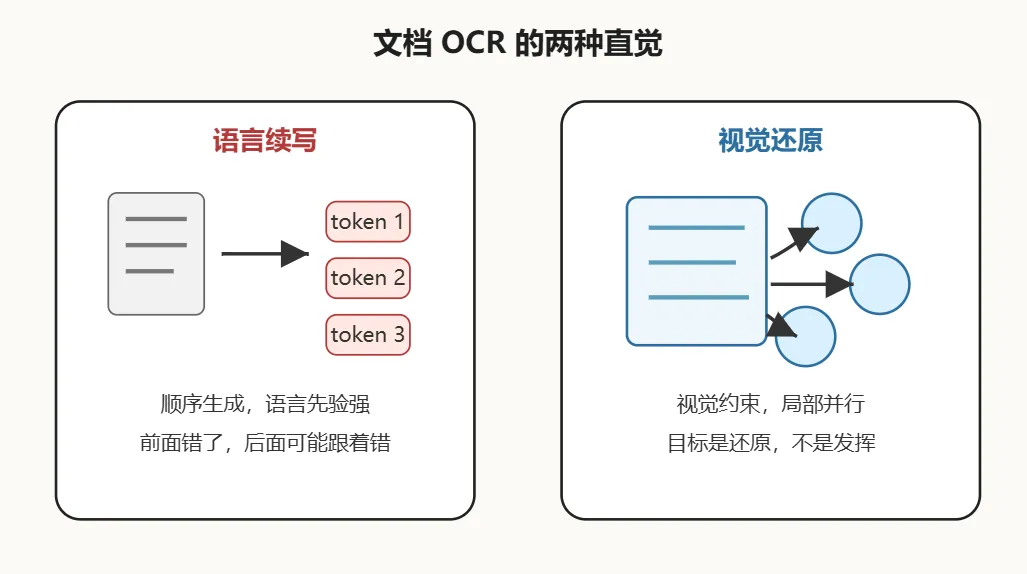
前两天看MinerU-Diffusion这篇论文的时候,脑子里一直有一个很小但很刺的问题,AI 读一份 PDF 的时候,它到底是在看图,还是在猜词?论文PDF下载链接:https://arxiv.org/pdf/2603.22458v1这个问题听起来有点怪。OCR 嘛,不就是识别文字吗。你给它一张扫描件,它把文字、表格、公式抠出来,不就完事了吗。但你稍微想深一点,就会发现这里面有个很微妙的差别,如果一个模型看到一行字有点糊,它输出了一句很通顺、很合理、很像原文的内容,我们到底应该夸它聪明,还是应该警惕它在补全?这个区别,在聊天机器人里可能不算特别致命。你问它一个开放问题,它接着上下文写出一段合理回答,本来就是它的工作。但在 OCR 里,这事儿就有点危险了。因为 OCR 的目标不是写出一段合理的话,而是把图上真的有的东西还原出来。哪怕原文不通顺,哪怕表格里有奇怪缩写,哪怕公式旁边有一串没人类语感的符号,它也应该老老实实还原。它不能因为自己觉得这样更像人话,就帮你把它改顺了。所以 MinerU-Diffusion 这篇论文有意思的地方在于它重新问了一遍这个问题:文档 OCR 到底应不应该被当成从左到右的语言生成?从左到右生成,是习惯,不一定是真理
现在很多 VLM 文档 OCR 系统,大体上都是一个熟悉的套路。前面有一个视觉编码器,把页面图像变成视觉特征。后面接一个语言解码器,把识别结果一个 token 一个 token地吐出来。这个设计很自然。因为大语言模型就是这么生成文本的。从左到右,前面生成什么,后面接着生成什么。写文章可以这么写,聊天可以这么聊,代码也可以这么补。你看一页论文的时候,并不是从左上角第一个 token 开始,在脑子里一个字一个字续写到页面结束。你其实是在看一个二维页面。标题在哪,正文在哪,表格边界在哪,公式从哪里开始,阅读顺序怎么走,这些东西都不是纯语言序列给你的,而是页面结构给你的。也就是说,一页文档只是最终被序列化成了一串 token,不代表它原本就是一个单向序列。这个差别很关键。自回归解码放在文档 OCR 里,会带来三个问题。一个是慢,长文档、复杂表格、公式这些东西,本来输出就长,你还要一个 token 一个 token 生成,延迟自然跟着上来。一个是串,前面如果错了,后面可能就会顺着错下去。长序列里这种错误传播放大之后,很难看。还有一个更隐蔽:语言先验太强。模型太会写合理文本了,所以当视觉信号弱、局部模糊、语义被破坏的时候,它可能会优先输出一个语言上更顺的答案,而不是视觉上更忠实的答案。自回归模型已经把文档 OCR 推到了很高的水平,MinerU2.5、PaddleOCR-VL 这些模型都很强。问题在于,OCR 这个任务可能不应该默认套用开放式文本生成的那套因果顺序。尤其是你面对的是论文、报表、扫描件、表格、公式这种复杂文档时,你真正想要的不是一个会续写的模型,而是一个愿意盯着图像证据干活的模型。论文最漂亮的一刀,是把 OCR 改写成反向还原
MinerU-Diffusion这篇论文用了一个说法,叫 inverse rendering。直译过来就是反向渲染。但如果只是这么翻译,基本没啥感觉。我更愿意把它理解成,从图像里把结构反向还原出来。正常的渲染,是你有一份结构化内容,比如文字、表格、公式、版式,然后把它画成一张页面图像。OCR 要做的事情刚好反过来。它看到的是页面图像,想恢复出背后的结构化 token 序列。听着很简单,但这个表述把问题一下子拧过来了。如果 OCR 是语言生成,那模型会自然地沿着语言顺序往后写。如果 OCR 是反向还原,那模型就应该尽量利用整张图里的视觉证据,去恢复每个位置上本来是什么。这里有个很重要的小点,一维 token 序列是输出格式,不是文档的原始形态。文档原本是二维的。段落、表格、公式、阅读顺序,这些关系很大一部分来自空间布局。我们把它压成一串 token,只是为了让模型和评测系统好处理,不代表任务本身就该被理解成从左到右写作。我觉得这就是这篇论文最值得被认真看的地方。它不是单纯说,我要把 自回归 换成 diffusion。它是在说,哥们,我们可能一开始就把任务说歪了。那 diffusion 怎么放进来?
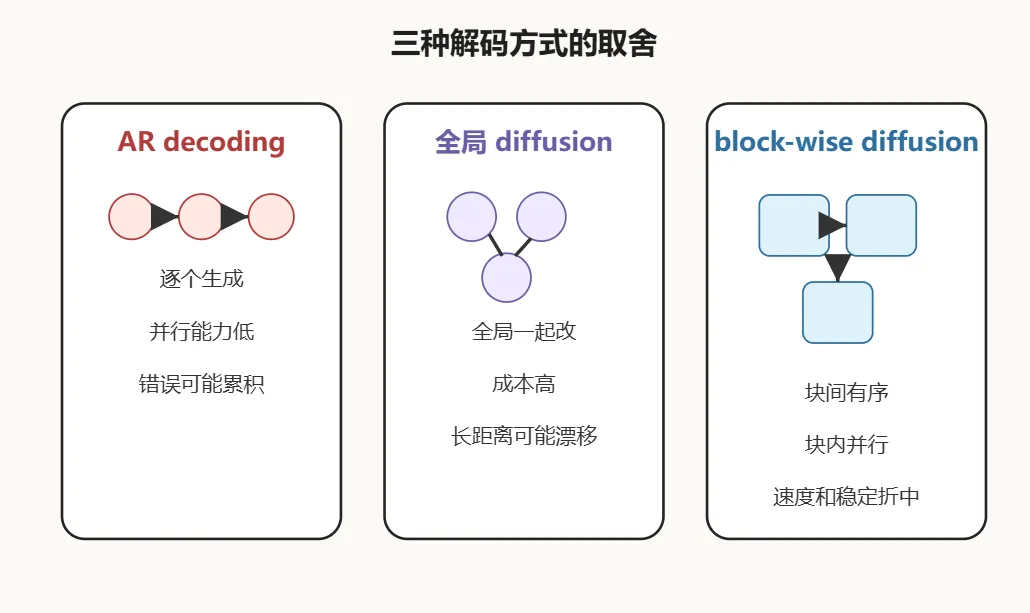
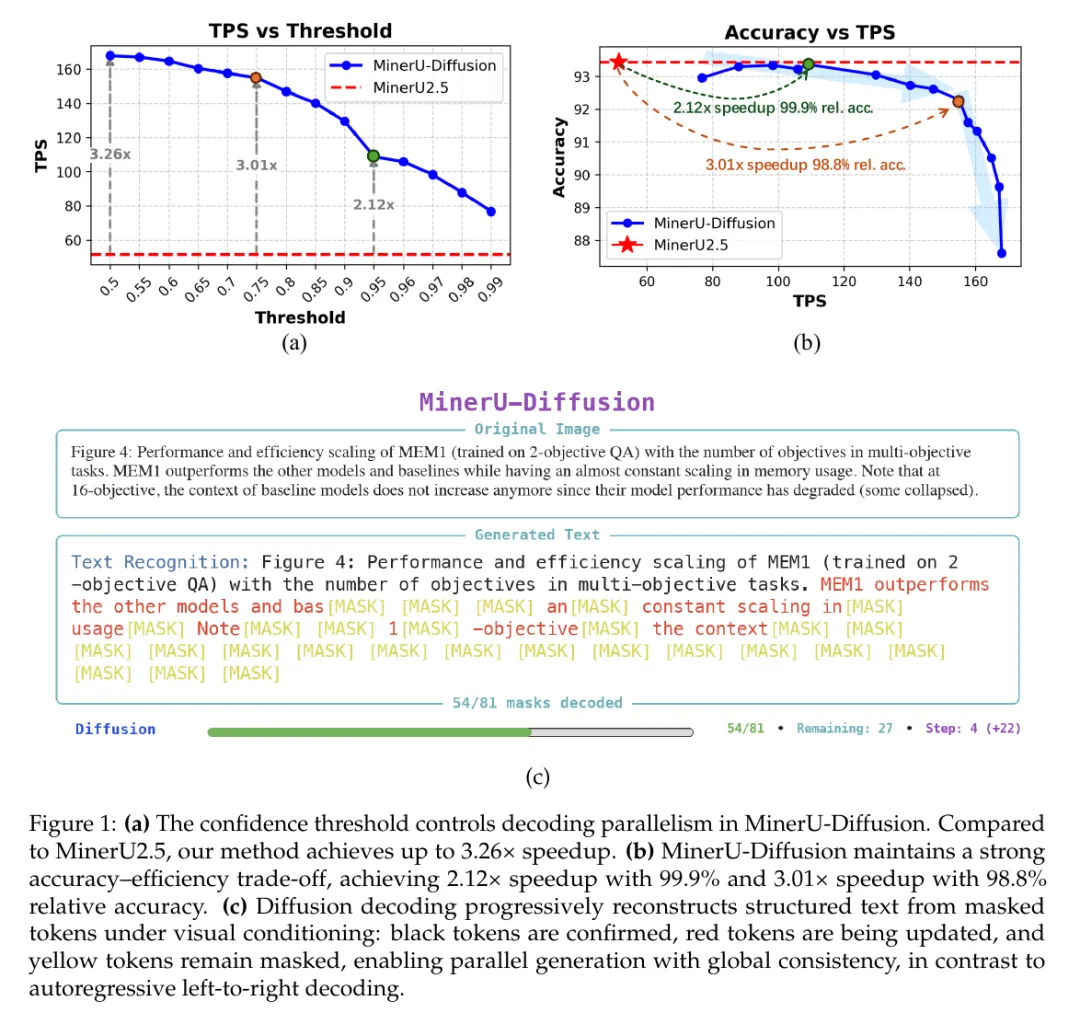
如果你只听到这里,可能会有一个疑问。就算 OCR 更像反向还原,为什么就一定要用 diffusion?这也是我觉得这篇论文没有乱套概念的地方。它没有直接把一个全局 diffusion 模型硬塞到长文档上。因为那样也会出问题。长文档 token 太多,全局注意力成本会很高。更麻烦的是,如果所有位置都一起全局去噪,早期的错误可能会在长距离上传开,位置对齐也容易漂。文档这个东西又很局部,表格区域和正文区域、公式区域和标题区域,并不总是需要强行全局耦合。所以 MinerU-Diffusion 做了一个折中。我觉得这八个字差不多就是这部分的核心。它把输出序列切成块。块和块之间还保留粗粒度的顺序关系,所以不会完全失去结构锚点。每个块内部则用 diffusion 的方式并行去噪,多个 token 可以一起更新,不必像 自回归 那样一个接一个排队。这个设计挺聪明的。它没有假装文档完全不需要顺序,也没有继续把所有东西都锁死在单 token 生成里。它承认文档有序,但也承认文档局部结构可以并行恢复。这就是为什么我觉得它比单纯喊一句 diffusion OCR 要扎实。它不是为了追时髦把 diffusion 搬过来,而是在问,文档的结构到底要求什么样的解码方式?顺着这个机制,论文还加了两个辅助设计。一个是置信度调度,大概意思是,不是每一步都一股脑确认所有 token,而是根据模型的置信度动态决定哪些 token 可以先定下来,哪些还要继续去噪。你可以把它理解成,模型不是闭着眼一口气填完整页,而是一边填,一边判断哪些位置已经比较确定。这个设计对应的是速度和稳定之间的取舍。阈值设得激进一点,生成更快,但低置信 token 可能更早被确认。阈值保守一点,模型会多跑几轮,稳定性更好,但速度下降。论文里thr=0.95是一个比较关键的平衡点,Overall 约 93.37,同时吞吐约 108.9 TPS。另一个是不确定性课程学习。这个名字听起来很学术,但人话版本并不复杂。先让模型在更广、更稳定的数据上学会基本能力,再把它容易不确定、边界更难的难样本挑出来做强化。先站稳,再修边界。主菜还是 block-wise diffusion。置信度调度和课程学习更像两个稳定器,一个管推理时怎么确认 token,一个管训练时怎么处理难样本。证据最有意思的地方,不是分数,而是那组语义打乱实验
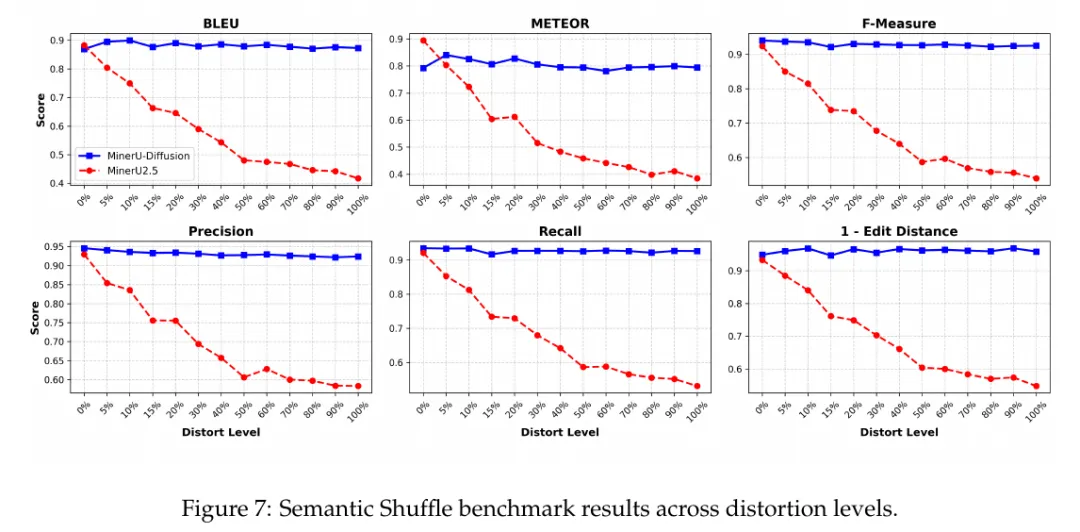
论文当然做了很多benchmark。在OmniDocBench v1.5上,有GT Layout设置下,MinerU-Diffusion 的Overall约 93.37,接近 MinerU2.5 的 93.44 和 PaddleOCR-VL 的 93.91。论文也说,在保持竞争性精度的同时,解码最高可以到约3.2 倍加速。这些数字有用,但坦率的讲,这篇论文有意思的,是 Semantic Shuffle。这个实验设计很直接。它把文档里的词按比例打乱,再重新渲染成视觉上格式一致的新文档。这样一来,语言层面的顺序和语义被破坏了,但视觉呈现仍然可比。你想想看,如果一个 OCR 模型真的主要靠看图,它应该还能尽量读出图上的文字。可如果它很依赖语言合理性,那语义一乱,它就会明显掉下来。论文里的结果显示,随着打乱程度增加,自回归解码器性能会明显下降,而 diffusion-style decoder 更稳。这个实验很妙。因为它不是在问模型会不会写一段更合理的话,而是在问模型能不能在语义不合理的时候,仍然尊重视觉证据。也就是回到文章开头那个问题:它到底是在看图,还是在猜词?图注,Semantic Shuffle 用来测试模型在语义被打乱时是否仍依赖视觉信号。
当然,这个实验也不能被过度解读。它不能证明 diffusion 在所有 OCR 场景里都更好,也不能证明 自回归 模型就不值得用。它证明的是,在语义结构被破坏的时候,diffusion-style decoder 对语言先验的依赖更低,更贴近视觉信号。另外,速度和精度也要放在设置里看。论文里 Figure 1、Figure 4、Figure 5 和 Table 4 都在讲同一件事,MinerU-Diffusion 可以通过置信度阈值调节并行度,在效率和精度之间找平衡。论文提到一个比较抓人的结果,是在thr=0.95附近,Overall 约 93.37,同时达到约 108.9 TPS,对比 MinerU2.5 的匹配精度设置大约有2.1 倍加速;阈值更激进时,最高加速接近3.2 倍,但精度会相应下降。图注,速度与精度取舍的关键结果。
所以这篇论文不是在说,我有一个模型,所有指标都碾压了。它更像是在说,我换了一种任务表述和解码方式,在精度仍然有竞争力的情况下,换来了更好的并行效率,以及在语义扰动下更强的视觉忠实性。比结果更值得关注的,是它背后的思路
我看这篇论文的时候,反复想起一个很普通的经验。很多时候,我们不是没有模型能力,而是把问题问错了。你把一个任务说成聊天,它就会按聊天的方式工作。你把一个任务说成写作,它就会按写作的方式补全。你把 OCR 说成从左到右生成文本,它当然会天然靠近语言模型那套工作方式。但文档 OCR 不是写作,而更像验尸。虽然不好听,但很准确。你面对的是一张已经存在的页面。你的工作不是发挥,不是润色,不是让它读起来更顺,而是尊重现场,把每个痕迹尽量还原出来。从这个角度看,MinerU-Diffusion 最重要的贡献不是告诉我们 diffusion 一定比 自回归 高级。它提醒我们,模型范式要服从任务,而不是反过来。有些任务确实适合从左到右生成。写文章、对话、代码补全,这些任务本来就有开放性,语言先验是一种能力。但有些任务看起来像文本输出,实际上被外部证据强约束。OCR 是这样,某些结构化信息抽取、表格还原、版式解析,可能也是这样。模型不应该太会发挥,它应该更会服从证据。这也许是 diffusion language model 一个很现实的落点。不是一上来就要取代所有大语言模型,不是直接杀进开放式写作,而是在那些确定性更强、外部证据更强、并行还原更重要的任务里,找到自己的位置。我觉得这个方向挺值得继续看。因为它背后真正的问题,不是 diffusion 和 自回归 谁赢谁输。而是我们终于开始更认真地问,不同任务到底应该被怎样表述。AI 读文档这件事,看起来很小。但它把一个更大的问题露出来了。当我们让模型做一件事的时候,我们到底是在让它创造,还是在让它还原?混在一起之后,你得到的东西可能很通顺,很聪明,很像真的。
如果你对文档解析、OCR、多模态模型这些方向感兴趣,也欢迎来群里一起交流。扫码即可加入:
 夜雨聆风
夜雨聆风