 夜雨聆风
夜雨聆风
不同于传统蛋白质 AI 模型将蛋白质简化为骨架或序列问题,Pallatom™ 从全原子坐标出发,将主链、侧链、界面 packing、氢键、疏水作用、手性与局部化学环境纳入统一建模框架。从 Pallatom™ V1 到 Pallatom™ V2,再到面向Agent驱动蛋白质设计的 Pallatom™-Lévin™,可以清晰看到力文所正在沿着一条更接近药物发现本质的技术路线持续推进。
Part1: “全原子 AI 蛋白质设计”领军企业

1、全原子生成的范式突破|Pallatom™ V1
主流蛋白质生成模型多采用“先骨架、后序列”的二阶段流程:第一步生成蛋白质主链骨架,第二步再调用序列设计模型为骨架匹配氨基酸序列,最后再进行结构预测与验证。这一流程虽然推动了de novo蛋白质设计的发展,但也天然存在信息割裂:骨架生成时没有充分考虑侧链,序列设计时又无法完整回到生成阶段修正三维构象。
Pallatom™ V1 的突破在于,它直接从全原子结构出发进行端到端生成,将蛋白质的主链、侧链与序列信息放入同一个模型框架中共同求解。通过 ATOM14 等原子表示方式,Pallatom™ 将“序列的离散性”与“坐标的连续性”统一到可学习的生成过程中,使蛋白质设计不再停留在骨架近似,而是进入真正的原子级建模阶段。
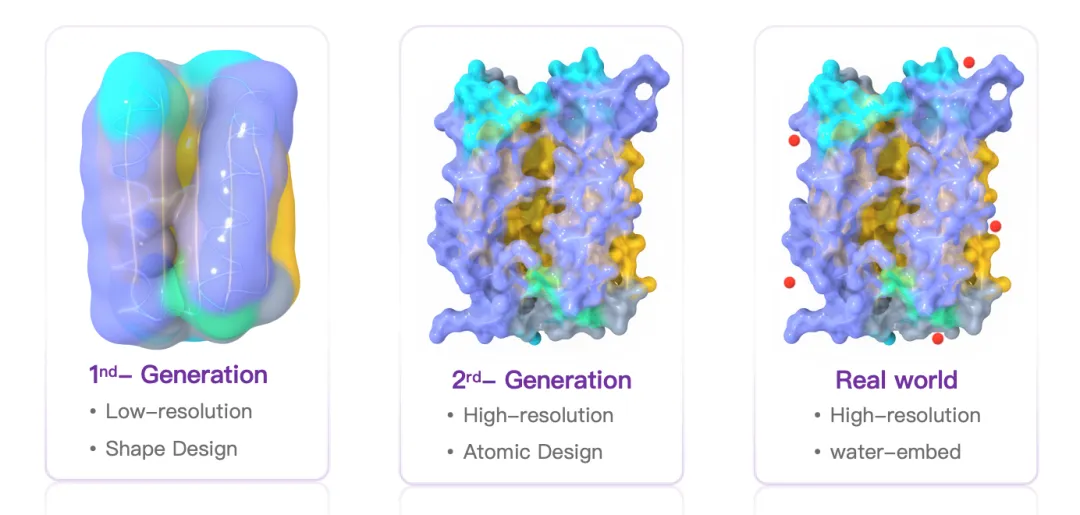
这一代模型的意义,是为 AI 蛋白质设计建立了新的底层语言:蛋白质不再只是氨基酸序列或主链形状,而是由每一个原子及其相互作用共同构成的可设计系统。Pallatom™ V1 不仅是行业的首创突破者,也被英伟达列为蛋白质世界四大基础模型之一,在国际顶级深度学习会议上被广泛报道。

2、从结构生成到功能分子设计|Pallatom™ V2
如果说 Pallatom™ V1 证明了全原子生成的可行性,那么 Pallatom™V2 则进一步把这一能力推向药物发现中的高价值任务:设计能结合靶点、调控功能、具备实验可验证性的全新分子。
在 Pallatom™ V2 中,全原子生成不再只是生成一个稳定折叠的蛋白结构,而是开始面向功能约束进行设计。模型需要同时考虑靶标界面、关键结合位点、侧链取向、局部相互作用、亲和力、特异性与稳定性等多重条件。这使 Pallatom™V2 能够进入 binder 设计、环肽设计、复杂蛋白互作设计等更接近药物开发的问题域。
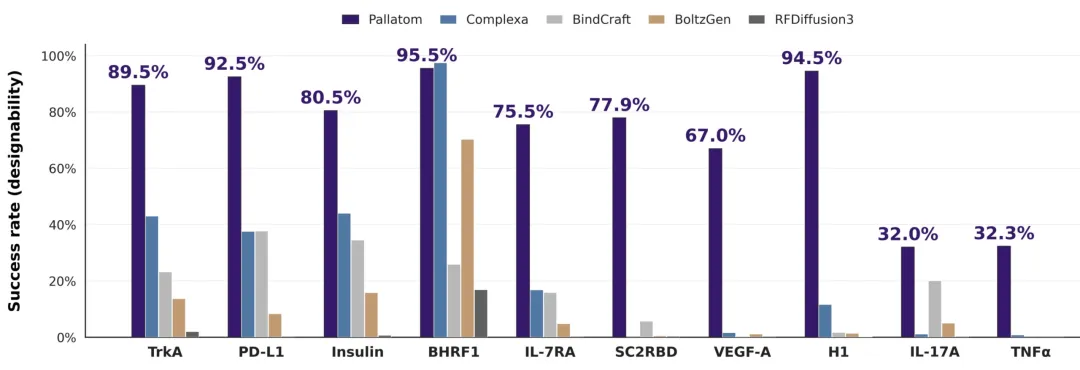
Pallatom™ 在多药物靶点上的实验binder成功率测试
全靶点 binder 设计——从“单点炫技”到“系统性命中”:在覆盖 TrkA、PD-L1、Insulin、BHRF1、IL-7RA、SC2RBD、VEGF-A、H1、IL-17A、TNFα 等多个药物相关靶点的实验 binder 成功率测试中,Pallatom™ 在多数靶点上取得显著领先表现。以实验 binder 成功率衡量,Pallatom™ V2 在 TrkA、PD-L1、BHRF1、H1 等靶点上达到接近或超过 90% 的设计成功率,在更复杂、更难设计的 IL-17A、TNFα 等靶点上也保持有效命中,显示出跨靶点泛化能力和稳定输出能力。
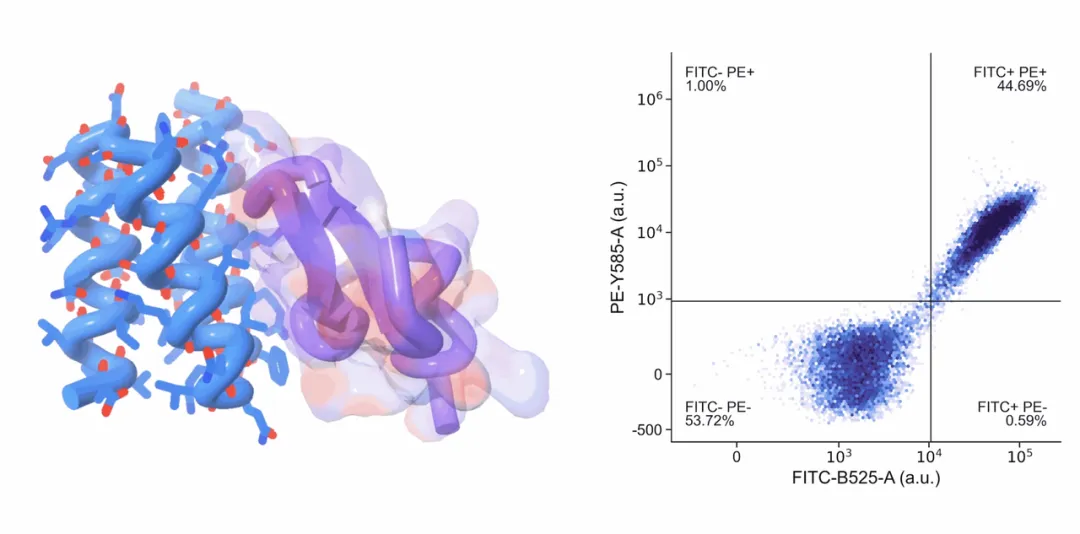
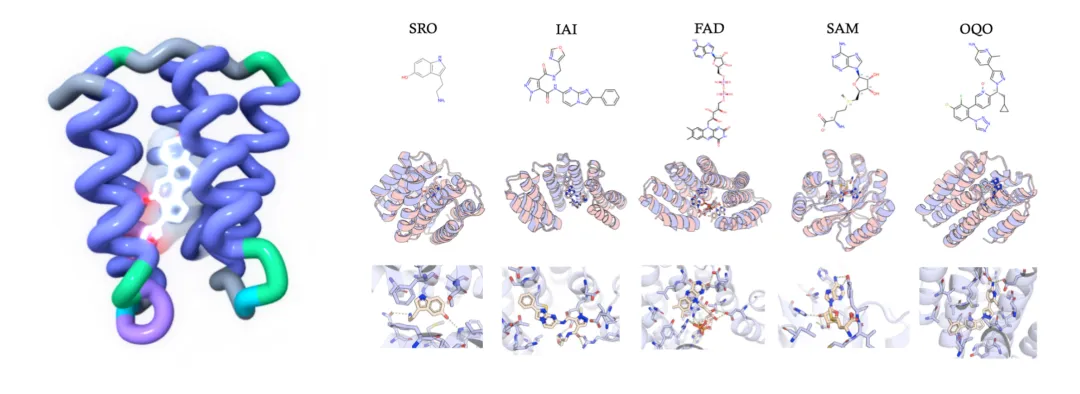
蛋白-小分子相互作用的原子级设计|Pallatom™-Ligand
在药物发现中,蛋白质与小分子之间的相互作用是最核心、也最精细的分子事件之一。传统方法往往先设计蛋白骨架,再尝试让侧链适配小分子配体;但配体结合口袋的形成高度依赖侧链构象、局部氢键网络、疏水作用与空间互补性,任何微小的原子级错配都可能导致结合失败。
Pallatom™-Ligand 正是为了解决这一问题而诞生。它将蛋白质和小分子配体放入统一的全原子扩散框架中,直接学习蛋白-配体复合物中所有原子的联合分布,让蛋白在生成过程中就围绕小分子的柔性构象形成匹配口袋,不只是“为已有蛋白找小分子”,而是进一步走向“为目标小分子设计蛋白环境”。对于酶设计、配体结合蛋白、药物递送、分子识别工具以及新型功能蛋白开发而言,这一能力打开了更大的设计空间。
Part2 打破“PPT造药”的工具化魔咒
AI 蛋白质设计的价值,最终不取决于模型能生成多少漂亮结构图,而取决于这些设计能否进入实验、形成命中、交付合作,并在真实任务中打破传统方法的效率边界。力文所正在通过“合作开发 + 模型实测 + 自研应用”的多线验证,把 Pallatom™ 系列从算法模型推进到药物发现和合成生物学的真实问题中。
1、药物发现:全药物靶点 binder 设计成功率领先
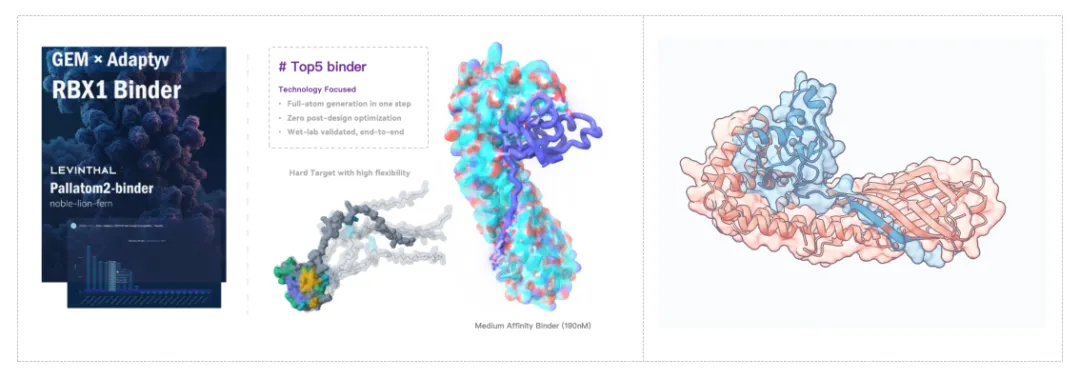
RBX1 Binder 竞赛——零后优化输出功能性 binder:在 GEM × Adaptyv RBX1 Binder Design Competition 中,力文所团队使用 Pallatom™V2-binder 模型,在不进行 ProteinMPNN 序列重设计、不进行 Rosetta 能量最小化的情况下,直接以模型原生输出获得可实验验证的 binder,取得全球前五、国内唯一的成绩。这一结果说明,Pallatom™V2 已经具备从结构生成跨越到功能性候选分子输出的能力。
2、合作开发:全球首个全原子生成类药性寡聚体设计
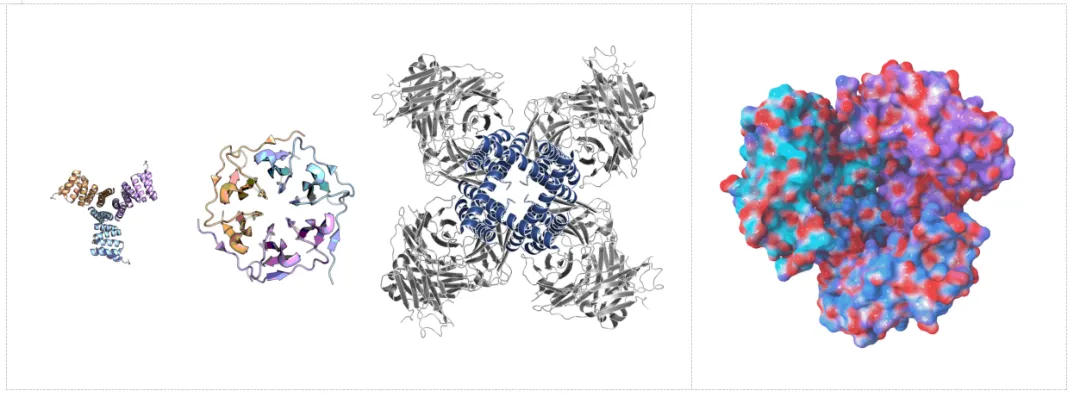
类药性寡聚体从头设计:在创新大分子底层设计合作中,力文所依托 Pallatom™ V2 全原子扩散生成模型,完成全球首个全原子生成类药性寡聚体设计的首批阶段性交付。候选分子在组装构象、热稳定性及成药性相关指标上展现出潜力,验证了 Pallatom™ V2 在复杂多链分子系统中的全局几何控制、侧链堆积和药物属性协同设计能力。
这类分子设计的难点在于:寡聚体不仅要求单个蛋白单元稳定折叠,还要求多链之间在对称性、界面 packing、溶解性、均一性和成药性之间同时达成平衡。全原子生成方式,使模型能够在生成初期就把多链组装和局部原子相互作用纳入同一框架,为复杂大分子药物设计提供新的技术路径。
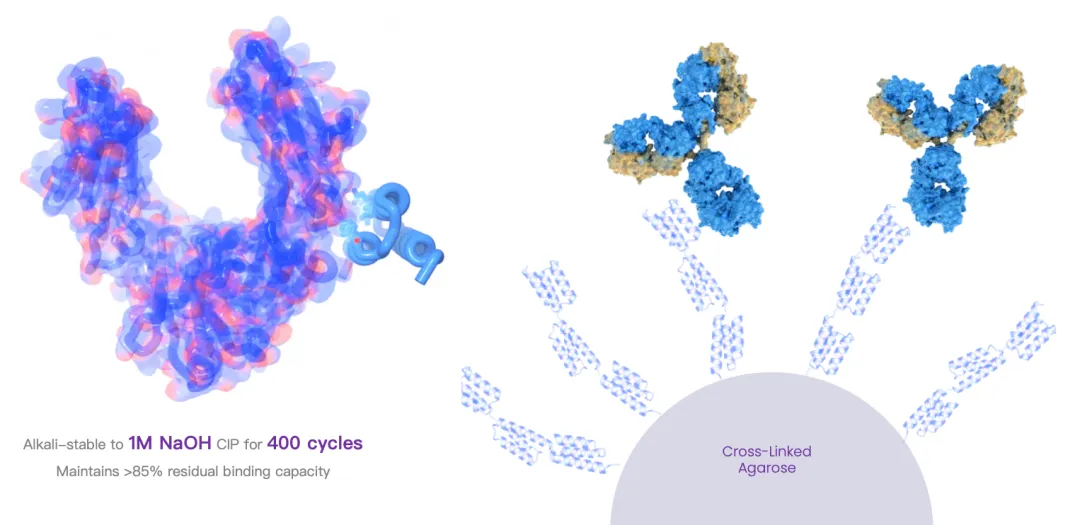
3、亲和配基:世界首个 de novo Protein A 高耐碱分子
Protein A 替代分子——从天然配基到 AI 设计配基:在抗体纯化这一生物制药核心场景中,力文所基于自研全原子设计能力,设计出世界首个 de novo Protein A 高耐碱分子。该分子面向抗体亲和纯化中长期存在的耐碱清洗、结合稳定性和国产替代需求,以全新序列和结构探索 Protein A 功能的 AI 设计路径。
相较于对天然蛋白进行局部改造,de novo Protein A 的意义在于从头设计一个兼具结合能力、稳定性和工艺适配潜力的新分子。这不仅验证了 Pallatom™ 在蛋白-抗体界面识别中的设计能力,也为抗体药物上游关键材料提供了新的分子设计范式,在实际测试中,耐碱性能达到国际主流产品的2倍以上。
4、合成生物学:从序列优化走向功能蛋白质设计
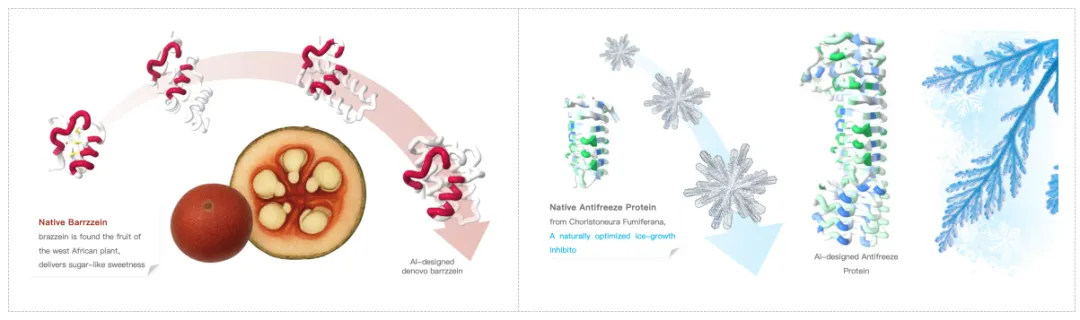
功能蛋白与工具酶设计——让 AI 设计走出单一药物靶点:除药物发现外,力文所也在合成生物学与功能蛋白开发中持续验证平台能力。依托Pallatom™ V2 相关技术,公司已在工业酶、甜味蛋白、抗冻蛋白、抗体工具酶等方向形成多类功能蛋白质设计与改造案例,用于提升稳定性、表达水平、底物识别能力与功能表现。
这一类应用的共同价值在于:AI 不只是替代传统筛选,而是将自然进化中的序列经验、结构约束和物理相互作用重新组织为可设计空间。从药物 binder 到功能蛋白,从配体结合到工具酶改造,Pallatom™ 系列正在证明同一套全原子设计能力可以跨越不同蛋白模态复用。
例如,在甜味蛋白、抗冻蛋白等场景中,设计目标往往不是简单提高某一个打分,而是在稳定性、表达、功能位点、环境耐受和应用成本之间做多目标平衡。这类问题天然适合全原子模型发挥作用:模型既要理解局部残基替换带来的微小相互作用变化,也要保证整体结构和功能输出不会被破坏。
Part3 从模型到系统的转型
Pallatom™-Lévin™ 让 AI 蛋白质设计进入 Agent 闭环
从 Pallatom™ V1 到 Pallatom™ V2再到Agent全面接管蛋白质设计流程,力文所的技术路线不是简单做模型版本升级,而是在持续推进一个更底层的命题:让 AI 真正以原子为单位理解和设计蛋白质功能。
这条路线的终点,不是一个单点模型,而是一套面向 AI 药物发现的全原子设计基础设施:输入目标功能,输出可验证候选;输入分子约束,生成匹配的蛋白环境;输入复杂药物模态,探索自然界未曾给出的原子排列。
Pallatom™-Lévin™以 Agent 方式组织 Pallatom™ 系列模型与结构分析工具:用户给出目标功能、靶点结构或分子约束后,系统可以围绕任务自动规划设计路径,生成多轮候选,并根据结构合理性、界面互补性、局部相互作用和可实验性指标进行筛选与反馈。它的关键不只是“生成更多分子”,而是让每一轮生成都能带着上一轮的证据继续前进。
以上,力文所的一整套方案使 AI 蛋白质设计更接近真实研发。
这并非一张漂亮结构图,也不是一个孤立分数,而是一个能够把设计、评估、解释和复盘串起来的闭环。对于药物发现团队而言,这意味着更短的候选探索周期、更清晰的失败归因,以及更容易沉淀为组织能力的设计流程。
力文所扎进的原子尺度的底层命题,是让模型真正理解每一个原子的排布、每一次氢键的形成、每一对相互作用的平衡。
从Pallatom™ V1到Pallatom™-Lévin™,这家藏身杭州的公司,用自己的全原子生成模型,在药物发现、合成生物学、亲和配基等真实战场中不断打出“国内唯一”“全球首创”的实绩。
技术路线清晰、实验验证扎实、商业化落地可见——它不只是一家被资本看好的公司,更可能成为定义AI蛋白质设计下一个十年的关键力量。
「错过杭州力文所,错过的不是一家AI4S公司,而是一整个以原子为单位重新编写生命功能的时代。」
拓展阅读,关注杭州更多小而美初创公司:
