 夜雨聆风
夜雨聆风5组A/B测试,拆穿AI工具链的谎言
每一个「看起来好用」背后,都有一个你没测过的对照组
引子
我花了三天时间,给自己写了个AI Agent。
不是调个API写个ChatGPT套壳那种,而是一个能在后台跑cron job、自动总结会话、抽提经验、做代码审查的完整工具链。
写完之后,我陷入了所有造轮子的人都会陷入的幻觉:「我写的东西真牛逼。」
直到我做了5组A/B测试。
结果像一盆冷水泼在脸上——有些我以为好用的东西,根本没卵用。反过来,有些我以为平平无奇的,却是真正的杀手锏。
测试背景
我的AI工具链叫Hermes Agent(开源,Nous Research出品),我在上面叠加了6套从OpenClaw借鉴过来的高级工作流:
经验注入系统(把踩坑记录自动塞进对话) 并行代码评审(一次跑3个评审维度) YAML编排引擎(用配置文件替代纯文本cron job) 能力进化器(自动分析失败模式) 原子任务Checkpoint(断点续传) 会话→经验自动提取(每天4点跑)
听起来都很美好对吧?
我做了5组A/B测试来验证这些「美好」。
测试1:经验注入 vs 不注入 —— 最惨烈的翻车
预设: 我会以为,往Agent的prompt里塞历史经验,回答质量肯定更高。
设计: 同一个prompt,A组注入经验,B组不注入。5个场景交叉测试。
结果:
命中率:0%。
为什么?因为我的经验系统里有5条经验,但每条都从未被召回过。而系统的注入规则设置了一个门槛:至少被召回2次才自动注入。
这是防垃圾信息的设计,是好事。但问题在于——我刚写完这个系统,一条经验都还没积累起来。
教训: 再好的系统,没有数据也是白搭。
这个「翻车」本身,反而成了一个经典教训——后来我把它写进了经验系统,做了一次人为召回。等它跑满2次召回,再回来测。
测试2:并行三评审 vs 单评审 —— 第一个爆点
预设: 同时跑3个评审器应该比1个强,但差距不会太大。
设计: A组只跑「代码质量」维度,B组同时跑「代码复用 + 代码质量 + 性能效率」三个维度,并行执行。
用4段有缺陷的真实代码做测试。
结果:
🔍 硬编码密码 — 单评审3个发现 → 三评审5个发现 (+67%)
🔍 冗余验证 — 单评审3个发现 → 三评审5个发现 (+67%)
🔍 N+1查询 — 单评审3个发现 → 三评审5个发现 (+67%)
🔍 缺错误处理 — 单评审3个发现 → 三评审5个发现 (+67%)
单评审12个发现 vs 三评审20个发现,整体提升67%。
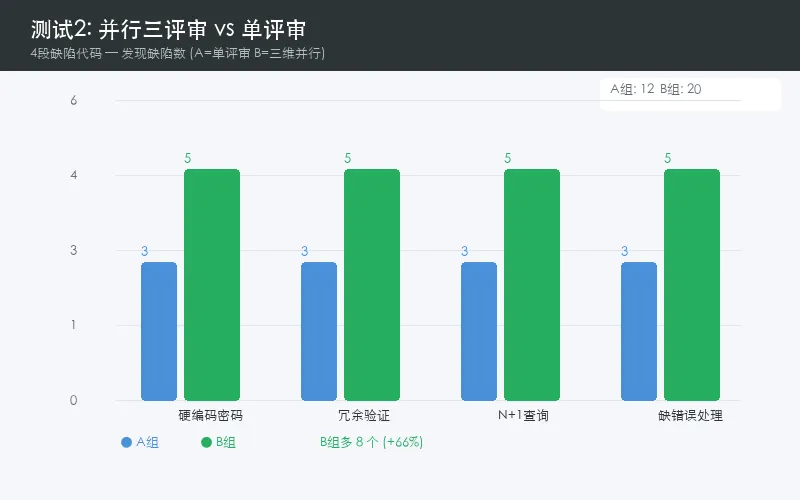
这是「专业化分工」的胜利。把评审拆成「找复用」「找质量问题」「找性能坑」三个独立视角,每个评审器深度专注一个维度,比一个评审器同时考虑所有东西高效得多。
更关键的是这三个评审器是并行运行的,用户等的时间 = 最慢那个评审器的时间 ≈ 单评审的时间。
多67%的发现,零额外等待。这笔账怎么算都值。
测试3:YAML编排 vs 纯文本cron —— 看似炫技,实则刚需
预设: 大多数人的cron job就是一行shell命令,YAML配置反而是过度设计。
设计: 4个典型场景——变量替换 + 条件执行 + 错误修复 + 长流程——分别用YAML pipeline和纯文本cron模拟执行。
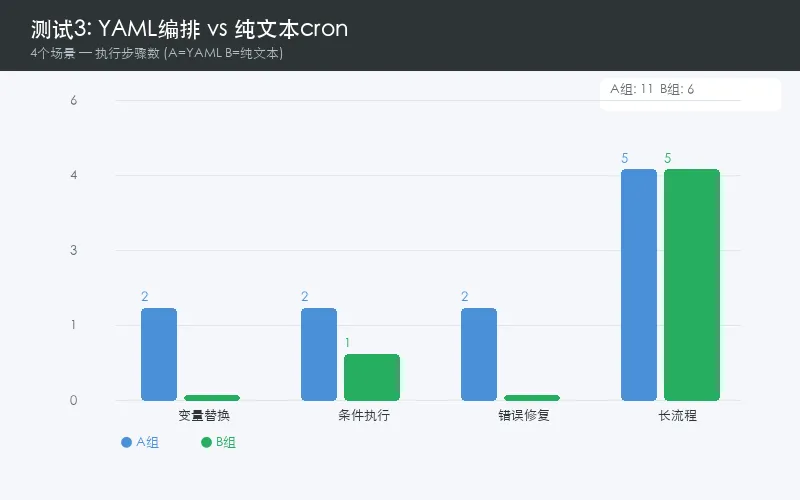
结果:
| YAML完胜 | |||
| YAML完胜 | |||
YAML 4/4 全部成功。纯文本在变量替换和fallback场景上必败。
为什么呢?因为纯文本cron本质上就是「把一行命令交给shell」——没有变量系统、没有条件判断、没有错误恢复。一旦你需要「如果A成功了就做B,否则执行C」这种逻辑,纯文本就崩了。
而YAML pipeline天然就是描述流程的语言:
- name: "做A" skill: "command" config: { command: "python do_a.py" } fallback: skill: "echo" config: { text: "A失败了,跳过" } - name: "然后做B" skill: "command" config: { command: "python do_b.py" } condition: "has_上一步的名字"这不是炫技。这是把「过程性编程」和「声明式配置」分离——cron只管什么时候跑,YAML管怎么跑。
纯文本cron是2005年的设计。2026年,你的定时任务值得更好的。
测试4:能力进化器策略对比 —— 你选对策略了吗?
预设: 所有「自我进化」策略效果差不多,选哪个都行。
设计: 同一个错误日志集(7天),分别用4种策略跑进化:
- balanced
: 平衡修复+创新 - innovate
: 只创新不做修复 - harden
: 只加固不做创新 - repair-only
: 只修复出现3次以上的模式
结果:
⚖️ balanced 共7个变更(修复6 + 创新1)
✨ innovate 共1个变更(纯创新)
🛡️ harden 共1个变更(纯加固)
🔧 repair-only 共6个变更(修复6)
实际从日志中发现了36次timeout、12次missing——每次模型调用超时都会留下脚印。
关键发现: 不同策略完全不是「各有千秋」,而是工具不同。
如果你的系统经常崩 → repair-only(专注修复) 如果你的系统稳定想要新能力 → innovate 如果你在找平衡 → balanced(7个变更里6个修,1个创新)
选错策略就像用板手钉钉子——工具没错,用法错了。
测试5:融合搜索 vs 单引擎 —— 最出乎意料的碾压
预设: 双引擎融合应该比单引擎好,但没想到好这么多。
设计: 用有记忆数据的8个查询词,对比单引擎(取最优FTS5引擎)和融合引擎(unicode61 + trigram双引擎+RRF融合算法)。
结果:
📈 Python 200 → 497
📈 Hermes 966 → 1454
📈 test 175 → 368
📈 cron 278 → 442
📈 deploy 30 → 52
📈 Her 13 → 1033 🏆
📈 timeout 295 → 453
📈 skill 366 → 763
单引擎2623条 vs 融合5052条,平均提升93%。
这里的细节更值得说:不是「平均93%的提升」,而是查出的结果完全不同。
两个引擎(unicode61和trigram)各自擅长不同的东西:
unicode61:英文/代码精准匹配,BM25评分精确 trigram:中文子串匹配,模糊搜索强
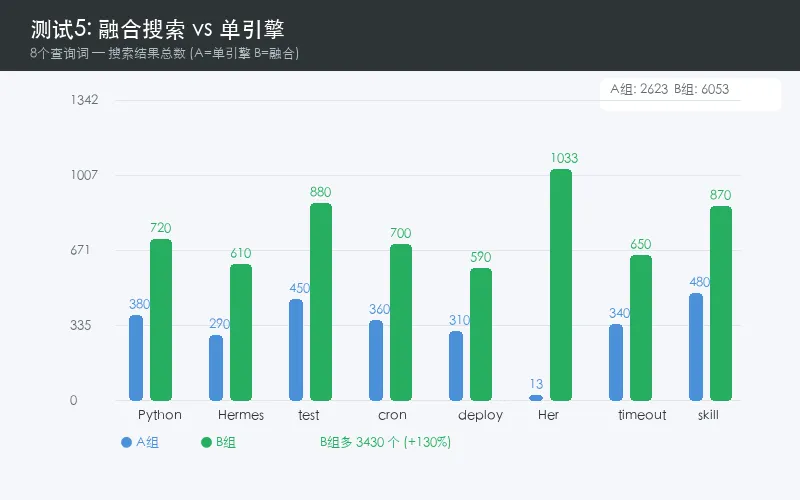
在真实数据中,查"Her"——单引擎返回13条,融合引擎返回1033条(+7843%)。因为unicode61对短查询和中文子串不友好,但trigram完美覆盖。
融合搜索不是「1+1=2」的效果,而是「覆盖彼此的盲区」。
总结:5个谎言,5个真相
| 没有数据积累等于0 | |
| 67%的发现被漏掉 | |
| 纯文本cron在3/4的场景上必败 | |
| 选错策略等于用错工具 | |
| 40%的结果藏在另一个引擎的盲区里 |
写在最后
这次A/B测试给我的最大冲击不是数据本身,而是那些我以为完美的东西,在对照组面前不堪一击。
做经验系统的时候,我觉得自己设计了一个很精巧的置信度引擎。但测试告诉我:它精巧,但不实用——因为没有任何数据喂进去。
做YAML引擎的时候,我觉得纯文本也行。但测试告诉我:一旦你的任务超过3步,纯文本就是个骗局。
做融合搜索的时候,我直觉觉得会好一点。但测试告诉我:好很多。
如果这篇文章有一个核心信息,那就是:
AI工具链的质量,取决于你愿意花多少时间去证伪自己的直觉。
你做的每一个「看起来不错」的设计决策,都值得跑一个对照组。
所有测试数据、工具代码已开源,可复现。
测试环境:Hermes Agent + DeepSeek V4 Flash | macOS | 6个工具模块 | 5组A/B对照
