 夜雨聆风
夜雨聆风企业级 PDF 智能解析与 RAG 入库技术方案
适用范围:企业知识库、合同文档、制度文件、财报研报、招投标文件、扫描档案、图文混排资料的统一解析、结构化处理与 RAG 检索问答
1. 文档概述
1.1 背景
在企业知识管理、智能问答、合规检索、档案数字化等场景中,PDF 是最常见但也最复杂的文档载体之一。其复杂性主要体现在以下几个方面:
• 来源多样:包括 Office 导出的电子 PDF、扫描件 PDF、图文混排 PDF、表格型 PDF、图片嵌入型 PDF、签章版 PDF 等。 • 内容形态复杂:既包含纯文本,也可能包含图片、图表、公式、页眉页脚、多栏布局、表格、印章、水印、批注等信息。 • 解析质量差异大:不同 PDF 的文本层质量、OCR 难度、版面结构、图表密度差异显著。 • 业务要求高:企业场景不仅要求“能读出来”,更要求可追溯、可审计、可扩展、可控成本、可持续优化。
因此,企业级 PDF 处理不宜采用单一解析链路,而应建设一套面向生产环境的智能处理平台,按文档特征自动分流到最合适的处理路线,并统一输出为适合知识检索与 RAG 应用使用的标准知识对象。
1.2 建设目标
本方案旨在建设一套可规模化、可治理、可观测的企业级 PDF 智能处理平台,实现以下目标:
1. 建立自动化的 PDF 类型识别与分流体系。 2. 针对不同 PDF 类型采用最优处理策略: • 纯文本 PDF:直接文本抽取与结构化入库; • 扫描件 PDF:OCR + 版面恢复 + 质检入库; • 图文混排 PDF:文本、表格、图表、图片的多模态联合处理。 3. 统一构建可用于向量检索、关键词检索、混合检索、问答溯源的知识对象。 4. 建立质量门控、人工复核、失败重试、监控告警、权限治理等生产能力。 5. 为企业级 RAG 提供稳定、可信、可扩展的底层文档处理基础设施。
1.3 适用对象
本技术方案适用于以下角色参考与实施:
• 企业架构师 • AI 平台研发团队 • 知识库与搜索平台研发团队 • OCR/文档智能化建设团队 • 运维与平台治理团队 • 项目管理与技术评审团队
2. 设计原则
整套系统遵循以下设计原则。
2.1 检测在前,处理分流
系统不假设所有 PDF 均适合同一条处理链路。所有文档在正式解析前,必须经过基础检测和分类,根据文档特征自动进入最合适的处理路线。
2.2 页面级处理优于文档级粗分类
现实中的 PDF 往往是混合型文档。例如同一份文件可能同时包含电子正文、扫描附件、财务图表和盖章页。因此建议采用文档级初判与页面级精分流结合的机制,避免整本文档误走同一条路线。
2.3 统一出口,屏蔽底层差异
无论底层采用文本抽取、OCR、表格识别还是多模态视觉理解,最终都应汇总为统一的知识对象模型,供上层索引、检索、问答和审计模块复用。
2.4 质量优先于吞吐
生产系统中,低质量解析结果进入知识库的危害通常大于暂时不入库。因此必须建立质量评估、置信度门槛与异常兜底机制。
2.5 人工复核是正式能力
人工复核不应被视为临时补丁,而应作为系统标准能力纳入设计,用于处理 OCR 低置信、图表识别异常、表格结构损坏、模型输出不稳定等场景。
2.6 成本与精度动态平衡
并非所有页面都值得调用昂贵的多模态大模型。系统应通过页面级分流、区域级处理和高价值文档分级策略,实现成本可控前提下的效果最优。
3. PDF 类型划分与总体处理思路
本方案建议将企业 PDF 至少划分为三类主处理路径。
3.1 类型 A:纯文本 PDF
定义
纯文本 PDF 指具备可用文本层、文本可直接提取、图片区域较少、整体版面较规则的文档。
典型文档
• Office 导出的制度文件 • 产品说明书 • 电子版合同 • 研究报告电子稿 • 公司内部流程文档
处理策略
• 直接抽取文本层; • 保留章节结构、页码、段落边界、表格/图片引用; • 进行结构化切块; • 生成 embedding 并构建检索索引; • 统一进入 RAG 知识库。
关键要求
纯文本 PDF 虽可直接进入 RAG 链路,但不应只做粗暴切块。生产环境中必须保留结构元数据,否则将影响精准召回、答案溯源与前端定位。
3.2 类型 B:扫描件 PDF
定义
扫描件 PDF 主要由页面图像构成,文本层缺失或无法直接使用,必须先完成 OCR 才能转化为可检索文本。
典型文档
• 纸质合同扫描版 • 盖章文件扫描版 • 发票、票据、报销单 • 历史档案 PDF • 手机拍照合成 PDF
处理策略
• 页面转图; • 图像增强预处理; • OCR 识别; • 版面分析与阅读顺序恢复; • 低置信检测与人工复核; • 结构化切块并入知识库。
关键要求
OCR 完成后不能直接将文本拼接入库,必须保留 bbox、置信度和版面信息,以支撑阅读顺序恢复、审计定位和人工校对。
3.3 类型 C:图文混排 PDF
定义
图文混排 PDF 指同时包含文本、图表、表格、流程图、截图、照片等视觉信息的复杂文档,单靠文本层无法完整表达语义。
典型文档
• 财报、年报、审计报告 • 行业分析报告 • 解决方案白皮书 • 医疗报告 • 工程说明资料 • 带流程图的制度文档 • 培训材料与汇报材料
处理策略
• 按页面进行区域分割; • 将文本区、表格区、图表区、图片区分别送入对应解析链路; • 对图表和图片补充视觉语义描述与结构化结果; • 与周边正文上下文融合; • 统一入库并构建多模态索引。
关键要求
图文混排文档不能仅依赖文本抽取。图表趋势、表格数据、流程步骤和界面截图等内容,往往是企业知识问答中的关键信息源。
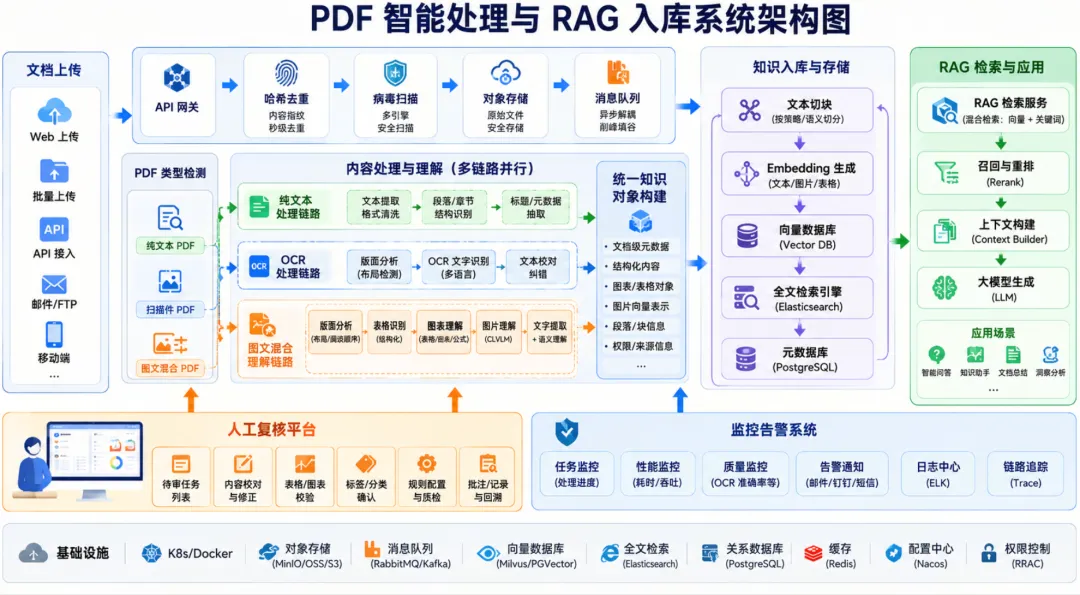
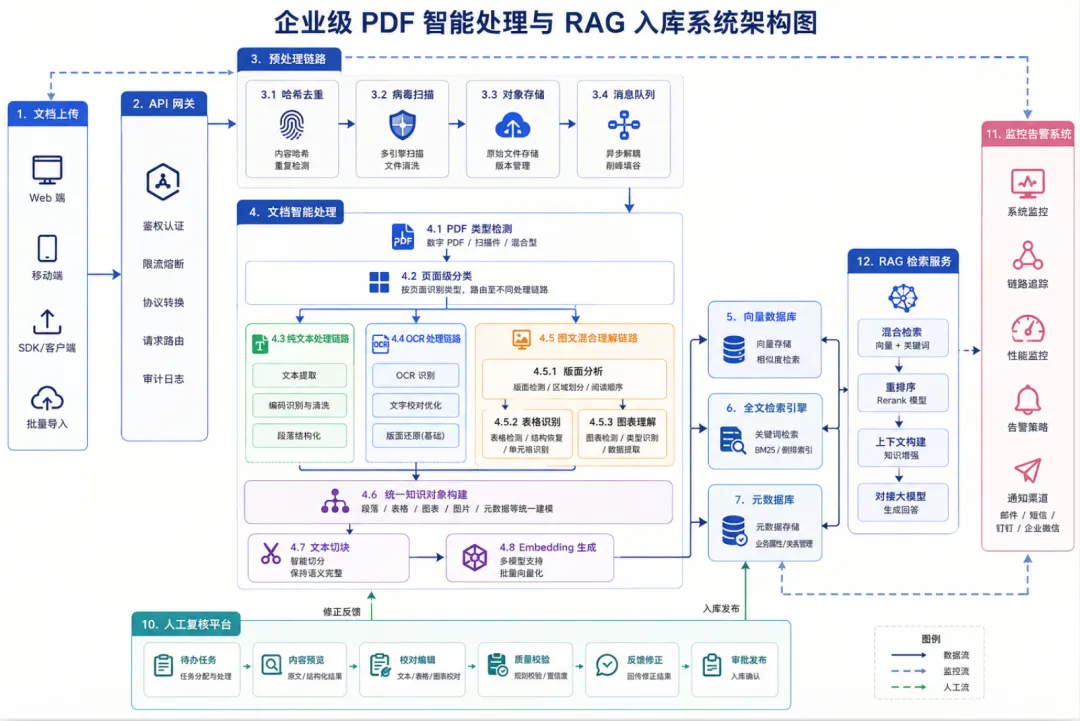
4. 总体架构设计
4.1 架构分层
整体架构划分为以下八层:
1. 文档接入层 2. 预处理与安全校验层 3. 文档检测与分流层 4. 多路线解析处理层 5. 质量控制与人工复核层 6. 统一知识对象构建层 7. 存储与索引层 8. 检索与 RAG 服务层 4.2整体架构图
5. 文档接入与预处理设计
5.1 接入能力要求
接入层负责将各来源文档标准化地引入处理平台,建议支持:
• 单文件上传 • 批量上传 • OpenAPI 推送 • 目录同步 • 邮件抓取 • 第三方系统回调接入
同时应支持:
• 企业统一认证 • 租户隔离 • 文档分类标签 • 来源系统标识 • 保密等级标识 • 操作人信息记录
5.2 基础校验要求
所有 PDF 进入处理流程前,建议执行以下校验:
1. MIME 白名单校验仅允许合法 PDF 文件进入处理流程。 2. 文件大小限制例如单文件不超过 500MB,超大文件异步处理。 3. 页数限制例如默认 2000 页以内,超限文档走专用大文档队列。 4. SHA-256 哈希去重对重复文档命中缓存,避免重复解析。 5. 病毒扫描建议采用 ClamAV 或企业现有安全服务。 6. 原件归档原始 PDF 上传成功后应立即进入对象存储归档,避免散落在处理节点本地。
5.3 推荐实现
• API Gateway:Nginx / Kong / APISIX • 上传服务:Spring Boot / Go • 对象存储:S3 / MinIO / OSS / COS • 去重键: tenant_id + sha256
6. 异步任务与队列设计
6.1 异步化必要性
PDF 解析链路中包含 OCR、版面分析、多模态理解、索引构建等耗时步骤,不适合同步阻塞上传请求。生产环境中应全部采用异步任务模式。
6.2 推荐队列划分
建议按照职责拆分多个主题或队列:
• pdf_ingest_queue:接入总入口• pdf_classify_queue:文档分类队列• pdf_text_parse_queue:纯文本解析队列• pdf_ocr_queue:OCR 处理队列• pdf_multimodal_queue:图文混合处理队列• pdf_review_queue:人工复核队列• pdf_index_queue:索引构建队列• pdf_retry_queue:失败重试队列• pdf_dlq:死信队列
6.3 消息体建议字段
消息体至少应包含以下字段:
• doc_id• tenant_id• source_uri• sha256• priority• document_type• page_ranges• retry_count• trace_id• operator• security_level
6.4 技术建议
• Kafka:高吞吐、适合大型企业平台 • RabbitMQ:流程控制清晰、适合中等规模 • SQS:适合云原生场景
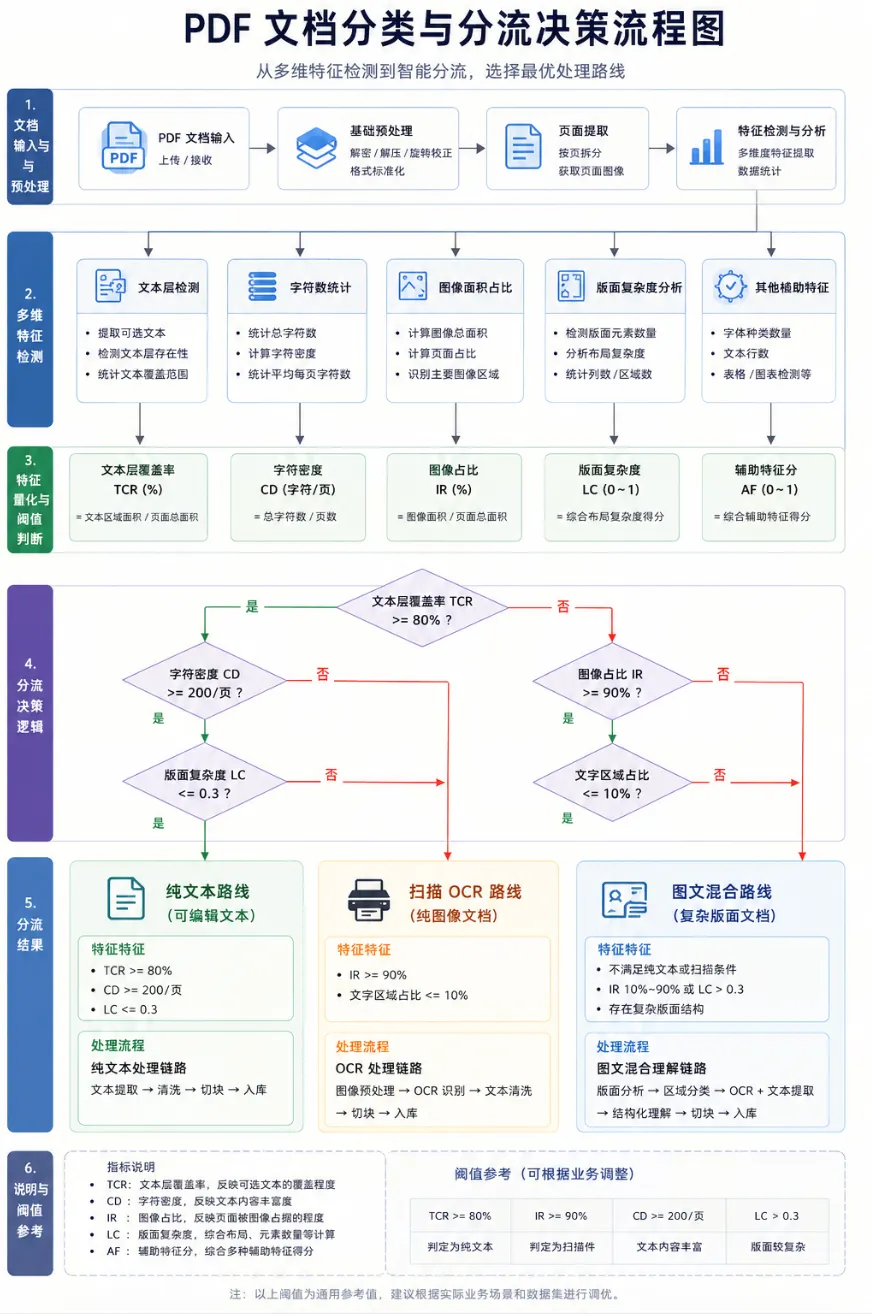
7. 文档检测与分流设计
文档检测与分流是整个系统的核心中枢,其目标是用最小成本判断文档和页面最适合进入哪条处理链路。
7.1 检测目标
需要回答以下问题:
1. 文档是否具备可直接使用的文本层? 2. 哪些页面属于扫描页? 3. 哪些页面包含表格、图表、图片密集区域? 4. 是否需要进入高精度处理模式? 5. 是否需要进入人工复核队列?
7.2 推荐检测顺序
第一步:PDF 基础信息提取
提取以下信息:
• 总页数 • 页面对象数量 • 字体对象数量 • 图片对象数量 • 是否存在文本层 • 页面尺寸 • 文件元信息
工具建议:
• PyMuPDF • pdfplumber • pypdf
第二步:文本层可用性检测
按页统计:
• 提取字符数 • 有效字符比例 • 乱码率 • 重复字符率 • 空白率
判定建议:
• 每页有效字符数较高且乱码率低,可判为文本页; • 虽存在文本层但内容大量乱码或无序时,不应直接视为文本页。
第三步:图像占比检测
按页统计:
• 图像区域面积占比 • 图片对象个数 • 大图覆盖率 • 图像分辨率估算
判定建议:
• 图像面积占比较高且字符数极少时,通常视为扫描页。
第四步:版面复杂度检测
检测:
• 多栏布局 • 表格密度 • 图表区域 • 标题区块 • 页眉页脚重复模式
工具建议:
• LayoutParser • Detectron2 • PaddleOCR Layout 系列能力
第五步:页面级分类
页面标签建议定义为:
• TEXT• SCANNED• TABLE_HEAVY• CHART_HEAVY• IMAGE_HEAVY• MIXED• LOW_CONFIDENCE
第六步:文档级汇总判定
按页面分布汇总:
• 以文本页为主,进入路线 A; • 以扫描页为主,进入路线 B; • 多种页面混杂,进入路线 C; • 低置信页面占比较高,进入增强处理或人工复核。
7.3 规则示意
if text_chars_per_page >= 100 and image_area_ratio < 0.4: route = Aelif text_chars_per_page < 30 and image_area_ratio > 0.8: route = Belse: route = C生产环境中,建议基于以下特征建立综合评分:
• has_text_layer_score• ocr_needed_score• layout_complexity_score• chart_density_score• table_density_score• image_dominance_score
优先从规则引擎起步,后续根据实际数据演进为轻量分类模型。
8. 路线 A:纯文本 PDF 处理方案
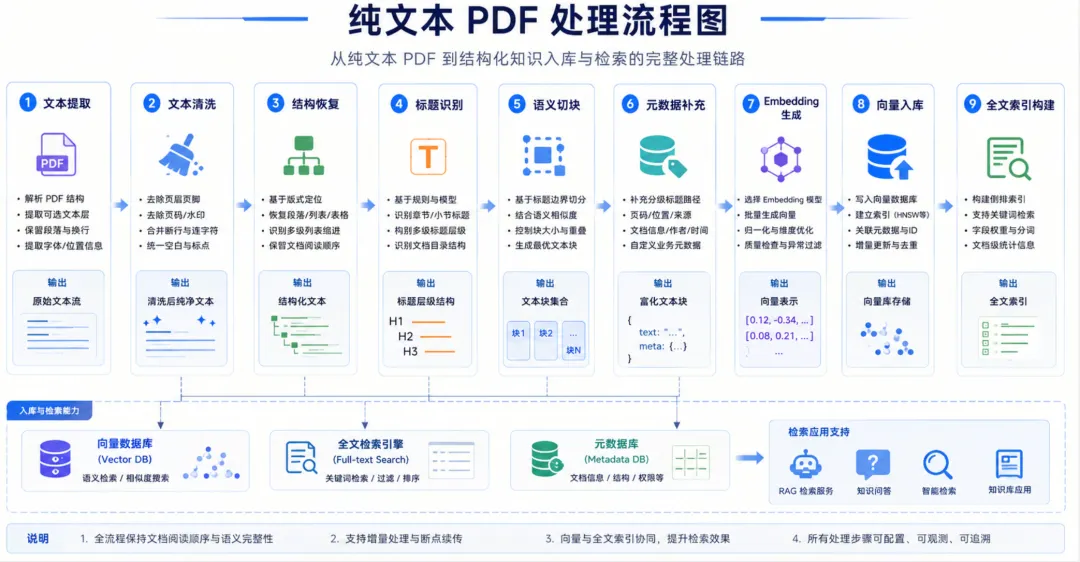
8.1 处理目标
以最低成本和较高吞吐,尽可能完整保留文档语义与结构,生成可直接用于 RAG 和检索的知识片段。
8.2 标准处理流程
1. 文本提取 2. 文本清洗 3. 结构恢复 4. 章节与段落识别 5. 表格/图片占位识别 6. 语义切块 7. 元数据补齐 8. Embedding 生成 9. 索引入库
8.3 文本提取工具建议
建议优先使用:
1. PyMuPDF性能好,页面对象提取能力强。 2. pdfplumber对版面辅助处理更友好,可作为补充或校验。 3. Apache Tika可作为通用兜底工具。
推荐策略:
• 主引擎:PyMuPDF • 兜底引擎:pdfplumber
8.4 文本清洗规范
生产级清洗建议包括:
• 去除连续空白字符 • 去除重复页眉页脚 • 去除页码污染 • 去除水印残留文本 • 合并被错误断开的段落 • 修复乱码字符 • 统一全角半角 • 标准化标点 • 保留原始换行信息辅助结构恢复
注意:清洗不能破坏原始结构语义,标题、编号、列表和表格前后说明必须尽量保留。
8.5 结构恢复要求
应尽量恢复以下结构信息:
• 标题层级:H1 / H2 / H3 • 段落边界 • 列表项 • 表格引用 • 图片引用 • 页码边界 • 章节路径
结构化对象示例:
{ "doc_id": "DOC123", "page": 12, "section_path": ["第三章", "2.1 风险控制", "2.1.3 审批流程"], "block_type": "paragraph", "text": "……"}8.6 切块策略
企业环境中不建议采用单纯固定长度切块,推荐父子切块策略。
父块
• 目标:保留完整语义上下文 • 建议大小:800~1500 tokens
子块
• 目标:提升精准召回能力 • 建议大小:200~400 tokens
切块边界优先级
1. 章节边界 2. 段落边界 3. 列表边界 4. 表格前后说明边界 5. 句号或换行边界 6. 最后才按 token 强切
不建议做法
• 全文按固定 token 粗暴切块 • 忽略页码与章节信息 • 一个 chunk 跨越多个主题段落
9. 路线 B:扫描件 PDF 处理方案

9.1 处理目标
将不可直接提取文本的扫描页,转换为高质量、可结构化、可检索、可追溯的知识对象。
9.2 标准处理流程
1. 页面转图 2. 图像增强预处理 3. OCR 识别 4. 版面分析 5. 阅读顺序恢复 6. 表格/印章/水印处理 7. 低置信检测 8. 人工复核分流 9. 结构化切块与入库
9.3 图像预处理要求
建议至少包括以下步骤:
• 去噪 • 倾斜校正 • 自适应二值化 • 对比度增强 • 亮度修复 • 分辨率补齐至约 300 DPI • 黑边与阴影去除 • 页面边缘裁切
可选增强:
• 手机拍照透视校正 • 背景纹理抑制 • 手写区域增强 • 印章干扰弱化
工具建议:
• OpenCV • Pillow • ImageMagick
9.4 OCR 引擎选型
建议采用分层引擎策略。
开源基础层
• PaddleOCR:中文能力较强,适合通用场景 • Tesseract 5:英文基础能力较好,可作为低成本兜底
商业高精度层
• Azure Document Intelligence • Google Document AI • AWS Textract • 百度智能云 OCR • 阿里云 OCR
推荐策略
• 普通文档:PaddleOCR • 高价值关键文档:商业 OCR 或专项模型 • 特定票据类文档:专票/表单模型优先
9.5 OCR 输出结构要求
OCR 输出不应仅保留纯文本,应至少包含以下信息:
{ "page": 5, "blocks": [ { "bbox": [x1, y1, x2, y2], "text": "合同编号", "confidence": 0.96, "type": "text" } ]}必须保留:
• bbox 坐标 • 文本内容 • 置信度 • 行块关系 • 页面尺寸 • 原图引用
9.6 版面分析与阅读顺序恢复
需要重点解决:
• 多栏文本串行 • 标题与正文顺序错乱 • 页眉页脚混入正文 • 表格内容混入段落 • 批注与印章干扰
推荐处理方法:
1. 识别文本区、表格区、图片区、页眉页脚区; 2. 按版面结构建立阅读顺序; 3. 页眉页脚与正文分离; 4. 表格区域进入表格解析器。
工具建议:
• LayoutParser • PaddleOCR PP-Structure • 商业 Document AI 的 layout 输出
9.7 OCR 质量门控
建议关注以下指标:
• 平均字符置信度 • 低置信词占比 • 空白页率 • 乱码率 • 重复识别率 • 阅读顺序完整性评分
建议门槛示例:
• 页面平均置信度低于阈值:进入复核 • 低置信文本块占比较高:切换引擎或增强图像后重跑 • 多页连续空白:触发质量告警 • 文档整体有效字符过低:不入库
10. 路线 C:图文混排 PDF 处理方案
10.1 处理目标
同时保留文档中的文本知识、表格知识、图表知识和图片语义,构建适用于多模态检索与问答的统一知识库。
本路线的目标不是“把复杂页面解释得差不多”,而是将一页图文混排 PDF 拆解为一组可管理、可追踪、可重跑、可审计的标准知识对象,使研发团队能够明确知道每一步做什么、输入输出是什么、失败时如何处理。
10.2 实现原则
路线 C 的实现建议遵循以下原则:
1. 先分区,后处理不直接把整页 PDF 送给多模态模型,而是先做版面切分,再按区域类型调用不同能力。 2. 同页内按区域复用已有链路文本区复用路线 A 或路线 B,表格区走表格解析链路,图表区走图表理解链路,避免重复建设。 3. 统一结构化输出每个区域最终都要产出标准知识对象,而不是散落成多种非统一格式。 4. 先抽取事实,再生成摘要对图表和表格,优先输出结构化字段,再根据结构化字段生成自然语言摘要,避免直接生成不可校验的描述。 5. 保留原始坐标与证据所有区域都必须保留页面坐标、页面号、裁剪图地址、原文邻接关系,用于前端溯源和人工复核。
10.3 页面级处理总流程
建议将图文混排页的处理拆成如下 11 个步骤:
1. PDF 页面渲染为标准图片 2. 页面级初筛,判断是否进入路线 C 3. 页面区域检测,产出页面区块列表 4. 区块标准化与排序,建立阅读顺序 5. 按区块类型路由到对应处理器 6. 文本区提取正文与标题 7. 表格区提取二维结构与文本摘要 8. 图表区提取图表类型、关键值和趋势摘要 9. 图片区提取 caption 与视觉向量 10. 进行跨区块融合,补齐上下文关系 11. 统一生成知识对象并入库
建议按页异步处理,单页处理完成后即可入后续索引队列,不必等待整本文档全部完成。

10.4 页面输入与处理结果定义
为便于研发实现,建议先定义路线 C 的页面输入输出。
页面输入对象
{ "doc_id": "doc_001", "tenant_id": "t_001", "page": 12, "pdf_uri": "s3://bucket/a.pdf", "page_image_uri": "s3://bucket/pages/doc_001/12.png", "width": 2480, "height": 3508, "dpi": 300, "security_level": "internal"}页面输出对象
{ "doc_id": "doc_001", "page": 12, "page_type": "mixed", "regions": [], "knowledge_blocks": [], "page_confidence": 0.92, "route": "C"}其中:
• regions表示版面检测出的页面区域;• knowledge_blocks表示最终可入库的统一知识块;• page_confidence表示该页整体处理质量评分。
10.5 页面进入路线 C 的判定规则
建议当页面满足以下任一条件时进入路线 C:
• 文本层存在,但图片、表格或图表区域占比高; • 版面检测到 2 个及以上异构区域类型; • 页面中存在明确图表、表格或流程图; • 文本可抽取,但正文占比不足以表达页面主要语义; • 页面分类器输出 MIXED、TABLE_HEAVY、CHART_HEAVY或IMAGE_HEAVY。
建议的工程判定逻辑如下:
if chart_count >= 1: route = Celif table_count >= 1 and text_area_ratio < 0.8: route = Celif image_area_ratio >= 0.35 and text_area_ratio >= 0.2: route = Celif region_type_count >= 2: route = Celse: route = A or B10.6 区域检测与标准化
页面进入路线 C 后,第一步不是 OCR,也不是调用多模态模型,而是先做区域检测。
10.6.1 区域类型定义
建议页面区域类型固定为以下枚举:
• title_block• text_block• list_block• table_block• chart_block• figure_block• formula_block• header• footer• stamp• signature• unknown
10.6.2 区域检测输出格式
{ "region_id": "r_12_003", "page": 12, "region_type": "chart_block", "bbox": [240, 820, 1960, 1680], "score": 0.95, "page_image_uri": "s3://bucket/pages/doc_001/12.png"}10.6.3 区域检测实施建议
• 对电子 PDF,优先结合 PDF 对象信息和页面图像做联合判断; • 对扫描页,优先基于页面图像做区域检测; • 对低置信区域保留 unknown类型,不强行归类;• 对明显重叠区域进行后处理去重,避免同一区域被重复处理。
10.6.4 区域后处理规则
建议在检测后增加一轮标准化:
1. 合并高度重叠的同类框; 2. 删除面积过小的噪声框; 3. 将页眉页脚与正文块分离; 4. 给所有区域分配稳定 region_id;5. 基于坐标排序,生成页面阅读顺序 reading_order。
阅读顺序建议采用:
• 先按上边界 y1排序;• 对同一行的区域,再按左边界 x1排序;• 多栏页面增加“列聚类”规则,避免左右栏串行。
10.7 路由层设计
区域检测完成后,系统应进入“区域路由器”阶段。该组件的作用是根据 region_type 把每个区域分发到正确的处理器。
建议映射如下:
10.8 文本区处理方案
文本区的处理不要单独再造一套链路,而是复用路线 A 或路线 B。
10.8.1 判定规则
对每个 text_block 或 title_block:
• 若该区域可直接提取文本层,则走路线 A 的文本抽取逻辑; • 若文本层缺失或质量差,则把区域裁剪为图片,走 OCR 逻辑; • 若区域内含大量噪声或印章干扰,则优先做局部图像增强再 OCR。
10.8.2 输出要求
文本区建议输出:
{ "region_id": "r_12_001", "region_type": "text_block", "content": "审批流程分为提交、复核、归档三个阶段。", "section_path": ["第四章", "审批机制"], "confidence": 0.98, "bbox": [180, 260, 2100, 760]}10.8.3 标题与正文关系恢复
如果页面中存在 title_block,应将其与其后的正文块绑定,作为 section_path 的候选来源。实现时建议:
• 标题块不单独孤立入库; • 标题块同时参与父块构建; • 后续正文块继承最近的标题路径。
10.9 表格区处理方案
表格区的关键不是“识别出文字”,而是恢复表格结构。
10.9.1 处理步骤
1. 裁剪表格区域; 2. 判断表格来源:电子表格还是扫描表格; 3. 电子表格优先使用表格结构提取工具; 4. 扫描表格先 OCR,再做单元格检测与结构恢复; 5. 生成二维表结构; 6. 对表格生成摘要文本; 7. 将结构化结果与摘要同时入库。
10.9.2 表格输出要求
至少保留以下字段:
{ "region_id": "r_12_004", "region_type": "table_block", "table_title": "2025-2026年营收情况", "headers": ["季度", "营收", "同比增长"], "rows": [ ["Q1", "1.2亿", "15%"], ["Q2", "1.5亿", "18%"] ], "summary": "表格展示 2025 年 Q1 与 Q2 营收及同比增长,Q2 高于 Q1。", "confidence": 0.91, "bbox": [200, 1700, 2200, 2500]}10.9.3 表格摘要生成建议
表格摘要不要直接让大模型自由发挥,建议基于结构化数据生成,至少包含:
• 表格标题 • 行列维度说明 • 关键数值 • 对比关系或趋势
10.9.4 表格失败兜底
若表格结构恢复失败:
• 保留 OCR 文本作为临时降级结果; • 标记 table_structure_failed = true;• 对高价值文档进入人工复核。
10.10 图表区处理方案
图表区是路线 C 最容易写得空泛、也最容易在实施中失控的部分。要真正落地,必须拆成固定步骤。
10.10.1 图表处理步骤
1. 裁剪图表区域; 2. 检测图表标题、图例、坐标轴、数据标签; 3. 识别图表大类; 4. 调用视觉模型提取关键数值与趋势; 5. 生成结构化 JSON; 6. 基于 JSON 生成简洁可控的自然语言摘要; 7. 与图注和邻接正文融合后入库。
10.10.2 图表类型建议枚举
• bar_chart• line_chart• pie_chart• scatter_plot• radar_chart• flow_chart• org_chart• timeline• unknown_chart
10.10.3 图表输出结构
{ "region_id": "r_12_005", "region_type": "chart_block", "chart_type": "bar_chart", "title": "季度营收同比增长", "x_axis": "季度", "y_axis": "同比增长", "key_values": [ {"label": "Q1", "value": "15%"}, {"label": "Q2", "value": "18%"} ], "trend": "upward", "summary": "图表显示 Q2 的同比增长高于 Q1,整体呈上升趋势。", "confidence": 0.88, "bbox": [220, 900, 2160, 1680]}10.10.4 图表提示词设计要求
如果采用 Vision LLM,提示词应固定要求模型输出 JSON,不允许只输出自然语言。提示词至少要约束:
• 图表类型; • 标题; • 横轴、纵轴; • 可识别的关键值; • 趋势判断; • 不确定字段填 null;• 禁止编造看不清的数据。
10.10.5 图表结果校验
图表输出后必须做程序校验:
• JSON schema 是否合法; • chart_type是否在允许范围内;• key_values是否为空;• 关键数值是否格式异常; • summary是否与结构化字段矛盾。
校验失败时建议:
1. 重试一次更强模型; 2. 若仍失败,退化为图片 caption; 3. 高价值页送人工复核。
10.11 图片区处理方案
对于普通图片、截图、流程图、实物照片等区域,处理目标是补充“图片在表达什么”,而不是强求还原全部细节。
10.11.1 处理步骤
1. 裁剪图片区域; 2. 识别图片类型; 3. 生成简洁 caption; 4. 生成图像 embedding; 5. 结合相邻正文生成上下文描述; 6. 统一入知识库。
10.11.2 图片输出格式
{ "region_id": "r_12_006", "region_type": "figure_block", "figure_type": "screenshot", "caption": "图片展示了审批系统中的待办列表页面。", "context_text": "该界面用于审批人员查看待处理任务。", "confidence": 0.9, "bbox": [260, 2540, 2000, 3300]}10.11.3 图片处理边界
• 对普通照片和截图,不要求还原所有小字; • 若截图中包含大段关键文字,应拆出文本区额外 OCR; • 若图片区实质是流程图或组织架构图,应优先归入 chart_block或特殊图示类,而不是普通图片。
10.12 跨区域融合与上下文补齐
路线 C 真正决定效果的,不是单个区域处理得多好,而是最后能不能把页面重新组织成有上下文的知识片段。
10.12.1 为什么要做融合
如果各区域独立入库,会出现以下问题:
• 图表摘要缺少图注语境; • 表格不知道属于哪一章节; • 图片说明与正文脱节; • 页面问答时无法正确拼接上下文。
10.12.2 融合规则建议
对每个非文本区域,补齐以下上下文:
• 最近标题块 • 最近上方正文块 • 最近下方图注或说明块 • 所属章节路径 • 页面阅读顺序前后邻居
示例:
• 图表块上方 150px 内有标题块,则将其作为图表标题候选; • 图表下方 120px 内有短文本块,则将其识别为图注候选; • 表格前后的说明段落可作为摘要生成辅助上下文。
10.13 统一知识块构建规则
完成区域处理和跨区融合后,必须将所有结果转换为统一知识块。
建议一页图文混排页面最终至少生成以下几类知识块:
1. 页面正文知识块 2. 表格知识块 3. 图表知识块 4. 图片说明知识块 5. 页面级摘要块
页面级摘要块建议
页面级摘要块不是必须直接给用户展示,但它对检索很有帮助。建议汇总本页的:
• 标题 • 正文主题 • 表格摘要 • 图表摘要 • 图片摘要
10.14 路线 C 的推荐工程拆分
为了便于落地,建议把路线 C 拆成以下几个独立服务或模块:
1. page-renderer:页面渲染2. layout-detector:区域检测3. region-router:区域路由4. text-region-parser:文本区域处理5. table-region-parser:表格区域处理6. chart-region-parser:图表区域处理7. figure-region-parser:图片区处理8. context-fuser:上下文融合9. knowledge-builder:统一知识块构建10. quality-gate:质量门控与复核分流
这样的拆分便于:
• 独立扩容; • 局部重试; • 替换单个解析器; • 跟踪每一类区域的错误率。
10.15 质量门控与失败处理
路线 C 必须明确失败处理,否则非常难运维。
页面级检查项
• 是否存在有效区域; • 区域总面积是否异常; • 关键区域是否全部处理完成; • 页面是否生成了可入库知识块; • 页面级置信度是否达标。
区域级检查项
• 文本区是否抽取到有效文本; • 表格区是否恢复出表头与行数据; • 图表区是否成功输出结构化 JSON; • 图片区是否生成 caption; • unknown区域比例是否过高。
建议失败策略
• 单个区域失败:允许局部降级,不阻塞整页; • 核心区域失败:整页标记 partial_success;• 图表结构化失败:退化为 caption; • 表格结构化失败:退化为 OCR 文本; • 页面整体低置信:进入人工复核。
10.16 路线 C 的最小可落地版本
如果团队希望先落地一个能上线的版本,建议最小版本只做以下能力:
1. 页面区域检测; 2. 文本区复用路线 A/B; 3. 表格区输出结构化表格 + 简单摘要; 4. 图表区先输出 caption + 粗粒度图表类型; 5. 图片区输出 caption; 6. 完成统一知识块入库; 7. 完成页码、bbox、原图溯源。
等最小版本跑稳后,再逐步增强:
• 图表关键数值抽取; • 流程图结构理解; • 组织架构图关系抽取; • 更复杂的页面级摘要生成。
11. 统一知识对象模型设计
统一知识对象模型是整个系统可持续演进的关键。
11.1 设计目标
通过统一数据出口,屏蔽不同解析链路的差异,支撑以下能力:
• 统一索引构建 • 统一检索接口 • 统一前端展示 • 统一权限控制 • 统一审计与回溯
11.2 推荐结构
{ "knowledge_id": "kg_001", "doc_id": "doc_123", "tenant_id": "t_001", "page": 10, "block_id": "blk_10_03", "block_type": "paragraph", "modality": "text", "content": "审批流程分为提交、复核、归档三个阶段。", "section_path": ["第四章", "审批机制"], "bbox": [100, 120, 820, 240], "parent_block_id": "parent_10_01", "source_file_uri": "s3://bucket/xxx.pdf", "source_image_uri": "s3://bucket/pages/10.png", "confidence": 0.97, "parser_route": "A", "security_level": "internal", "version": 3, "created_at": "2026-06-09T10:00:00Z"}11.3 建议枚举字段
block_type
• title• paragraph• list• table• table_summary• figure• chart• chart_summary• image_caption• footer• header• signature• stamp
modality
• text• table• image• chart• mixed
12. 存储与索引设计
12.1 存储分层建议
1)对象存储
保存:
• 原始 PDF • 页面图片 • 图表裁剪图 • OCR 中间结果 • 人工修订版本
推荐:S3 / MinIO / OSS
2)关系型数据库
保存:
• 文档元信息 • 处理状态 • 任务日志 • 审计记录 • 版本关系 • 权限信息
推荐:PostgreSQL
3)全文检索引擎
保存:
• 原始文本 • 结构化文本 • 表格摘要 • 图表摘要 • 高亮定位字段
推荐:Elasticsearch / OpenSearch
4)向量数据库
保存:
• 文本 embedding • 图像 embedding • 多模态 embedding
推荐:Qdrant / Milvus / pgvector / Pinecone
12.2 双引擎检索必要性
企业场景中,很多查询不仅依赖语义,还依赖精确关键词,例如:
• 文件编号 • 合同编号 • 专有名词 • 固定条款 • 日期与百分比
因此推荐采用全文检索 + 向量检索的混合方案,而不是单一语义检索。
13. RAG 检索与生成方案
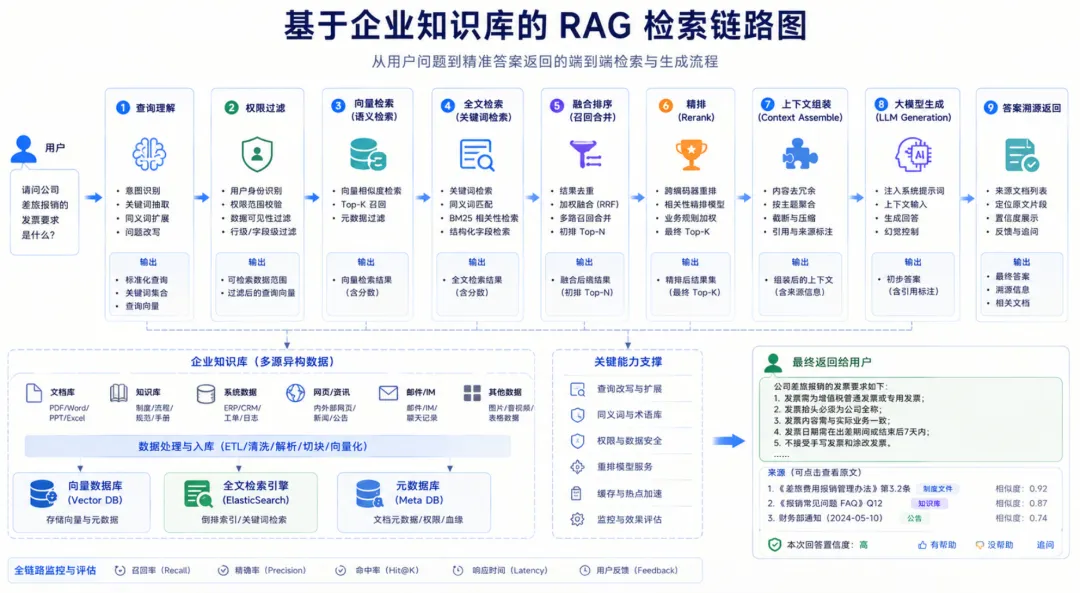
13.1 标准检索流程
1. 查询理解 2. 权限过滤 3. 向量检索 topK 4. 全文检索 topK 5. RRF 融合 6. Cross-Encoder 精排 7. 上下文组装 8. 大模型生成 9. 溯源返回
13.2 召回与排序建议
• 向量检索: topK = 20 ~ 50• 全文检索: topK = 20 ~ 50• 融合方式:RRF • 精排:Cross Encoder 或 reranker 模型 • 最终送生成模型上下文: top 5 ~ 10
13.3 上下文组装原则
上下文组装时,建议:
• 合并同页相邻 chunk • 补充所属章节标题 • 保留图表摘要与图注 • 同一表格优先保持整体 • 附加页码、文档名、块类型等溯源信息
13.4 溯源要求
最终回答建议同时返回:
• 文件名 • 页码 • 章节路径 • 证据片段摘要 • 原文定位信息
该能力是提升企业用户信任度的关键。
14. 质量控制与人工复核设计
14.1 质量控制原则
系统应遵循“不合格不入库”的原则。低质量解析结果若直接进入知识库,将长期污染检索与问答效果。
14.2 质量门控点
建议设置以下门控环节:
接入前
• MIME 合法性 • 病毒扫描 • 文件完整性
分类后
• 路线判定置信度
抽取后
• 字符数 • 乱码率 • 重复率
OCR 后
• 平均置信度 • 阅读顺序评分 • 空白页率
多模态后
• JSON schema 校验 • 图表字段缺失率 • 数值识别合理性
入库前
• 页数一致性 • chunk 数量异常检测 • embedding 非法值检测
14.3 人工复核触发条件
满足任一条件时可进入人工复核:
• OCR 平均置信度过低 • 页面分类低置信 • 图表理解输出缺关键字段 • 表格结构损坏严重 • 用户反馈命中结果错误 • 高价值文档要求强制复核
14.4 HITL 工作台建议能力
• 原文与解析结果并排展示 • bbox 高亮定位 • OCR 文本逐块修正 • 表格结构修正 • 图表摘要修正 • 审核记录留痕 • 修订版本回写与重新入库
工具建议:
• Label Studio • Prodigy • 自研轻量审核平台
15. 可观测性与运维设计
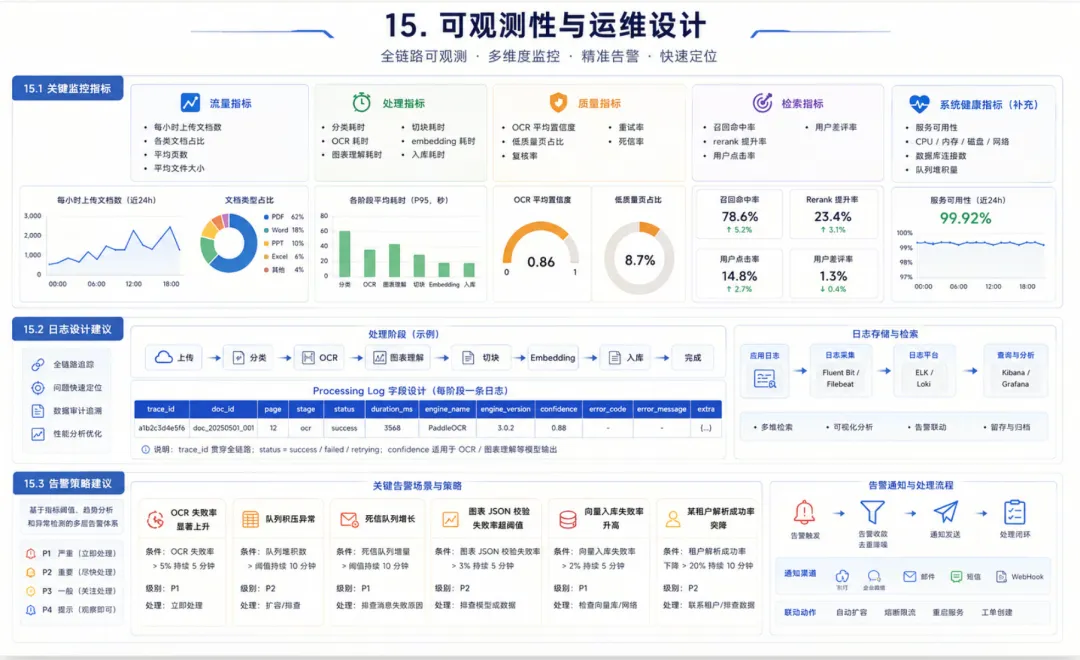
15.1 关键监控指标
流量指标
• 每小时上传文档数 • 各类文档占比 • 平均页数 • 平均文件大小
处理指标
• 分类耗时 • OCR 耗时 • 图表理解耗时 • 切块耗时 • embedding 耗时 • 入库耗时
质量指标
• OCR 平均置信度 • 低质量页占比 • 复核率 • 重试率 • 死信率
检索指标
• 召回命中率 • rerank 提升率 • 用户点击率 • 用户差评率
15.2 日志设计建议
建议为每一处理阶段记录 processing log,至少包含:
• trace_id• doc_id• page• stage• status• duration_ms• engine_name• engine_version• confidence• error_code• error_message
15.3 告警策略建议
推荐针对以下场景设置告警:
• OCR 失败率显著上升 • 队列积压异常 • 死信队列增长 • 图表 JSON 校验失败率超阈值 • 向量入库失败率升高 • 某租户解析成功率突降
16. 安全、权限与合规设计
16.1 数据安全
• 原始文件加密存储 • 传输全程 HTTPS • 敏感字段脱敏 • 审计日志留存 • 中间文件生命周期清理
16.2 权限隔离
• 租户级隔离 • 文档级 ACL • 部门级与角色级权限 • 检索前置过滤,禁止生成后过滤
16.3 合规要求
• 支持数据删除与回溯 • 支持文档版本管理 • 支持访问审计 • 高敏文档可禁用外部模型 • 对外部模型调用配置脱敏与白名单策略
17. 成本控制方案
17.1 成本主要来源
• OCR 费用 • Vision LLM 调用费用 • Embedding 费用 • 存储费用 • CPU/GPU 算力成本 • 人工复核成本
17.2 成本优化策略
1. 优先识别纯文本,避免无意义 OCR。 2. 页面级分流,避免整本文档走最贵路线。 3. 仅对真正的图表区域调用 Vision LLM。 4. Embedding 采用增量更新,避免全量重建。 5. 重复文档命中缓存直接复用。 6. 高价值文档走高精度模式,普通文档走标准模式。 7. 热数据与冷数据分层存储。
18. 推荐技术栈
18.1 服务与平台
• 后端服务:Java Spring Boot / Go • 消息队列:Kafka • 对象存储:MinIO / S3 / OSS
18.2 文档处理
• PDF 解析:PyMuPDF、pdfplumber • OCR:PaddleOCR + 商业 OCR 组合 • 版面分析:LayoutParser、PaddleOCR PP-Structure • 表格识别:Camelot / Paddle 表格识别 / 商业 Document AI • 图像理解:Vision LLM • 图像 embedding:CLIP / SigLIP
18.3 存储与检索
• 元数据:PostgreSQL • 全文检索:Elasticsearch / OpenSearch • 向量数据库:Qdrant / Milvus / pgvector
18.4 可观测性
• Prometheus • Grafana • Loki
19. 实施难点与规避建议
难点 1:分类不准导致路线走错
建议从规则引擎起步,保守分流。低置信文档进入增强处理或人工复核,而不是直接进入错误路线。
难点 2:OCR 看似成功但文本不可用
建议必须引入版面分析与阅读顺序恢复,不能仅看 OCR 是否输出了文字。
难点 3:图表理解成本失控
建议仅对检测出的图表区域调用 Vision LLM,避免整页多模态理解。
难点 4:低质量内容污染知识库
建议设置严格入库门槛,不合格内容不应进入正式检索库。
难点 5:RAG 命中但回答不可信
建议所有结果返回来源页码和证据片段,高风险问题显式展示来源摘要。
20. 结论
企业级 PDF 处理不应简单理解为“文档转文本”,而应建设为一套面向知识治理的多路线智能解析平台。
从生产落地角度,推荐采用以下统一方案:
• 纯文本 PDF:直接文本抽取 + 结构化切块 + RAG 入库; • 扫描件 PDF:图像增强 + OCR + 版面恢复 + 质量门控 + 入库; • 图文混排 PDF:区域分割 + 文本/表格/图表/图片分别处理 + 多模态融合入库。
最终通过统一知识对象模型、混合检索、人工复核闭环、可观测性与权限治理能力,构建一套真正可长期运行、可扩展、可审计、可优化的企业级 PDF 智能处理体系。
