 夜雨聆风
夜雨聆风
引言
近年来,大语言模型(LLMs)的突破性进展推动其在医疗保健领域的快速应用,广泛用于医学问答、电子健康记录(EHR)生成和临床决策支持。与此同时,基于LLM的智能体(LLM-based Agents)迅速兴起。临床实践中,医务人员经常需要面对多模态且高度异质化的数据、繁重的工作负荷以及对时间高度敏感的临床决策需求。在此背景下,AI智能体展现出独特优势:它们不仅能够理解和生成自然语言,还能够通过调用外部工具自主完成多步骤任务,从而具备目标导向的推理与决策能力。因此,AI智能体正逐渐被视为医疗技术发展的前沿方向。
已有研究开始探索AI智能体在医疗中的潜力。例如,Qiu等人研究了其在诊断支持和工作流程优化中的应用,并指出数据隐私及过度依赖等问题;其他学者分析了Agentic AI在疾病诊断、临床运营、药物研发和机器人辅助干预中的核心功能;还有研究综述了当前应用场景,并强调幻觉(hallucination)、泛化能力不足以及伦理风险等挑战。Moritz等人进一步提出了医疗领域协同多智能体系统(MASH)的概念,强调由多个基于LLM、可互操作的智能体组成的分布式协作体系,通过协同工作优化临床及运营流程,同时指出安全通信、互操作性和临床验证等关键挑战。
然而,与医疗领域大语言模型研究的迅速增长相比,专门针对LLM智能体的研究仍然相对有限。此外,现有综述在覆盖范围、评价深度以及理论框架方面仍存在不足。因此,本研究旨在填补上述空白,通过更加系统和全面的综述,为医疗AI智能体的开发与部署提供理论依据。
本文试图回答以下核心问题:当前基于大语言模型的医疗AI智能体发展现状如何?如何有效评价其实施效果?如何指导其部署,以确保安全性、可控性与可靠性?为此,本文设定了四项研究目标:(1)梳理AI智能体的概念基础、历史演进及核心特征;(2)总结医疗领域的典型应用及代表性系统;(3)构建覆盖临床和人文维度的多维评价框架;(4)识别并讨论未来关键发展方向。
AI智能体的发展演化
“智能体(Agent)”这一概念最早可追溯至哲学思考的深处,跨越了理论探索与技术实践两个层面。古希腊哲学家已经开始关注具有欲望、信念、意图和行动能力的实体,从而萌生了智能体的早期思想。亚里士多德提出的“目的(telos)”概念,为后来智能体所体现的目标导向特征奠定了哲学基础。
进入现代,随着自然科学和计算机技术的发展,人工智能研究逐渐从哲学思辨转向实际应用。20世纪50年代,艾伦·图灵提出“图灵测试”,成为衡量机器智能的重要标准。20世纪70年代出现的专家系统,则通过将人类专家知识编码到计算机程序中,实现推理与决策。随后,机器学习技术的发展使智能体能够从数据中获取知识与技能,其智能水平显著提升。进入21世纪后,深度学习在感知、决策和执行等方面取得突破,推动智能体技术进入快速发展阶段。特别是强化学习(RL)和多智能体强化学习(MARL)的进展,使智能体能够在复杂环境中做出更加优化的决策。
2022年以后,随着大语言模型的广泛普及,AI开始深入社会各个领域,也为智能体的发展开辟了新路径。基于大模型构建的AI智能体具备更丰富的知识储备、更自然的人机交互能力以及更好的可解释性。OpenAI推出Custom GPT(GPTs)功能,允许用户通过整合知识、操作和指令创建专属GPT;Google依托Gemini系列模型推出支持多模态任务处理的智能体框架;Meta开源的LLaMA系列模型催生了大量社区驱动的智能体应用;Anthropic的Claude模型通过Constitutional AI框架在安全性和可控性方面树立了新标准;DeepMind的Sparrow项目则展示了语言模型与强化学习结合的创新路径。这些进展共同推动了个性化AI助手的广泛应用,并形成了多样化的AI智能体生态。
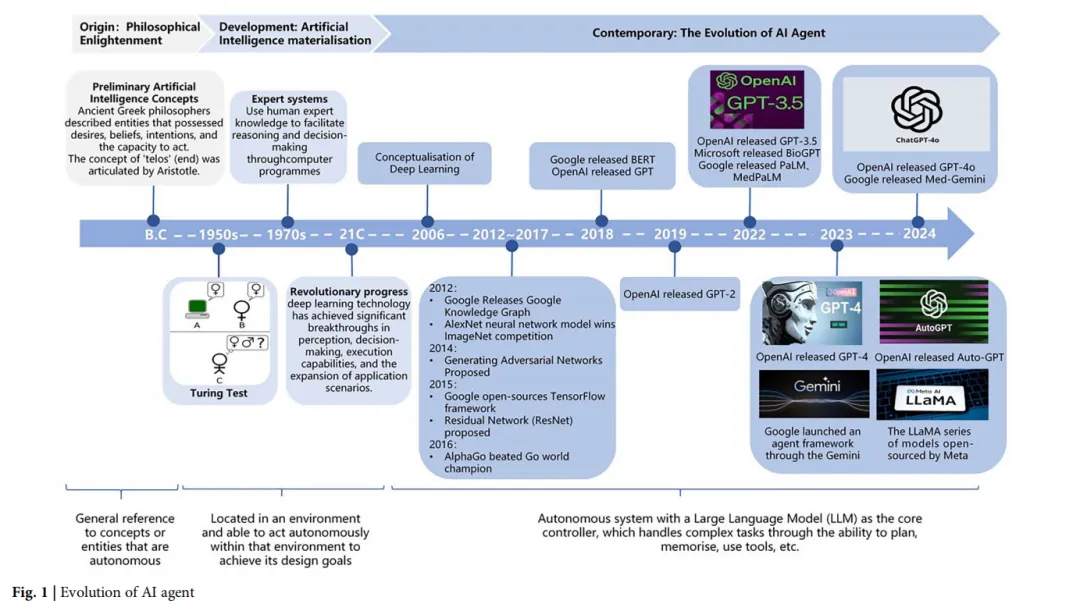
在医疗领域,众多机构也开始优先布局基于LLM的AI智能体。例如,IBM Watson Health利用自然语言处理、机器学习和大数据技术,为医疗机构提供辅助诊断、患者管理和药物研发等智能服务。
AI智能体的定义
目前学术界尚未形成统一的AI智能体定义。1998年,Castelfranchi将其定义为能够自主做出决策并采取行动的智能实体,具备目标导向、社会智能、心智推断、适应性和灵活性等特征。Weng则将AI智能体定义为以大语言模型为核心控制器,并结合记忆、任务规划和工具使用能力来处理复杂任务的自主系统,即“LLM + 记忆 + 任务规划 + 工具使用”。李飞飞团队则强调智能体具备感知环境、做出决策和执行行动的能力,其核心在于利用LLM或视觉语言模型(VLM)增强系统的交互性与适应性。Parisi强调通过调用外部API扩展模型能力,而Schick等人的Toolformer则展示了语言模型能够自主学习如何使用工具。
相比之下,Weng的定义既突出LLM作为核心控制器,又系统整合了规划、记忆和工具使用等关键模块,更适合用于构建能够处理复杂多步骤任务的自主系统。因此,本文采用Weng的定义,将AI智能体视为一种以大语言模型为核心控制器,并辅以规划、记忆、工具使用和自我反思四大模块的自主智能系统,以确保其能够高效、可靠地执行医疗领域的专业任务。
AI智能体的核心特征
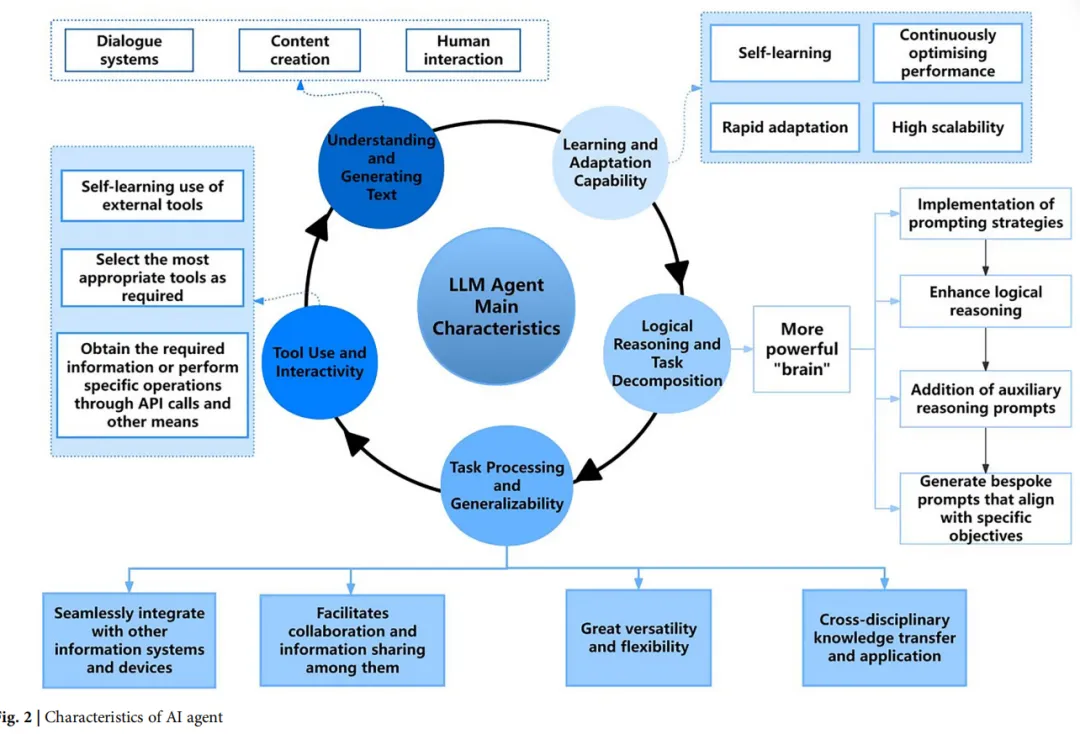
1. 文本理解与生成能力
结合大语言模型后,AI智能体表现出强大的文本理解与生成能力。它不仅能够深入理解上下文信息,还能生成自然流畅的文本内容,从而在对话系统、内容创作等领域带来革命性变化。这种理解与生成能力的结合,使AI智能体能够以更加智能和个性化的方式与人类交互,提供更精准的服务。
2. 工具使用与交互能力
AI智能体不仅具备强大的学习和处理能力,还能够自主学习如何使用外部工具。它们可以根据具体任务选择最合适的工具,并通过API调用等方式获取信息或执行操作,从而提升任务处理的效率和准确性。这种工具使用能力增强了智能体的自主性,也拓展了其与人类及其他系统的交互方式。
3. 任务处理与泛化能力
AI智能体能够与电子健康记录系统(EHR)、医学影像归档与通信系统(PACS)以及实验室信息系统(LIS)等多种医疗信息系统无缝集成,自动提取患者的多模态数据,辅助医生进行综合决策,减少人为错误,提高诊断效率和准确性。此外,基于LLM的智能体展现出较强的跨领域适应能力,能够在不同任务之间灵活切换,因此被视为解决复杂问题和推动智能化转型的重要工具。
4. 逻辑推理与任务分解能力
大语言模型赋予AI智能体更强的“思维能力”。通过合理的提示策略,智能体能够显著增强LLM的逻辑推理效果。自主智能体还可以根据目标自动生成适合的提示,从而更有效地完成复杂推理任务和多步骤任务分解。
5. 学习与适应能力
与传统AI相比,基于LLM的AI智能体具备更强的学习与适应能力。它们能够从海量数据中自主提取关键信息并持续优化自身性能,而无需大量人工标注或预设规则。同时,智能体还能够在少样本甚至零样本条件下快速适应新任务或小规模数据集,并表现出良好的性能。此外,其高度可扩展的系统架构也有利于持续改进和自我演化,以满足不断增长的实际应用需求。
AI智能体在医疗中的应用
当前医疗领域AI智能体的应用归纳为六大核心方向:
辅助诊断(Assisted Diagnosis) 辅助临床决策(Clinical Decision Support) 医学报告生成(Medical Report Generation) 健康管理与医疗聊天机器人(Health Management) 医学教育(Medical Education) 药物管理与医院管理(Medication & Hospital Management
一、辅助诊断(Assisted Diagnosis)
辅助诊断是目前AI智能体最广泛、最成熟的应用场景之一。从技术角度来看,研究表明:多智能体(Multi-Agent)协作能够提高诊断准确率,并减少病历中的错误。因此,研究人员通常采用:专家模拟(Expert Simulation)、医患互动(Doctor-Patient Interaction)、多智能体协作(Multi-Agent Collaboration)来提升诊断性能。
Agent Hospital(清华大学):清华大学提出了著名的:Agent Hospital(智能体医院)该系统模拟真实医院场景中的:医生、患者、护士、医疗流程。通过构建完整的虚拟医院环境,提高医患交互智能化水平。
其本质是:利用多个AI智能体模拟真实医疗系统运行。
AMSC(哈尔滨工业大学):Assistant-driven Multi-Specialist Consultation通过构建:神经科专家、心内科专家、呼吸科专家、全科医生等不同背景智能体,模拟真实MDT讨论过程。
这种模式能够:减少单个模型偏差、提高复杂疾病诊断准确率、增强可解释性。
ClinicalAgent:ClinicalAgent通过建立:专科智能体、科室级智能体为不同科室提供定制化支持。
例如:神经科Agent、心血管Agent、肿瘤Agent使模拟环境更接近真实临床工作。
专病智能体
除了通用诊断系统外,越来越多智能体聚焦专科领域。MMedAgent(Stanford)利用多模态数据:CT、MRI、病理图像、临床文本。实现:图像检测、病灶分割、疾病分类。
ZODIAC(心血管领域)
功能包括:心律失常识别、心电图分析、风险评估;达到接近心脏病专家水平。
MAGDA
结合:影像学资料、临床指南。进行推理决策。比单纯LLM具有更强临床可靠性。
二、辅助临床决策(Clinical Decision-Making)
辅助决策是AI智能体另一项重要应用。临床决策往往涉及:多学科知识、多角色协作、多源数据融合。因此非常适合多智能体系统。
MedAgents(耶鲁大学):MedAgents采用:Role Playing(角色扮演)
模拟:神经科医生、放射科医生、ICU医生、全科医生之间的讨论。
经过多轮讨论后:形成最终共识决策(Consensus Decision)。
研究发现:这种方式显著提高:推理质量、可解释性、决策可信度
MDAgents
根据病例复杂程度自动配置:全科医生Agent、专科医生Agent形成:MDT(多学科会诊)模式。
对于复杂病例:自动增加专科智能体参与讨论。
MEDAIDE
MEDAIDE通过:查询重写(Query Rewriting)、意图识别(Intent Recognition)、多智能体协作提高复杂临床问题的决策质量。
肿瘤学智能体
海德堡大学开发的肿瘤决策Agent能够整合:文本、病历资料、影像、CT、MRI、病理、组织病理学图像、基因组学、NGS结果、指南、NCCN等指南从而生成个体化治疗建议。
急诊医学
研究人员构建了包含:急诊医生、分诊护士、药师、调度员的多智能体系统。
结合:ETAS分诊体系实现:急诊分级、治疗建议、药物推荐。显著提高急诊效率。
三、医学报告生成(Medical Report Generation)
这是AI智能体最早进入临床的应用方向之一。
最初目标:缓解放射科医生短缺问题。
CheXagent Stanford开发。主要针对:胸片(Chest X-ray)能够:自动识别病变,自动生成放射学报告。其视觉任务性能:比通用大模型高97.5%。
CXR-Agent专注胸片分析。可完成:病变检测、病变分类、病变定位、自动报告生成。
MGA Medical Generalist Agent通过建立:
医学术语库、从既往报告中匹配最佳句子,提高:报告准确性、专业性、一致性。
患者友好型报告:近年来研究方向发生变化:从“写给医生”
转向“写给患者”。
多智能体系统能够:一个Agent负责专业内容另一个Agent负责通俗化表达最终生成:Patient-Friendly Report。提高:可读性、患者理解度、就医体验,同时减少医生工作量。
四、健康管理与医疗聊天机器人
聊天机器人(Chatbot)是健康管理最常见的智能体形式。
其核心优势:7×24小时服务、个体化干预、长期随访。心理健康领域目前最活跃方向。
AMC(Agent Mental Clinic)
针对抑郁症诊断。构建:患者Agent、精神科医生Agent、监督Agent,模拟精神科门诊过程。
MISHA针对大学生。提供:压力管理、放松训练、心理教育,帮助缓解焦虑和压力。
其他应用包括:自杀风险干预、新冠后心理孤立缓解、老年人心理支持等领域。
慢病管理
研究已扩展至:减重管理、糖尿病管理、皮肤病管理等方向。
Polaris
Polaris支持:电话、语音交互。
系统中包含:护士Agent、社工Agent、营养师Agent。能够完成:用药提醒、预约管理、饮食指导等健康管理任务。
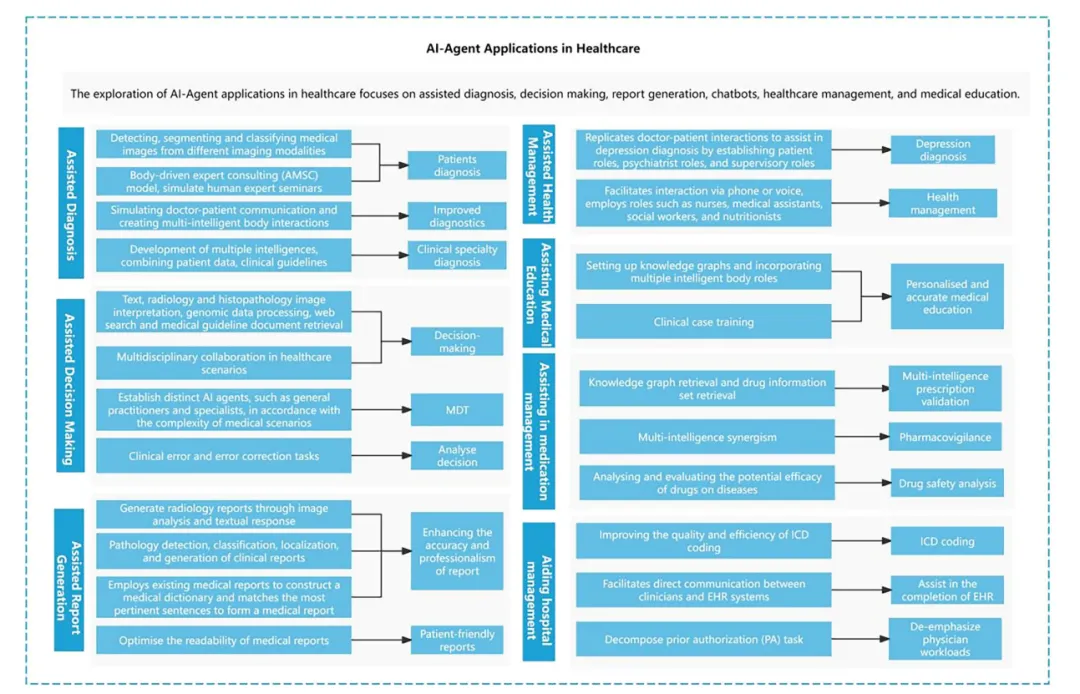
五、辅助医学教育(Assisting Medical Education)
医学教育是AI智能体的重要应用场景之一。研究人员通常基于真实医疗场景,通过构建患者、教师等不同角色的智能体,创建高度交互式的教学环境,从而提升医学生的临床能力。
例如,密歇根大学开发的 AI Patient(人工智能患者)系统能够模拟真实患者。该系统通过构建知识图谱,并引入检索(retrieval)、推理(reasoning)和生成(generation)等多个辅助智能体角色,提高模拟病例的真实性和可信度,从而促进医学生临床训练。
香港中文大学开发的 MEDCO(Medical Education Copilot)则强调临床病例训练。系统通过建立:虚拟患者(Patient Simulation)、高年资医生反馈(Senior Doctor Feedback)、专家点评(Expert Review)、多学生互动(Multi-Student Interaction)等机制,为医学生提供更加个体化和精准的医学教育体验。
此外,ChatCoach 系统通过设置:医生角色、患者角色、教练角色模拟真实医疗沟通场景,帮助医学生提高医患沟通能力。除通识医学教育外,研究已进一步拓展至专科教育领域。例如,针对放射肿瘤学(Radiation Oncology)开发的基于LLM的医学聊天机器人,已成为专业医疗培训的重要工具,显著提高了医学教育的可及性、个性化水平和交互性。
六、辅助药物管理(Assisting in Medication Management)
在药物管理领域,研究人员通过模拟药物全生命周期的不同阶段,探索AI智能体在以下方面的应用:处方审核(Prescription Management)、药物不良反应监测(Pharmacovigilance)、临床试验药效预测(Drug Efficacy Prediction)等。
Rx Strategist:Rx Strategist提出了一种多智能体处方审核框架。
其核心功能包括:药物适应证验证、剂量合理性审核、药物知识图谱检索、药品数据库调用。从而提高处方审核效率与准确性。
MALADE:MALADE主要聚焦药物警戒(Pharmacovigilance)。
通过多个智能体协同工作,实现:药物不良反应识别、风险评估、安全性监,从而提高药物安全管理能力。
ClinicalAgent
ClinicalAgent是一种针对临床试验设计的多智能体系统。
其能够:分析药物潜在疗效、评价药物安全性、预测治疗效果。从而为药物研发与临床试验提供支持。
七、辅助医院管理(Aiding Hospital Management)
医院管理是AI智能体的重要应用方向之一。其核心目标包括:减轻医生负担、提高工作效率、优化医疗流程、提升医院运营水平。
电子健康记录(Electronic Health Records,EHR)系统复杂的操作流程和管理任务已经成为导致医生工作负担增加和职业倦怠的重要因素之一。
因此,越来越多研究尝试利用AI智能体解决这一问题。
EHRAgent:EHRAgent能够实现:医生与EHR系统之间的自然语言交互。
系统通过自主代码生成与执行,使医生无需复杂操作即可完成:数据查询、信息整理、临床分析,从而提高工作效率和用户体验。
Almanac Copilot:Almanac Copilot能够帮助临床医生完成:病历文书工作、信息检索、流程管理。通过自动化重复性任务,减少文档处理负担。
ColaCare:ColaCare主要面向:EHR建模、临床预测、精准医疗
其核心架构包括:
DoctorAgent:模拟不同专科医生。MetaAgent:负责整合多个医生意见。从而实现类似真实MDT的协同决策过程,提高临床预测能力和个体化医疗水平。
医保与行政管理
部分研究还关注:医疗保险授权(Prior Authorization)通过构建多智能体系统,将复杂行政任务进行拆解,实现自动化处理,从而降低医生行政负担。此外,还有研究探索:ICD编码自动化,利用多智能体框架完成疾病分类编码工作,提高医保结算效率。
其他医疗应用场景
除上述领域外,AI智能体还被应用于:生物医学研究,包括:生物实验设计,细胞生物学研究,化学生物学研究,遗传学研究等。
基层医疗
在基层医疗场景中,研究者构建:任务难度评估智能体、专家智能体、回答简化智能体。同时结合:地区文化特征、本地方言语言,为基层医疗提供支持。
AI智能体在医疗应用中面临的挑战
尽管AI智能体具有广阔前景,但其真实世界应用仍面临若干关键挑战。
(一)幻觉问题(Hallucination)
在罕见病或复杂病例场景下,
AI智能体可能生成:看似合理但实际上错误的诊断结论。这种“诊断幻觉”可能直接威胁患者安全。
(二)可解释性不足(Lack of Interpretability)
AI智能体的决策过程往往缺乏透明度。
临床医生难以追踪:推理过程、证据来源、决策依据。
从而影响其可信度和临床采纳率。
(三)责任归属不清(Ambiguity in Accountability)
当AI智能体提出诊断或治疗建议时,如果最终导致错误结果:开发者负责、医院负责、医生负责。目前尚缺乏明确法律和伦理框架。
(四)数据相关问题(Data-related Issues)
主要包括两个方面:数据偏倚,训练数据可能存在:性别偏倚、种族偏倚、地域偏倚,导致部分人群诊疗效果下降。
2. 隐私保护
医疗数据属于高度敏感信息。若缺乏完善的数据治理体系:可能导致:隐私泄露、数据滥用、伦理风险等问题。
医疗领域AI智能体的评价框架(Evaluation of AI Agents in Healthcare)
目前医疗AI智能体研究快速增长,但评价体系的发展明显滞后。
现有研究大多仅关注:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值等传统机器学习指标。然而,对于医疗场景而言,仅依赖这些技术指标远远不够。因为医疗AI智能体最终服务于:患者(Patients)、医务人员(Clinicians)、医疗机构(Healthcare Organizations)
因此评价体系必须同时考虑:技术性能(Technical Performance)、临床价值(Clinical Value)、人文价值(Human-centered Value)三大维度。
评价框架总体结构
医疗AI智能体评价体系应包含三个层面:
AI系统层面评估:模型性能、推理能力、工具调用能力、多智能体协同能力
用户层面评估:医生体验、患者体验、用户满意度。
3医疗系统层面评估:成本效益、医疗资源利用率、安全性、医疗质量。
一、技术性能评价(Technical Evaluation)
(1)准确性(Accuracy)
评价内容:AI输出结果与标准答案的一致程度。例如:诊断场景比较:AI。诊断结果与专家诊断结果是否一致。
医学问答场景,比较:AI回答与标准医学答案的一致程度。
(2)推理能力(Reasoning Ability)
对于医疗智能体而言,不仅要答对,更要:给出正确的推理过程。评价内容包括:逻辑链完整性,推理合理性,临床依据充分性。
(3)任务完成率(Task Completion Rate)
衡量:AI是否成功完成指定任务。例如:病历书写,是否完成:主诉、现病史、既往史、查体、诊断等全部内容。
(4)自主性(Autonomy)
评估:AI在无人干预条件下完成任务的能力。例如:是否能够:自动检索文献、自动调用数据库、自动整合信息、自动完成决策。
(5)工具使用能力(Tool Use)评价:AI是否正确调用外部工具。
例如:PubMed、EHR、PACS、医学知识库等。
(6)多智能体协同能力(Collaboration)对于Multi-Agent系统,需要评价:信息共享效率、协作质量、最终共识质量等。
二、临床价值评价(Clinical Evaluation)
医疗AI最重要的评价标准仍然是:是否改善患者结局。(1)诊断准确率
包括:正确诊断率、误诊率、漏诊率。
(2)决策质量评价:AI建议是否符合:临床指南、专家共识、最佳实践。
(3)患者预后改善,例如:卒中领域可以评价:mRS改善、死亡率降低、卒中复发率降低、肿瘤领域可以评价:生存率、无进展生存期等。
(4)医疗效率提升,例如:减少:门诊等待时间、诊断时间、报告生成时间
提高:医生工作效率、医疗资源利用率。
(5)患者安全性,这是特别强调的维度。评价内容包括:不良事件发生率、误诊率、药物错误率、潜在伤害风险。
三、人本维度评价(Human-centered Evaluation)
这是目前绝大多数研究忽略的部分。AI智能体最终服务于人。因此必须评价:(1)用户满意度包括:患者满意度、医生满意度、医院满意度。
(2)用户信任度,评价:
用户是否愿意:接受AI建议、依赖AI结果、与AI协作。
(3)可解释性,评价:
AI是否能够解释:为什么给出该诊断、为什么推荐该治疗。
(4)透明性,评价:
用户是否知道:数据来源、推理过程、工具调用过程。
(5)公平性评价:不同群体之间:性别、年龄、种族、地域
是否获得一致性能。
四、系统层面评价(System-level Evaluation)
未来医疗AI必须接受卫生经济学评价。(1)成本效益分析
评价:AI投入是否值得。例如:减少:医生时间成本、医院运营成本
(2)投资回报率评价:部署AI后的收益。
(3)长期维护成本包括:模型更新、数据维护、安全监管等。
(4)可扩展性评价:系统是否能够:跨医院部署、跨地区部署、跨专科部署。
目前绝大多数AI研究仍然停留在:“模型是否聪明”而未来真正重要的问题应当是:“模型是否真正改善医疗”
因此未来评价体系必须从:技术导向转变为价值导向,即:不仅关注模型性能,更关注:患者获益、医生体验、医疗系统价值。
八、未来发展方向(Future Directions)
作者认为,尽管基于LLM的AI智能体已经在医疗领域展现出巨大潜力,但距离真正大规模、安全、可信地融入医疗体系仍有很长的路要走。基于当前研究现状,作者提出了七个关键发展方向。
一、AI智能体与具身机器人(Embodied Robots)的融合
未来AI智能体的发展将不仅局限于数字空间,而是逐渐与实体机器人(Embodied Robots,ERs)融合。
随着大语言模型能力不断提升,AI智能体有望与机器人深度结合,使其能够直接参与现实医疗活动。
例如:手术机器人,未来机器人不仅能够执行预设动作,还能够:理解医生指令、实时分析患者状态、辅助手术决策。
护理机器人实现:生命体征监测、用药提醒、康复指导。
医疗服务机器人,能够直接与患者交流:收集病史、回答问题、提供健康建议
从而实现更加人性化和个体化的医疗服务。
面临的问题,机器人与AI智能体融合同时带来新的挑战:
安全性(Safety)机器人错误行为可能直接伤害患者。
责任归属(Accountability)
发生医疗事故时:开发者负责?医院负责?医生负责?仍缺乏明确规定。
患者隐私(Privacy):机器人将接触大量敏感医疗数据。
因此医疗体系必须建立:监管机制、行业规范、法律框架。确保其安全应用。
二、混合专家模型(Hybrid Expert Models),未来医疗AI的重要发展方向之一是:专家混合模型。为什么需要MoE?尽管大型预训练模型拥有很强泛化能力,但面对专科医疗任务时常存在:精度不足、可解释性不足、专业性不足等问题。
例如:神经科问题、需要神经科专家知识。肿瘤问题、需要肿瘤专家知识。影像问题、需要放射科专家知识。单一大模型难以同时达到所有专科专家水平。因此:MoE通过动态调用不同专家模块,让最适合的“专家”参与决策。
医疗实例
MoE-SLU语音医疗咨询系统,利用多个专家模型融合ASR结果。结果显示:关键词识别准确率提高:3.4%–5.1%,说明MoE已经开始从理论研究走向实际医疗应用。MoE能够:保留模型效率、增强可解释性、提高专业能力、提升决策可靠性。未来很可能成为医疗AI的重要架构。
三、评价指标扩展(Expansion of Evaluation Metrics)
当前评价体系存在明显局限。大多数研究仅关注:Accuracy、Precision、Recall、F1 Score等技术指标。
但真实医疗环境中:真正重要的问题是:AI是否创造了医疗价值?因此未来评价体系应更加全面。应新增经济学指标例如:成本效益分析,投资回报率,长期维护成本。
应新增安全指标
例如:不良事件发生率、医疗差错率、患者伤害风险。
应新增患者相关指标
例如:患者满意度、用户体验、医患接受度。
未来必须建立,多维度评价体系(Multi-dimensional Evaluation Framework)才能真实反映AI在医疗中的价值。
四、安全与风险管理(Safety and Risk Management)
随着AI智能体自主性不断增强,其在医疗领域的影响将越来越大。但同时也会带来新的风险。
当前两大核心问题
1. 临床信任不足,许多医生仍不愿完全信任AI建议。原因包括:黑箱问题、幻觉问题、不可预测行为。
2. 缺乏风险控制机制,目前多数系统缺少:实时监测、异常预警、自动纠错机制。
建议建立:持续监督框架,能够:实时监控AI行为、发现错误、自动预警
同时建立:应急响应机制,确保系统在异常情况下快速响应。
五、伦理审查(Moral and Ethical Review)
随着AI智能体逐步进入临床工作流,伦理问题将成为核心议题。
三个核心伦理问题,数据隐私、算法透明性、责任归属,这些问题直接影响:用户接受度、社会信任、长期可持续发展。
NHS与DeepMind案例
过去英国国家医疗服务体系(NHS)与Google DeepMind合作时曾引发患者隐私争议。该案例提示:医疗AI应用必须严格遵守伦理规范。国际监管进展、欧盟AI法案将医疗AI定义为:高风险系统(High-Risk System)要求:技术文档备案、安全性证明、合规性审查。未来医疗AI必须建立:独立伦理委员会、隐私保护机制、医生监督机制、责任分配制度确保负责任发展。
六、用户信任与反馈机制(User Trust and Feedback Adoption)
AI智能体能否成功推广,不仅取决于技术突破,更取决于用户是否信任它。主要利益相关者包括:患者、医生、医疗机构。
当前问题
现实中存在:多方需求难以平衡,患者关注:安全与隐私;医生关注:准确性与责任;医院关注:成本与效率。缺乏反馈闭环,多数AI系统上线后:用户反馈难以真正用于模型改进。建立:动态反馈机制,持续收集:医生意见、患者体验、医院需求并直接融入模型迭代过程。
七、医务人员职业发展(Career Development of Medical Staff)
长期以来社会一直担心AI会不会取代医生?答案是否定的。从社会技术系统理论(Socio-Technical Systems Theory,STS)角度来看,AI智能体带来的并不是医生消失,而是医疗工作方式的重构。医生角色将发生转变未来医生将更多承担:监督者:监督AI输出质量。决策整合者,综合:AI建议、临床经验、患者偏好进行最终决策。
人文关怀提供者,承担:医患沟通、情感支持、价值判断等AI难以替代的工作。
结论(Conclusion)
本综述系统总结了基于大语言模型的AI智能体在医疗领域的发展现状。包括:AI智能体的发展历程、核心特征。医疗应用场景包括:辅助诊断、临床决策支持、医学报告生成、健康管理、医学教育、药物管理、医院运营管理等领域。同时兼顾:技术性能、临床价值、人本价值的多维评价框架,并明确指出未来七大发展方向。
未来医疗AI的发展目标不应仅是构建更强大的模型,而应致力于打造安全(Safe)、可控(Controllable)、值得信赖(Trustworthy)的医疗智能体系统,使其真正服务于患者、医生和整个医疗体系。
