 夜雨聆风
夜雨聆风本文整理自2026年6月10日的线下单独授课,分上下两篇,下篇为《MCP与Skill:AI工具的标准化协议与任务模板》

By the way,之前做社群,总觉得微信社群是最笨重的方式,没有任何的管理工具,有人数上限,新来的成员也看不到历史的学习资料。所以之后转向飞书社群,欢迎大家加入。
本群主要面向非技术背景的文商科生或者在职人士,当然也欢迎专业人士进来交流。
一、为什么要深入理解这些原理?
在AI编码时代,会用工具只是第一步,理解工具背后的原理才能让你真正掌控AI。理解AI编码工具的工作原理,对搭建Agent系统、把握未来AI产品形态以及优化个人工作流都有重要帮助。
本文主要面向0基础的文商科生,也可能适用于非专业领域的理工科学生,或其他在职人士。
二、AI编码工具的四种形态
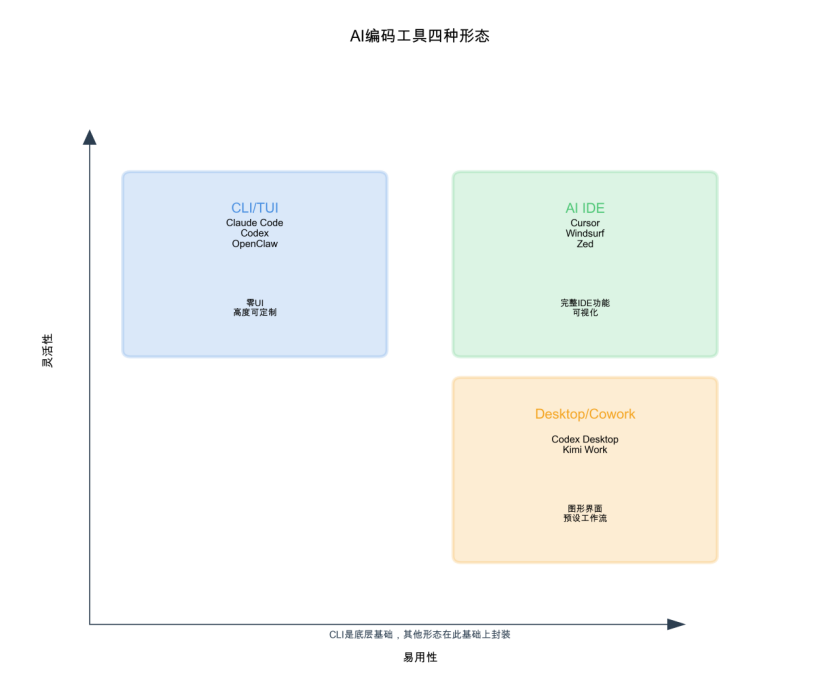
图1:四种工具形态对比
终端命令行工具(CLI/TUI)
目前最推荐的是ClaudeCode、Codex这类终端CLI工具,包括OpenClaw、KimiCode等也属于这一类。这些工具本质上都是终端命令行工具,可以在任何带有终端的窗口中输入命令后弹出对话界面使用。它的核心优点是方便定制化,因为终端是零UI的纯文本界面,这种极简的特性使其组合性非常强,是构成所有工具的底层能力。
推荐学习CLI工具的原因类似于学习编程语言要从底层原理入手。当你掌握了底层的东西,就像学会了建房子的基础,之后想搭什么样的房子都可以。这也是为什么虽然CLI工具门槛较高,但仍然值得投入时间学习。
Desktop应用(AINative)
Codex Desktop、ClaudeDesktop这类工具在CLI基础上进行了UI和能力层的封装,将零UI的命令行工具转化为符合传统互联网用户直觉的可视化应用。可以这样理解:AI原本是云端的抽象存在,现在通过Desktop应用实体化,从原先的零UI变成了有UI的产品。
Desktop应用最明显的改进是用户体验。左边清晰显示文件结构,右边实时展示运行的命令和窗口状态,设置也不再需要通过斜杠命令(如/config、/mcp、/plugin),而是通过鼠标点击Preference菜单来完成。这种可视化窗口更符合用户直觉,也是为什么CodexApp更适合普通人使用的原因。不过建议的学习路径仍然是先理解CLI这种底层工具,因为当你学会了底层原理,再往上搭建各种应用就会更加灵活和得心应手。
AI IDE(集成开发环境)
Cursor、Windsurf、Zed、Trae等AIIDE在功能上更加完整,集成了丰富的插件生态系统。IDE本身也可以在终端里运行,有两种方式:一种是在IDE内调用终端工具(比如VSCode加上ClaudeCode),另一种是通过专门的AI交互面板(比如Cursor右侧的垂直窗口)直接编辑代码。
IDE的最大好处是能看到增减了哪些行,对代码需要精确控制的人来说非常合适。它左边有Git命令显示变更文件,支持一键提交,还有SSH工具等各种完善的开发工具。IDE虽然跟直接在终端调用没有太大区别,但它的Harness组织方式不同——CLI工具的Harness组装在终端命令里,而IDE的Harness放在了IDE界面中,这意味着Harness可以直接调用IDE内置的相关工具进行操作。这就是IDE产品形态的独特之处。像Trae这样的工具还支持组建不同团队、分配角色,主要用于开发复杂项目,适合需要团队协作的场景。
Cowork形态(工作伙伴)
腾讯Work Body、Kimi Work、Claude Cowork这几个工具跟CodexApp和Claude Code App类似,但它们更专注于成为工作伙伴。它们封装了专门应付日常工作的Harness,比如帮你整理文件、处理发票、发送邮件等日常办公自动化任务。本质上还是在CLI工具或Desktop应用基础上,针对日常工作场景做了特定方向的封装。
三、Harness:从”缸中之脑”到执行能力
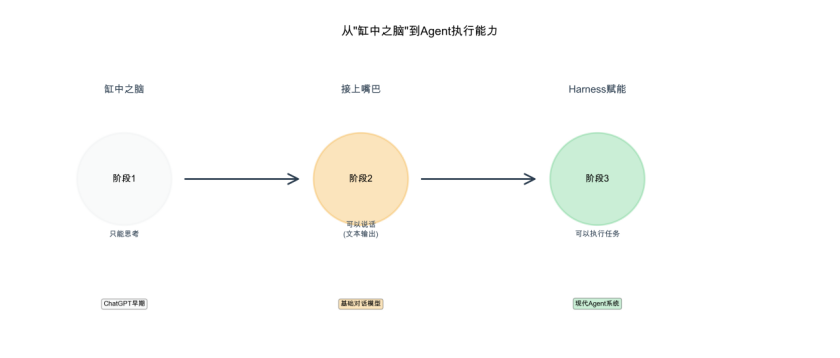
图2:“缸中之脑”到Harness演进
“缸中之脑”问题
早期的ChatGPT被称为”缸中之脑”——就像一个盒子里放了一个脑袋。人是有手有脚的,具备行走能力、使用工具的能力、操作物理世界的能力,但如果只有一个脑子,就只能思考,不能行动。AI最多接了一张嘴巴可以说话,但实际上还是在缸中。Harness的意思就是给AI做一个封装,让它具备Agent的能力。现在所有AI都可以规定输出格式,比如要求以JSON方式输出,它就会输出完整的JSON;要求Markdown输出,它就输出Markdown。这种指定方向的强制约束,使AI能够把纯文本转化为现实工具的调用能力。
从机器码到高级语言的封装层次
理解Harness需要先理解计算机的抽象层次。电脑本身是二进制的0101,零一对应电压的高低、晶体管的通断,必须绝对确定。在0101基础上做封装,例如在某种指令集下,000001代表add、010101代表minus,这就是汇编语言——把机器执行的底层零一操作变成可读的命令。
但用汇编语言编写复杂程序非常繁琐且容易出错,而且不同CPU的汇编指令不通用。为了提高开发效率和代码可移植性,人们发明了高级语言。高级语言创建了类、类型等更抽象的计算机概念,更接近人类的自然语言,而不是简单的零一或短命令。像C++、Python、TypeScript、Java、Go、Rust这些都是高级语言。这些高级语言本质上仍然会被转换成零一。
那么问题来了:能不能让AI直接输出这种高级语言?答案是可以的。高级语言的语法和语义是人为定义的、确定性的——一个A就是A,一个B就是B,没有歧义。就像底层零一对应电压的高低变化、晶体管的通断一样,必须绝对确定。所以少写一个分号、少一个括号或拼错一个关键字,代码就无法通过编译或正确执行。这是计算机工作的基础。
AI如何实现确定性输出
AI虽然本质上是概率生成,但可以通过约束解码技术来实现接近确定性的输出。例如,降低温度参数(Temperature)会让模型几乎总是选择概率最高的词;使用较小的Top-p采样(核采样)则只从累计概率最高的少数几个词中随机选择。这两种方式都能显著减少随机性,使输出稳定可重复。通过这种方式,我可以要求AI百分之百输出TypeScript,百分之百输出Go语言。编写Harness工具后,AI就可以直接执行。它通过汇编语言的add、delete等操作,利用电脑内置的高级语言工具,去操作对文件的增删改查。
文件操作:AI的”手”
绝大部分的操作,本质上Claude的核心设计思想都是对文件的操作。比如修改Word文件,Word不是单一的Markdown文件,而是多个文件组合在一起——格式文件、内容文件等封装成WPS、Office可以读取的文件格式。本质上是一堆XML的压缩包。Docs也是一堆代码文件的压缩包:A代码文件负责编辑样式,B代码文件负责控制用户偏好,C代码文件负责组织整个内容。AI能操作它是因为本质上这些都是代码。AI把对ComputerUse能力内化成了对代码、对文件本身的操作能力。这就是AI长出来的很重要的”手”——电脑原生的终端命令工具。
四、Agent的两种工作方式
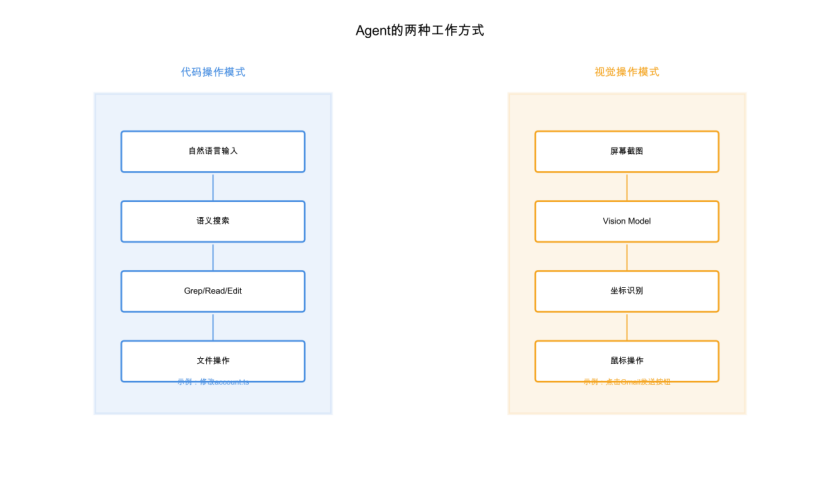
图3:Agent双模式工作原理
通过代码操作(第一种方式)
AI本质上不具备真实理解电脑的能力,它只是用代码去操作。比如Word里的查找替换,本质上是一个正则表达式。AI使用Grep获取具体的代码片段,使用Read查看文件,使用Write、Edit、Sed等各种电脑命令去操作文件,进行增删改查。
AI并没有看到整个代码仓库的全貌,但它知道通过Grep的方式去搜索。比如要找用户相关功能,可能是”account”、“account setting”,然后搜索很多语义类似的词。通过语义方式把需求转化成可能包含这个代码的词语,然后读取对应文件的内容,判断是不是要改这个东西。这样AI就具备了对代码的原始操作能力。
通过视觉操作(第二种方式)
第二种是视觉操作能力,通过VisionModel(视觉语言模型)去操作浏览器。桌面本质上都有文字和布局信息,AI把图片传回去识别,理解操作栏在左边哪个位置、XY坐标是多少,然后把它返回成格式化的数据。AI知道点哪里,就帮你模拟鼠标操作点一下。这种方式不是通过代码,而是通过App。当然App本身也是代码,本质上也是对代码的操作。
五、AI的概率机制:从Token到Attention
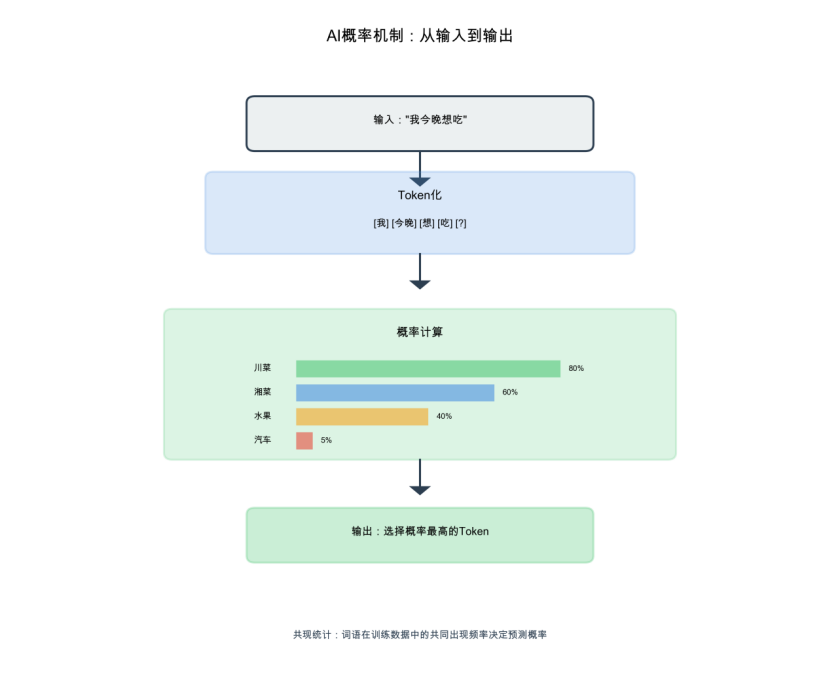
图4:AI概率机制示意图
填词游戏与共现统计
AI给出的回答为什么看起来往往合理?这背后涉及一个核心概念:概率。举个例子,当你说”我今晚想吃”时,你可能会下意识地想到后面接什么词。从统计角度看,在大量日常对话或菜谱文本中,“我今晚想吃”后面出现”湘菜”或”川菜”的概率比较高,出现”汽车”或”作业”的概率就很低。
AI在训练时,会从海量的互联网文本中学习这种”词与词共同出现”的规律。比如”王子”和”公主”经常一起出现,它们的语义向量距离就会很近,这称为语义相似度。一个非常简单的算法就是统计共现频率:A词后面出现B词的次数越多,预测B词的概率就越大。但这只是最基础的思路。现代AI还会使用更复杂的机制,比如下文要提到的注意力机制。总之,AI本质上是在玩一个巨大的”填词游戏”:给定前面的词,预测下一个最可能出现的词是什么。
Token(词元)机制
AI如何理解”一个词”呢?这就需要引入Token(词元)的概念。文本不能简单地按空格或字符切分。例如,“王子”经常作为一个整体出现,那么它会被分成一个Token;“苹果”也是一个Token;而”苹”单独出现很少,一般不作为独立Token,但”果”在很多场景下可能是一个Token(如”果实”)。这种切分方式叫做子词切分,常见算法有BPE(Byte Pair Encoding)。通过这种方式,AI把句子拆分成一串Token,然后计算每个Token之后出现下一个Token的概率。
注意力机制的两种形式
接下来聊一聊注意力机制。它并不是单一的一种工作方式,而是根据用途不同分为两类。
因果注意力(又称单向注意力)是生成文本时(如GPT系列)使用的方式。模型从左到右逐个预测下一个Token,并且只能看到当前位置之前(及自身)的Token,不能看到未来的内容。这样能确保生成过程是顺序的、因果的。你可以理解为:模型在写文章时,只能根据已经写好的部分来推测下一个字,不能提前看到后面的内容。
双向注意力则允许模型同时看到某个词左右两侧的全部上下文。它不用于生成新文本,而是用于理解文本,比如判断句子的情感、做阅读理解、完形填空等。BERT模型就是使用双向注意力的典型例子。双向注意力可以计算出句子中哪些词对其他词更重要,但它并不会”先挑出关键词再预测整篇文章”——这种说法是错误的,因为生成文本仍然需要自回归地逐步进行,无法一步到位。
无论单向还是双向,注意力的本质都是:给句子中不同位置的Token分配不同的权重,让模型知道哪些信息更值得关注。这并不是某种”先确定关键词再写全文”的魔法,而是一种灵活的加权机制。
六、Agent的任务编排能力
从操作能力到任务完成
AI具备了操作能力——通过代码方式控制电脑,通过Vision方式控制电脑。但现在有个问题:我知道怎么操作了,但你要我干什么?做一个项目不是一次操作就能完成的,而是许多个操作叠加在一起。虽然具备了操作能力,但还需要项目管理、用户Memory、用户意图识别。如何系统性地理解并完成一个任务、交付结果?这就是Agent做的事情。
本质上,原本AI只是LanguageModel,负责文本生成就行。但现在是Outcome导向的,给AI一个任务目标,要求达成这个结果。完成一个具体任务不是一次对话就能完成的,不像ChatGPT那样问一句答一句。任务编排就是这个意思——比如发送邮件,要先打开Gmail,点击发送,写内容,输入邮箱地址,输入主题,点击发送,任务完成。这就是任务编排——把复杂任务拆解成一系列有序的操作步骤。
AI的任务理解能力来源
AI必须具备理解任务执行的能力。就像建房子,必须知道怎么建造。在下一代语言模型的训练中,AI内置了这种能力——理解现实中各种任务是怎么完成的,理解代码工作的基本流程,理解什么叫测试、什么叫技术栈、什么叫CRUD操作。这就是内置的完成任务的基本能力。
通过大量数据训练,AI学会了输出命令的先后顺序。比如完成某个任务,本质上就是输出各种命令的先后——先Grep搜索,再Edit修改,再保存,最后进行Git提交。这种任务流它已经理解了。具备这种能力后,就相当于知道怎么用筷子了。
Harness赋予执行权限
现在给AI筷子——把它放在Harness中,Harness就这么出来了。AI具备了任务编排的能力,然后Harness赋予了工具执行的权限,能让AI在电脑上执行代码命令。这就是AI有了”手”和”脚”。
七、Memory机制的多层级结构
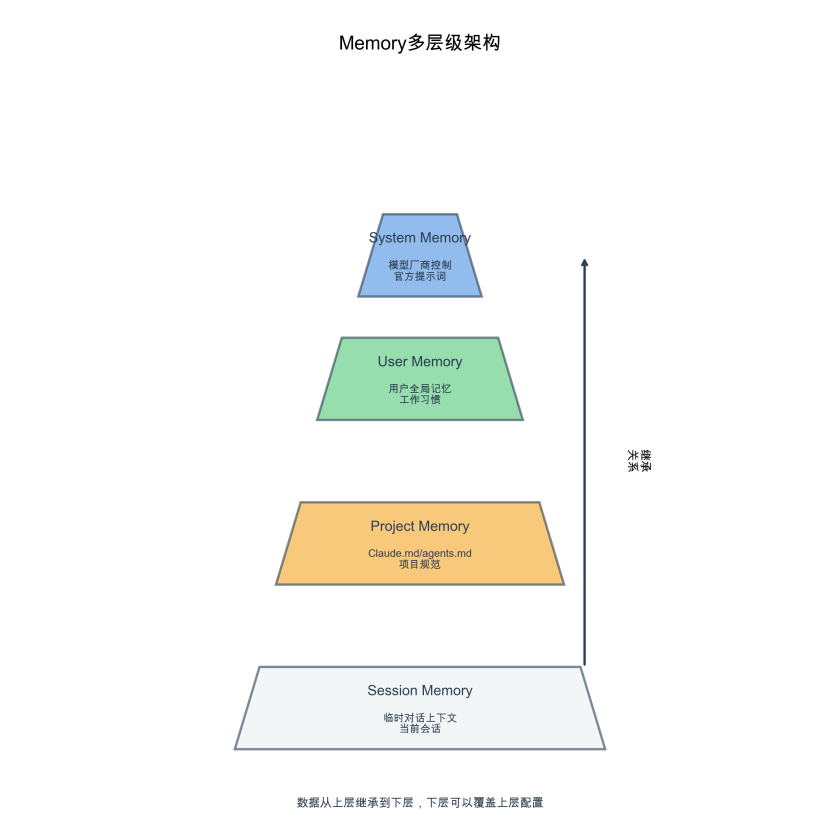
图5:Memory金字塔架构
为什么需要Memory?
给了AI筷子和用筷子的方式,但怎么用筷子炒出一锅菜?这是个大任务,不是学会用锅铲就可以的。必须记住菜谱、配料、怎么买菜、怎么做菜、怎么上盘。不能一边做一边忘,所以需要Memory机制。
Memory又有分层。首先是系统层Memory,因为不可能实时把所有数据都训练进去——模型训练速度跟不上世界发展速度。所以产生了系统性Memory,记住目前正在发生什么。这就是系统级的提示词工程,后来演进为Memory工程。
Project级Memory
项目级别的Memory,比如Claude.md、Codex的agents.md。这些Markdown文件就存储了项目层级的记忆。每次AI工作之前,读取这个项目的Claude.md或agents.md,就知道整个项目的大概信息。这个Markdown文件就是它的Memory,是项目级别的Memory。
Memory可以修改,可以改变AI的记忆。每次做项目时必须及时更改Memory,不然AI不知道做到哪里了。Memory里要写清楚常用的命令有哪些,这样磨合就少了。还要写清楚必须不能做什么、能做什么,限制就清楚了。Skill的使用方式也是Memory的一部分。Memory本质上是一堆文档。
Session级Memory
能修改的Memory往往是ProjectMemory或UserMemory,因为系统级别的Memory由模型厂商控制。系统级别的所有人都得用,Harness的一部分就是系统级Memory。比如DeepSeek觉得官方提示词很好用,但不可能每次都让用户输入,就把提示词内置到云端,这就叫系统级别的Memory。
用户级别的Memory在ChatGPT里经常见到。代码开发一般是ProjectMemory——每次进入项目进行工作,就是这个项目的Memory。还有SessionMemory。在对话窗口里的上下文也属于Memory,但是TemporaryMemory。新开一个Session,首先获取ProjectMemory,然后在这个Session里开始对话,让AI干了什么、返回了什么结果、什么任务成功失败,这就是Session的Memory。它不一定会保存到系统级Memory,因为只是在这个Session里成为了Token的组成部分。
可以在对话中手动控制Memory——觉得有重要的东西,让AI保存到Memory。这样之后的工作就更加顺畅。这就是Session级别的Memory。
User级Memory
Project在电脑上就是一个文件夹。一个Project下所有Session都共用同一个Memory文件,就是Claude.md,按照项目目录来分。还会自动存储Session内容。还有用户层级的Memory,用户经常干什么事情就记下来。这一般是系统自动的。像Hermes、OpenClaw、Claude本身就存储了用户级Memory——经常让它干什么,它就记住了,它就是个用户。User高于Project。User知道电脑上有哪几个Project。
八、总结与展望
核心概念回顾
AI编码工具从CLI到Desktop、IDE、Cowork四种形态,各有特点但底层原理相通。Harness将AI从”缸中之脑”变成了可执行任务的Agent,通过约束解码技术实现确定性输出,从而能够操作文件系统。Agent通过代码操作和视觉操作两种方式与世界交互。AI的概率机制基于Token和注意力,而任务编排能力让它能够系统性地完成复杂工作。Memory的多层级结构(System、User、Project、Session)让AI能够记住上下文,不断进化。
学习路径建议
建议从CLI开始理解底层原理,然后掌握Harness的工作机制,学会管理Memory,最后在实际项目中实践。从0到1搭建应用,理解前后端架构的必要性,掌握Prompt工程技巧。

