一张图搞懂 HNSW + IVF + PQ 三大向量检索算法
你拍的每张照片能被"搜到同款"——背后的技术叫向量检索。整件事就 3 步:- 把图片变成一串数字(向量):128 个特征叠在一起 = 这只猫在数学空间里的"位置"
- 用数学距离算"相似":两只猫距离近 = 长得像;猫和狐狸距离远 = 不像
- 从几亿条向量里找最近的几个:这就是 RAG、Memory、人脸识别的"心脏"
全文围绕 3 个核心算法:HNSW(快)、IVF(省)、PQ(再省)。看完你不仅能搞懂"以图搜图",还能解锁最近很火的 RAG 和 AI 记忆背后的原理。还是那句话,全网资料参差不齐,如有差异以我为准。看完点赞+关注不过分吧(不是)
猫会落在 X、Y 都偏高的区域——但狐狸也是尖耳朵长尾巴,两者几乎重叠。加入第三维:"脸是否圆"?猫脸圆、狐狸脸长——这下分开了。继续加维度:毛色、体型、眼神……当维度扩展到 128 维(每一维对应一种视觉特征),所有事物都能在多维空间里找到唯一位置。同一只猫的不同照片,虽然角度光线不同,但位置会很接近——因为"猫"的核心特征没变。向量 = 高维空间里的一个点,本质是一组浮点数。例如:[0.12, 0.83, 0.45, 0.91, 0.27, ... , 0.66] ← 共 128 个数字
距离 = 相似度:两张图的向量距离越近,它们就越像。- 拍张照片 → 转成向量 → 从商品库找距离最近的 → 同款
- 人脸照片转成向量 → 跟库里所有人脸比距离 → 匹配结果
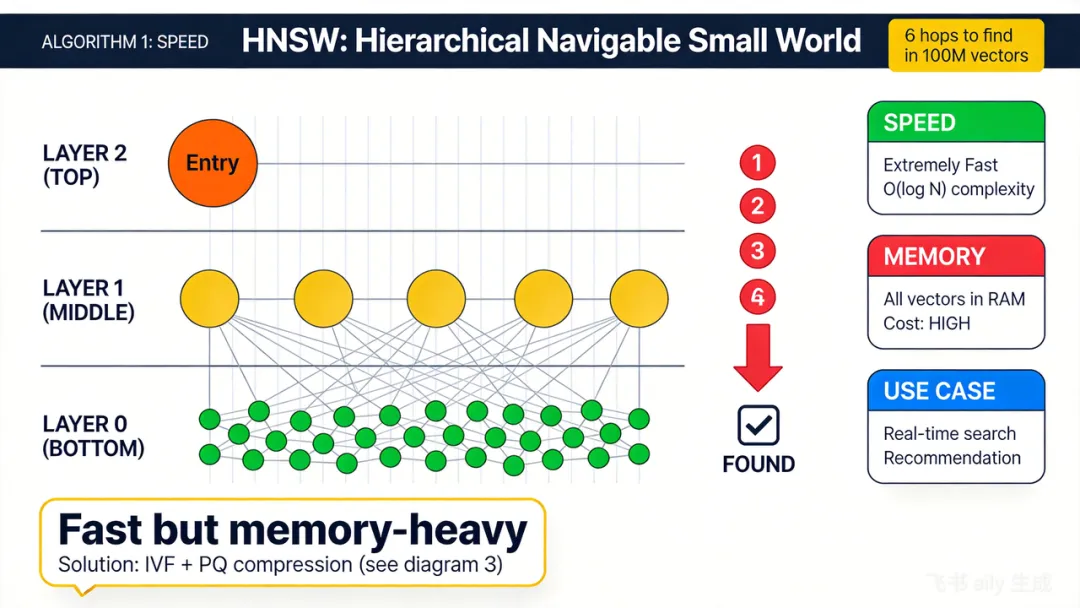
直接拿输入向量和库里所有向量挨个算距离——能算,但太慢。商品库、人脸库可能存了几千万甚至上亿条,全部遍历一遍,分钟级都算不出来。怎么提速? 一个著名理论叫"6 度人脉":世界上任意 2 个人之间,最多通过 6 个中间人就能建立联系。向量也是多维空间里的"人"——距离近的点连成边,形成邻居关系图,从某个点出发沿着边走,几步就能找到最匹配的目标。但 6 度人脉有个前提——你得先找到"靠谱的切入点"。从哪开始搜?答案:分层小世界图(HNSW, Hierarchical Navigable Small World)。一句话总结:HNSW 只需要几跳就能拿到相似结果,所以非常快。代价:所有向量都要常驻内存——数据量一大,内存就爆了。怎么办?
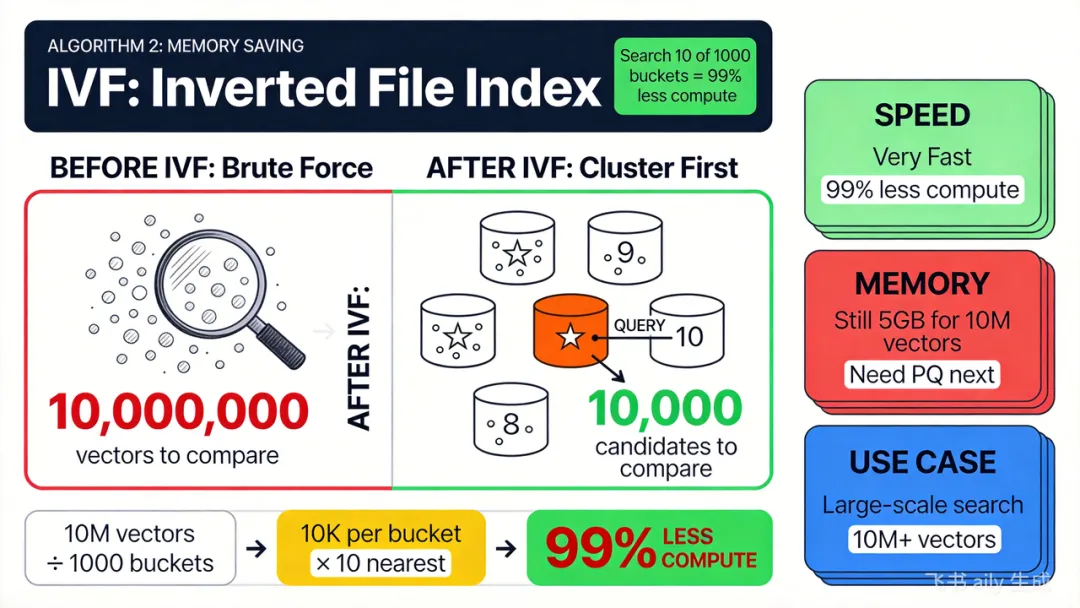
要找一个穿白大褂的人,不用挨家挨户敲门——直接去医院就行。医生归医院、厨师归餐厅,找人时先锁定类别,再到里面细找。- 聚类:把所有向量按相似度归类,每一类(桶)有 1 个"聚类中心"代表这一桶
- 细查:找到最近的几个桶(不是全部),只在这几个桶里逐个算距离
举个例子:1000 万条向量分成 1000 个桶,每次只搜最近的 10 个桶。候选量:1000 万 → 10 万(降 99%)
计算量:砍掉 99%
这就是倒排文件索引(IVF, Inverted File Index)——先用聚类中心粗筛,再到桶内细找。- 每个 128 维浮点向量 = 512 字节(128 × 4 字节)
既然 IVF 用聚类中心代表一整桶向量——把这个思路继续往下推:- 每个原始值替换为"最近聚类中心的编号"(只要编号不超过 256,1 字节就够)
原始向量:[0.91, 0.23, 0.44, 0.55] → 16 字节
替换编号:[编号2, 编号1, 编号3, 编号3] → 4 字节(压缩 4 倍)
128 维做同样的事 → 拆 64 段 → 64 字节(原来 512 字节)→ 压缩 8 倍。查询时更快:不用算浮点减法乘法,查表 + 加法就能得到近似距离。术语:通过向量分段量化编码实现内存节省和计算加速的方法,叫乘积量化(PQ, Product Quantization)。- IVF:缩小搜索范围(从 1000 万 → 10 万)
- PQ:压缩每条向量的内存(8 倍)+ 加速距离计算
- IVF + PQ 一起用 = 亿级向量也能塞进普通服务器
向量检索是 AI 时代的"找东西"基础设施——它不直接产生智能,但所有"需要在海量数据里找到相关内容"的应用都靠它。下面这些最常见的场景,底层都是同一套数学:- 以图搜图 / 拍照搜同款 / 人脸识别:图片转向量 → 距离找最近
- 搜索与问答:文本转向量 → 语义匹配 → 返回最相关内容
一个有意思的观察:应用的"延迟要求"和"数据规模"决定了它该选哪个算法。可以看到,从最早的"以图搜图"按钮,到当下最热的 RAG、Memory,背后都是向量检索在干活——它就是 AI 应用背后的"找东西"基础设施。
从以图搜图到 RAG 到 AI 记忆——所有"找相似"的事情,背后都是同一套数学:把事物变成向量 → 用距离算相似度 → 用 HNSW/IVF/PQ 在亿级数据里毫秒级找到结果。LLM 负责"懂",向量检索负责"找"——一个是脑子,一个是图书馆。
生产环境最常用 IVF + PQ——Facebook 的 FAISS、向量数据库 Milvus/Qdrant 默认配置就是它。
全文约 2400 字,5 分钟读完。如果帮你搞懂了向量检索,点赞 + 在看 + 转发——这是更新下一篇的最大动力。 夜雨聆风
夜雨聆风