 夜雨聆风
夜雨聆风每次刷新都是一次"全量重算"
你的数据管道里,有多少张表是这样工作的:
每隔一小时,把源表全量扫一遍,重新算一次聚合,覆盖写入目标表。
数据量 1TB,每次刷新就扫 1TB。数据增量只有 0.1%,计算成本却是 100%。
这不是个别现象,而是批处理 ETL 的常态。更麻烦的是,当你想把刷新频率从"每小时"压缩到"每分钟",全量重算的代价会让整个链路直接撑不住。
两条路,都不好走
面对这个问题,通常有两条路:
路径一:引入流计算引擎。Flink 确实能做到秒级实时,但代价是重构整条链路——EventTime、Watermark、Window、状态后端,每一个概念都需要重新学习,现有的 SQL 资产几乎无法复用。
路径二:继续忍受批处理的延迟。业务数据"昨天的",报表永远慢半拍。
但其实还有第三条路:增量计算——只处理变化的数据,用批处理的 SQL 语义,实现接近流计算的刷新频率。
问题在于,增量计算的正确实现并不简单。AI 编程助手"知道"增量计算的公式,但在实际生成代码时,往往会在关键细节上出错。
这些都正是 Incremental Skills 要解决的问题:我们发现,增量计算的核心原理是通用的,然而,这些知识长期分散在学术论文、系统文档和工程师经验中,缺乏系统性的整理。与此同时,AI 编程助手正在改变软件开发范式,但对增量计算的理解往往停留在理论层面,在实际生成代码时容易遗漏关键细节。我们希望借助这套完整的增量计算技能包,系统性地呈现增量计算的知识体系,让开发者都可以在不迁移数仓的前提下,以尽可能少的改动体验到增量计算的收益。
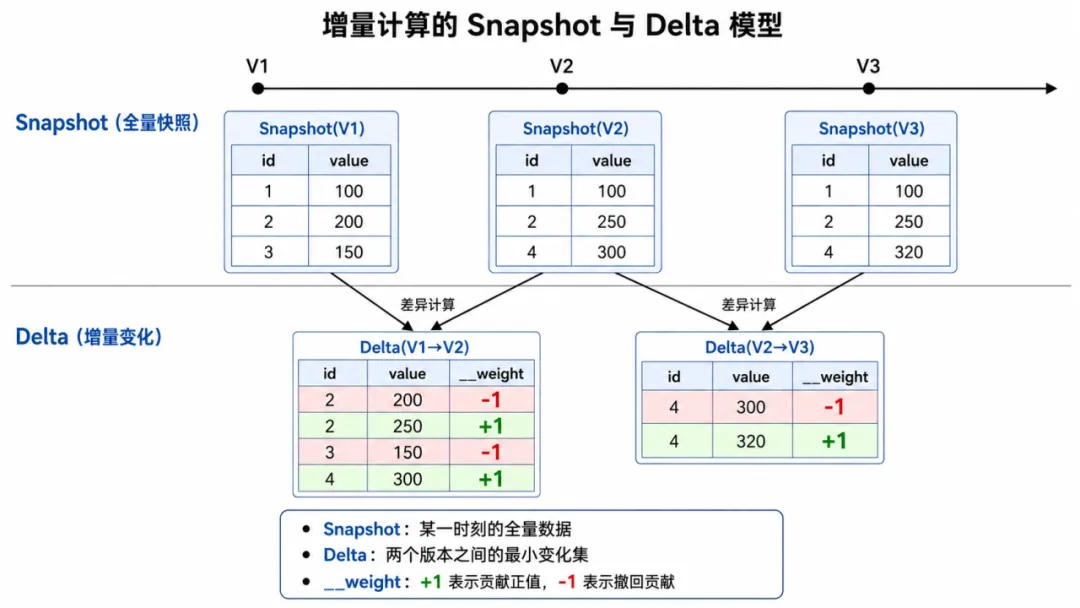
核心模型:Snapshot 与 Delta
增量计算的基础是两个原语:
Snapshot(V):版本 V 时刻的全量快照
Delta(V1, V2):两个版本之间的行级变化,每行携带 __weight 列(+1 表示插入,-1 表示删除,UPDATE = 旧行 -1 + 新行 +1)
__weight 是增量计算的核心。以聚合为例:
-- 全量聚合(扫全表)SELECT group_key, SUM(value) FROM snapshot GROUP BY group_key-- 增量聚合(依赖上次的聚合结果,处理增量数据)SELECT group_key, SUM(sum_res)FROM (-- 旧状态:每个group key只保留1行SELECT group_key, sum_res FROM stateUNION ALL-- 新插入的增量数据SELECT group_key, value * __weight FROM insert_delta) GROUP BY group_key;
删除的行 __weight = -1,乘以 value 后贡献负值,自动从累计结果中扣除。这一行代码的差异,决定了增量计算是否正确。
场景一:电商大促实时销售看板
业务需求:大促期间,运营需要每分钟看到各品类的实时销售额和订单量,用于动态调整活动策略。
原始 SQL:
SELECTc.category_name,COUNT(o.order_id) AS order_count,SUM(o.amount) AS total_amountFROM orders oJOIN categories c ON o.category_id = c.idWHERE o.status = 'paid'GROUP BY c.category_name
这条 SQL 包含 JOIN + GROUP BY,增量维护需要分两层处理:
Layer 1(JOIN 层):对 orders 和 categories 的 Delta 分别应用 JOIN 的增量规则。例如,当orders产生新数据的时候,只需要将这部分新数据与categories进行JOIN即可得到当前层的增量结果,而无需读取orders的历史数据。
Layer 2(聚合层):对JOIN产生的 Delta 应用 Aggregation 的增量规则。COUNT 和 SUM 都是可撤回的——删除的行通过 __weight = -1 自动从累计值中扣除,无需重扫历史数据。
每次刷新,只处理新增/变更的订单行,计算量与订单增量成正比。大促高峰期每分钟新增 10 万笔订单,只需结合历史聚合结果,处理这 10 万行,而非全量的数亿行历史订单。
场景二:商品最低价格订阅
业务需求:价格监控系统需要实时维护每个商品的历史最低价,当最低价发生变化时触发用户订阅通知。
原始 SQL:
SELECT product_id, MIN(price) AS min_priceFROM price_historyGROUP BY product_id;
MIN 是不可撤回聚合 —— 例如当一条价格记录被删除时,如果它恰好是当前最低价,你无法通过简单的加减法得到新的最低价,必须重新扫描该商品的所有历史价格。
增量技能包对此的处理策略是:受影响分组重算。
每次刷新时,先从 Delta 中找出哪些 product_id 发生了变化,然后只对这些商品重新执行 MIN(price) 查询。如果一次刷新涉及 500 个商品的价格变动,只需重算这 500 个商品,而非全量的百万级商品。
这与可撤回聚合的处理方式截然不同,也是 AI 在没有领域知识支撑时最容易混淆的地方。
AI + 技能包:正确实现的关键
现有的AI Agent在增量计算上的失误,往往不是"不知道",而是"知道但遗漏了细节"。技能包系统性地覆盖了这些细节,在此示例一些AI常犯的错误:
Delta 去重:同一行在一个批次内可能出现多次(多次更新产生一系列先删后插的数据记录)。直接应用未去重的 Delta 会导致 PK 冲突或幽灵行。正确做法:GROUP BY 所有列 HAVING SUM(__weight) != 0。
数据清理:当Aggregate一个分组的所有行都被删除后,状态表中该分组的 accumulated_count 会归零。如果不清理,这个"空分组"会作为幽灵行出现在查询结果中。
多层版本传播:大部分计算都需要依赖自身的历史状态和输入源的增量数据,Layer N+1 的 from_version 必须来自自己的 Profile,而不是 Layer N 的 Profile。混淆这一点会导致数据重复处理或丢失。
空集 NULL 保护:SUM() 在无匹配行时返回 NULL,后续 NULL + 5 = NULL。必须用 COALESCE(SUM(...), 0) 保护。
诸如此类的陷阱,每一个都能让看似正确的增量 SQL 在生产环境中悄悄产生错误数据。
安装与使用
Incremental Skills 遵循 Agent Skills 规范:
https://agentskills.io/home
支持 Claude Code、Cursor、Kiro、Copilot CLI、Gemini CLI、Codex 等主流 AI 编程助手。
安装方式,执行:
npx skills add clickzetta/incremental-skills安装后,直接在AI Agent中使用:
/incremental-computation 将批处理任务 order_summary 转换为增量计算/incremental-computation REFRESH TABLE order_summary
AI Agent 会加载技能包,确认如何获取 Snapshot、Delta、Schema 和版本信息,然后按照算法参考生成正确的增量 SQL。
相关的内容一并开源整理在了GitHub中 Incremental-Skills,包含完整示例,感兴趣的朋友欢迎移步查阅。https://github.com/clickzetta/incremental-skills
结语
Incremental Skills 由云器科技开源(Apache 2.0)。云器在自研的 ClickZetta Lakehouse 中深度实践增量计算多年,并发布了《增量计算技术白皮书》。技能包将这些实践经验系统化,以引擎无关的形式开放给社区。
如果你的数据管道正在被全量重算拖累,或者你想让 AI Agent真正理解增量计算而不只是"知道公式",不妨试试这个技能包。
如果你的场景需要应用于严肃的生产环境,并且对数据安全性和时效性有明确要求,建议直接使用 ClickZetta Lakehouse——增量计算在其中是引擎原生支持的能力,而非依赖 AI 生成的 SQL 拼接。配合 cz-cli 可以在命令行直接管理动态表的增量刷新,开箱即用。
项目安装地址:npx skills add clickzetta/incremental-skills
获取cz-cli安装文档请访问:
https://www.yunqi.tech/documents/setup_cz_cli
🎁 限时福利
✅ 新用户赠200元体验代金券
✅ 免费领取《智能网联汽车数据平台白皮书》
➤ 即刻通过下方网址/扫描二维码体验:
www.yunqi.tech
END
▼点击下方小程序,一键解锁云器产品与解决方案
全套资料、视频与技术洞察尽在掌握!
关于云器
云器Lakehouse作为面向企业的全托管一体化数据平台,只需注册账户即可管理和分析数据,无需关心复杂的平台维护和管理问题。新一代增量计算引擎实现了批处理、流计算和交互式分析的统一,适用于多种云计算环境,帮助企业简化数据架构,消除数据冗余。
点击文末“阅读原文”,前往云器官网申请试用,了解更多产品细节!
官网:yunqi.tech
B 站:云器科技
知乎:云器科技
往期推荐
云器科技正式发布 Data Engineering Agent:以 Agentic AIOps 重新定义数据开发方式
