 夜雨聆风
夜雨聆风nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
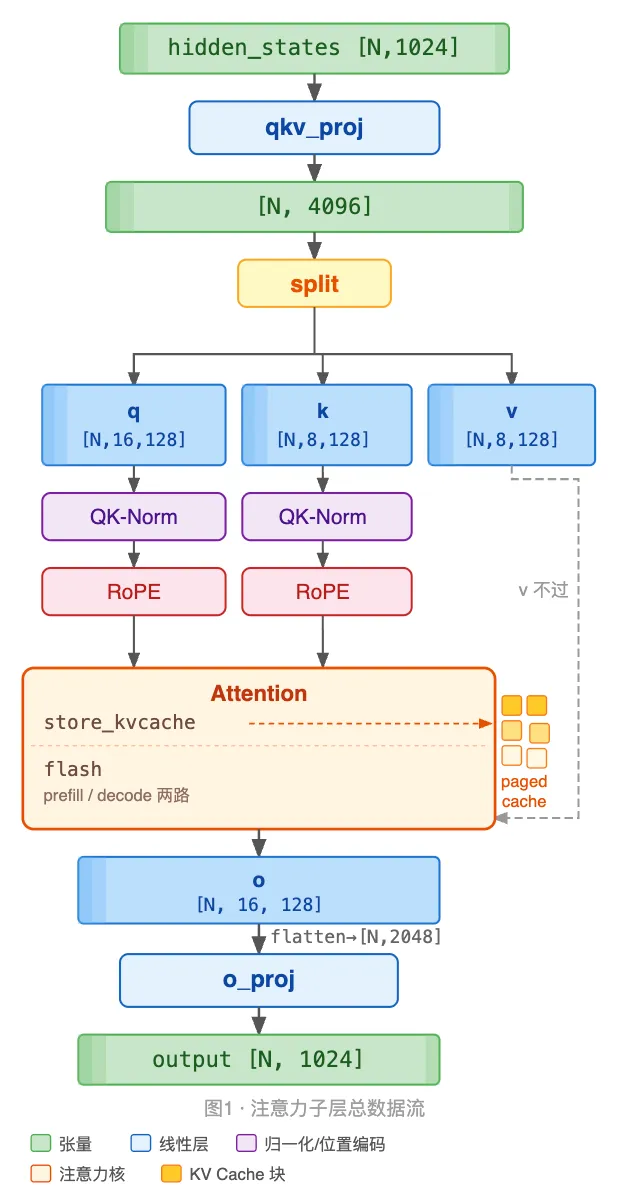
L14 到 L16 逐个讲解了注意力子层用到的模块:RMSNorm(L14)、RoPE(L15)、Linear 家族(L16)。本篇把它们按 forward 的真实顺序串成一条线,完整走通 Qwen3 的注意力子层 self_attn:从 hidden 投影出 q、k、v,对 q、k 归一化、旋转,把 k、v 写进 paged KV cache,做注意力,再投影回 hidden。
本篇涉及源码两个文件:qwen3.py 的 Qwen3Attention 负责编排,forward 九行把各步串起来;attention.py 的 Attention 是注意力层——把 K/V 写进 cache、按 prefill / decode 两路调用 FlashAttention。两个新东西是本篇重点:第一个 Triton kernel store_kvcache,以及 prefill / decode 两路注意力。
沿用单卡视角:num_heads // tp_size 这类按卡数切分的代码按单卡(tp_size=1)读,多卡的 head 切分留到后文介绍。
2. 总览
一次注意力子层的 forward,数据沿下图自上而下流过七步。
hidden_size | ||
num_heads | ||
num_kv_heads | ||
head_dim | ||
q_size | ||
kv_size | ||
scaling |
后续各节按图中七步展开。
# Qwen3Attention.forward
defforward(self, positions, hidden_states):
qkv = self.qkv_proj(hidden_states) # ① 合并投影
q, k, v = qkv.split( # ② 切回 q/k/v
[self.q_size, self.kv_size, self.kv_size], dim=-1)
q = q.view(-1, self.num_heads, self.head_dim) # ③ 摊成 [N,16,128]
k = k.view(-1, self.num_kv_heads, self.head_dim) # k/v 只有 8 头(GQA)
v = v.view(-1, self.num_kv_heads, self.head_dim)
ifnotself.qkv_bias: # ④ QK-Norm(Qwen3)
q = self.q_norm(q)
k = self.k_norm(k)
q, k = self.rotary_emb(positions, q, k) # ⑤ RoPE
o = self.attn(q, k, v) # ⑥ 写 cache + 注意力
output = self.o_proj(o.flatten(1, -1)) # ⑦ 输出投影
return output3. QKV 投影与 GQA
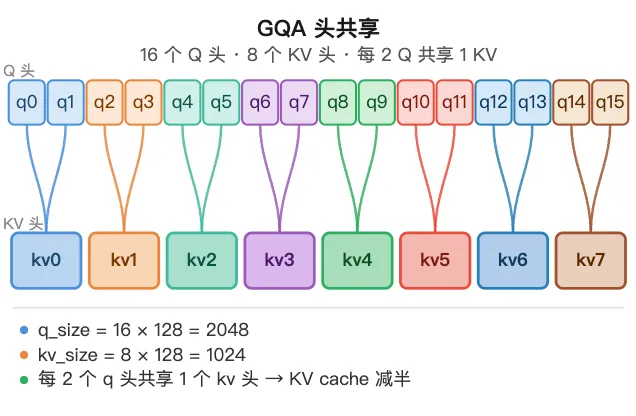
qkv_proj 一次投影出 q、k、v 拼在一起的 [N, 4096],split 按 [2048, 1024, 1024] 切回三股,再 view 成 [N, 头数, 128]。这里藏着一个关键设计:q 有 16 个头,k、v 只有 8 个——这就是 GQA(分组查询注意力)。
query 有 16 个头,key/value 只有 8 个;16 个 q 头分成 8 组,每组 2 个 q 头共享同一个 kv 头。所以切出来 q 是 2048 = 16×128,k、v 各是 1024 = 8×128。
打个比方:8 个资料柜(KV),16 个人(Q)两两合用一个柜子查资料,不必一人一柜。
为什么需要:KV cache 占的显存随 kv 头数线性增长。每个 q 头都配独立 kv 头(标准多头注意力 MHA)时 cache 最大;所有 q 头共用一个 kv 头(MQA)时最小,但表达力受损。GQA 取折中。
解决了什么:kv 头减半(8 而非 16),KV cache 直接少一半,decode 时从 cache 读的访存也减半,精度几乎不掉。
怎么解决:qkv_proj 的输出维一开始就按 q_size + kv_size + kv_size = 2048 + 1024 + 1024 = 4096 排好,split 切出的 k、v 自然只有 8 头;注意力内部再把每个 kv 头广播给同组的 2 个 q 头(FlashAttention 自动处理)。
# __init__ 里算好各段宽度
head_dim, n_q, n_kv = 128, 16, 8
q_size = n_q * head_dim # 2048:q 的 16 个头
kv_size = n_kv * head_dim # 1024:k、v 各 8 个头
print("q_size / kv_size :", q_size, kv_size) # 2048 1024
print("qkv 合并输出维 :", q_size + 2 * kv_size) # 4096
print("每组 q 头数 :", n_q // n_kv) # 2(GQA 组大小)
# forward 里的切分与摊开(源码摘录):
# q, k, v = qkv.split([q_size, kv_size, kv_size], dim=-1)
# q = q.view(-1, n_q, head_dim) # [N, 16, 128]
# k = k.view(-1, n_kv, head_dim) # [N, 8, 128]
# v = v.view(-1, n_kv, head_dim) # [N, 8, 128]q_size / kv_size : 2048 1024
qkv 合并输出维 : 4096
每组 q 头数 : 24. QK-Norm 与 RoPE
切出 q、k 之后、做注意力之前,还有两步预处理,都只作用在 q、k 上(v 不动):先 QK-Norm,再 RoPE。QK-Norm 是 Qwen3 相对 Qwen2 的关键改动。
是什么:对每个头的 q、k 向量各做一次 RMSNorm,归一化的维度是 head_dim=128(就是 L14 那个 RMSNorm,只是作用在每个头的 128 维上)。代码就两行:q = self.q_norm(q)、k = self.k_norm(k)。
为什么需要:注意力分数是 q 与 k 的点积。如果某些 token 的 q 或 k 模长异常大,分数会出现极端值,softmax 之后注意力塌到一两个位置,训练容易发散,长序列尤其明显。
解决了什么:把每个头的 q、k 拉回稳定尺度,注意力分数不爆,训练更稳、长上下文更鲁棒。
怎么解决:view 成 [N, 头数, 128] 后,在最后一维 head_dim 上做 RMSNorm,每个头独立。
归一化之后是 RoPE:q, k = self.rotary_emb(positions, q, k),按每个 token 的位置把 q、k 旋转(L15 已详解,v 不旋转)。
# QK-Norm 作用在最后一维、每个头独立,QK-Norm 前后形状不变
import torch
from nanovllm.layers.layernorm import RMSNorm
qn = RMSNorm(128) # 与 q_norm 同构
q = torch.randn(5, 16, 128) # [N, 16 头, 128]
print("QK-Norm 前后形状不变 :", tuple(qn(q).shape)) # (5, 16, 128)
# 预期:
# QK-Norm 前后形状不变 : (5, 16, 128)QK-Norm 前后形状不变 : (5, 16, 128)5. Attention:写 cache 与 FlashAttention
forward 第 ⑥ 步 o = self.attn(q, k, v) 进入 attention.py 的 Attention 层,它接连做两件事:先把这一批新算的 K/V 写进 paged cache,再用 FlashAttention 算出注意力输出——FlashAttention 本身怎么分块算而不丢精度是一件事,prefill / decode 两种形状下如何实际调库又是一件事。
5.1 store_kvcache:把 K/V 写进 paged cache
paged KV cache 的物理块是不连续的:新算出的 token 该写进哪个物理位置,由调度时算好的 slot_mapping 决定——它给每个 token 一个全局槽位编号 slot。把 K/V 按各自的 slot 散开写进 cache,是一次「散布写」(scatter),普通的连续 copy 表达不了,而且要逐 token 并行才够快。nano-vllm 为此写了一个 Triton kernel——这也是本系列唯一的 Triton 代码。
打个比方:像一队快递员,每人只管一个 token——看一眼 slot_mapping 给的货架编号,把这条 K/V 搬到对应格子;编号是 -1 就这趟不送。
Triton 是什么:一种内嵌在 Python 里的 GPU 编程语言。你只写「每个并行单元(program)该干什么」,用 tl.load / tl.store 读写显存,Triton 负责编译成 GPU 代码——省去手写 CUDA C++。
并行模型:启动 kernel 时给一个网格大小(grid),GPU 就并行跑这么多个 program。每个 program 用 tl.program_id(0) 拿到自己的编号。store_kvcache 的 grid 是 (N,)——N 个 token,一个 program 管一个 token,编号 idx 就是 token 序号。
这个 kernel 怎么写 cache:第 idx 个 program 先查 slot_mapping[idx] 拿到目标 slot;如果 slot 是 -1(这趟不写,下面解释)就直接返回;否则把第 idx 个 token 那一整条 K/V(D = 8×128 = 1024 个数)从输入读出,写到 cache 里第 slot 条的位置(偏移 slot × D)。
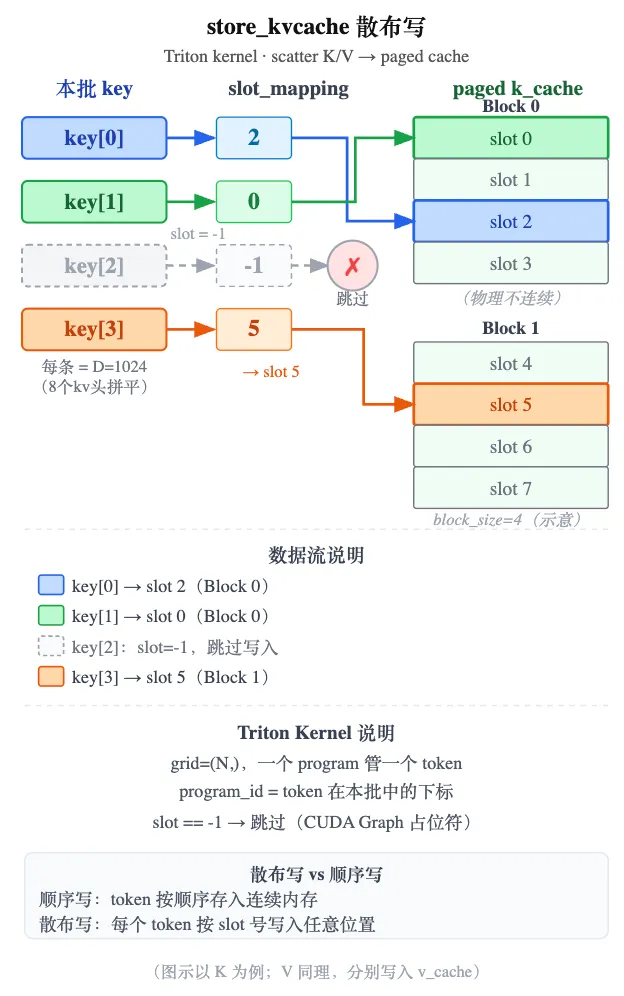
slot 为 -1 的情况:decode 走 CUDA Graph 时,batch 会补齐到固定大小,多出来的占位 token 把 slot 填成 -1(后文细说),kernel 见到 -1 就跳过,不污染 cache。
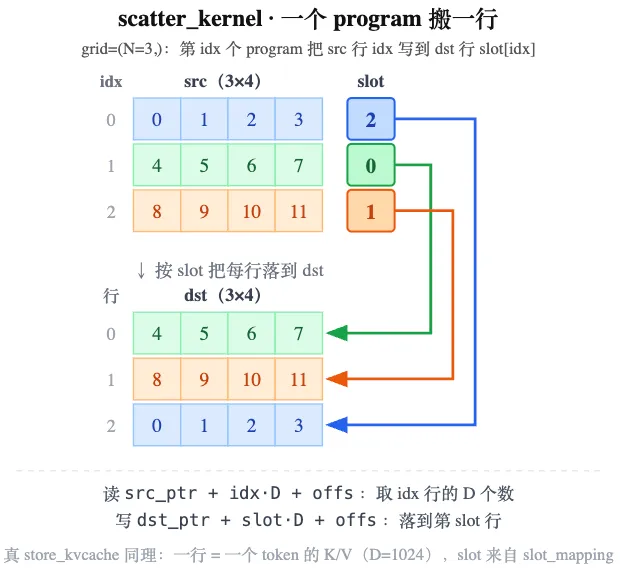
简单起见,实现一个 scatter_kernel。
scatter_kernel 是 store_kvcache 的最小骨架:按 slot 把 src 每一行搬到 dst 的目标行(第 idx 行 → 第 slot[idx] 行)。grid 设成 (N,),N 行各由一个 program 并行搬运;把「一行 D 个数」换成「一行 = 一个 token 的 K/V」,就是 store_kvcache。
N=3、D=4、slot=[2,0,1]:src 三行按 slot 重新落位,dst 行号正好等于 slot 值:
import torch, triton
import triton.language as tl
# scatter_kernel:把 src 的每一行,按 slot 搬到 dst 的对应行。
# src / dst 虽写成 [N, D] 二维,显存里其实是 N*D 个数连续平铺:
# 第 r 行 = 平铺下标 [r*D, r*D+D) 这 D 个数。
# kernel 按这个下标算地址,一个 program 一次搬一整行。
@triton.jit
defscatter_kernel(src_ptr, slot_ptr, dst_ptr, D: tl.constexpr):
# src_ptr/dst_ptr 指向 [N*D];slot_ptr 指向 [N]
# D 是 constexpr(编译期常量),下面 tl.arange(0, D) 才能用
idx = tl.program_id(0) # 标量:第 idx 行(program 号),idx∈[0,N)
slot = tl.load(slot_ptr + idx) # 标量:目标行号 slot[idx]
offs = tl.arange(0, D) # [D] 向量:列下标 0..D-1
# idx*D + offs → [D] 向量:src 第 idx 行那 D 个数的平铺下标
row = tl.load(src_ptr + idx * D + offs) # [D]:一次读出整行
# slot*D + offs → [D] 向量:dst 第 slot 行的平铺下标
tl.store(dst_ptr + slot * D + offs, row) # [D]:整行写进 dst 第 slot 行
# ---- 跑一个 N=3、D=4 的例子 ----
N, D = 3, 4
# src [N,D]=[3,4],值 0..11:行0=[0,1,2,3] 行1=[4,5,6,7] 行2=[8,9,10,11]
src = torch.arange(N * D, device="cuda", dtype=torch.float32).reshape(N, D)
# slot [N]=[3],int32:行 0→2, 1→0, 2→1
slot = torch.tensor([2, 0, 1], device="cuda", dtype=torch.int32)
# dst [N,D]=[3,4],先全 0,等 kernel 填
dst = torch.zeros(N, D, device="cuda", dtype=torch.float32)
# grid=(N,)=(3,):启动 3 个 program,第 idx 个搬第 idx 行
scatter_kernel[(N,)](src, slot, dst, D=D)
print(dst) # [3,4]:src 三行按 slot 重新落位
# 预期:
# tensor([[ 4., 5., 6., 7.], # dst 行0 ← src 行1(slot[1]=0)
# [ 8., 9., 10., 11.], # dst 行1 ← src 行2(slot[2]=1)
# [ 0., 1., 2., 3.]], # dst 行2 ← src 行0(slot[0]=2)
# device='cuda:0')
# 这就是 store_kvcache 的骨架:一个 program 搬一行(= 一个 token)、按 slot 散布。
# 真 kernel 只多三处:同时搬 K 和 V 两份、slot==-1 跳过、用真实 stride 定位。tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 0., 1., 2., 3.]], device='cuda:0')scatter_kernel 加上三处改动,变成 nano-vllm 实际调用的 store_kvcache_kernel,一个 program 管一个 token:
• ① K、V 两份:读 key[idx]、value[idx],分别写进k_cache[slot]、v_cache[slot](两次 load + 两次 store,共用同一个 idx、slot)。• ② slot == −1 跳过:decode 走 CUDA Graph 时 batch 补齐到固定大小,多出来的占位 token 把 slot 填 −1,kernel 见到就 return,不写 cache。• ③ 真实 stride:读 input 改用调用时传入的真实步长 idx × key_stride(不再像 scatter 写死idx × D);写 cache 仍是slot × D(cache 保证每 slot 紧密 D 个)。
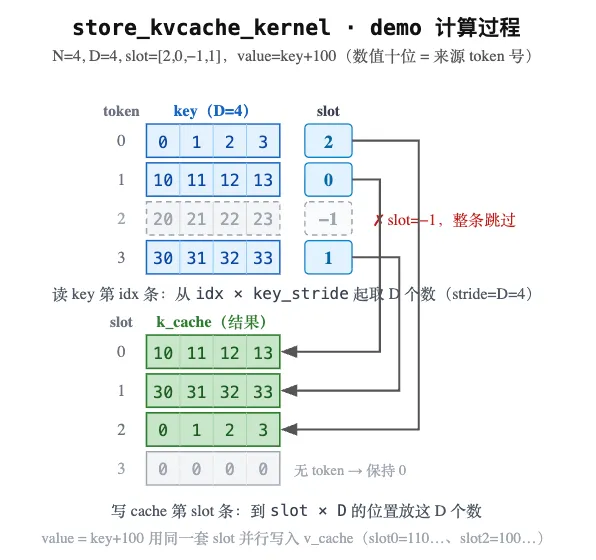
下图用下面代码里的 4-token 例子走一遍真实数据(每个数的十位 = 来源 token 号,可直接对照 print(k_cache)):每条 key 按 slot 写到 k_cache 对应位置——token2 的 slot = −1 整条跳过,没有 token 落到的 slot3 保持 0;value = key + 100 用同一套 slot 并行写进 v_cache。
import triton
import triton.language as tl
@triton.jit
defstore_kvcache_kernel(
key_ptr, key_stride, # 输入 key 的首地址、每个 token 占的步长
value_ptr, value_stride,
k_cache_ptr, v_cache_ptr, # paged cache 的首地址
slot_mapping_ptr, # 每个 token 的目标 slot
D: tl.constexpr, # 一个 token 的 K/V 长度 = 8×128 = 1024
):
idx = tl.program_id(0) # 第 idx 个 token
slot = tl.load(slot_mapping_ptr + idx)
if slot == -1: return# 占位 token:不写(CUDA Graph 用,后续讲解)
key_offsets = idx * key_stride + tl.arange(0, D) # 读 key 第 idx 条
value_offsets = idx * value_stride + tl.arange(0, D)
key = tl.load(key_ptr + key_offsets)
value = tl.load(value_ptr + value_offsets)
cache_offsets = slot * D + tl.arange(0, D) # 写 cache 第 slot 条
tl.store(k_cache_ptr + cache_offsets, key)
tl.store(v_cache_ptr + cache_offsets, value)
defstore_kvcache(key, value, k_cache, v_cache, slot_mapping):
N, num_heads, head_dim = key.shape # key: [N, 8 个 kv 头, 128]
D = num_heads * head_dim # 注意 num_heads 这里 = kv 头数 8 → D=1024
# 下面断言保证内存是 kernel 假设的「连续平铺」布局:
assert key.stride(-1) == 1and value.stride(-1) == 1# head_dim 连续
assert key.stride(1) == head_dim and value.stride(1) == head_dim # 头与头连续
assert k_cache.stride(1) == D and v_cache.stride(1) == D # cache 每 slot D 个
assert slot_mapping.numel() == N
# 启动 N 个 program,一个管一个 token
store_kvcache_kernel[(N,)](
key, key.stride(0), value, value.stride(0),
k_cache, v_cache, slot_mapping, D)
# 关键点:key.shape 解包出的局部 num_heads 其实是 kv 头数(K/V 只有 8 头),
# 所以 D = 8×128 = 1024——一个 slot 存一个 token 的全部 KV 头。
# 三组 stride 断言确保「token 内连续、cache 每 slot 连续 D 个」,
# 让 kernel 能用 idx*stride 和 slot*D 直接定位,不必逐头算偏移。
# ==== 跑一个 4-token 的例子(对应上图,slot=[2,0,-1,1])====
import torch
# 缩小尺寸便于看:每个 token 仅 2 个 kv 头 × 2 维 → D=4(真实是 8×128=1024)
N, nkv, hd = 4, 2, 2
D = nkv * hd
# key 填好辨认的值:第 idx 个 token 的数都带前缀 idx*10;value 再 +100 以区分
base = torch.arange(nkv * hd).reshape(1, nkv, hd) # [[0,1],[2,3]]
key = (torch.arange(N).reshape(N, 1, 1) * 10 + base).float().cuda() # [N,nkv,hd]
value = key + 100
# slot_mapping:token0→slot2、token1→slot0、token2→跳过(-1)、token3→slot1
slot_mapping = torch.tensor([2, 0, -1, 1], device="cuda", dtype=torch.int32)
# paged cache:[num_blocks, block_size, nkv, hd],stride(1)=nkv*hd=D,满足断言
k_cache = torch.zeros(1, 4, nkv, hd, device="cuda") # 共 4 个 slot
v_cache = torch.zeros(1, 4, nkv, hd, device="cuda")
store_kvcache(key, value, k_cache, v_cache, slot_mapping) # 启动 4 个 program
# 每个 slot 展平成 D 个数来看:值里的前缀就是源 token 编号
print("k_cache:\n", k_cache.view(-1, D))
print("v_cache slot0:", v_cache.view(-1, D)[0]) # 应是 token1 的 valuek_cache:
tensor([[10., 11., 12., 13.],
[30., 31., 32., 33.],
[ 0., 1., 2., 3.],
[ 0., 0., 0., 0.]], device='cuda:0')
v_cache slot0: tensor([110., 111., 112., 113.], device='cuda:0')5.2 FlashAttention
K/V 写进 cache 后,剩下就是算注意力 softmax(QKᵀ/√d)·V。
朴素方法的计算过程:分三步,每步的中间结果都写回显存(HBM)。① Q·Kᵀ——整段 query 和整段 key 两两点积,得到一张 N×N 的分数矩阵 S;② 先把 S 乘 1/√d 缩放,再按行做 softmax,得到权重矩阵 P,仍是 N×N;③ P·V——加权求和,得到输出 O。
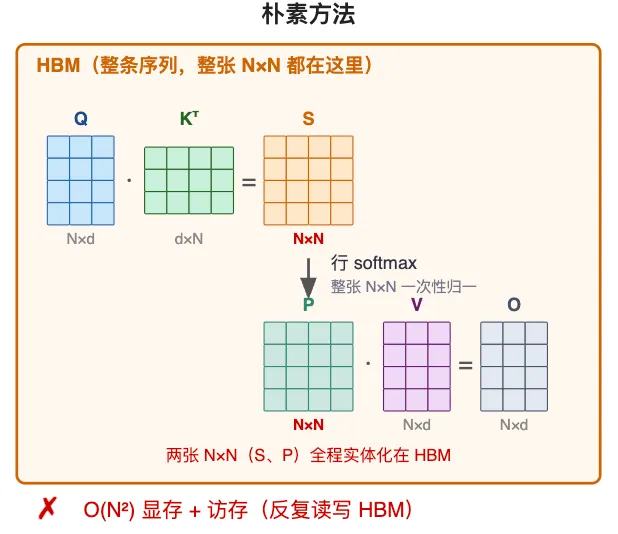
朴素方法的弊端:S、P 两张 N×N 矩阵都要整张实体化、落在 HBM。序列一长,N² 个元素的显存占用、以及反复读写 HBM 的访存量,都是 O(N²),很快就不堪重负;而且慢——慢在反复读写显存,不在算力。
FlashAttention 是什么:一种把注意力「分块、不落整张分数矩阵」的算法,正是为绕开上面那张 N×N 而生。它和朴素方法数学上等价、输出在数值精度内一致,只是换了计算的组织方式。打个比方:像滚动记账——不摊开整张大表,来一块算一块、逐块更新合计,最后总额不变。
怎么解决:把 Q、K、V 切成小块,搬进快得多的片上缓存(SRAM)里逐块算。每次只取一个 (i,j) 块(i 是第 i 个 query 块,j 是第 j 个 key/value 块):① Qᵢ·Kⱼᵀ 得一小块分数 Sᵢⱼ;② 行 softmax,但分块时拿不到整行,只能边走边更新;③ Pᵢⱼ·Vⱼ 加权后累加进输出块 Oᵢ。外层对所有块循环,从头到尾不拼出整张 N×N。显存降到 O(N),访存大减,长上下文才得以运行。
为什么分块仍然正确:换了计算的组织方式,结果为何不损失精度?拆成两件事看。
① 分块矩阵乘法本就精确。 矩阵乘法的每个输出,都是一串乘积相加;而一串数相加,先分成几堆各自求小计、再把小计加起来,总和不变。注意力的输出 Oᵢ=Σⱼ Pᵢⱼ·Vⱼ 就是这样一个加权和——按 key 分块,逐块算出小计再相加,与一次性算逐位相等。

同理,分数 Sᵢⱼ=Qᵢ·Kⱼᵀ 的每个数是一次完整点积(head_dim 不切分),分块只是把大网格切成小网格,数值一个不差。跨块唯一的麻烦只剩一处:P 那步 softmax 要用整行的 max 和 sum 来归一化,而分块时它们还没集齐——这正是 ② 要解决的。
② softmax 的归一化能边走边修正。 标准 softmax 把一行缩放后的分数 变成一组和为 1 的权重,第 个权重是
实际实现都先减去整行最大值 再取指数。一整行同减一个常数,分子分母同乘,恰好抵消,结果不变(平移不变);好处是指数的输入从变成,落在内,exp 不会溢出:
注意力这一行的输出 O 是用这些权重对 value 加权求和。把分子、分母拆开看,整行计算只依赖三个量——最大值 m、分母和 ℓ、未归一化输出 Ō(分子,还没除以 ℓ):
整行一次算:一行 4 个缩放后分数 s=[1,3,2,5]、对应 value v=[10,20,30,40](真实 value 是 128 维向量,这里各用一个数代表):
1. 整行最大值 m = 5;2. 逐个减 m取指数:、、、;3. 求和得 ℓ ≈ 1.203,逐个除以ℓ得权重[0.015, 0.112, 0.041, 0.831]——和为 1,分数最大的 token 权重最大;4. 加权求和: O ≈ 0.015×10 + 0.112×20 + 0.041×30 + 0.831×40 ≈ 36.881。
麻烦在于:第 1 步的 m、第 3 步的 ℓ 都要见到整行分数才能定下来,而分块时分数一块一块来。online softmax 把 m、ℓ、Ō 当作三个累加器边走边更新,靠一条数学事实保证精确——exp 可因式分解:
含义:新块带来更大的最大值、基准从 换到 时,旧块不必回头重算——把已累计的 ℓ、Ō 统一乘上修正因子 (一个 ≤1 的数),效果与当初就用新基准算一模一样。于是每来一个新块,三个累加器按下式更新( 取遍新块内的分数):
所有块走完,O = Ō/ℓ。重缩放不是近似,是精确记账。
分块逐步算:同一行 s=[1,3,2,5]、v=[10,20,30,40],切成两块 A=(s=[1,3])、B=(s=[2,5]),逐块套用上面的更新式:
m | ℓ | Ō | |
e⁻²+e⁰ ≈ 1.135 | 0.135×10+1×20 ≈ 21.353 | ||
1.135×0.135 ≈ 0.154 | 21.353×0.135 ≈ 2.890 | ||
0.154+e⁻³+e⁰ ≈ 1.203 | 2.890+0.050×30+1×40 ≈ 44.383 | ||
÷ℓ | 44.383÷1.203 ≈ |
块 A 的贡献被 0.135 缩小,正因为块 B 带来了更大的 max——这就是重缩放在做的事。对照「整行一次算」:重缩放后的 ℓ=0.154、Ō=2.890,恰好等于整行算法里前两项的贡献(0.018+0.135≈0.154、0.018×10+0.135×20≈2.890)——分块只是换了记账顺序,最后 36.881 分毫不差。
5.3 两路调用:prefill / decode
FlashAttention 的算法不变,但 prefill 与 decode 的张量形状不同,nano-vllm 因此分两路调库。
• prefill:一批序列变长拼在一起,q 和 k 都是「整段」,要用 cu_seqlens把拼平的 token 切回各条序列、做块内 causal。用flash_attn_varlen_func。• decode:每条只新算 1 个 token,q 是单点,k/v 是 cache 里到目前为止的一整条。用 flash_attn_with_kvcache,按block_table从 paged cache 取 K/V,cache_seqlens标明每条读到哪。
还有一个 prefix cache 分支:prefill 时若命中前缀复用,就把 k, v 直接换成整块 cache——新 token 的 K/V 刚被 store_kvcache 写进去,连同复用的前缀一起,flash 按 block_table 从 cache 读。此时 k 比 q 长。
import torch
from torch import nn
from flash_attn import flash_attn_varlen_func, flash_attn_with_kvcache
from nanovllm.utils.context import get_context
classAttention(nn.Module):
def__init__(self, num_heads, head_dim, scale, num_kv_heads):
super().__init__()
self.num_heads = num_heads # 16
self.head_dim = head_dim # 128
self.scale = scale # 128^-0.5
self.num_kv_heads = num_kv_heads # 8
self.k_cache = self.v_cache = torch.tensor([]) # 空,等 allocate 时填
defforward(self, q, k, v):
context = get_context() # 取本 step 的元数据(L10)
k_cache, v_cache = self.k_cache, self.v_cache
if k_cache.numel() and v_cache.numel(): # cache 已分配
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)
if context.is_prefill:
if context.block_tables isnotNone: # prefix cache:改从 cache 读
k, v = k_cache, v_cache
o = flash_attn_varlen_func(
q, k, v,
max_seqlen_q=context.max_seqlen_q, cu_seqlens_q=context.cu_seqlens_q,
max_seqlen_k=context.max_seqlen_k, cu_seqlens_k=context.cu_seqlens_k,
softmax_scale=self.scale, causal=True, block_table=context.block_tables)
else: # decode:单点 q 读整条 cache
o = flash_attn_with_kvcache(
q.unsqueeze(1), k_cache, v_cache,
cache_seqlens=context.context_lens, block_table=context.block_tables,
softmax_scale=self.scale, causal=True)
return o
# q.unsqueeze(1):decode 的 q 是 [batch, 16, 128],补一个长度 1 的序列维
# 成 [batch, 1, 16, 128],告诉 flash「每条只有 1 个 query」。
# 三条路径共用一份 store_kvcache(先把新 token 的 K/V 写进 cache),
# 之后 prefill / decode / prefix 各取所需:
# - prefill 无 prefix:用刚算的 k, v;
# - prefill 命中 prefix:k, v 换成整块 cache(含复用前缀 + 刚写入的新 token);
# - decode:q 单点,K/V 全程从 cache 读。6. o_proj 输出投影
注意力输出 o 形状 [N, 16, 128],flatten(1, -1) 把 16 个头拼回 [N, 2048],再过 o_proj 投影回 [N, 1024],与子层入口的 hidden 同维,好接回残差流(L13)。
# forward 两行源码摘录:
# o = self.attn(q, k, v) # [N, 16, 128]
# output = self.o_proj(o.flatten(1, -1)) # [N, 2048] → [N, 1024]
# flatten(1, -1):把第 1 维到最后一维(16 头 × 128)压平成 2048
import torch
o = torch.randn(5, 16, 128)
print("flatten 前 :", tuple(o.shape)) # (5, 16, 128)
print("flatten 后 :", tuple(o.flatten(1, -1).shape)) # (5, 2048)
# 预期:
# flatten 前 : (5, 16, 128)
# flatten 后 : (5, 2048)flatten 前 : (5, 16, 128)
flatten 后 : (5, 2048)7. 集成验证
用源码版 ModelRunner 加载真实 Qwen3-0.6B——它在构造时完成权重加载、warmup 和 paged KV cache 分配。取第 0 层手搭一个最小 prefill:跑通注意力子层,验证两件本篇核心的事——store_kvcache 把 K/V 写到了 slot_mapping 指定的位置、prefill 走 varlen 输出形状正确;再跑一步 decode,验证 with_kvcache 能从 cache 读回。
import torch
from modelscope import snapshot_download
from nanovllm.config import Config
from nanovllm.utils.context import set_context, reset_context
from nanovllm.engine.model_runner import ModelRunner
model_path = snapshot_download("Qwen/Qwen3-0.6B")
config = Config(model_path, enforce_eager=True, max_model_len=4096)
runner = ModelRunner(config, 0, [])
model = runner.model # Qwen3ForCausalLM(权重 bf16)
attn0 = model.model.layers[0].self_attn # 第 0 层 Qwen3Attention
print("num_heads / num_kv_heads / head_dim :",
attn0.num_heads, attn0.num_kv_heads, attn0.head_dim) # 16 8 128
print("KV cache 块数 :", config.num_kvcache_blocks)Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B
2026-06-10 15:39:16,594 - modelscope - INFO - Target directory already exists, skipping creation.
num_heads / num_kv_heads / head_dim : 16 8 128
KV cache 块数 : 1943# ---- 造一条短 prefill 序列 ----
N = 5
ids = torch.tensor([100, 200, 300, 400, 500], device="cuda")
x = model.model.embed_tokens(ids) # [N, 1024]
positions = torch.arange(N, device="cuda")
# ---- KV cache 已由 ModelRunner 分配好、挂在每层 attn 上 ----
# 形状 [num_blocks, block_size=256, nkv, hd]:
# stride(1) == nkv*hd == D,满足 store_kvcache 的断言
nkv, hd = attn0.num_kv_heads, attn0.head_dim # 8, 128
print("k_cache 形状 :", tuple(attn0.attn.k_cache.shape))
# ---- 设 prefill context:单条序列、无 prefix cache ----
slot_mapping = torch.arange(N, device="cuda", dtype=torch.int32) # 写进 block0 的 slot 0..4
cu = torch.tensor([0, N], device="cuda", dtype=torch.int32)
set_context(is_prefill=True, cu_seqlens_q=cu, cu_seqlens_k=cu,
max_seqlen_q=N, max_seqlen_k=N, slot_mapping=slot_mapping)
with torch.inference_mode():
out = attn0(positions, x) # 跑通整条 forward(含 store_kvcache + varlen)
print("prefill 输出形状 :", tuple(out.shape)) # (5, 1024)
# ---- 验证 store_kvcache 写对:重算 post-QK-Norm + post-RoPE 的 k ----
with torch.inference_mode():
qkv = attn0.qkv_proj(x)
q_r, k_r, _ = qkv.split([attn0.q_size, attn0.kv_size, attn0.kv_size], dim=-1)
q_r = q_r.view(-1, attn0.num_heads, hd)
k_r = k_r.view(-1, nkv, hd)
q_r = attn0.q_norm(q_r) # 与 forward 同样的 QK-Norm
k_r = attn0.k_norm(k_r)
_, k_r = attn0.rotary_emb(positions, q_r, k_r) # 与 forward 同样的 RoPE
k_in_cache = attn0.attn.k_cache.view(-1, nkv, hd)[:N] # cache 里 slot 0..4 的 k
print("store_kvcache 写对 :",
torch.allclose(k_in_cache, k_r, atol=1e-2)) # True
reset_context()
# 预期:
# k_cache 形状 : (num_blocks, 256, 8, 128) —— num_blocks 由显存水位决定
# prefill 输出形状 : (5, 1024)
# store_kvcache 写对 : Truek_cache 形状 : (1943, 256, 8, 128)
prefill 输出形状 : (5, 1024)
store_kvcache 写对 : True# ---- decode 一步:在上面的 prefill 之后追加 1 个新 token ----
new_id = torch.tensor([600], device="cuda")
x_d = model.model.embed_tokens(new_id) # [1, 1024]
pos_d = torch.tensor([N], device="cuda") # 新 token 在第 N 位
slot_d = torch.tensor([N], device="cuda", dtype=torch.int32) # 写进第 N 个 slot
ctx_lens = torch.tensor([N + 1], device="cuda", dtype=torch.int32) # cache 现有长度 = 6
block_tables = torch.tensor([[0]], device="cuda", dtype=torch.int32) # 这条序列用 block 0
set_context(is_prefill=False, slot_mapping=slot_d,
context_lens=ctx_lens, block_tables=block_tables)
with torch.inference_mode():
out_d = attn0(pos_d, x_d) # 走 flash_attn_with_kvcache 分支
print("decode 输出形状 :", tuple(out_d.shape)) # (1, 1024)
reset_context()
# 预期:
# decode 输出形状 : (1, 1024)decode 输出形状 : (1, 1024)8. 小结
注意力子层一次 forward 七步:qkv_proj 合并投影、split+view 切出 q/k/v(q 16 头、k/v 8 头,GQA 省一半 KV cache)、QK-Norm 给每个头的 q/k 校准尺度、RoPE 按位置旋转、store_kvcache 把 K/V 散布进 paged cache、FlashAttention 按 prefill / decode 两路算注意力、o_proj 投影回 hidden。
两个新机制:store_kvcache 是本系列第一个 Triton kernel,一个 program 管一个 token、按 slot 散布写、slot==-1 跳过;注意力分两路——prefill 用 flash_attn_varlen_func 做块对角 causal,decode 用 flash_attn_with_kvcache 让单点 q 从 paged cache 读整条 K/V,prefix cache 命中时 k、v 直接取自 cache。
下一篇讲 Embedding 与 LM Head:token 怎么查成向量、最后怎么从 hidden 算出 logits。
