投入不小,但可行。而另一种选择(也是大多数网站在实际评估工作量后最终会选择的)是与专门的机器人管理平台合作。Radware Bot Manager 已经在四类流量上实现了上述能力:整合了声明式爬虫验证、签名请求校验、网络与 TLS 指纹识别,以及基于数万个应用集体情报的会话级行为模型。大部分工作对你来说只是几项配置,检测和执行层面早已就绪并持续运行。
AI 爬虫和 AI 代理会持续演进,代理与真实用户之间的界限也会越来越模糊。未来两年里,好的网站运营者,将不再把“AI 流量”当作一个筐,而是真正将其拆分为两个不同类别进行防御——他们还会再进一步,不仅问“谁在访问”,更要问“他们想干什么”。

点击下方" 阅读原文"
了解更多Radware解决方案
关于Radware
Radware®(NASDAQ: RDWR)是多云环境应用安全和交付解决方案的全球领导者。该公司的云应用程序、基础设施和API安全解决方案使用人工智能驱动的算法,可提供精确、无操作、即时的防护,免受复杂的网络、应用程序、DDoS攻击、API滥用和恶意机器人的攻击。全球的企业和运营商依靠Radware解决方案来应对不断变化的网络安全挑战,并在降低成本的同时保护品牌和业务运营。
欲知详情,请访问:https://cn.radware.com/