 夜雨聆风
夜雨聆风大模型在回答用户之前,已经悄悄把你淘汰了三次
很多品牌发现自己在AI里"查无此人",第一反应是:是不是内容发得太少、写得太差?但更扎心的真相往往是——你的内容压根没进入大模型回答这道问题时的"候选池"。它甚至没获得被比较的资格。今天我们把一段内容从"被检索"到"被说出口"的全过程拆开,看清它究竟是在哪一步、因为什么被淘汰的。
一、先打破一个幻觉:AI不会"读完全网再回答"
我们习惯性地以为,当你问AI"XX品类有哪些靠谱的牌子",它是把全网相关内容都读了一遍,然后客观地总结出一个答案。这个想象很美好,但和真实机制相去甚远。
今天主流的AI搜索——无论是带联网检索的对话模型,还是搜索引擎里的AI摘要——背后大多走的是同一条技术路线:检索增强生成(RAG)。它的工作流是三步:第一步,从海量内容里"召回"一小批可能相关的片段;第二步,对这一小批片段重新打分、"重排";第三步,只挑其中排在最前面的几条,作为生成答案的依据。
换句话说,AI每次回答,真正"读"进去的只是极少数几个片段。你的内容要被AI说出来,必须连续闯过三道关:能不能被召回进候选池、能不能在重排里排到前面、能不能在生成时被真正引用。三道关淘汰的逻辑完全不同。而绝大多数品牌,其实倒在了第一关——根本没进池子,后面两关连入场资格都没有。
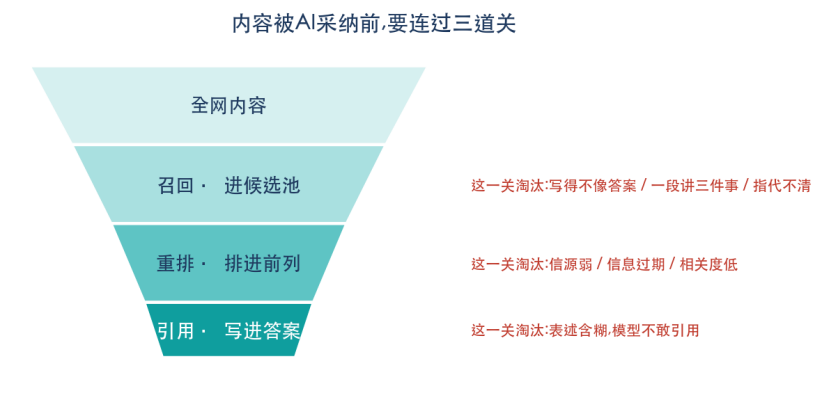
▲ 一段内容被AI采纳,要连过召回、重排、引用三道关,每一关淘汰逻辑不同
二、第一关· 召回:决定你"在不在场"
召回阶段的核心技术是语义检索。系统会把用户的问题转换成一个数学向量,再去内容库里寻找向量上最接近的片段。听起来抽象,但它带来的三个实操结论,每一条都在颠覆我们过去写内容的习惯。
结论1:AI读的是"段",不是"篇"
内容入库前会被切成一个个片段(chunk),召回的最小单位是片段,不是整篇文章。这意味着,一篇辞藻华丽、但结构松散、一段话里塞了三四个意思的"好文章",被切片之后,每一个片段都显得语焉不详、不知所云,反而比不上一段话只讲清楚一件事的朴素内容。
所以,为AI写内容的第一原则是:让任意一段单独拎出来都能独立成立。每个自然段只回答一个子问题,不依赖上下文也能被读懂。这和我们写给人看的"起承转合"是两套逻辑——人会顺着读,AI是随机抽片段读。
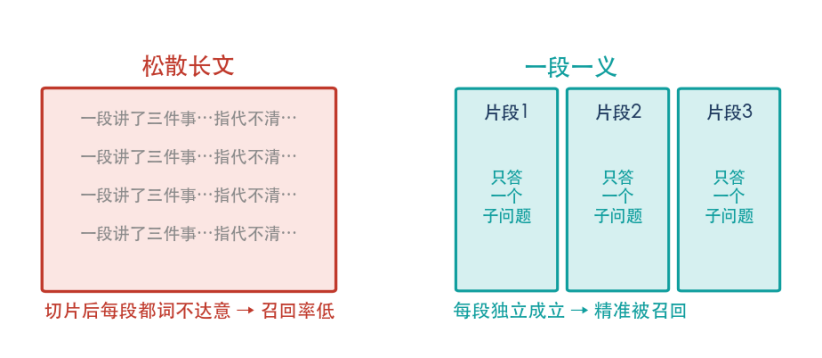
▲ 同样的信息量,"一段一义"的结构比松散长文更容易被精准召回
结论2:比的是语义密度,不是关键词密度
SEO时代那套"在标题和正文里反复堆关键词"的老办法,在召回阶段基本失效。向量检索比较的是语义接近度:一段话有没有把"是什么、解决什么问题、适用什么人群和场景"讲清楚,远比它出现了几次品牌词更重要。
反过来,有几种写法会悄悄稀释语义、拉低召回率:一是满篇代词,"它""这个""上述"用到底,机器分不清你在说谁;二是长难句套从句,一句话三个转折,核心信息被埋没;三是正确的废话,通篇正确却没有任何具体信息点。这些在人看来"读着挺顺",在机器看来却是"信息模糊"。
结论3:用AI会用的句式写,做"问答对齐"
这是一个被严重低估的技巧。用户向AI提问,大多是疑问句;而我们写内容,大多是陈述句。两者在语义空间里其实是有距离的。一个立竿见影的做法,是在内容里显式地把"问题"和"答案"配成对——
比如不要只写"信阳毛尖产自信阳",而是写成"信阳毛尖和信阳红到底有什么区别?核心差异在于发酵工艺:前者是绿茶,后者是红茶……"。这种"自问自答"的结构,天然贴近用户真实提问的向量,被召回的概率明显高于平铺直叙。你等于提前把用户会问的问题,亲手喂给了模型。
结论:进不了候选池,往往不是因为写得不够好,而是因为写得"不像答案"。
三、第二关· 重排:决定你"排第几"
闯进候选池,只是拿到了入场券。重排阶段,系统会对召回来的几十条片段重新打分排序,这一步决定你是被优先采纳,还是沉在底部被忽略。打分主要看三件事:
· 相关度:这段内容是不是直接、正面地回答了问题,而不只是擦边相关。
· 信源可信度:内容来自什么平台,有没有被其他独立来源一致印证。同一个事实,被多个来源说过,会被判定为更高置信。
· 新鲜度:对于有时效性的问题(最新款、最新价格、最新政策),旧内容会被系统性降权。
其中,新鲜度是最容易被忽视、也最容易出问题的一项。一个非常普遍的现象是:某品牌的核心产品早已换代升级,但AI在回答用户时,引用的仍是上一代产品的旧参数、旧价格。内容明明在库里,只是没有更新的、权重更高的内容把它"顶下去"。这不是AI坏了,这是你没有持续供给新内容的结果。
四、第三关· 引用:决定你"算不算数"
即使排到了前面,模型在生成最终答案时,还会做一次微妙的取舍:它倾向于引用那些表述确定、可以直接成句的内容。模棱两可、需要读者自己脑补的句子,模型用起来"心里没底",因为它要为自己生成的每一句话负责。
这一关的启示非常直接:把你最想被AI说出来的那句话,提前写成一句干净、肯定、可被原样复述的话。与其写"我们的产品在某些场景下可能有不错的表现",不如写"该产品主打XX场景,核心优势是XX、XX两点"。前者AI不敢用,后者AI拿来就用。你要做的,是替AI把"金句"写好,让它省事。
五、把方法收成一张"为召回而写"的清单
讲了三道关,落到笔头上,其实就是六条可执行的动作。下次写GEO内容前,可以逐条对照:
· 一段一义:每个自然段只回答一个子问题,单独拎出来能成立。
· 显式问答:在小标题或段首,用用户的提问句式起头,再紧跟答案。
· 去指代:关键句把主语写全,少用"它/这个/上述"。
· 埋确定句:把最想被引用的结论,写成一句肯定、可复述的话。
· 控语义密度:删掉正确的废话,每段都要有具体信息点。
· 保新鲜度:有时效的信息标注版本与时间,并持续用新内容覆盖旧内容。
六、不同AI平台,召回口味并不一样
还有一个进阶但重要的认知:虽然底层都是检索增强生成,但不同的AI平台,在召回和引用上的"口味"是有差异的。有的平台更依赖实时联网检索,对内容的新鲜度极其敏感;有的平台更倚重训练语料里沉淀下来的知识,对内容的"历史厚度"更看重;还有的平台对结构化、列表化的内容有明显偏好,更容易把它们整理进答案。
这带来的实操启示是:同一份事实,在分发到不同平台时,值得做"表达上的适配"——给偏好实时性的平台多供新内容,给偏好结构的平台多用清晰的小标题和要点列表。这也是为什么专业的GEO不会"一稿走天下",而是同一内核、多版表达。当然,这属于精细化运营的范畴,但理解它的存在,能帮你避免"在A平台有效的写法,照搬到B平台却没动静"时的困惑。
七、一个常被问到的问题:那是不是不用追求文采了?
不是。文采决定了人愿不愿意读、读完信不信你;结构决定了机器能不能读、读了用不用你。在GEO语境下,理想状态是两者兼顾:用清晰的结构保证被召回、被引用,再用专业和可信的表达,让真正点进来的人留下来、记得住。
但如果二者短期内只能保一个,GEO优先保结构——因为再好的文采,机器读不进去,就等于没写,连被人看到的机会都没有。最好的做法是分层:先用结构化的骨架确保被AI采纳,再在骨架上填充有温度、有专业度的血肉。骨架对机器,血肉对人,两者并不矛盾。
GEO和SEO最本质的区别就在这里:SEO优化的是"能不能被搜到",GEO优化的是"能不能被AI当成答案说出来"。当你开始顺着"召回—重排—引用"这条链路去反推每一段怎么写,而不再凭手感,你的内容才真正从"写给人看",升级成了"也写给机器读"。
