 夜雨聆风
夜雨聆风
最近 Harness Engineering 突然火了。
OpenAI 发布了《Harness engineering: leveraging Codex in an agent-first world》,Anthropic 发布了《Effective harnesses for long-running agents》,LangChain 发布了《The Anatomy of an Agent Harness》,Martin Fowler / Thoughtworks 也发布了《Harness Engineering》。GitHub 上甚至出现了一个「awesome-harness-engineering」列表,收录了几十个相关资源。
这绝非偶然。Agent Coding 已经从只会写单个函数,进化到全天开发完整功能。业内慢慢看清:制约 Agent 落地的不是大模型性能,而是配套运行环境。
Agent 的瓶颈不是模型能力,而是模型运行的环境。
Harness Engineering 提炼出了通用落地范式,部分思路与衡石此前 JARVIS 项目的研发方向重合,但二者仍存在本质区别。本文将梳理二者的共性与核心差异。

一、Harness Engineering 究竟是什么
Harness 这个词,最早来自 Anthropic 对 Claude Code 的工程实践。它的核心含义是:
Agent = Model + Harness
模型提供推理能力,Harness 提供一切让推理能落地的环境。
具体来说,Harness Engineering 关注的是:
1. Context Engineering(上下文工程)
怎么管理 agent 的上下文窗口。不是”塞得越多越好”,而是把上下文当作工作记忆预算来管理。Manus 团队讲的 KV-cache 局部性、工具屏蔽、文件系统记忆;Anthropic 讲的 context condensation;OpenHands 讲的 bounded conversation memory——都是在解决同一个问题:agent 跑久了,上下文会失控。
2. Constraints & Guardrails(约束与护栏)
怎么让 agent 自主但不失控。沙箱、权限策略、审批节点、工具边界。Anthropic 讲的 sandboxing、MCP 执行控制;HumanLayer 讲的 12 Factor Agents;Thoughtworks 讲的 quality check in the loop——都是在回答:自动化的边界在哪?
3. Specs & Agent Files(规约与指令文件)
AGENTS.md、CLAUDE.md、agent.md——这些 repo-local 的指令文件告诉 agent”在这个仓库里怎么工作”。GitHub 的 Spec Kit 更进一步,把 spec-driven development 变成标准流程。
4. Evals & Observability(评估与可观测性)
怎么知道 agent 做得好不好。不只是看最终结果,还要 trace 整个过程。OpenAI 的 eval skills、Anthropic 的 trace grading、LangChain 的 multi-turn eval——agent 越自主,你越需要可观测性。
5. Runtime & Orchestration(运行时与编排)
Agent 的生命周期管理:启动、暂停、恢复、多 agent 协调。LangChain 的 deepagents、Inngest 的 AgentKit、SWE-agent 的执行环境。
我们简要总结 Harness Engineering:
它关注 agent 如何稳定运行。
二、JARVIS 的核心定位
此前小编已发布 JARVIS 系列文章:《构建软件公司的 JARVIS》聚焦整体落地方法论,《从 AI 写代码到 AI 驱动研发》论证 Coding agent 无法等同于完整研发体系。
相关核心观点不再赘述,本文仅提炼关键结论:
JARVIS 关心的不是 agent 如何运行,而是 agent 运行的时候知识库里有什么。
具体来讲,JARVIS 是一个按 History / Present / Future 三层时态架构组织的产品知识库:
History:5.7 万个 issue 的分类索引、18 个模块的深度文档、635+ 条 MR 修复摘要、7311 条被否决需求、60+ 条破坏性变更、跨模块依赖矩阵
Present:当前 backlog 快照、版本计划、团队配置
Future:AI 对 backlog 的去重检测、优先级分析、排期推荐
它解决的核心问题是:当 AI agent 面对一个 bug 时,它不只是看当前代码——它能够追溯至 3 年前这个模块的设计原理,总结类似 bug 过往修复方案 ,了解哪些方案已经被否决。
由此,我们简要总结 JARVIS:
它关心的是 agent 有多少知识沉淀。
三、本质差异:运行环境层 VS 长期记忆层
现在区别相对清晰。
我们具体举例:
如果 Harness Engineering 给 agent 提供了标准化手术室,灯光、器械、监控设备、安全规程都到位。
JARVIS 则是让上手术台的 agent 拥有十年临床经验,它知道病人病史,知道过往手术失败原因,知道药物禁忌。
完善的手术室不可或缺,但缺乏临床经验的医师,即便身处优良环境仍易出现重大失误。
反之,经验丰富的医生,在简陋的条件下也能救治,但给他配备完善的手术室,他能做得更好。
由此可见, JARVIS 和 Harness Engineering 的关系:它们各司其职且相辅相成。
四、Harness Engineering 体系现存短板
梳理 awesome-harness-engineering 相关资源可以发现,其定义的 Memory 仅针对Context(Memory & Working State)、Constraints(Guardrails & Safe Autonomy)、Specs(Agent Files & Workflow Design)、Evals & Observability 、Benchmarks 和 Runtimes(Harnesses & Reference Implementations)。
其中 Context, Memory & Working State看似和 JARVIS 能力相似,但细分落地内容不难发现差异:Anthropic 聚焦上下文窗口优化、节约 Token 开销;Manus 依托 KV 缓存局部性提升缓存效率;OpenHands 通过会话压缩留存关键信息;HumanLayer 侧重规避上下文漂移问题。这些方案都围绕运行时的记忆展开,只能管控单次任务周期内的短期记忆。
而产品长期沉淀的组织记忆并未纳入 Harness 体系,例如模块原始设计逻辑、同类故障历史修复方案、过往废弃技术路线、功能测试短板、代码改动带来的跨模块联动风险等内容,这类知识不在上下文窗口里,不在 AGENTS.md 里,不在任何 harness 组件里。
Harness Engineering 的”Memory”是工作记忆(Working Memory),类比计算机 RAM。JARVIS 的”Memory”是承载的是沉淀全生命周期信息(Long-term Memory),更像是硬盘。二者缺一不可,但技术定位完全不同。
五、JARVIS 离不开 Harness 配套落地
反观 JARVIS,仅搭建知识库同样无法独立运转。在实际操作中,JARVIS 的知识库需要被 agent 有效调用。这个落地环节恰好在 Harness Engineering 的能力边界内:
上下文预算分配
JARVIS 有 18 个模块、每个模块有 overview、known-issues、decisions、test-coverage、faq。如果 agent 接到一个 charts 模块的 bug,不能把 18 个模块的文档全塞进上下文——需要智能路由。这是 Context Engineering 的问题。
工具边界设计
Agent 应该能搜索 JARVIS、能更新 JARVIS,但不应该在没有人工审批的情况下删除或覆盖关键知识。这是 Guardrails 的问题。
知识更新的评估
Agent 从一次 bug 修复中提炼出的 known-issue 条目,质量怎么样?有没有幻觉?这是 Evals 的问题。
多 agent 协调
一个 agent 在修 bug,另一个在更新知识库,还有一个在跑回归测试。它们之间怎么协调?这是 Orchestration 的问题。
两者结合我们能看到:
JARVIS 提供了 agent 需要的知识,Harness Engineering 提供了 agent 使用这些知识的可靠方式。
六、两者协同,配套落地
在衡石的实际工作中,JARVIS + Harness 的搭配是这样运作的:
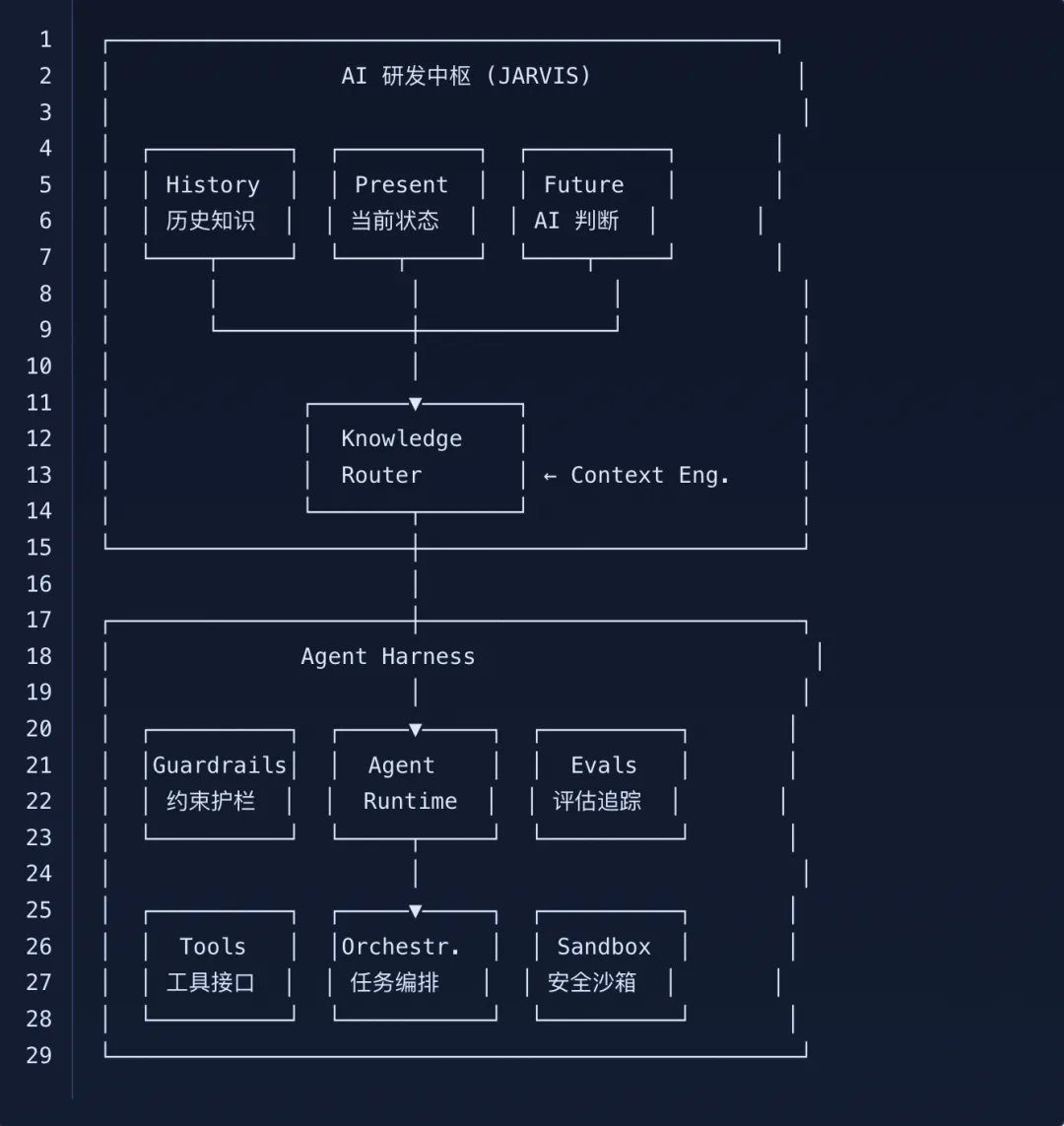
我们用一个典型案例说明:
Issue 进入 → Harness 接收任务,分配至 agent
知识路由 → JARVIS 根据 issue 内容匹配模块,推送相关 overview、known-issues、decisions
上下文组装 → Harness 的 Context Engineering 决定推多少知识进上下文(预算管理)
方案生成 → Agent 基于知识库生成修复方案
约束检查 → Harness 的 Guardrails 检查方案是否触及已知风险(JARVIS 的 cross-module interactions)
代码实现 → Agent 写代码
测试验证 → Harness 运行测试,对比 JARVIS 的 test-coverage 确认覆盖
知识回写 → 修复完成后,agent 更新 JARVIS 的 known-issues 和 fix-knowledge
评估记录 → Harness 的 Evals 记录整个过程的质量指标
整套流程的每个环节均离不开 JARVIS 与 Harness 的协同支撑,任一模块缺失都会造成体系闭环断裂。
七、行业预判
纵观 Harness Engineering 生态发展趋势我们可以大胆预测,这个体系会在 2026-2027 年被标准化。Context Engineering、Evals、Guardrails 这些东西会变成基础设施,就像 CI/CD 在 2015 年被标准化一样。
但是:组织记忆不会被标准化。
各企业产品形态、迭代历程、设计思路与过往问题存在差异化特征,通用 Harness 框架可以跨企业复用,但 JARVIS 这类记忆体系无法通用。
Harness 相关能力可依托 SWE-agent、AgentKit 等开源产品直接采购落地,而企业专属的记忆层只能自主搭建。
JARVIS 并非标准化商用产品,本质上是企业独有的组织能力,他的核心价值不在于开发技术,而是企业对自身业务的沉淀理解,组织记忆的结构化沉淀深度直接决定 AI 智能体能力上限。
八、落地建议
针对正在尝试 AI 深度参与研发的团队,衡石总结出以下建议:
先做 Harness,再做 JARVIS。
Harness 的投入产出比更直接:写好 AGENTS.md、配好沙箱、接好测试、设好审批节点。这些是低垂的果实,能立刻提升 coding agent 的可靠性。
Harness 完成后,启动组织记忆建设
从 issue 系统开始:导出历史 issue,做模块分类,提取高频 bug 模式和被否决需求。你会发现,光是”让 AI 知道哪些方案之前被否决过”,就能省掉大量重复讨论。
同时进行时关,注两层体系的连接
记忆层和运行层的连接是最容易出问题的地方:知识路由是否准确?上下文预算是否合理?知识回写是否有质量保障?这些”接缝”决定了系统的实际效果。

结语
HENGSHI
Harness Engineering 的爆火绝非偶然。它标志着行业从”模型军备竞赛”转向”工程基建竞赛”。
工程基建解决智能体可靠运行的问题,但无法定义执行目标与决策依据,这个部分能力恰好由 JARVIS 补齐。
JARVIS 并非 Harness 的替代方案,而是上层支撑体系:Harness 保障智能体稳定执行,JARVIS 保障智能体决策方向准确。
一套成熟的 AI 研发体系,两层架构缺一不可。

相关推荐
关于衡石科技
衡石科技致力于在 Data+AI 的数据智能时代开创性定义新一代 Agentic BI,旗下产品HENGSHI SENSE作为企业级的数据智能引擎,赋能客户伙伴零代码构建垂直领域的AI分析智能体应用。
衡石科技成立于2016年,是国内数据分析平台领域唯一专注赋能企业级应用软件SaaS伙伴的产品厂商,服务WPP、宝马、广汽本田、阳狮集团、蓝色光标、国药集团、亚马逊云科技、太太乐、元气森林等大型集团企业客户,同时也和菲尼克斯电气、Synagie(新加坡)、中国航信、深信服、金蝶云、浪潮云、致远互联、天润融通、宝尊电商、纷享销客、六度人和、明道云、北森酷学院等超过两百家企业应用软件 SaaS 落地深度合作,让 built-in 的商业智能分析即刻上线。

