 夜雨聆风
夜雨聆风日常工作中,Excel 用来保存和传递数据非常常见。
但 Excel 与数据库之间的交互,很多时候并不友好。
原因也很简单:Excel 往往不是一张干净的数据表。
比如:
使用 VLOOKUP 或 XLOOKUP 时,有些内容没有匹配到,会得到 #N/A除数为 0 时,会出现 #DIV/0!公式中的数据类型不匹配时,会出现 #VALUE!公式引用了已删除或无效的单元格时,会出现 #REF!为了让报表更好看,表头上方经常会有标题、说明文字、合并单元格
这些内容在 Excel 里可能只是“不太好看”,但一旦导入数据库,就很容易导致异常,甚至直接导入失败。
所以很多时候,真正耗费时间的不是分析数据,而是在分析之前整理数据,先做一轮手工整理:
删除多余表头、处理合并单元格、清理异常值、另存为 CSV,然后再导入数据库。
这一步很烦,尤其是周期性报表。
格式基本固定,数据量也不大,但每周、每月都要重复处理一次。
最近几天在尝试 DuckDB 的 Excel 扩展。
最开始只是想看看它能不能直接读取 Excel 文件,结果用了几天之后发现:
它解决的并不仅仅是“读取 Excel”的问题。
更重要的是,它把 Excel 和数据库之间那层麻烦的中间步骤省掉了。
一个 read_xlsx() 函数,就可以比较轻松地应对指定 Sheet、指定区域、跳过无效表头、处理脏数据等常见问题。
对于一些固定格式、周期性生成的小数据量报表,甚至可以不用先入库。
直接读取 Excel,直接用 SQL 处理。
后续收到新的 Excel 文件时,只需要在脚本里改一下文件名,就能一键输出整理结果。
这个是使用过程中,觉得最舒服的地方。
本文就从基础安装、常用参数和几个实际场景出发,记录一下 DuckDB 在处理 Excel 文件时的一些使用技巧。
1. 安装和加载 Excel 扩展
注意:该方法只支持 .xlsx,不支持 **.xls**。如果是老式.xls文件,需要先另存为.xlsx。第一次安装并加载后,后续在编写脚本时,不用再写LOAD了,Duckdb会自动加载 当然,也可以在脚本前面加上 LOAD excel;
INSTALL excel;LOAD excel;2. 最简单的读取方式
很多时候只是想快速查看数据,DuckDB甚至不需要写read_xlsx: 适用于:Excel中只有一个sheet,或所需读取的sheet就是第一个,可以使用最简单的方式
SELECT * FROM'F:\测试中转数据\测试数据-20260608.xlsx'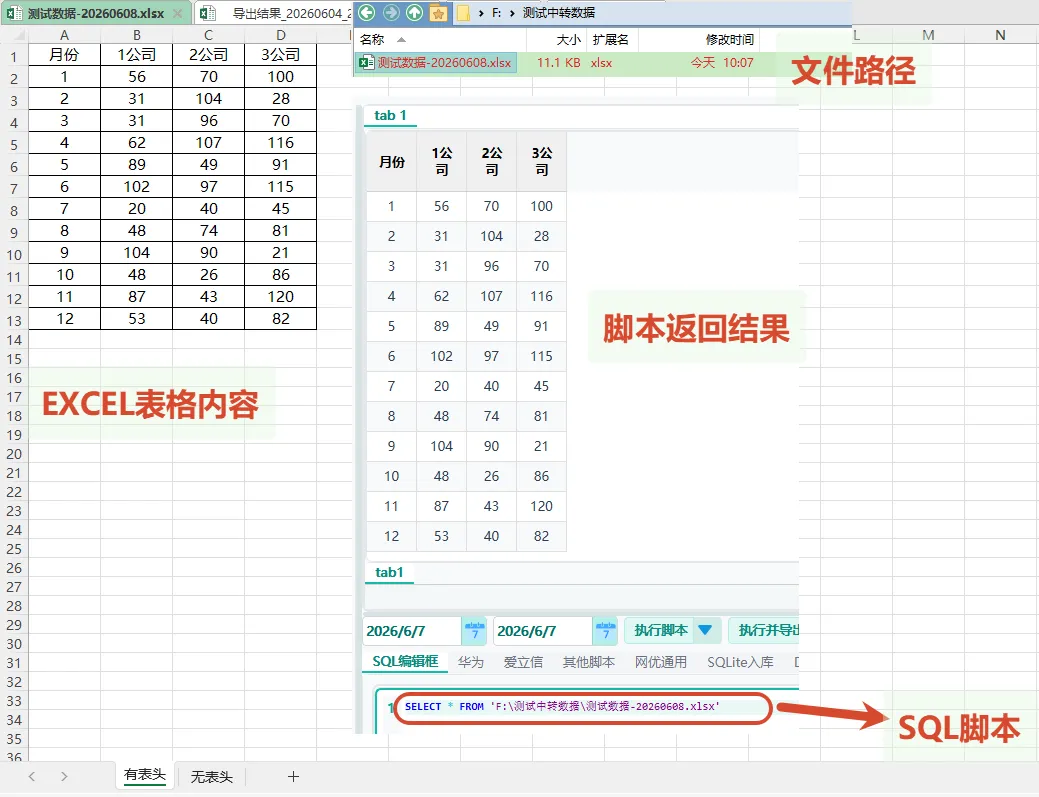
3. 推荐使用方法read_xlsx
read_xlsx是读取 Excel 内容时最常用、最可控的方法。它支持指定工作表、表头、读取范围、错误处理和类型控制。
--这个示例展示的是读取无表头数据时,如何指定表头SELECTA1 AS 月份,B1 AS'公司1',C1 AS'公司2',D1 AS'公司3'FROM read_xlsx('F:\测试中转数据\测试数据-20260608.xlsx', header = false, sheet = '无表头', all_varchar = true, ignore_errors = true);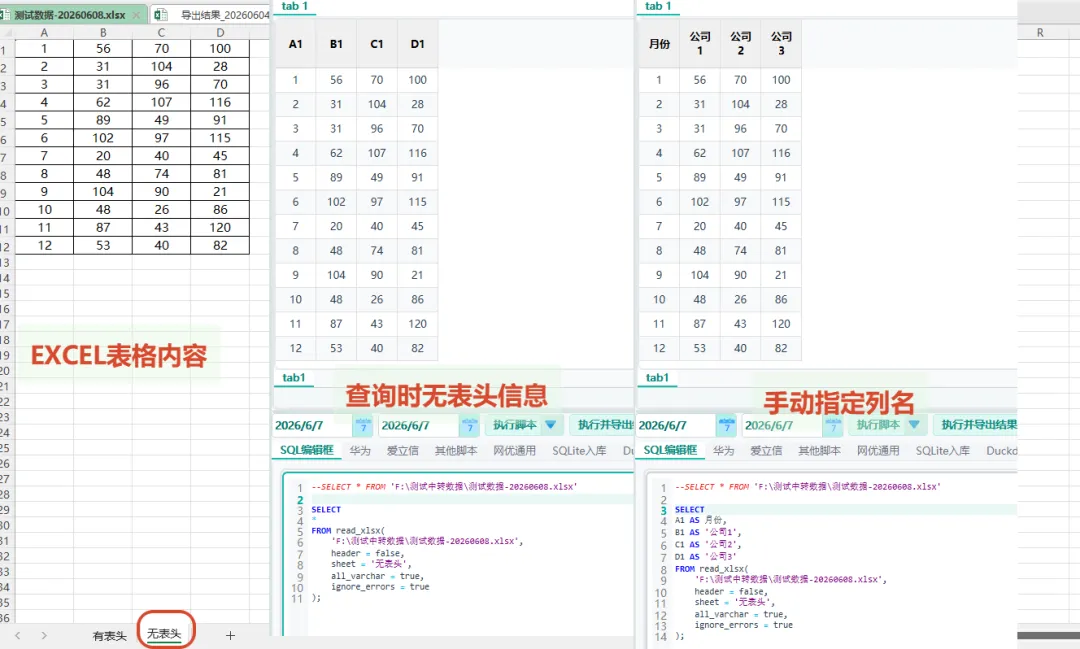
4. 常用场景
场景 1:读取指定 Sheet
适合一个 Excel 文件里有多个工作表的情况。
SELECT* FROM read_xlsx('F:\测试中转数据\测试数据-20260608.xlsx', header = true, sheet = '有表头');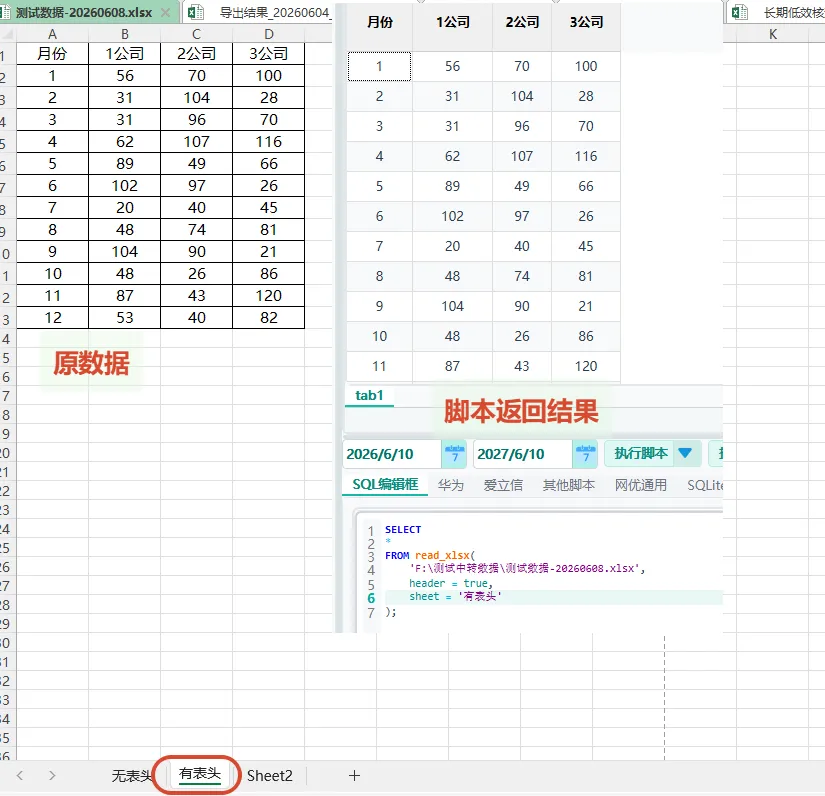
场景 2:只读取指定区域
工作中常常会遇到一些首行中有单元格合并,美化的表头,实际需求数据一般是从第二行或第三行开始 解决方法:指定一个大区域,可以让行数多一些,同时设置遇到空行自动停止,这样后续数据结构不变,行数增多了也不会报错,兼容性更好 适合 Excel 上方有标题、说明文字,或者只想读取某一块数据区域的情况。
SELECT * FROM read_xlsx('F:\测试中转数据\测试数据-20260608.xlsx',range = 'A3:D9999', header = true, sheet = '有表头', stop_at_empty = true);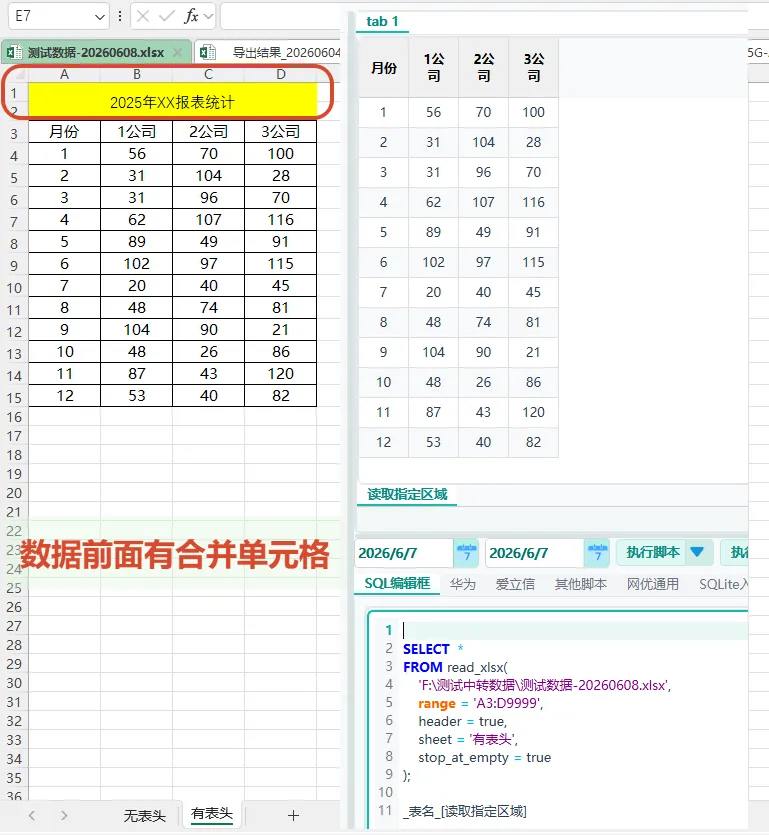
场景 3:全部按文本读取,避免类型推断错误
这个参数很实用。Excel 中经常会出现同一列既有数字、又有文本、又有空值的情况,直接推断类型可能出错。先全部读成文本,再用 SQL 转换类型,会更稳定。
SELECT * FROM read_xlsx('F:\测试中转数据\测试数据-20260608.xlsx',range = 'A3:D9999', header = true, sheet = '有表头', stop_at_empty = true, all_varchar = true);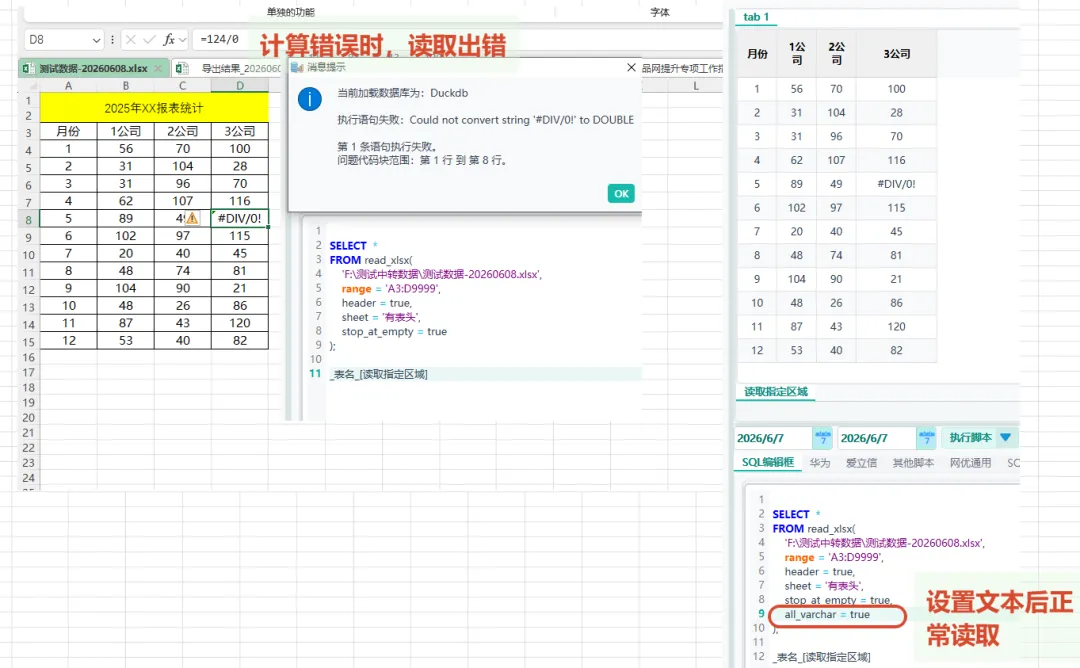
场景 4:忽略异常单元格
当某些单元格无法转换为推断出的列类型时, ignore_errors = true会把这些异常值替换为NULL,避免整个读取过程失败。一般设置了 all_varchar = true时,可以规避很多脏数据的影响了,遇到特殊情况,可以再加上ignore_errors = true,
SELECT * FROM read_xlsx('F:\测试中转数据\测试数据-20260608.xlsx',range = 'A3:D9999', header = true, sheet = '有表头', stop_at_empty = true, all_varchar = true, ignore_errors = true);5. 总结
read_xlsx 参数说明汇总
header | |||
sheet | |||
all_varchar | |||
ignore_errors | |||
range | A1:D100 | ||
stop_at_empty | |||
empty_as_varchar |
最常用参数是 header、sheet、range、all_varchar、ignore_errors。
其中 all_varchar = true 是处理复杂 Excel 文件时非常实用的稳定读取方式。
通过使用read_xlsx可以让Excel与数据库的交互更加方便优雅
最大的价值并不仅仅是 DuckDB 能读取 Excel。
而且还可以把那些每日、每周、每月等,重复整理 Excel 的工作,
变成一个可以复用执行的 SQL 流程。
