 夜雨聆风
夜雨聆风只有当AI嵌入到方案设计、EHR支持的匹配、患者参与、研究中心工作流程和治理中时,才能改善招募。最高价值的近期用例是那些具有记录的使用背景、验证、隐私控制和偏倚监测的人机协同决策支持应用。
**战略问题**
对于申办方、CRO和研究机构而言,临床开发的核心瓶颈已不再仅仅是是否存在足够的潜在受试者。而是试验的设计、启动和管理是否能够识别、接触、招募和留住合适的患者,同时不让研究中心不堪重负或侵蚀患者信任。
在大型EHR网络、受HIPAA监管的数据流、FDA对AI可信度的期望,以及扩大社区环境下试验参与度的巨大压力中,诸如方案复杂性、严格的入排标准、研究中心负担、患者理解、隐私、验证和人工监督等利益相关方主题同样重要。
已发布的基准数据说明了行业为何关注AI。一项系统综述指出,约80%的试验未能达到初始招募目标和时间表,导致代价高昂的后续延迟。
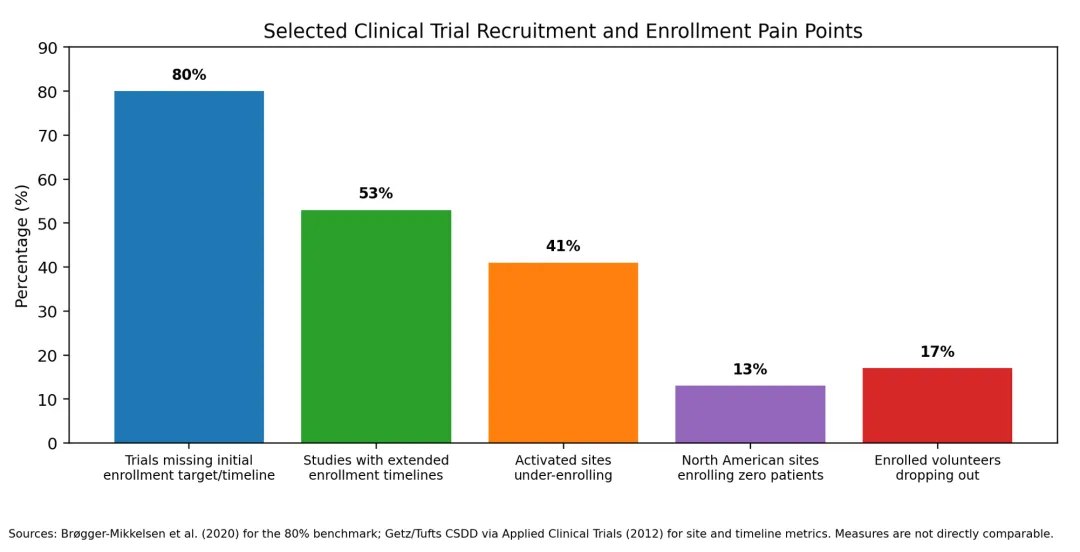
Tufts CSDD数据显示,53%的研究延长了招募时间线,41%启动的研究中心招募不足,约六分之一的入组志愿者在完成前退出。 这些统计指标并不完全相同,但它们共同指向一个一致的问题:招募是系统性失败,而非营销失败。只有能够改善这一系统,AI才有用武之地。
**1. 从方案设计开始,而非招募广告**
招募问题往往在首例患者筛选前数月就已埋下。精准肿瘤学、免疫学、罕见病和细胞治疗试验越来越多地结合生物标志物标准、既往治疗线数限制、洗脱期、实验室阈值、影像学计划和可选活检。
当研究中心收到方案时,协调员可能需要筛选数十份病历才能找到一名合格患者,而患者可能面临与工作、照护和出行现实相冲突的访视计划。AI驱动的可行性模型可以在方案定稿前对其进行压力测试。
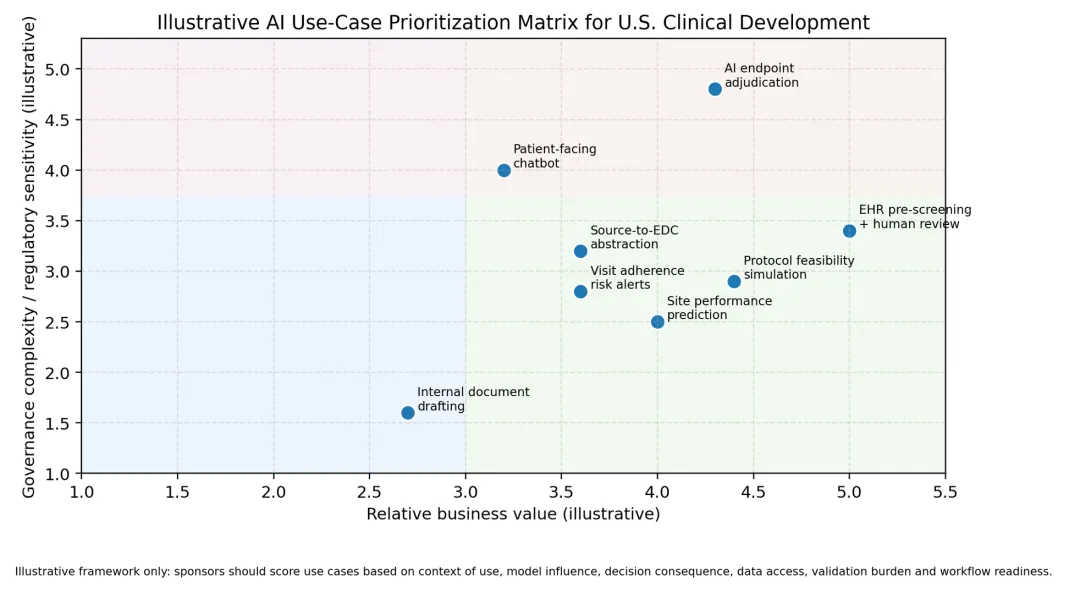
图2. 示例性AI用例优先级矩阵
自然语言处理(NLP)可以解析入排标准;机器学习模型可以将这些标准与去标识化的EHR、登记数据库和索赔衍生队列进行比较;模拟可以估算主要的筛选失败驱动因素、研究中心覆盖重叠情况和访视负担。例如,一项II期肺癌试验的申办方可以模拟ECOG评分、血红蛋白水平或既往治疗标准是否排除了临床上本来合适的患者,然后与医学、生物统计、监管和患者参与团队一起审查替代方案。
AI不应决定入排政策,但它可以及早暴露权衡取舍,从而避免可预防的修订。更高级的设计应用包括试验成功预测模型、终点选择和适应性监测。
针对临床试验设计的研究已经描述了AI在队列选择、患者分层、终点评估和运营规划方面的机会。³⁻⁵ 在实践中,对大多数组织而言,近期价值是务实的:减少可避免的复杂性,在投入研究中心前量化可行性,并围绕患者参与而非机构便利来设计访视。
**2. 使用EHR规模的患者匹配,但保持临床医生在闭环中**
最成熟的AI用例是患者-试验匹配。医疗系统拥有结构化数据,如诊断代码、药物和实验室检查结果,但大部分入排信号存在于非结构化的记录、病理报告、影像学印象和基因组学PDF中。NLP系统可以将这些非结构化内容转换为候选匹配项,并为授权的研究中心工作人员生成可筛选的清单。针对Watson for Clinical Trial Matching和Trial Eligibility Surveillance System等系统的研究证明了AI支持的入排审查的潜力,同时也强调了在具体背景下进行验证的必要性。⁶,⁷
商业和供应商的实例说明了市场方向。Deep 6 AI描述了使用AI和NLP处理EMR数据(包括临床记录、实验室和病理报告)以生成患者队列并与研究机构共享匹配结果。⁸
美国医院协会重点介绍了使用基于EHR的NLP进行招募和可行性分析的平台,包括在特定环境中报告更快识别速度和高准确性的实例。⁹ 这些实例应视为说明性而非普遍可推广的。
性能取决于数据质量、研究中心工作流程、治疗领域、本地记录习惯以及具体的入排标准。操作模型与算法同等重要。
一个合规的工作流程应定义谁可以访问可识别数据、何时允许重新识别、IRB批准如何构建、HIPAA授权或豁免如何适用,以及医生或协调员如何验证AI生成的匹配结果。AI生成的清单应作为决策支持,而非自动招募。
最终的入排资格、适宜性和患者接触决定必须由合格的临床和研究人员负责。
**3. 将匹配的患者转化为参与受试者**
找到候选者只是漏斗的顶部。许多试验在接触、预筛选、知情同意和前几次访视过程中流失患者。
AI可以通过个性化教育、简化访视说明、标记可能的依从性障碍以及生成供医学、法律和监管团队审查的通俗语言材料来支持转化。生成式AI可以为不同识字水平或语言起草版本,但每个面向患者的材料都需要人工审查、版本控制和IRB对齐。
保留是AI发挥运营重要性的领域。可穿戴设备、ePRO/eCOA工具、远程健康访视、智能提醒和基于风险的监测可以减少不必要的研究中心访视,并更早地发现依从性或安全性信号。
对于一项心血管结局试验,一个支持可穿戴设备的监测模型可能会标记需要协调员跟进的数据缺失模式或生理变化。对于一项皮肤科试验,图像采集和ePRO提醒可以减少出行负担。
其原则是以患者为中心的增强:AI应消除摩擦,而不是取代研究者和协调员所创造的共情与信任。
**4. 减轻研究中心负担并提高数据质量**
临床研究协调员通常是试验执行中隐藏的制约因素。他们筛选病历、安排访视、解释研究、核对源数据、录入EDC数据、回答质疑并维护文件夹。
AI支持的抽象提取、自动质疑分流、源数据到EDC的辅助、访视窗口预测和不良事件文本分类可以显著减少非临床工作量。这种减负可以重新分配给患者沟通和方案依从性;然而,缺乏可审计性的自动化会带来新的风险。
申办方应要求可追溯的数据谱系、源链接、置信度分数、异常处理、基于角色的访问、审计跟踪和记录在案的人工审查。如果AI工具总结了医生的笔记,协调员应该能够看到源短语。
如果一个模型建议了一个不良事件术语,药物警戒人员应该知道这是推荐、提取还是自主分类。AI必须在不妨碍问责制的前提下提高数据质量。
**5. 构建一个现成的治理模型**
监管方向比许多团队假设的更清晰。FDA 2025年关于药物和生物制品开发中AI的指南草案重点关注用于支持监管决策的AI输出,并强调基于风险的可信度框架。¹⁰
FDA和EMA 2026年的良好AI实践原则强调以人为本的设计、明确的使用背景、多学科专业知识、数据治理、性能评估、生命周期管理和清晰的基本信息。¹¹ FDA早期的讨论文件也认可了AI在非临床、临床、上市后和生产活动中的应用。¹²
对于生命科学公司而言,这意味着每个AI用例都应以使用背景为起点。模型将回答什么问题?它将影响什么决策?如果输出错误会发生什么?
一个对研究中心进行可行性排序的模型与一个决定给药后监测强度的模型具有不同的风险特征。风险应通过模型影响力和决策后果两者来评估。
高风险应用需要更强的验证、偏倚分析、锁定的规格、漂移监测以及尽早与监管机构沟通。数据治理同样关键。
在非代表性数据上训练的AI模型可能因遗漏记录不完整的患者、在社区环境中表现不佳或排除具有非标准护理模式的群体而加剧不平等。申办方应在适当且法律允许的情况下,按种族、民族、年龄、性别、地理位置、语言、保险状况以及研究中心类型评估性能。
隐私和安全控制必须在工作流程中设计好,而不是在供应商演示后添加。HIPAA、知情同意、IRB审查、GCP、21 CFR Part 11期望和网络安全要求在AI支持的试验中相互交叉。
**6. 经济性和数据伙伴关系决定AI是否可规模化**
AI的价值通过重新设计的伙伴关系实现,而不仅仅是仪表盘。大多数申办方并不直接控制招募所需的可识别患者数据,而医疗系统则拥有这些数据。
因此,可扩展的实施需要保护隐私的数据伙伴关系、清晰的重新识别规则、数据使用协议、适当情况下的联邦或通用数据模型方法,以及对缺乏大型信息学团队的社区研究中心的实际支持。
申办方的角色是定义科学和运营问题、资助工作流程并维护监管质量证据。提供方组织的角色是保护患者关系并管理接触。
供应商应提供模型文档、验证证据、可审计性以及对变更控制的支持。商业案例也应超越模型准确性。
领导者应跟踪周期时间和质量指标,例如:避免的方案修订次数、从方案概念到研究中心可行性决策的天数、每名合格预筛选者所需的病历审查数量、筛选失败率、首例患者入组时间、按研究中心类型划分的招募情况、协调员节省的小时数、质疑数量、访视依从性、脱落率以及入组受试者的代表性。这些指标将AI投资与项目经济和患者可及性联系起来。
它们还能阻止一种常见的失败模式:部署一个技术上令人印象深刻的模型,却给已经不堪重负的研究团队增加又一个登录、又一个工作流程和又一个负担。
**示例说明**
考虑一家中型生物技术公司计划在学术和社区肿瘤研究中心开展一项转移性非小细胞肺癌研究。一个方案可行性模型显示,一个限制性实验室阈值和一个强制性的现场活检是预计最大的筛选失败驱动因素。
团队修改了活检要求,允许进行一次远程安全性随访,并在治理文件中预先规定了理由。在启动阶段,一个NLP匹配工具扫描参与系统中的结构化EHR数据、肿瘤科医生笔记以及病理/基因组学报告。
该模型生成一个带有源证据的优先候选列表。CRC验证每个病例,治疗肿瘤科医生决定接触是否合适,患者收到IRB批准的通俗语言材料。
每月监测性能,包括假阳性、假阴性、种族/民族分布、年龄分布以及研究中心间的差异。关键不是AI取代研究中心,而是让研究中心的稀缺时间更高效。
**领导者现在应该做什么?**
高管应抵制两种极端:将AI作为独立技术解决方案购买,或在等待完美监管之后再行尝试。一个实用的12个月路线图从三到五个与可衡量瓶颈相关的用例开始,例如可行性周期时间、病历筛选小时数、筛选失败率、招募多样性、质疑数量或错过的访视。
建立一个AI治理委员会,成员包括临床运营、数据科学、生物统计、监管、法律、隐私、质量、药物警戒、患者参与和研究中心的代表。要求供应商提供验证证据、数据来源证明、审计功能、变更控制程序以及关于模型更新的合同明确性。
试点应优先采用人机协同的决策支持,而非自主决策。良好的起点包括方案可行性模拟、EHR预筛选加协调员验证、招募材料个性化加IRB审查、访视依从性预测以及自动化源数据提取。
随着信心的增长,组织可以转向适应性设计支持、数字生物标志物分析以及AI辅助的安全性监测,并在输出可能支持安全性、有效性或质量决策时与监管机构互动。项目组合领导者还应定义停止或重新设计试点的阈值。
如果一个EHR匹配模型给协调员带来太多假阳性,就不应仅仅因为它在回顾性验证中准确而进行扩展。如果一个聊天机器人提高了响应速度但增加了升级事件,则应缩小其范围。
如果一个可行性模型识别出代表性不足的社区,但方案仍然要求过多的出行,那么需要重新设计的是运营计划,而不是算法。将AI部署视为持续的临床运营学习。
最后,领导团队应以与招募、质量和安全性指标相同的治理节奏来报告AI试点,确保创新始终与试验执行相关,而不是分离成一个数字实验。
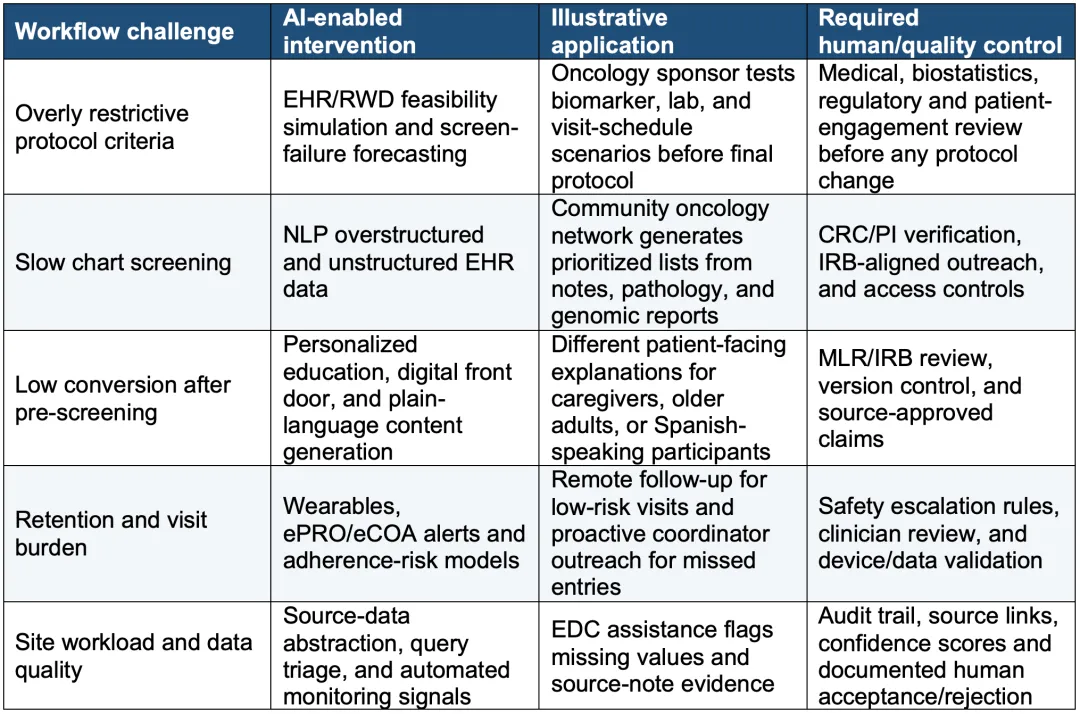
表1. 面向申办方、CRO和研究中心的AI支持的招募与设计用例
**结论**
AI不会拯救一个无法招募的方案,也不会补偿资源不足的研究中心。然而,它可以更早地暴露设计缺陷、更快地识别合格患者、减轻协调员负担、个性化参与互动,并建立一个更具证据基础的招募与保留运营模型。
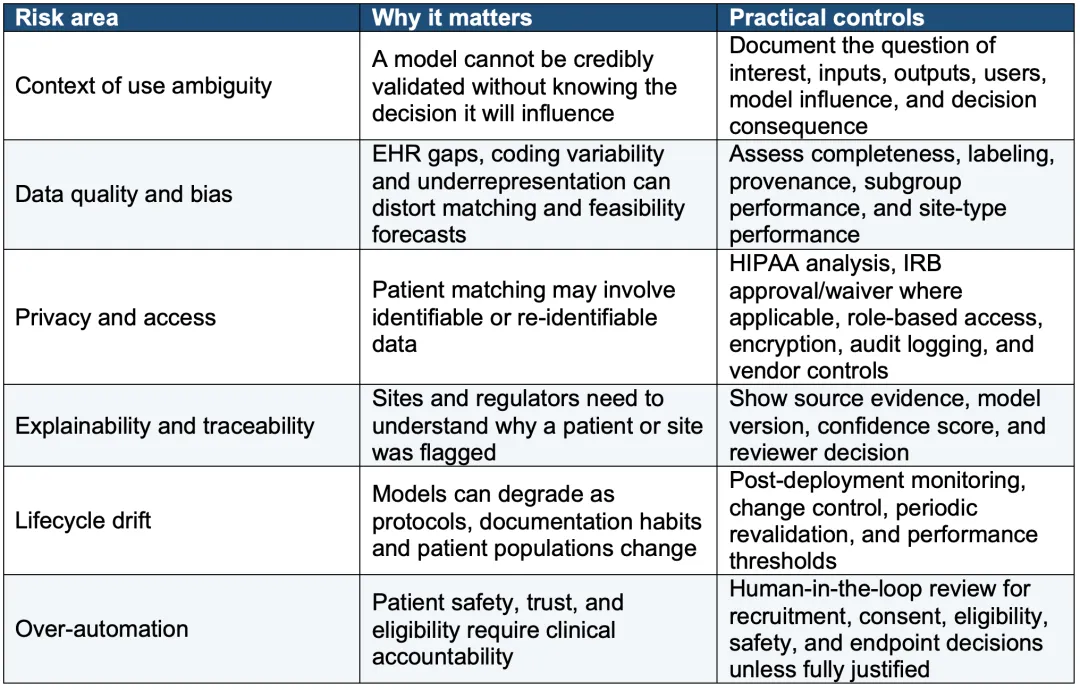
表2. AI支持的临床试验操作的风险控制检查表
临床开发中的赢家将是那些将AI视为一种受监管的、以人为本的能力的组织:在临床上实用、在运营上嵌入、保护隐私、经过偏倚测试,并且足够透明以赢得患者、研究机构和监管机构的信任
