 夜雨聆风
夜雨聆风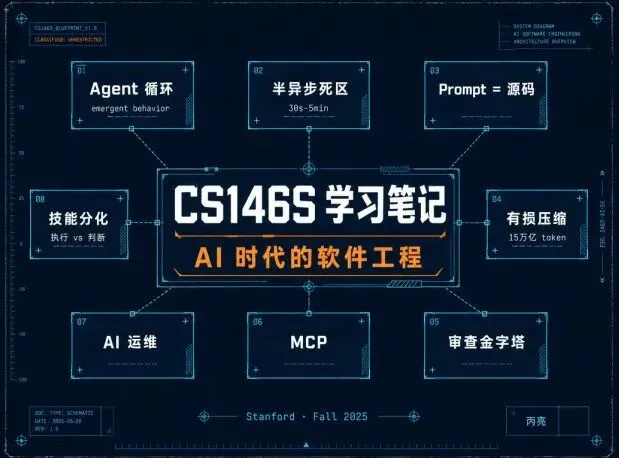
CS146S 学习笔记:AI 时代的软件工程
斯坦福第一门以 AI 驱动软件开发为核心的课程。不是编程入门课——是一份宣言。
讲师 Mihail Eric,斯坦福 AI 博士,前 Amazon Alexa 对话系统技术主管,YC 孵化过 AI 编程公司。课程邀请了 Anthropic(Claude Code 创造者 Boris Cherney)、Cognition(Devin 研究主管)、Semgrep(CEO Isaac Evans)、Vercel(v0)、a16z 等公司的核心人物做 guest lecture。
课程的核心论点
编程没有死,但它已经从根本上改变了。"现代软件开发者"不再是语法写手,而是系统架构师、AI 输出的验证者、自主 Agent 的管理者。
贯穿十周的四条主线:
- 从语法到规格
— Prompt 是新的源代码。编写清晰、无歧义的规格说明书已成为首要瓶颈 - "半异步"区域
— 开发者必须学会将 10 分钟以上的任务委托给 AI Agent,实现真正的并行 - 防御性 Prompting
— LLM 是随机、易出错的工具,需要一套全新的交互设计方法 - AI-Native 运维
— 从手动 runbook 到动态的、AI 生成的事件响应
一、LLM 的本质:互联网的有损压缩
预训练:预测下一个 token
数据来源是 Common Crawl——自 2007 年起索引万维网的非营利组织。截至 2025 年,归档超过 3000 亿网页,约 11.3 PB。全球几乎所有大语言模型 70-90% 的 token 来自 Common Crawl。
但这数据充满了噪音——广告、Cookie 横幅、垃圾邮件、恶意软件。经过严格过滤后的高质量数据集(如 FineWeb)仍包含约 44 TB 文本、约 15 万亿 token。
预训练的核心操作极其简单:基于前文预测下一个 token。GPT-4 据报告有 1.8 万亿参数(16 个专家子模型,每次激活其中 2 个,实际激活约 2800 亿参数)。训练成本:约 25,000 块 A100 GPU 运行 90-100 天,数千万美元。
关键洞察:预训练的产出是"互联网的大规模有损压缩"——人类知识的概率性 ZIP 文件。它学到的是"什么通常跟在什么后面",不是"什么是真的"。
这解释了模型绝大多数失败模式的根源:它不是"推理",是在做统计预测。它能解奥林匹克数学题,然后告诉你 9.9 < 9.1——因为它的能力分布像瑞士奶酪,遍布不可预测的孔洞。
SFT:赋予模型人格
监督微调用几万到几十万组人类标注的对话教模型"怎么当助手"。SFT 的计算成本极低——几小时,不是几个月。
Mihail Eric 的原话很祛魅:
当你与 AI 助手对话时,你不是在与某种新形式的智能互动。你在与一个神经网络互动——它在模拟那个严格按照指令工作的、平均水平的熟练人类标注员。
这意味着:你的 AI 助手不是一个"思考实体",而是一个"角色扮演者"。它的所有"友好"、"耐心"、"专业"都是标注员行为的统计投影。
RL:教会模型思考
在数学、代码等可验证领域,RL 强制模型自己发现推理路径。这就是 Chain-of-Thought 产生的阶段——因为每个 token 的计算量有限,模型学会将推理分布到多个步骤。
关键实践启示:模型需要 token 来思考。 让它"逐步思考"不是风格偏好——它解锁了一种不消耗 token 就不能工作的能力。要求它一次性产出复杂答案而不做推理,就像要求一个人不用草稿纸做微积分。
六种可靠性策略
| Few-shot | ||
| Chain-of-Thought | ||
| Self-consistency | ||
| RAG | ||
| Reflexion | ||
| Role prompting |
高手不是用一种策略——是知道什么时候用哪种组合。格式控制类任务加 CoT 可能坏事(过度思考),Self-consistency 的成本是 5 倍 token。
二、Coding Agent 的解剖结构
Agent 循环
工业级 Agent(Devin、Claude Code、Codex)都遵循同一个核心模式:
while not task_complete: context = build_context(task, history, available_tools) action = llm.decide(context) # 模型决定下一步 if action.type == "tool_call": result = execute_tool(action) history.append({"call": action, "result": result}) # 关键:工具执行结果作为新上下文输入,形成闭环 elif action.type == "final_answer": return action.content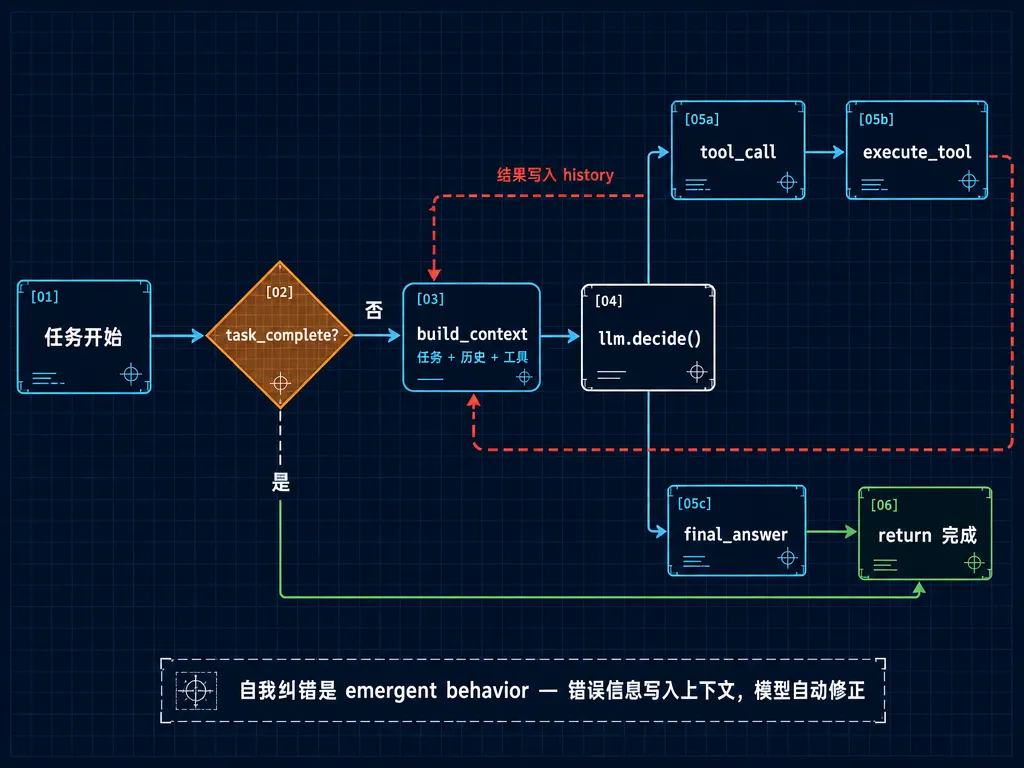
Agent 执行循环
精妙之处:没有显式的"如果失败则重试"逻辑。 Agent 的自我纠错是 emergent behavior——错误信息被追加到历史上下文中,模型下一轮"看到"错误,自然地尝试修正。这就是为什么清晰的错误信息对 Agent 如此重要——模糊的错误等于不给人类看报错信息。
Tool Use / Function Calling
工具调用不是模型"懂"了这个工具——是它在对话上下文中看到了工具的"说明书"(类似 JSON Schema),然后像生成其他文本一样生成了调用参数。工具描述的清晰程度直接影响调用成功率。
MCP:Agent 的"USB 接口"
Anthropic 2024 年底提出的标准化协议,三类原语:
- Tools
:模型可以调用的函数 - Resources
:模型可以读取的上下文数据 - Prompts
:预定义的 prompt 模板
课程要求学生从零构建一个 MCP Server——说明他们视"理解 Agent 如何与外部世界交互"为基本功,不是高级话题。
三、上下文工程:这门课技术含金量最高的内容
同步 vs 异步 Agent
| 真正的生产力倍增器 |
半异步死区——课程最实用的概念
避免让 Agent 执行 30 秒到 5 分钟的任务。
原因:
太短,不够你切换到需要深度思考的复杂任务 太长,干等着足以破坏心流 结果:既没推进工作,也没利用 Agent 的并行能力——两败俱伤
对策:
要么缩小任务到 30 秒内(同步化) 要么扩大到 10 分钟以上(真正异步委托) - 目标:最大化自己的并行度。你是一个多线程的编排者,不是单线程的等待者。
四大上下文失败模式
给 Agent 更多上下文 ≠ 更好的输出。超阈值后反而退化。
| Context Poisoning | |||
| Context Distraction | |||
| Context Confusion | |||
| Context Clash |
学术背景:斯坦福和 Meta 2024 年的论文《Lost in the Middle》首次证明 LLM 在长上下文中呈现 U 形性能曲线——开头和结尾准确率最高,中间显著下降。根源在 Transformer 架构中固有的 U 形注意力偏差。
防御性 Prompting 四原则
新的核心技能不是"写代码",是"做一个好的委托者":
- 精确而非笼统
— 说怎么做,不是说什么。区别不在于详细程度,在于约束密度。好 prompt 创造窄而深的"管道",坏 prompt 给出宽而浅的"草原" - 预测非显而易见的依赖
— 显式声明隐藏约束。Agent 没有你的隐性知识:它没在这个团队工作过,没参加过架构评审,没处理过上次的线上事故 - 嵌入人工检查点
— 多小时的复杂任务必须设阶段性审批节点。这不是不信任 AI——是不信任自己 prompt 的完备性 - 使用强类型语言
— TypeScript 优于 JavaScript。Agent 从类型错误中获得的信息远比运行时 bug 丰富——类型错误精确地告诉它"哪个位置、什么类型不匹配"
Prompt 是新的源代码
课程引用了 Shawn Gross 的类比:
传统开发中,你保留源码(Python, TypeScript),丢弃编译后的机器码。源码包含意图、结构和所有设计决策。
在 AI 驱动的开发中,团队目前的实践是:精心撰写 prompt → 生成代码 → 丢弃 prompt,版本控制生成代码。
这等于:撕掉源码,版本控制编译后的二进制。
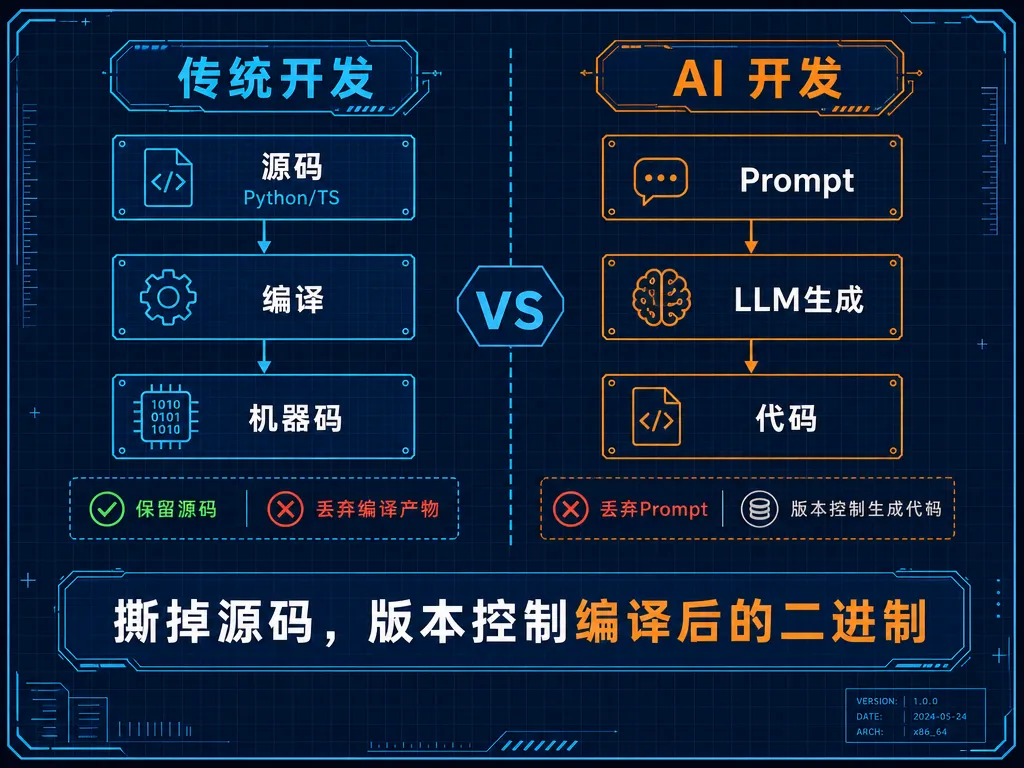
Prompt 是新的源代码
生成的代码只是原始规格的有损投影。Spec 包含意图、业务逻辑、代码无法捕捉的细微语义。Prompt 应以与源码同等的纪律被版本化保存——理想情况下,修改功能 = 修改 prompt = 重新生成代码 = 审查 diff。
四、Agent 工具设计与 CLAUDE.md
为 Agent 设计工具 ≠ 为人设计 API
| 合并函数 | ||
| 语义化输出 | user: "Jane Doe" 而非 user_id: "A1B2C3D4" | |
| 允许详细度控制 | ||
| 镜像生产环境 |
CLAUDE.md:投资回报最高的单项投入
本质上是"Agent 的长期项目记忆"。每次对话启动时自动加载为 system prompt 前缀。
应该包含:常用命令、架构概览、数据流和依赖、团队约定、安全的可执行命令清单。
应该避免:冗长的历史背景、可被代码推导的信息、过期的内容、过于宽泛的通用建议。
关键提醒:CLAUDE.md 的全部内容出现在每一次对话中。5000 token × 20 次对话 = 为同样信息支付 20 次 token 成本。
好的 CLAUDE.md 像执行手册而非文档——它告诉 Agent"在这个项目里怎么正确地干活",不是"这个项目是干什么的"。
Strategic vs YOLO:课程最反直觉的实验
同一个 prompt("构建一个 NFL 预测 App"),两种 Agent 配置:
- Strategic Agent
(紧护栏、每次操作需人类批准、详细多步计划)→ 失败。卡在爬取失效的 URL 上,每次等待审批无法自主尝试替代方案 - YOLO Agent
(少护栏、可执行任意指令、不生成详细计划)→ 成功。自动搜索替代数据源,切换方案,完成可用 App
核心洞察:最"可控"的配置不一定产出最好的结果。 Agent 的自治级别应该与任务的风险容忍度匹配:
低风险(个人原型、内部工具)→ 放宽约束,让 Agent 有更大灵活性去 pivot 高风险(生产数据库、支付系统)→ 紧护栏、人类审批、多重验证
正确的决策框架不是"多少护栏最好",是"这个任务失败的成本是什么"。
五、AI 安全:不是理论演示,是已经在发生的攻击
三种攻击链
- SSRF 内网探测
— 诱导 Agent 访问内网 IP,Agent 成为攻击者的跳板。本质:Agent 的"读取网页"工具是运行在可信网络内的 HTTP 客户端,没有内网访问控制 - 凭证窃取
— 将窃密脚本 Base64 编码绕过输出过滤,提取环境变量中的 API key。本质:Agent 有 shell 权限 + 可访问环境变量 - YOLO 模式逃逸(CVE-2025-3773)
— Prompt Injection → Agent 修改自己配置文件 → 禁用安全护栏 → 任意命令执行。本质:Agent 对配置文件的写权限 + 命令执行 = 持久化安全降级
共同特征:利用了 Agent 的"正常功能"作为攻击面。 安全漏洞来自功能的组合 + 缺少边界控制,没有哪个单独功能看起来是"漏洞"。
AI 安全扫描的可靠性——不能信任单次结果
Semgrep 在 11 个大型真实 Python Web 应用上测试:
| 86% | |||
| 82% |
更令人警醒的是非确定性:完全相同的扫描,不同时间运行三次,报告的 bug 数量分别是 3、6、11——3.7 倍差异。 问题不在于 AI 找不到漏洞——在于它找的东西中只有约 1/6 是真的,而且你无法仅凭单次扫描知道哪 1/6 是真的。
六、代码审查:找 bug 是最次要的目的
代码审查金字塔
| 心理对齐 | ||
| 验证方案正确性 | ||
| 设计讨论 | ||
| 找 bug | ||
| 风格检查 |
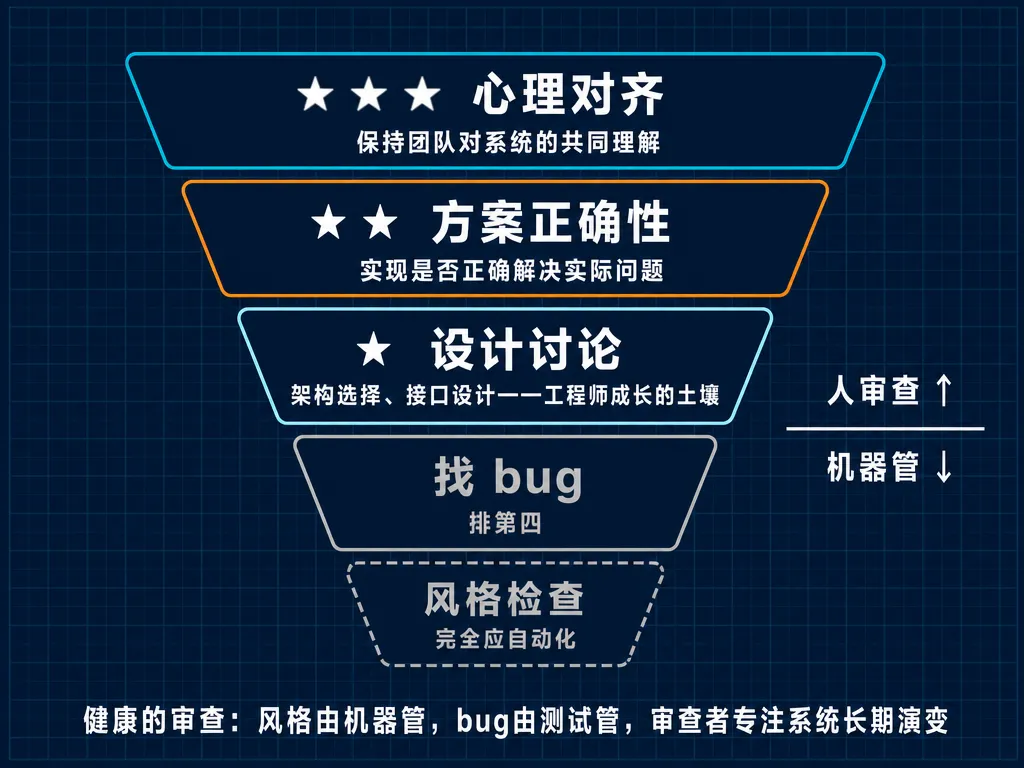
代码审查金字塔
如果审查只是为了找 bug,团队失去的是前三个更重要的价值。
很多团队的实际审查是"倒金字塔"——大多数评论在纠正格式和找简单 bug,很少有架构讨论。这恰恰说明审查流程没做好:如果风格检查占用大量时间→linter 配置不完善;如果 bug 是主要产出→缺少自动化测试。
健康的审查:风格由机器管,bug 由测试管,审查者专注于"这个方案对系统长期演变意味着什么"。
AI 审查四象限
| 应该压制,不是改善 |
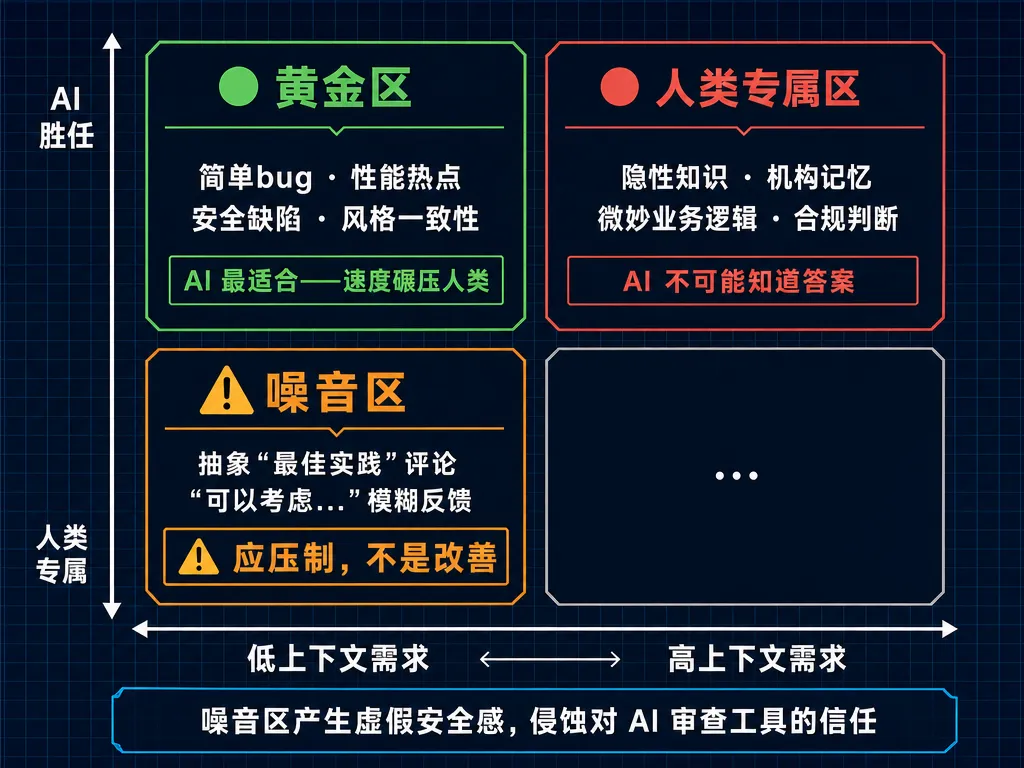
AI 审查四象限
七、UI 生成:LLM + 规则引擎的组合才是正解
专业化模型流水线(以 Vercel v0 为例)
① 意图理解 → ② 上下文组装(设计系统 token + API schema)→ ③ 代码生成 → ④ 自动验证(a11y, lint, bundle size, XSS)→ ⑤ 流拦截修正
第五步最关键:系统实时拦截输出的 token 流,动态检测并修复已知错误模式——在代码到达用户之前就已经修正了。 用户看到的是"修正后"的代码,不是 LLM 的原始输出。
被低估的模式:用 LLM 处理"创造性"部分(设计、意图理解),用规则引擎处理"正确性"部分(语法、无障碍、安全)。 最好的 AI 系统不是"更聪明的 LLM",是 LLM + 围绕它的工程基础设施。
历史复杂度税
每一代 Web 架构都在叠加新一层的必需知识:LAMP → MEAN → JAMstack → Serverless → ...。每一层都不是"可选"的,是进入生产环境所必需的。AI 生成消除了这个税——瓶颈从"你会不会做"转移到了"你知不知道要做什么、做了对不对"。
八、AI-Native 运维:从 SRE 到 Agent Ops
Google SRE 模型
50% 辛劳规则:SRE 必须将至少 50% 的时间花在工程工作上(自动化、工具建设),而不是手动运维。如果运维辛劳超过 50%,多余的部分推回给开发团队。深层逻辑:不自动化的运维工作不会自行消失——只会持续堆积。
错误预算:100% 可用性是错误的目标。SLO(如 99.9%)与实际完美之间的差距不是"缺陷"——是创新的预算。预算内可以承担风险、快速迭代。预算用完了,冻结发布,所有精力转向可靠性。不是惩罚,是可计算的风险管理。
AI-assisted vs AI-native
AI 生产工程师的工作流:Agent 构建系统动态知识图谱 → 生成针对本次事件的即时 runbook → 并行分析所有数据源(人类 SRE 只能顺序排查,Agent 可同时检查 10 个假设)→ 1 分钟内返回根因假设 + 修复路径。工程师的新角色:判断假设是否合理,决策是否执行修复——而不是手动翻日志。
九、未来:什么在消退,什么在增值
课程的唯一主线论点
"你不会被 AI 取代。你会被一个会用 AI 的合格工程师取代。"
从第一周到第十周,用不同角度反复论证这同一件事。
技能分化

技能分化
复合增长公式
能复合增长的工程师 = 能精确描述需求 × 能架构思考 × 能严格验证
这三项的投资不是"在学习 AI 工具"——它们是用好 AI 工具的前提。
课后随想
无论是半异步死区的论点、还是防御性 Prompting 四原则、Context Poisoning 问题,都让我再次系统性地梳理了对 Agent 的认识。是一篇非常适合初学者学习与实践的讲义。
(PS:这是一门2025年秋季课程,最早一批完整学习该课程并毕业的学生就是这个月)
这是一个"方法论"丛生的时代,是一个天马行空的时代
与时俱进是当下每个IT人,不可或缺的必要素养
