 夜雨聆风
夜雨聆风当 AI Agent 从"能写代码"走向"能管理写代码的 AI",中间需要怎样的架构?本文从源码层面深度拆解 Everything Claude Code(ECC)的设计哲学与工程实现。
一、引言:为什么需要一个"Agent 的操作系统"
2025 年,AI 编码工具百花齐放——Claude Code、Cursor、Codex、OpenCode、Gemini CLI、Zed……每一款都有自己的指令格式、生命周期事件和工具权限模型。开发者面临的困境是:同一个工作流,在每个工具里都要重写一遍。
ECC(Everything Claude Code)试图解决的问题正是这个。它不是一个 IDE,也不是一个 LLM,而是一个 "harness-native operator system"——AI 编码代理的操作协议层。在它的仓库里,你可以找到 64 个专业代理、261 个技能包、84 个命令、一套完整的事件驱动 Hook 系统,以及一个用 Rust 编写的多代理控制面板。
截至 2026 年 6 月,这个项目已经积累了 211.9K Star、32.5K Fork 和 230+ 贡献者。但比数字更值得关注的,是它在 Agent 架构层面做出的那些设计决策。
本文将从源码出发,完整拆解 ECC 的 Agent 架构。
二、ECC 的五层架构
ECC 2.0 的参考架构定义了一个清晰的五层栈。这不是文档里画的漂亮方框,而是从 ecc2/ 的 Rust 代码、docs/architecture/ 的设计文档和数百个实际文件里可以一一验证的分层。
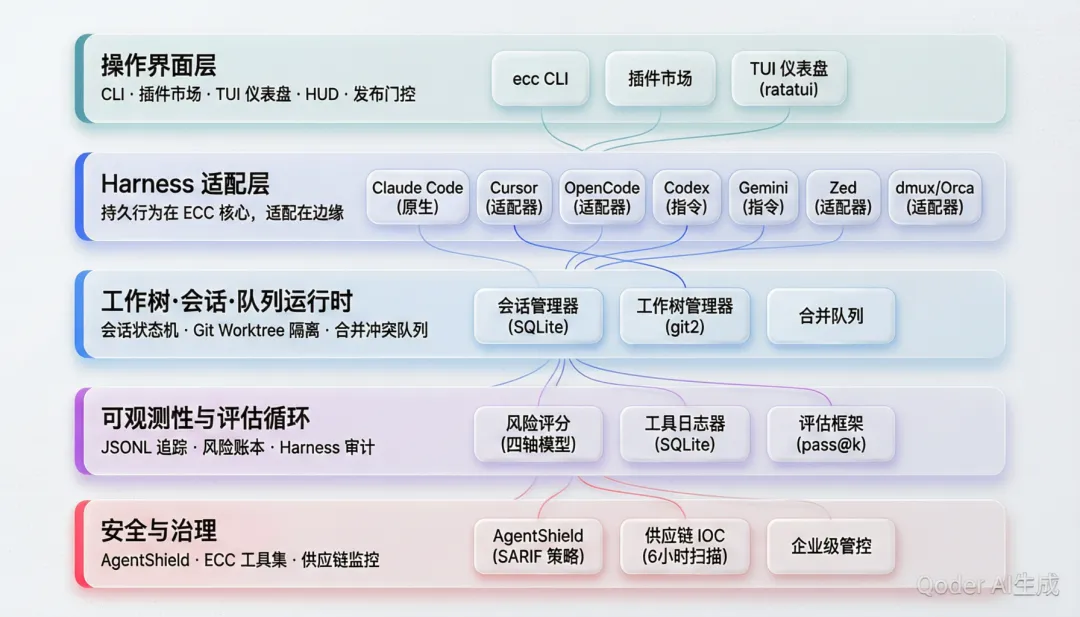
每一层的设计都有明确的职责边界。其中最具架构意义的是第四层——Harness Adapter Layer。ECC 的核心原则是 "Durable Behavior in ECC, Adaptation at the Edge"(持久行为在核心,适配在边缘)。SKILL.md 是最小可移植单元,各工具特定的目录(.cursor/、.codex/、.opencode/ 等)只是共享资产在不同运行时上的投影。
从 scripts/lib/harness-adapter-compliance.js 的源码可以看到,ECC 为每个 Harness 定义了四种合规状态:Native(完全原生)、Adapter-backed(有适配器但功能差异)、Instruction-backed(仅提供指导文件)、Reference-only(仅作为设计参照)。这不是文档里的分类,而是代码中冻结的 adapter record:
// 源码: harness-adapter-compliance.js{ id: "claude-code", state: "native", supportedAssets: ["skills", "rules", "hooks", "commands", "agents", "mcp"], unsupportedSurfaces: [], installCommand: "node scripts/install-apply.js --target claude", verifyCommand: "npm run harness:audit"},{ id: "cursor", state: "adapter-backed", supportedAssets: ["skills", "rules", "hooks", "commands"], unsupportedSurfaces: ["native-agents", "native-mcp"], // ...}三、Agent 定义:不只是 Prompt,而是合约
ECC 中的每个 Agent 都是一个 Markdown 文件(agents/*.md),带有 YAML frontmatter。但如果你认为它只是一段 Prompt,那就低估了这个设计的精密程度。
以 agents/planner.md 为例,它的 frontmatter 包含四个关键字段:
name: plannerdescription: Expert planning specialist for complex features and refactoring. Use PROACTIVELY when users request feature implementation...tools: ["Read", "Grep", "Glob"]model: opus3.1 工具隔离作为安全边界
这里的 tools 字段不是"建议",而是硬性的权限隔离。planner 只有 Read、Grep、Glob——它物理上无法写代码。这不是 Prompt 层面的约束,而是 Claude Code 运行时层面的工具权限控制。
整个 Agent 系统遵循一个一致的设计模式:
| 可以修复 | |||
注意 build-error-resolver 有一个显式的 "When NOT to Use" 段落,指名道姓地把相邻关切路由给其他 Agent:代码需要重构→refactor-cleaner,架构变更→architect,新功能→planner,测试失败→tdd-guide。这是一种显式委派边界——每个 Agent 都知道自己不该做什么。
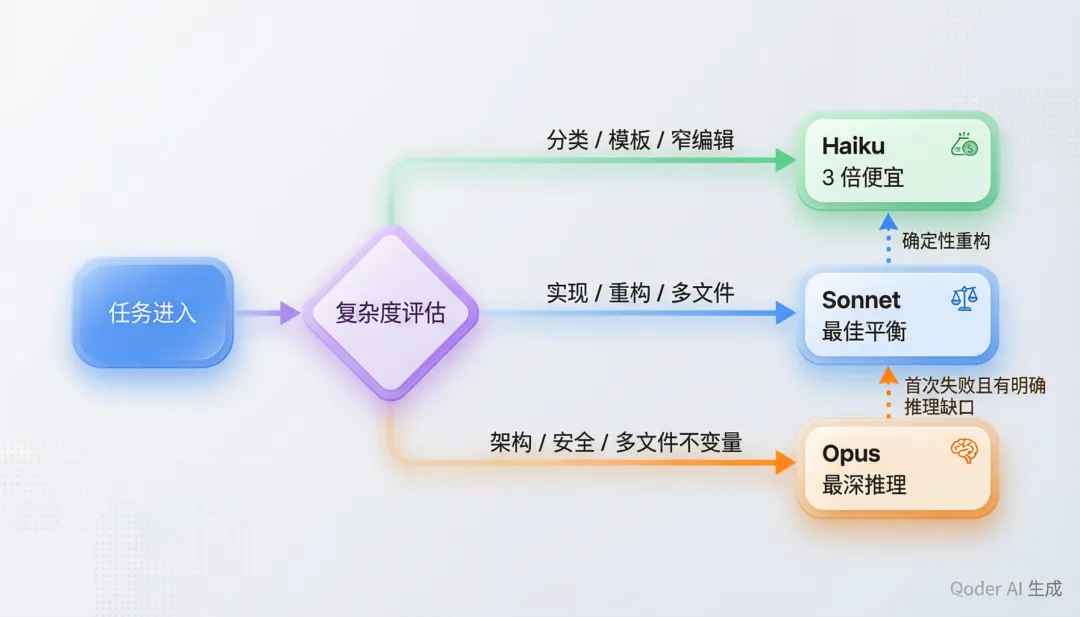
3.2 模型层级路由
model 字段实现了成本感知的模型路由策略:
- Opus(最贵、最强):架构决策、安全审查、复杂规划
- Sonnet(平衡):代码实现、评审、日常开发
- Haiku(最便宜):分类、简单编辑、文档查询
从 the-longform-guide.md 的源码可以看到一个清晰的升级策略:默认使用 Sonnet(60% 成本降低),仅在以下条件升级到 Opus——首次尝试失败、任务跨越 5+ 文件、架构决策、安全关键代码。
四、编排引擎:从手动路由到自动委派
4.1 主动路由哲学
ECC 的编排哲学可以用一句话概括:"Use agents proactively without user prompt"(主动使用代理,无需用户提示)。
AGENTS.md 中的路由表为每个 Agent 定义了精确的触发条件。当你写完一段代码,code-reviewer 会自动被调用;当构建失败,build-error-resolver 会主动介入;当涉及架构决策,architect 会被路由。这不是靠 Prompt 里的 "if...then" 实现的——它依赖 Claude Code 的 Agent 调度机制,结合 AGENTS.md 中的路由表和各 Harness 的 Agent 调用能力。
4.2 五阶段顺序编排
从源码中的 the-longform-guide.md 可以看到一个标准的顺序编排模式:
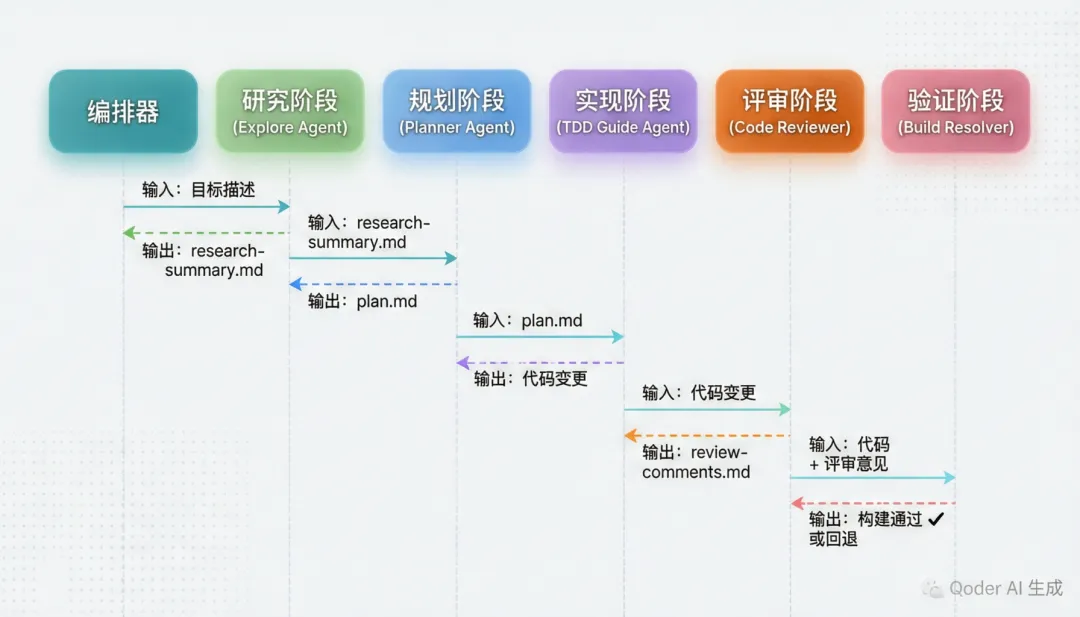
每条规则都很关键:
- 每个 Agent 接收一个清晰的输入,产出一个清晰的输出
- 产出成为下一阶段的输入(通过文件传递,不是对话上下文)
- 永远不跳过阶段
- 中间产出存储在文件中(存活于压缩之外)
4.3 子代理的上下文问题
源码中有一段非常坦诚的讨论,叫 "The Sub-Agent Context Problem":子代理存在的意义是通过返回摘要而非倾倒所有内容来节省上下文。但编排器拥有子代理缺少的语义上下文。
ECC 的解决方案是迭代检索模式:编排器评估子代理的每次返回,在最多 3 个循环内提出追问。关键原则是:传递目标上下文,而非仅传递查询。
五、Hook 管线:事件驱动的质量执行
如果说 Agent 定义是"做什么",那么 Hook 系统就是"怎么保证做到"。这是 ECC 架构中最精巧的部分之一。
5.1 事件模型
ECC 的 hooks/hooks.json定义了一张完整的事件驱动管线。从源码来看,Hook 覆盖了 Agent 生命周期的每一个关键节点:
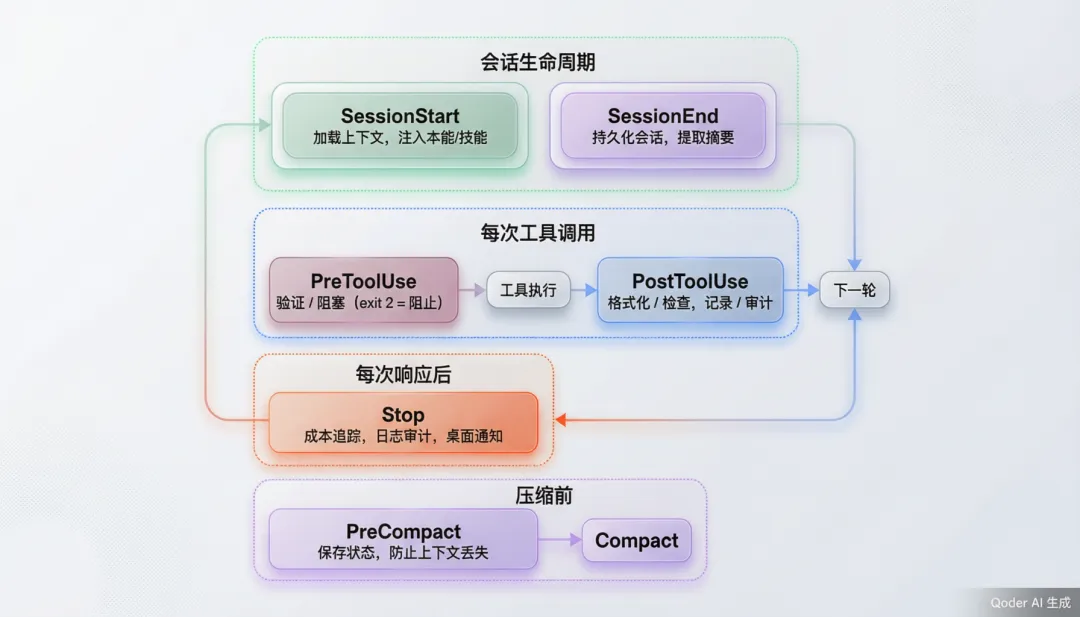
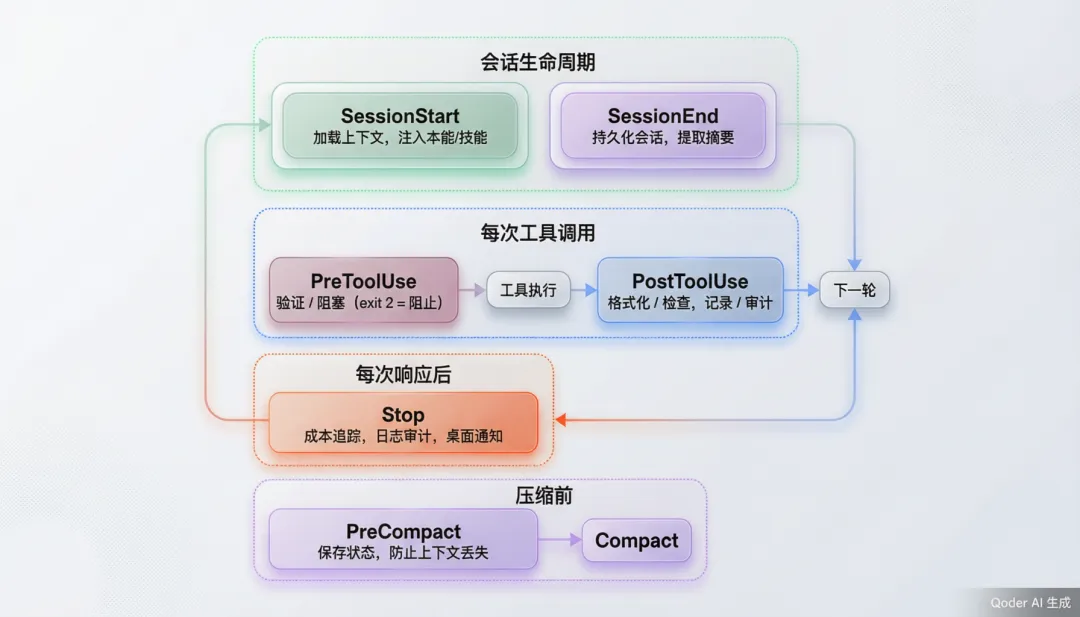
5.2 运行时控制:三级配置文件
从 scripts/hooks/ 的源码可以看到,Hook 系统通过环境变量实现运行时控制:
ECC_HOOK_PROFILE:三级配置文件——minimal(仅安全关键)<standard(常规质量检查)<strict(最严格,包含 tmux 提醒和 git push 审查)
ECC_DISABLED_HOOKS:逗号分隔的 Hook ID 禁用列表
ECC_SESSION_START_MAX_CHARS:SessionStart 注入上下文的上限(默认 8000 字符)
每个 Hook 通过 run-with-flags.js 包装器运行,这个包装器检查当前 profile 和 disabled 列表,决定 Hook 是否执行。
5.3 GateGuard:事实强制而非确认提示
gateguard-fact-force.js 是 ECC 中最有设计哲学深度的 Hook。它不问"你确定吗?"——它要求 Agent 提供具体事实才能继续操作:
编辑门控:必须列出该文件的导入者、受影响的公共 API、数据 Schema、引用用户指令 写入门控:必须列出调用文件、确认无重复用途 破坏性 Bash 门控:必须列出受影响的文件/数据、回滚程序
其破坏性命令检测的实现极其精密:先剥离引号字符串(防止 commit 消息中的 "drop table" 触发误报),然后递归展开子 shell($(...)、反引号),最后对每个命令段进行命令特定的分析。git push --force 被拦截,但 --force-with-lease 被放行——这个细节体现了工程判断。
5.4 MCP 健康检查
mcp-health-check.js 实现了一个完整的双事件 MCP 健康探测系统:在 PreToolUse 阶段探测服务器健康(HTTP 服务器通过 GET 请求,stdio 服务器通过启动进程并等待),在 PostToolUseFailure 阶段处理失败并尝试重连。健康状态持久化到 ~/.claude/mcp-health-cache.json,带有指数退避(基础 30 秒,最大 10 分钟)。
六、六种自治循环模式
ECC 的 skills/autonomous-loops/ 和 skills/continuous-agent-loop/ 定义了六种从简单到复杂的自治 Agent 循环模式。这是整个项目中最具工程创新性的部分。
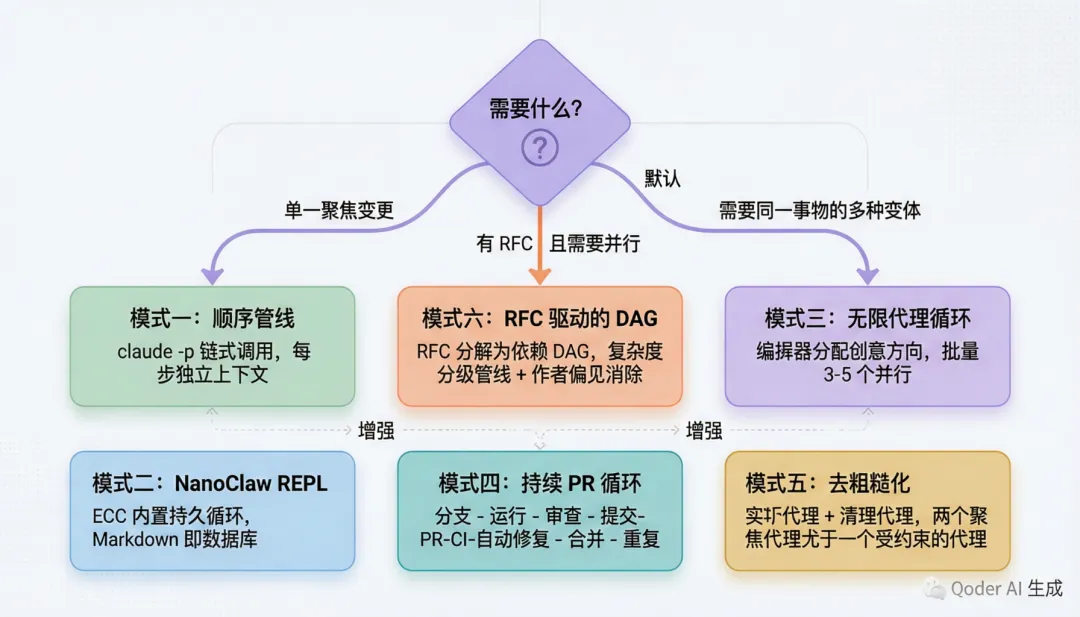
Pattern 4 的精妙之处:Continuous PR Loop
这是一个生产级的 Shell 脚本循环:创建分支 → 运行 Claude → 可选审查 → 提交 → 推送 PR → 等待 CI → 自动修复失败 → 合并 → 重复。几个关键的工程决策值得注意:
- 跨迭代上下文:通过 SHARED_TASK_NOTES.md 文件在迭代之间持久化进度、下一步和可复用模式
- CI 失败恢复:自动获取失败的 run ID,启动修复 pass,检查日志,重新等待
- 完成信号:魔法短语 CONTINUOUS_CLAUDE_PROJECT_COMPLETE,连续出现 3 次后停止
- 可配置边界:--max-runs、--max-cost、--max-duration、--merge-strategy、--worktree
Pattern 6 的架构创新:RFC-Driven DAG Orchestration
这是最复杂的模式。它将一个 RFC 分解为具有依赖关系的 WorkUnit,每个 WorkUnit 有复杂度分级(trivial / small / medium / large),不同分级走不同深度的管线:
- trivial:实现 → 测试
- large:研究 → 计划 → 实现 → 测试 → PRD 评审 + 代码评审 → 修复 → 最终评审
几个关键的架构决策:
作者偏见消除:每个阶段在自己的 Agent 进程中运行。"审查者永远不是写那段代码的人。"
文件重叠智能:非重叠的 WorkUnit 可以推测性地并行合并;重叠的 WorkUnit 逐个合并并 rebase。
Worktree 隔离:每个 WorkUnit 在独立的 worktree(/tmp/workflow-wt-{unit-id}/)中运行,同一 WorkUnit 的管线阶段共享 worktree。
可恢复:完整状态持久化到 SQLite。
七、持续学习:从"每次从零开始"到"本能系统"
ECC 的持续学习系统(skills/continuous-learning-v2/)可能是整个项目中最具原创性的设计。它解决的是 AI Agent 的一个根本问题:每次会话都从零开始,之前学到的东西全部丢失。
7.1 Instinct 模型
一个"本能"(Instinct)是一个小型的学习行为,具有五个属性:
- 原子性:一个触发条件,一个动作
- 置信度加权:0.3(试探性)到 0.9(接近确定)
- 领域标签:code-style、testing、git、debugging、workflow
- 证据支持:追踪产生它的观察
- 作用域感知:project(默认)或 global
从 .claude/homunculus/instincts/inherited/everything-claude-code-instincts.yaml 的源码可以看到 8 条手工策划的本能规则,每条都有精确的置信度:
7.2 数据流管线
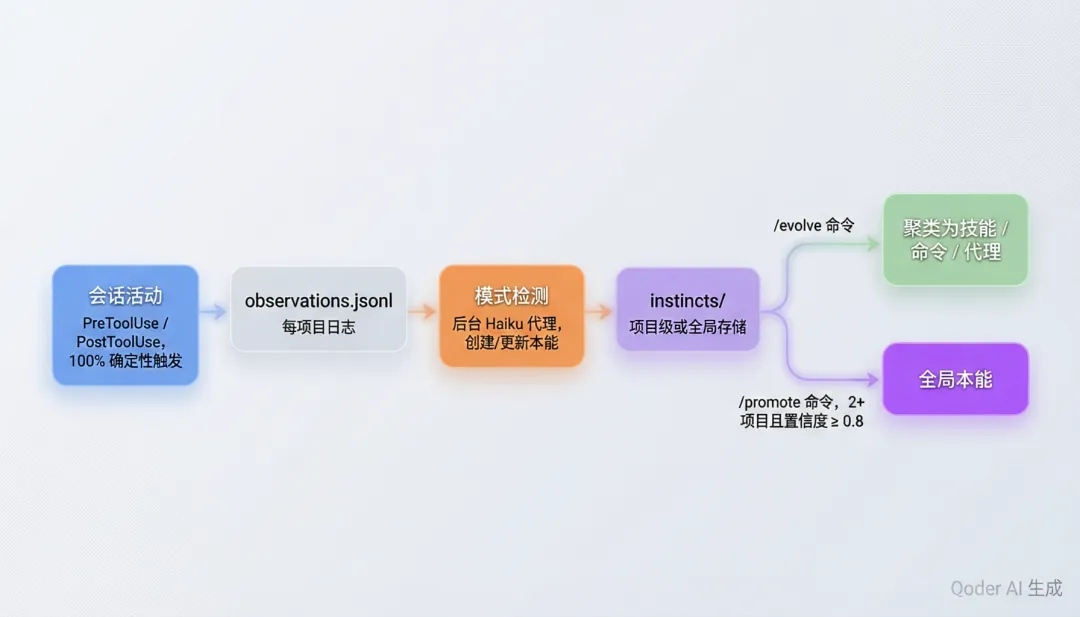
一个关键的设计决策是:v2 使用 Hook(而非 Skill)来观察。原因是 Skill 的触发是概率性的(约 50-80% 的时间),而 Hook 是 100% 确定性触发的。对于一个学习系统来说,观察的可靠性比一切都重要。
v2.1 解决了跨项目污染问题(React 模式泄漏到 Python 项目中)。项目通过 git remote URL(哈希化)检测,同一本能在 2+ 个项目中出现且平均置信度 ≥ 0.8 时,自动晋升为全局本能。
存储路径设计也体现了工程判断:${XDG_DATA_HOME}/ecc-homunculus/projects/<hash>/,刻意放在 ~/.claude 之外,以避免敏感路径保护规则的误触发。
八、Session 生命周期:跨会话的上下文桥梁
从 scripts/hooks/session-start.js 的源码来看,SessionStart Hook 是整个系统中最复杂的单个文件。它在每次会话启动时执行一个精密的管线:
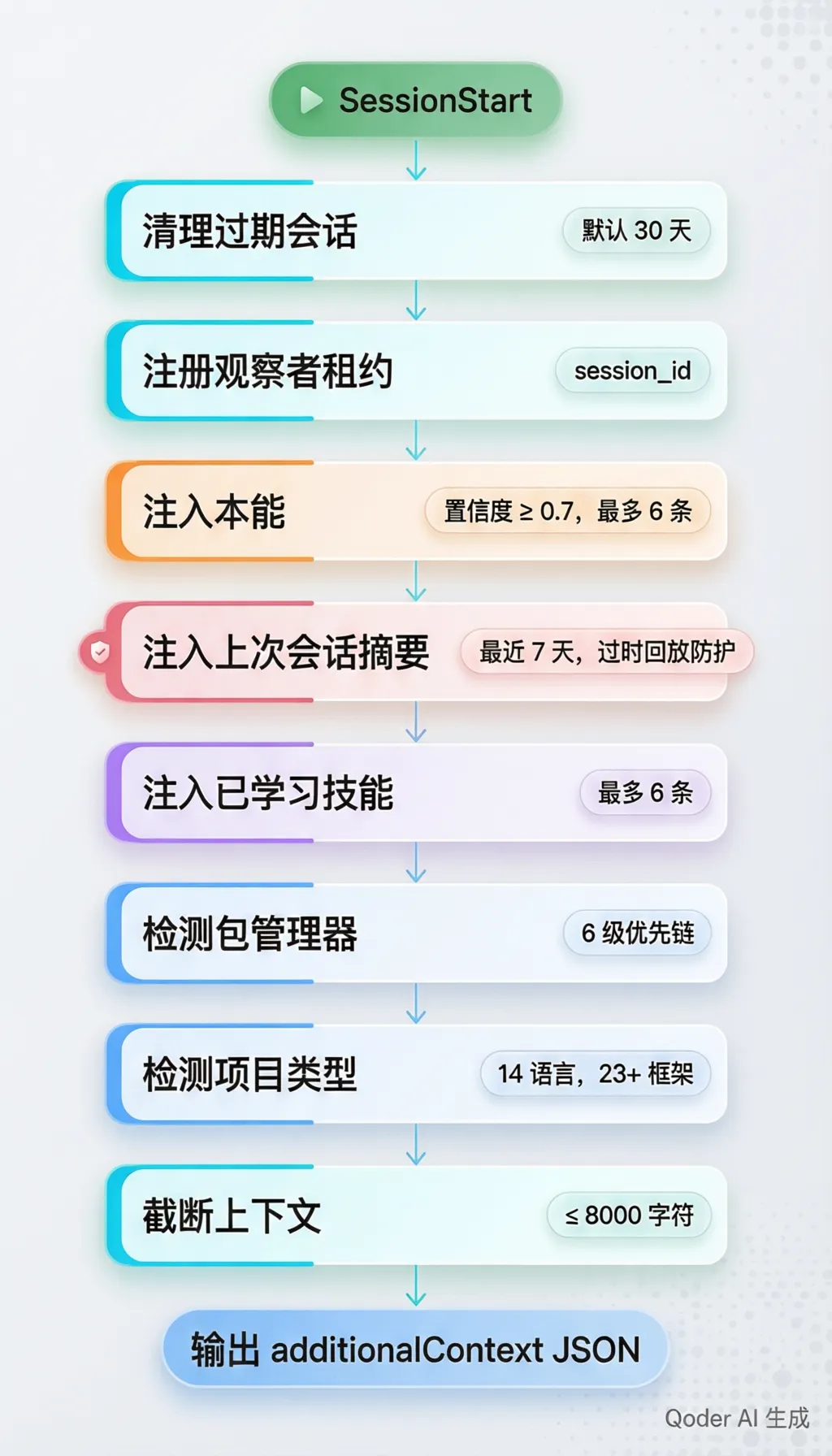
其中第 4 步值得特别关注:注入上次会话摘要时,内容被包裹在 "HISTORICAL REFERENCE ONLY — NOT LIVE INSTRUCTIONS" 的过时回放防护中。这是为了防止模型将上次的工具调用指令当作当前会话的实时指令重新执行——一个微妙但关键的防御设计。
Session 文件本身是 Markdown 格式(.tmp 扩展名),存储在 ~/.claude/session-data/ 中。每个文件包含结构化的 Header(项目、分支、Worktree、时间戳)和 Summary Block(任务、修改的文件、使用的工具、统计)。Summary Block 使用 HTML 注释标记(<!-- ECC:SUMMARY:START -->)实现幂等更新。
九、多因素风险评分
ECC 2.0 的 Rust 控制面板(ecc2/src/observability/mod.rs)实现了一个四轴风险评分引擎,用于评估每个工具调用的风险等级:
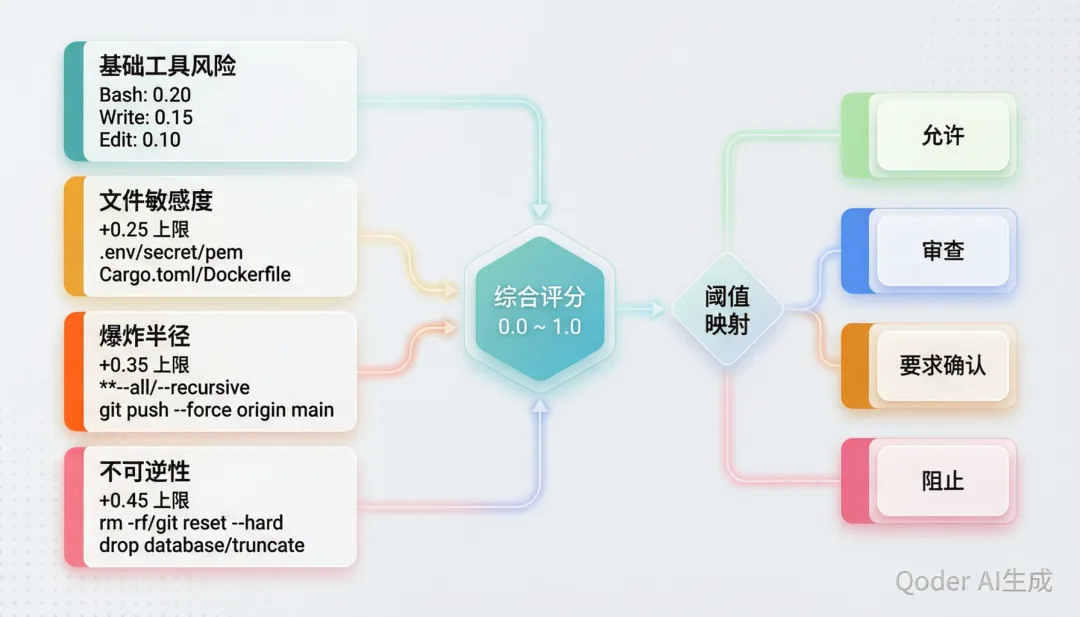
风险不是二值的。它通过四个维度的组合得分映射到四级响应。Tool Logger 将每个工具调用事件(工具名、输入/输出摘要、参数 JSON、风险分数、时间戳)持久化到 SQLite,支持分页查询。
十、自我改进:验证器门控的进化循环
ECC 的 Evaluator RAG Prototype(docs/architecture/evaluator-rag-prototype.md)定义了一个只读直到验证的自我改进循环。这个设计直接回应了 Agent 系统最大的风险:自我改进可能引入自我退化。
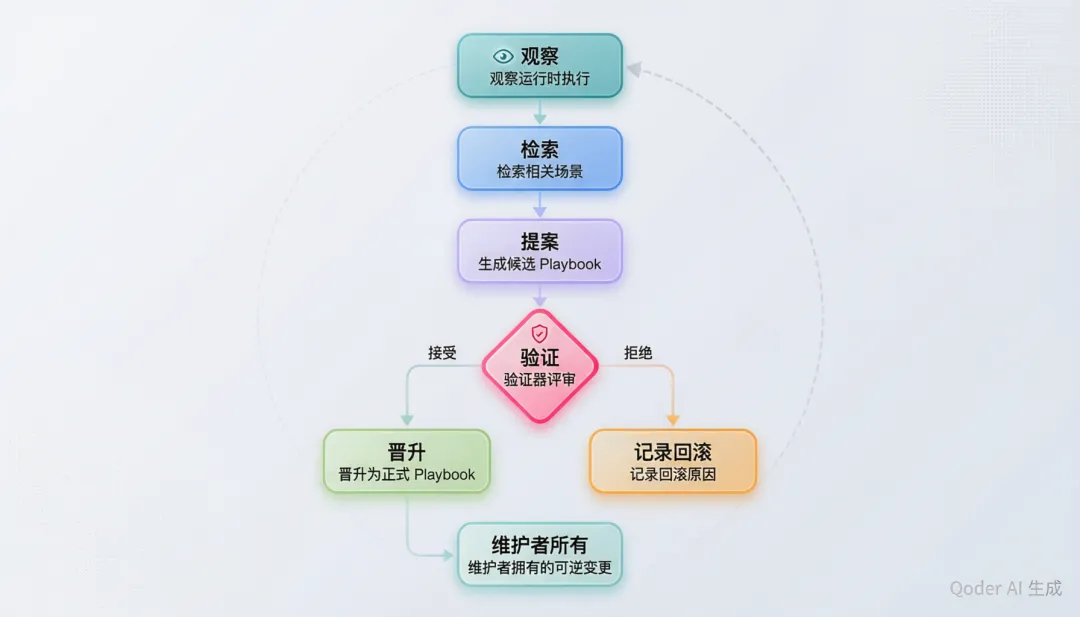
晋升规则极其严格:候选只有在验证器结果为 accepted、至少有一个被拒绝的候选(证明验证器能说"不")、每个来源有归属、动作是维护者拥有且可逆的情况下才能被晋升。
五个工件合约构成了这个循环的骨架:Scenario Spec(目标与门禁)、Trace(观测与提案事件链)、Report(评分与风险)、Candidate Playbook(可复用的工作流)、Verifier Result(接受/拒绝与理由)。
十一、关键设计模式总结
从源码中可以提炼出 ECC 在 Agent 架构层面的七个核心设计模式:
1. Harness-Neutrality(Harness 中立性):每个合约、载荷和数据结构都刻意不假设任何特定编码工具。适配器在边缘翻译,共享行为在 ECC 核心中。
2. Local-First, Hosted-Later(本地优先):可观测性、安装状态、会话快照、风险账本——全部无需托管依赖即可工作。托管功能必须消费相同的事件模型。
3. Verifier-Gated Evolution(验证器门控进化):自我改进循环是只读的,直到验证器证明候选改善了场景且没有扩大爆炸半径。
4. Typed Operation Contracts(类型化操作合约):安装系统从"宽泛的文件复制器"进化为类型化操作(copy-file、merge-json、render-template、remove),每个操作有所有权元数据和覆盖策略。
5. Multi-Factor Risk Scoring(多因素风险评分):风险不是二值的。基础工具风险、文件敏感度、爆炸半径和不可逆性组合为渐进式响应。
6. Evidence-Backed Claims(证据支持声明):发布就绪度、公告声明、插件可用性——所有声明都需要新鲜的证据。不能证明的东西就不能声称。
7. Context Graph as Memory(上下文图即记忆):会话模型包含完整的上下文图——实体、关系、观察(带优先级)和评分召回。这是 ECC 对持久代理记忆的回答:结构化、可查询、压缩感知。
十二、写在最后
ECC 不是一个简单的 Prompt 集合或工具插件。从架构角度看,它是在回答一个根本性问题:当 AI Agent 成为日常开发工具时,我们如何"操作化"它们——确保质量、管理成本、维护安全、保持跨工具一致性,以及让 Agent 能够从经验中学习而不引入自我退化?
它的答案是:用事件驱动的 Hook 管线替代 Prompt 层的可靠性约束,用显式的工具权限隔离替代"请不要做 X"的指令,用验证器门控替代无约束的自我改进,用多因素风险评分替代二值的允许/阻止判断。
这些不是理论设计,而是经过 211K Star、230+ 贡献者、10+ 个月日常使用验证的工程实践。每一个 Hook 的 exit code 约定、每一个 Agent 的工具集选择、每一个本能的置信度阈值,背后都有具体的 issue 编号和 regression 故事。
如果你正在构建自己的 Agent 系统,ECC 的源码值得逐行阅读。不是因为你要复制它的代码,而是因为它在 Agent 架构层面做出的那些设计决策——关于可靠性、关于成本、关于安全、关于学习——恰好是当前这个"Agent 狂热"时代最稀缺的东西:经过实战检验的工程判断。
本文基于 ECC v2.0.0 源码分析。通过 Qwen3.7-Max 汇总整理。
