 夜雨聆风
夜雨聆风一篇帮你快速理解 v3.0 架构全貌、找到源码入口、知道改代码该去哪里的实操指南
阅读提示
适合谁看:准备阅读或修改 GraphRAG 源码的工程师 看完能做什么:知道 5 个子包各自负责什么,找到索引和查询的源码入口,理解 TableProvider 抽象的设计意图 不适合谁:只用 pip install 跑命令、不打算改源码的用户
先给结论
v3.0 拆成 5 个子包的核心原因是模块化 + 可插拔:LLM 层、存储层、向量层、切分层都可以替换实现
入口文件就两个: api/index.py(索引)和api/query.py(查询),其他都是被它们调用的TableProvider 是最关键的抽象:它让"数据存哪里"变成一个可配置的选择,而不是硬编码
很多人第一次打开 GraphRAG v3.0 的源码,看到 packages/ 目录下有 5 个子包,第一反应是"为什么要拆这么散"。
答案很简单:为了让每个层都可以独立替换。
你可以换 LLM 提供商(OpenAI → Azure → 本地模型),可以换存储后端(本地文件 → Blob Storage → 数据库),可以换向量引擎(LanceDB → Azure AI Search),可以换切分策略(按句子 → 按 Token → 按语义)。每个替换都不需要改其他层的代码。
这篇文章解决一个问题:v3.0 的 5 个子包各自负责什么,依赖关系是什么样的,改代码该从哪里入手。
01 先说清问题:v2.x 的"大锅饭"有什么问题
GraphRAG v2.x 的代码都放在一个包里。LLM 调用、数据存储、向量检索、文本切分、流程编排全混在一起。
这带来了几个实际问题:
想换 LLM 提供商?得改好几处代码 想换存储后端?得深入内部逻辑 想单独测试某个模块?做不到,因为依赖链太深 想贡献代码?得理解整个大包才能改一小块
v3.0 的 Monorepo 架构就是为了解决这些问题。每个子包有清晰的职责边界和对外接口,互不侵入。
这一节的小结
Monorepo 不是为了"看起来高级",而是为了让每一层都可以独立开发、独立测试、独立替换。
02 先把全局地图摆出来
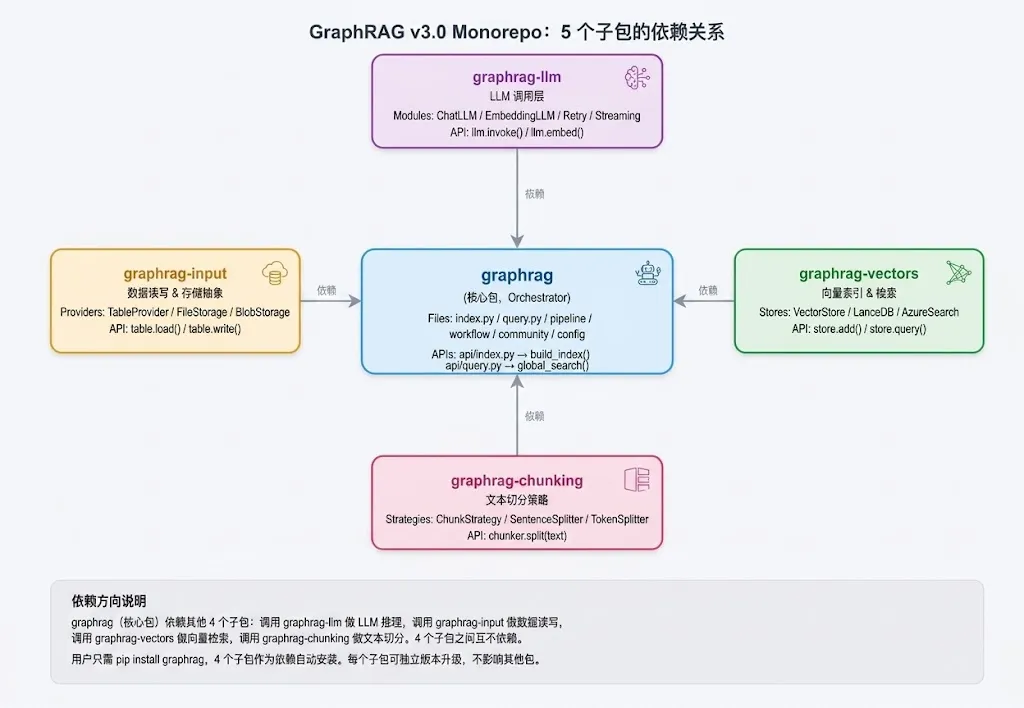 图 1|GraphRAG v3.0 Monorepo:5 个子包的依赖关系
图 1|GraphRAG v3.0 Monorepo:5 个子包的依赖关系
中心是 graphrag 核心包(编排调度),四周是 4 个工具包。箭头标注依赖方向:核心包依赖其他 4 个,4 个工具包之间互不依赖。
5 个子包的定位:
graphrag(核心包):编排调度,包含 Pipeline / Workflow / Step / Config / API 入口 graphrag-llm:LLM 调用层,封装 Chat / Embedding / 重试 / 流式 / Token 计数 graphrag-input:数据读写抽象,TableProvider / FileStorage / BlobStorage graphrag-vectors:向量索引与检索,支持 LanceDB / Azure AI Search 等后端 graphrag-chunking:文本切分策略,按句子 / Token / 语义切分
读者应该先记住的 1 件事
graphrag 核心包是唯一一个依赖其他 4 个包的包。4 个工具包之间互不依赖。这意味着你可以单独替换任何一个工具包,不需要改其他包的代码。
03 关键机制 1:两个入口文件
整个 v3.0 的源码入口就两个文件:
代码 1:索引入口
# packages/graphrag/graphrag/api/index.pyasyncdefbuild_index(config: GraphRAGConfig) -> IndexResult:"""构建知识图谱索引的主入口"""# 1. 创建 Pipeline pipeline = create_pipeline(config)# 2. 注入依赖(LLM / TableProvider / VectorStore) pipeline = inject_dependencies(pipeline, config)# 3. 执行 result = await pipeline.run()return result代码 2:查询入口
# packages/graphrag/graphrag/api/query.pyasyncdefglobal_search(config, query, **kwargs):"""Global Search 查询入口"""# 从 TableProvider 加载 Community Reports reports = config.table_provider.load("community_reports")# 执行 Map-Reducereturnawait run_map_reduce(query, reports, config.llm)asyncdeflocal_search(config, query, **kwargs):"""Local Search 查询入口"""# 从 TableProvider 加载实体和关系 entities = config.table_provider.load("entities")# Fan-Out 检索 + LLM 生成returnawait run_fan_out(query, entities, config.llm)所有索引和查询的操作,最终都会走到这两个入口。想找某个功能的源码,从这里顺着调用链往下找就行。
04 关键机制 2:TableProvider 抽象
TableProvider 是 v3.0 最关键的设计。它解决的问题是:中间结果和最终产出存到哪里。
代码 3:TableProvider 接口
classTableProvider(Protocol):"""数据读写的统一接口"""defload(self, name: str) -> pd.DataFrame:"""读取一张表""" ...defwrite(self, name: str, data: pd.DataFrame) -> None:"""写入一张表""" ...defdelete(self, name: str) -> None:"""删除一张表""" ...默认实现是 ParquetTableProvider,把所有数据存为本地 Parquet 文件。但你可以替换为:
BlobTableProvider:存到 Azure Blob StorageDataFrameTableProvider:直接在内存中操作自定义实现:存到数据库、S3、GCS 等
为什么这个抽象重要?
GraphRAG 索引过程中会产生大量中间结果(TextUnit 表、实体表、关系表、社区表等)。如果这些表的存储方式和核心逻辑耦合,你就没法把 GraphRAG 部署到云端(因为本地文件路径硬编码了)。TableProvider 把"存到哪里"变成了一个可注入的依赖,核心逻辑完全不关心数据存在哪。
05 一次索引请求在源码中的完整调用链
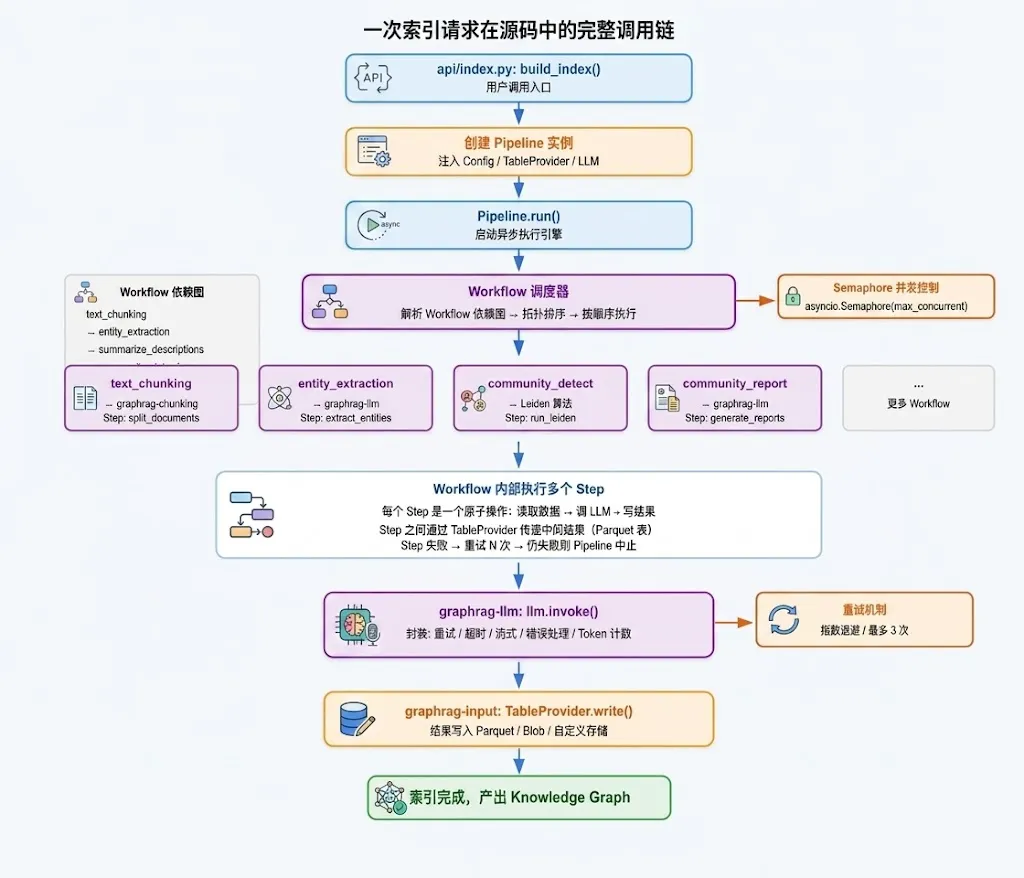 图 2|一次索引请求在源码中的调用链
图 2|一次索引请求在源码中的调用链
从
api/index.py:build_index()出发,经过 Pipeline → Workflow 调度器 → 多个 Workflow → 每个 Workflow 内部的 Step → Step 调用 LLM → 结果写入 Storage。橙色标注并发控制(Semaphore),红色标注重试机制。
完整调用链的关键节点:
** build_index()**:用户调用入口,创建 Pipeline** Pipeline.run()**:启动异步执行引擎Workflow 调度器:解析 Workflow 依赖图 → 拓扑排序 → 按依赖顺序执行 Workflow 内部:每个 Workflow 包含多个 Step,Step 之间通过 TableProvider 传递中间结果 Step 调用 LLM:通过 graphrag-llm 的 llm.invoke()封装,自动重试、超时、计数结果写入 Storage:通过 graphrag-input 的 table.write()写入 Parquet 或其他存储
并发控制:Pipeline 使用 asyncio.Semaphore 控制并发 LLM 调用数量,防止触发 API rate limit。
错误恢复:Step 失败后会重试 N 次(指数退避),仍失败则整个 Pipeline 中止并报告错误位置。
06 子包速查表
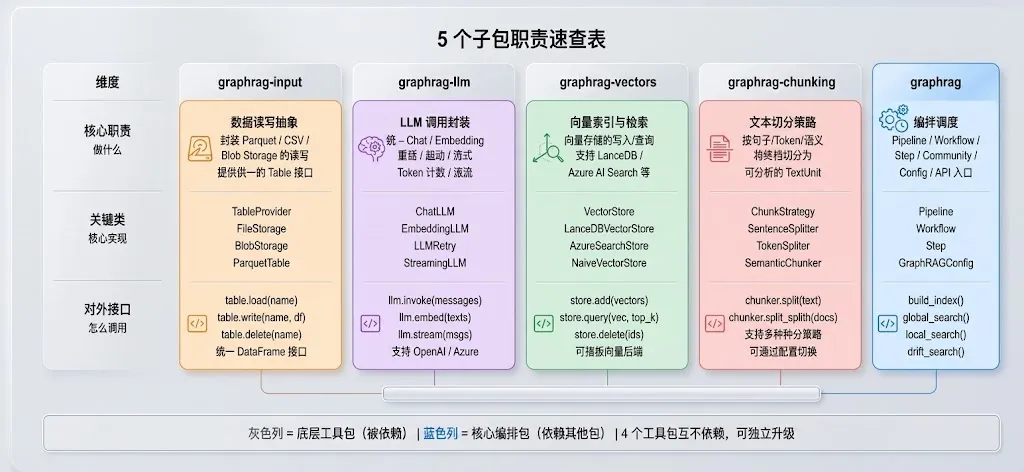 图 3|5 个子包职责速查表
图 3|5 个子包职责速查表
每列一个包,3 行分别列出核心职责、关键类、对外接口。灰色列是底层工具包(被依赖),蓝色列是核心编排包(依赖其他包)。
改代码时的快速定位
想换 LLM 提供商?→ 改 graphrag-llm,实现ChatLLM接口想换存储后端?→ 改 graphrag-input,实现TableProvider接口想换向量引擎?→ 改 graphrag-vectors,实现VectorStore接口想换切分策略?→ 改 graphrag-chunking,实现ChunkStrategy接口想改索引流程?→ 改 graphrag核心包的 Pipeline / Workflow想改查询逻辑?→ 改 graphrag核心包的api/query.py
07 为什么 v3.0 要拆成 Monorepo
拆包的 3 个核心收益
模块化:每个包有清晰的职责边界,改一个不影响其他 独立版本: graphrag-llm可以单独发版升级,不需要等整个 graphrag 发版可插拔:LLM / 存储 / 向量 / 切分 4 个层都可以替换实现,核心逻辑不变
Monorepo vs 多仓库
GraphRAG 团队选择 Monorepo 而不是 5 个独立仓库,原因是:
子包之间的接口还在演进,放在同一个仓库里方便同步修改 CI/CD 可以统一管理,确保所有包的兼容性 开发者 clone 一个仓库就能看到全部代码,降低贡献门槛
依赖管理
5 个子包通过 pyproject.toml 的 [project.dependencies] 声明依赖关系。用户只需 pip install graphrag,4 个子包作为传递依赖自动安装。
08 第一次上手怎么试:最小实验
实验条件
环境:已 clone graphrag v3.0 仓库 输入:无 预期观察:理解源码目录结构,找到两个入口文件
代码 4:最小实验步骤
# 1. 查看 packages 目录结构ls packages/# 应该看到:graphrag/ graphrag-input/ graphrag-llm/ graphrag-vectors/ graphrag-chunking/# 2. 找到索引入口cat packages/graphrag/graphrag/api/index.py# 3. 找到查询入口cat packages/graphrag/graphrag/api/query.py# 4. 查看 TableProvider 接口cat packages/graphrag-input/graphrag_input/table_provider.py# 5. 查看 ChatLLM 接口cat packages/graphrag-llm/graphrag_llm/chat_llm.py你应该观察什么
每个子包的目录结构是否清晰(src / tests / pyproject.toml) 对外接口是否简洁(Protocol 类定义) 核心包是否只做编排,不直接实现 LLM / 存储 / 向量逻辑
09 什么时候该改源码,什么时候别动
适合改源码的场景:
你需要接入一个 GraphRAG 不支持的 LLM 提供商(改 graphrag-llm) 你需要把数据存到自定义存储(改 graphrag-input) 你需要实现一个自定义的切分策略(改 graphrag-chunking)
不适合改源码的场景:
只是想调参数(改 settings.yaml 就够了) 只是想换模型名(改 .env 就够了) 只是想修改 prompt(改 prompts/ 目录下的模板就够了)
10 给读者一个真正能用来做决策的结论
决策帮助
如果你只是用 GraphRAG:不需要读源码,settings.yaml + .env + prompts/ 覆盖 90% 的配置需求 如果你需要扩展 GraphRAG:先读 TableProvider 和 ChatLLM 的接口定义,再决定改哪个包 如果你要贡献代码:从 api/index.py和api/query.py出发,顺着调用链往下读
v3.0 的 Monorepo 架构是"先拆清楚,再各自演进"的设计。理解了 5 个子包的职责边界,改代码就不会迷路。
如果你在阅读源码时遇到了具体的定位问题,欢迎在评论区写下你想改的功能,我帮你指出该看哪个包的哪个文件。
下一篇我们进入 Day 12:核心流程源码阅读。从 build_index() 出发,逐行跟踪 Pipeline 是怎么执行的。
如果这篇帮你搞清楚了 v3.0 的架构全貌,欢迎点个赞。
如果你正在改某个子包的代码但不确定该从哪里入手,欢迎在评论区写下你的需求。
参考链接
[GraphRAG GitHub 仓库] (https://github.com/microsoft/graphrag) [DEVELOPING.md - 开发指南] (https://github.com/microsoft/graphrag/blob/main/DEVELOPING.md) [GraphRAG 官方文档] (https://microsoft.github.io/graphrag/)
