 夜雨聆风
夜雨聆风困扰
识别并提取PDF发票信息,真的困扰了我很久。
更头疼的是我之前用 Python 折腾了很久一直没找到好用的方案,毕竟我不是专业的程序员。
转机
直到最近,用上了OpenCode,效果还不错。
先看看成品长啥样,分了汇总表和明细表(表内数据已进行脱敏处理):
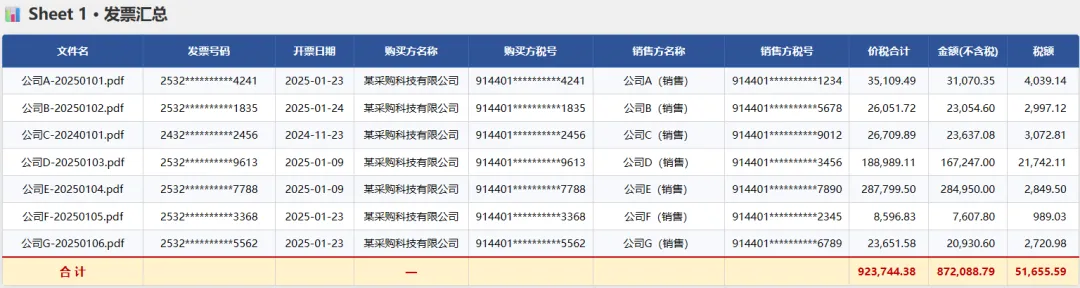
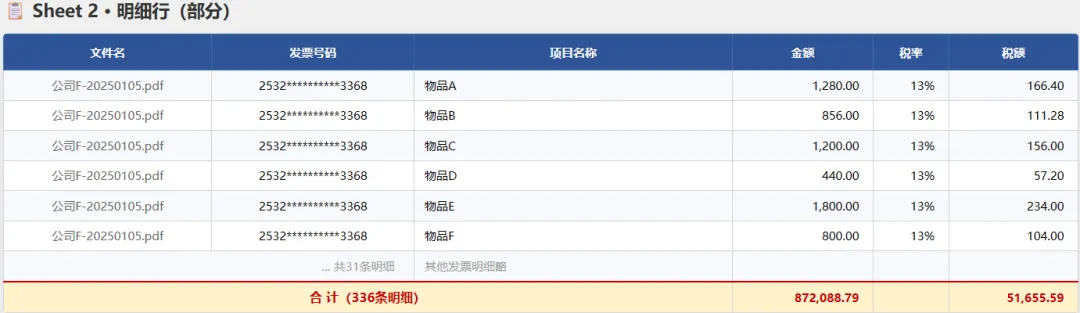
两页Sheet,第一页是汇总(谁开的、多少钱、多少税),第二页是每条商品明细,底下自动合计。
整个过程如下:
在OpenCode里装一个MinerU,MinerU是专门干文档提取的。安装玩出,跟它说一声"帮我提取这些发票",它就自动把 PDF 里的文字、表格全扒出来,吐成结构化的 Markdown。不需要装 OCR、不需要注册账号、不需要配置环境。甚至不用记命令行,在 OpenCode 里自然语言描述需求就行:"把发票文件夹里的PDF全提取出来",它自己就安静地干活了。
提取出来之后,再用 Python 把发票号、日期、买卖双方、商品明细一条条扒出来,最后用 openpyxl 写进 Excel。
然后Excel 这边做了点美化——数字设成数值格式(不然没法拉公式),表头蓝底白字,隔行变色,底下自动带一行合计。
我现在也把这个方案打包成了 OpenCode 的 一个Skill,以后就可以直接复用啦。
反思
弄完以后我反思了一下:其实之前用 Python 搞不定,不是因为 Python 不行,是想纯靠代码解决 PDF 解析这件事本身就方向不对。PDF 解析交给专业工具(MinerU),Python 专注做数据清洗和 Excel 输出,各干各的活,反而一下就通了。
当然中间会遇到一些问题,需要持续给它优化,比如MinerU 遇到复杂表格会串行,有几张发票商品明细特别多(100多项),表格又带合并单元格,MinerU 的 HTML 输出行列对不齐。后来加了 pdfplumber 做交叉验证,两套结果对着看,数据才稳定了。当然这个过程不需要去写代码,只要关注输出效果,不满意的时候直接跟OpenCode说就行,它会帮忙调试好,直到得到满意的结果。
以前我用Python的时候,还要自己研究,怎么优化代码,怎么打包程序。现在一句话就可以解决,和OpenCode说一句:“帮我把这个识别方案打包成一个可执行的exe,并设计一个可视化界面,直接使用。”它不到1分钟就做好了一个可以独立使用的exe程序。
这个事情其实不复杂,但每次手动搞都烦得不行。而花点时间写个脚本一次搞定,之后不管来多少张发票都能复用。
这种重复劳动的痛点,不是不会弄,是忍着忍着就习惯了。什么"几分钟的事手抄一下算了"——但今天20张花半小时,下次200张呢?
哪怕当下多花两倍的时间去搞自动化,下次就全是纯“赚”。
真的是工具用对,事半功倍啊。
