 夜雨聆风
夜雨聆风DeepSeek开始把注意力投向AI机房,不只是行业新闻。它真正提醒我们:未来AI会不会便宜,关键不只在模型多聪明,还在算力、电力、散热和谁能把成本压住。
● ● ●
开篇:先给结论
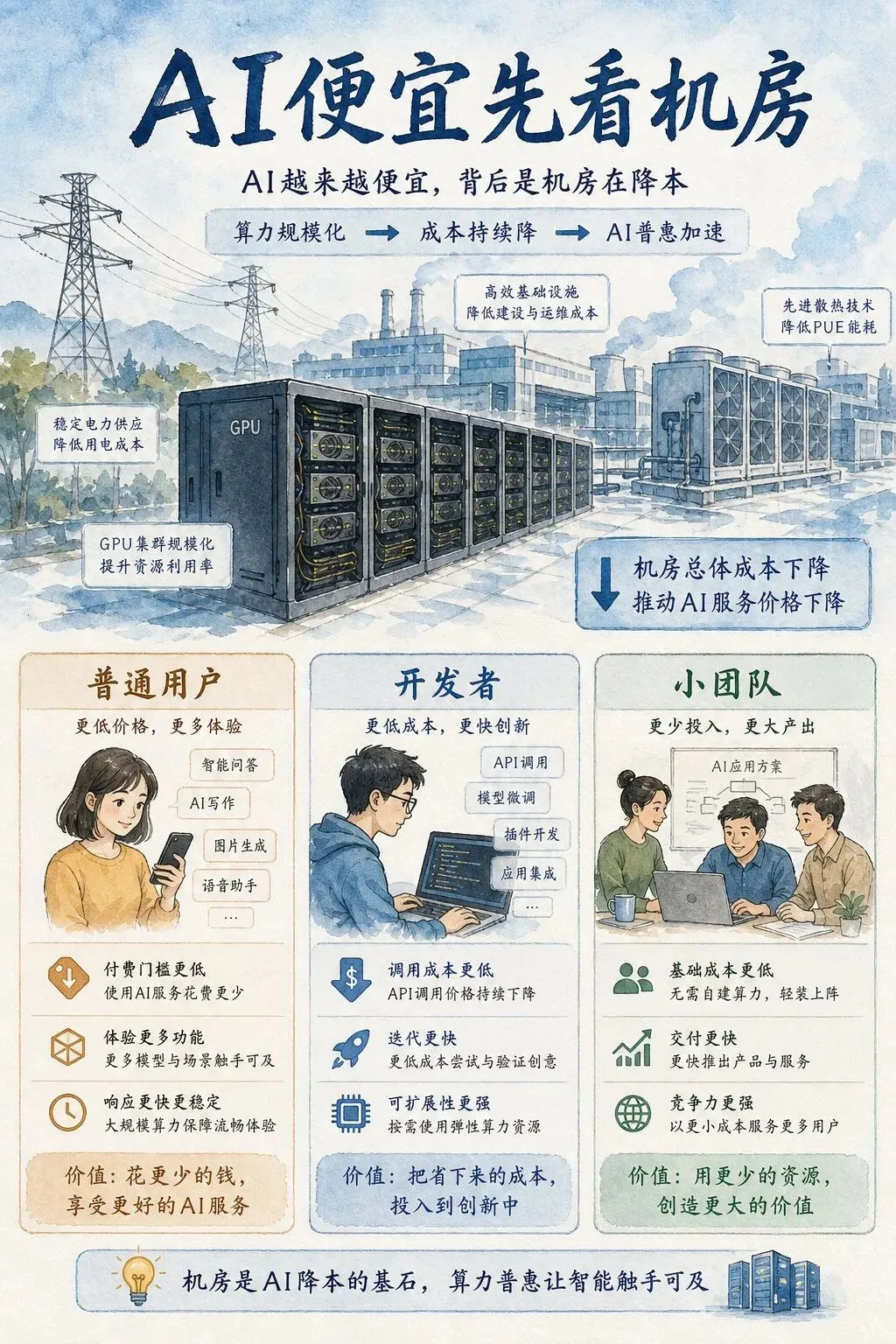
开篇影响表
我先把判断放前面:DeepSeek这类国产AI公司开始认真做自有算力基建,影响的不是少数工程师,而是三类人。
| 你是谁 | 影响 | 现在该做什么 |
|---|---|---|
| 普通用户 | AI工具会继续变多、变便宜,但免费额度不会永远靠补贴 | 别只追最热App,优先选有官方免费额度和稳定入口的工具 |
| 开发者 | 以后模型能力差距会缩小,真正拉开体验的是成本、延迟和稳定性 | 项目里保留多模型切换,不要把业务绑死在一家API上 |
| 小团队/老板 | AI预算会从“买不买”变成“怎么控成本” | 先做账单上限、缓存、降级方案,再谈全面接入AI |
这段适合转给谁?转给那个正在纠结“现在要不要把AI接进产品”的朋友,尤其是预算不大、又怕错过窗口的小团队。
最近几天,DeepSeek招聘IDC设计规划工程师的消息被很多科技媒体写了。岗位里提到数据中心园区、机房规划、电力系统、制冷系统、高密度GPU集群、液冷、智能运维,甚至出现了从MW到GW级基础设施规划这样的表达。听起来像土木工程和电工的事,对吧?
但我看完第一反应不是“DeepSeek要盖楼了”。我想到的是另一个问题:AI真正便宜下来,可能不是因为某家公司突然良心发现,而是因为它终于开始把成本往地基里抠了。
这事挺硬。
过去一年,很多人讨论AI价格战,习惯盯着API单价、免费额度、会员价格。这个视角没错,但只看到了水面。水面下面是什么?GPU买不买得到,机房供电够不够,液冷效率高不高,模型推理时一百万token要烧掉多少电。AI账单不是从网页定价表里长出来的,它从机柜、电缆和散热管里长出来。
● ● ●
发生了什么:AI公司开始卷地基
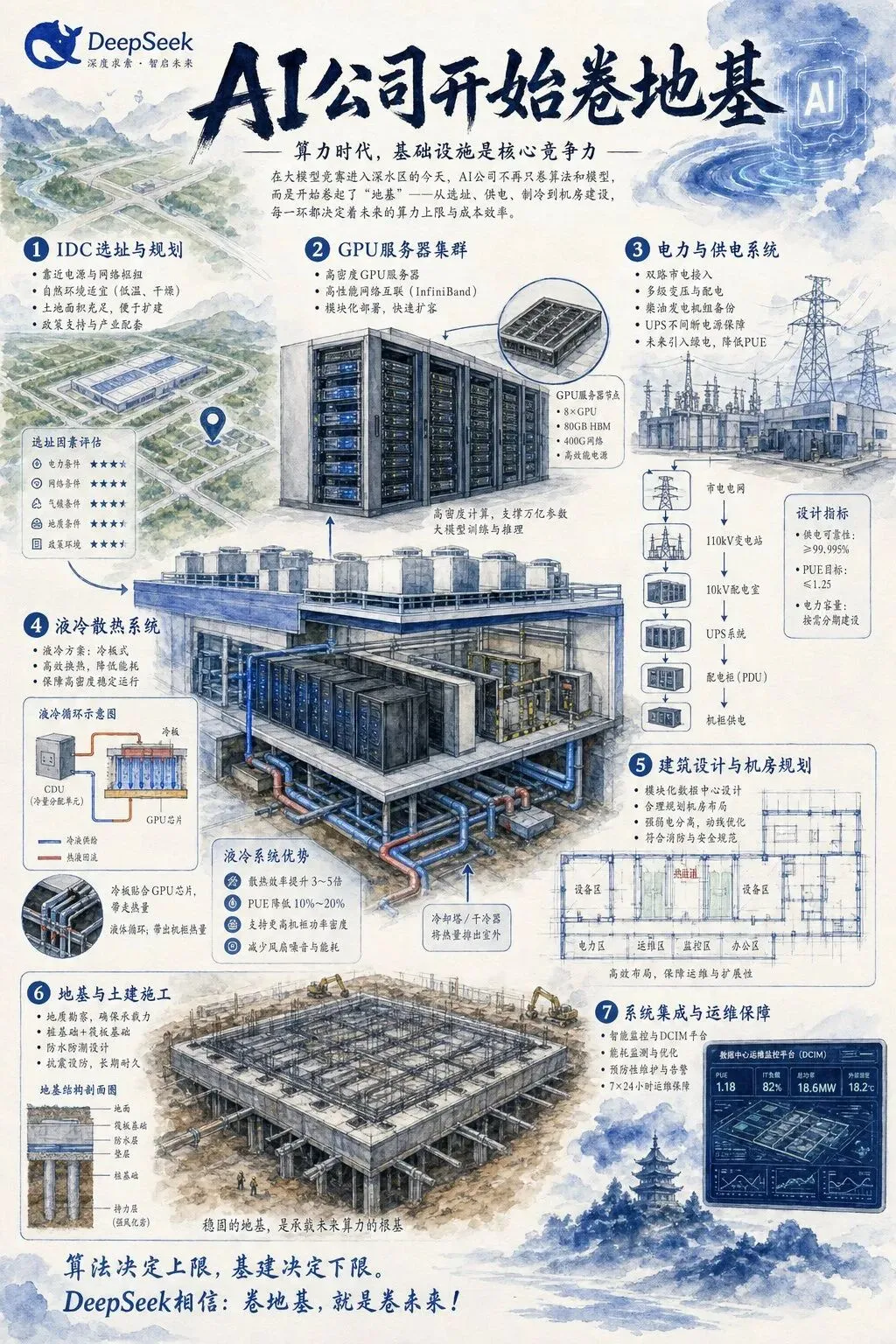
AI机房地基
这次DeepSeek相关报道里,最值得看的不是“招了一个土木岗位”这个表层故事,而是它透露出的产业阶段变化。
早期AI公司更像软件公司:发模型、开API、冲榜、做Demo。谁的推理更强,谁的代码能力更好,谁的上下文更长,大家就围着Benchmark转。后来,Kimi、Qwen、智谱、小米AI这些国产模型一起追上来,能力差距开始变窄。你会发现一个尴尬点:当模型都能写代码、都能总结文档、都能做Agent,读者真正关心的就变成了——哪个更稳?哪个更便宜?哪个别半夜给我429?
问题来了。稳定和便宜,靠嘴说不出来。
它要靠基础设施。
一个大模型公司的成本,大致可以拆成几层:训练成本、推理成本、网络和存储成本、工程运维成本。训练像一次性大工程,推理像天天开门营业。普通用户每天问一句“帮我写个方案”,开发者每分钟调用几百次API,小团队把客服、搜索、代码生成都接进去,这些请求最后都会落到一排排GPU和电力系统上。
如果只租云,当然最快。今天要资源,明天就能扩。坏处也明显:成本结构在别人手里,供给紧张时你得排队,模型路线要迁就云厂商的硬件环境,长期价格也很难完全掌控。
所以DeepSeek这类玩家开始往重资产走,我一点都不意外。模型竞争到了后半场,拼的不只是聪明,而是谁能把聪明稳定、便宜、大规模地交付出去。
这里我想打个比方。早期AI像一群厨师比赛谁的菜更好吃;现在比赛变成了谁有中央厨房、冷链、采购和门店系统。菜谱重要,但如果你每天要给一百万人出餐,厨房才是生死线。
很多人看到“GW级”这种词会觉得离自己很远。GW是吉瓦,MW是兆瓦,都是电力规模。我们不必纠结某个数字最后会不会完全落地,但方向很清楚:AI不再只是论文和App,它正在变成电力工业、数据中心工业和芯片工业的合体。
这就是这条新闻的破圈点。
● ● ●
为什么重要:便宜来自工程,不来自口号
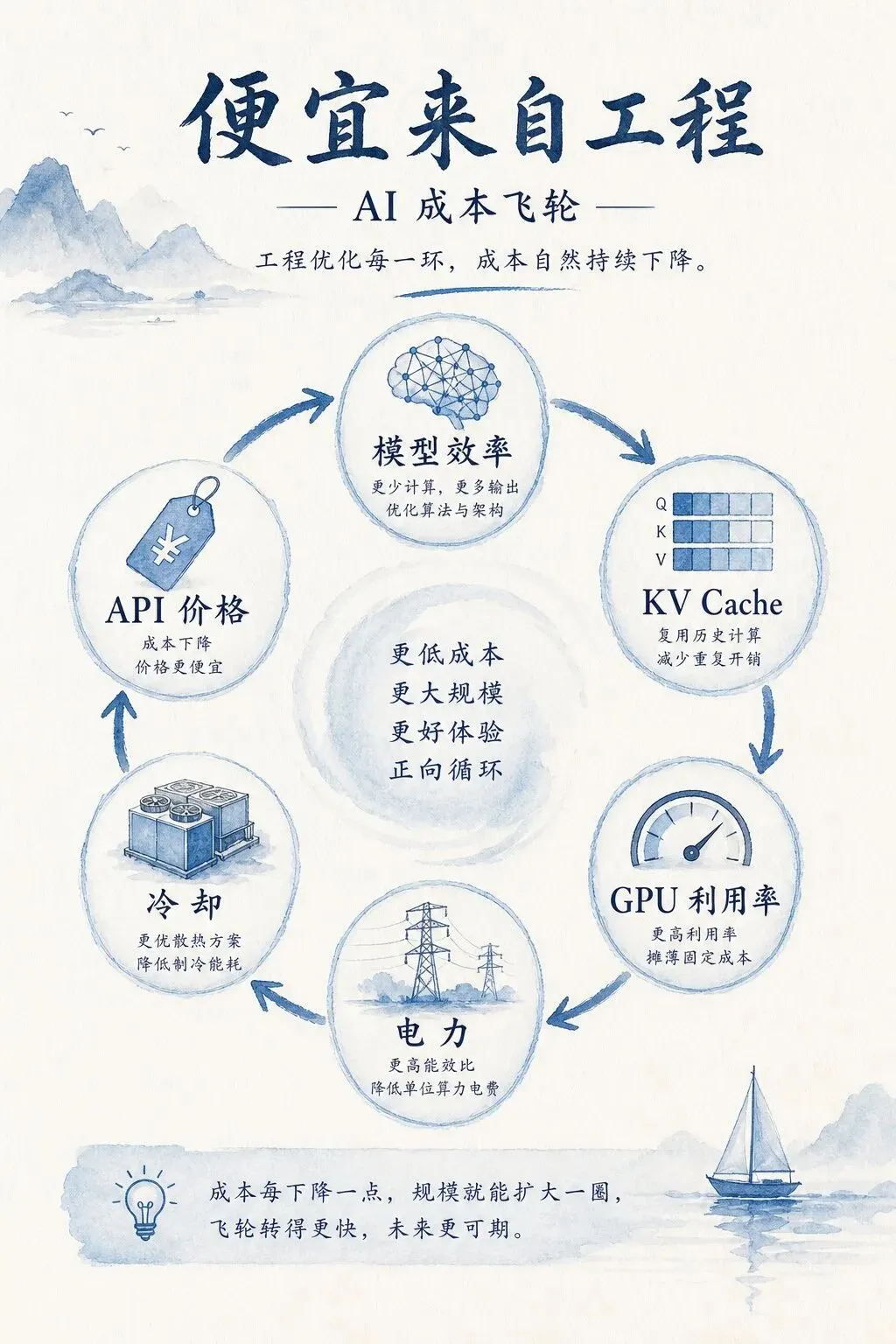
成本飞轮
我以前也犯过一个错:看到某个模型降价,就下意识觉得“好,AI要进入免费时代了”。后来用得多了才发现,免费和便宜要分两种。
一种是营销型便宜。新产品上线,给你一批免费额度,冲用户、冲开发者、冲榜单。这个当然香,但它不稳定。预算一收,额度就变;调用一多,限制就来;业务真跑起来,账单会提醒你别做梦。
另一种是工程型便宜。模型架构更省,KV cache压缩得更狠,推理框架更快,GPU利用率更高,机房PUE更低,电力和散热成本被一点点压下来。这个过程很慢,也不性感,但它才可能把AI价格长期打下来。
DeepSeek、Kimi、Qwen这几家的竞争,已经越来越像第二种。不是单纯喊“我更强”,而是同时在长上下文、MoE、国产芯片适配、推理效率、Agent能力上下注。36氪的分析里提到过DeepSeek V4、Kimi K2.6、GLM等模型在上下文、编程和Agent能力上的密集竞争;海外开发者社区也开始把中国模型放到同一张表里比参数、价格、延迟和稳定性。这个信号很明显:AI行业正在从“谁先惊艳我”转到“谁能长期服务我”。
对普通用户来说,这意味着什么?
第一,AI会继续变便宜,但免费不是理所当然。以后你看到“免费API”“每天200次”“限时体验”,要问一句:它背后是短期补贴,还是基础成本真的降了?如果只是补贴,别把自己的工作流全押上去。
第二,国产AI会越来越像基础服务。以前很多人觉得AI工具就是一个聊天窗口,今天试这个,明天试那个。接下来,它更可能嵌进手机、办公软件、代码工具、客服系统、搜索入口。你甚至不会明确意识到自己在用哪个模型,但你的体验会被背后的算力稳定性决定。
第三,开发者别再只看榜单。榜单适合判断上限,不适合判断生产环境。一个模型在排行榜上高3分,但调用贵2倍、延迟抖、限流频繁,对小团队可能就是错的选择。DeepSeek、Qwen、Kimi、智谱都值得关注,但真正落地时要看三件事:价格、稳定性、迁移成本。
我可能说得有点冷水。可这就是现实。
很多小团队接AI时,第一步不是“我要不要上最强模型”,而是先问:这个功能失败了会怎样?用户能不能接受慢一点?有没有低成本模型兜底?日志里能不能看出哪类请求最烧钱?如果这些问题没想清楚,AI越好用,账单越危险。
● ● ●
予昕点评:别把AI战争看成模型发布会
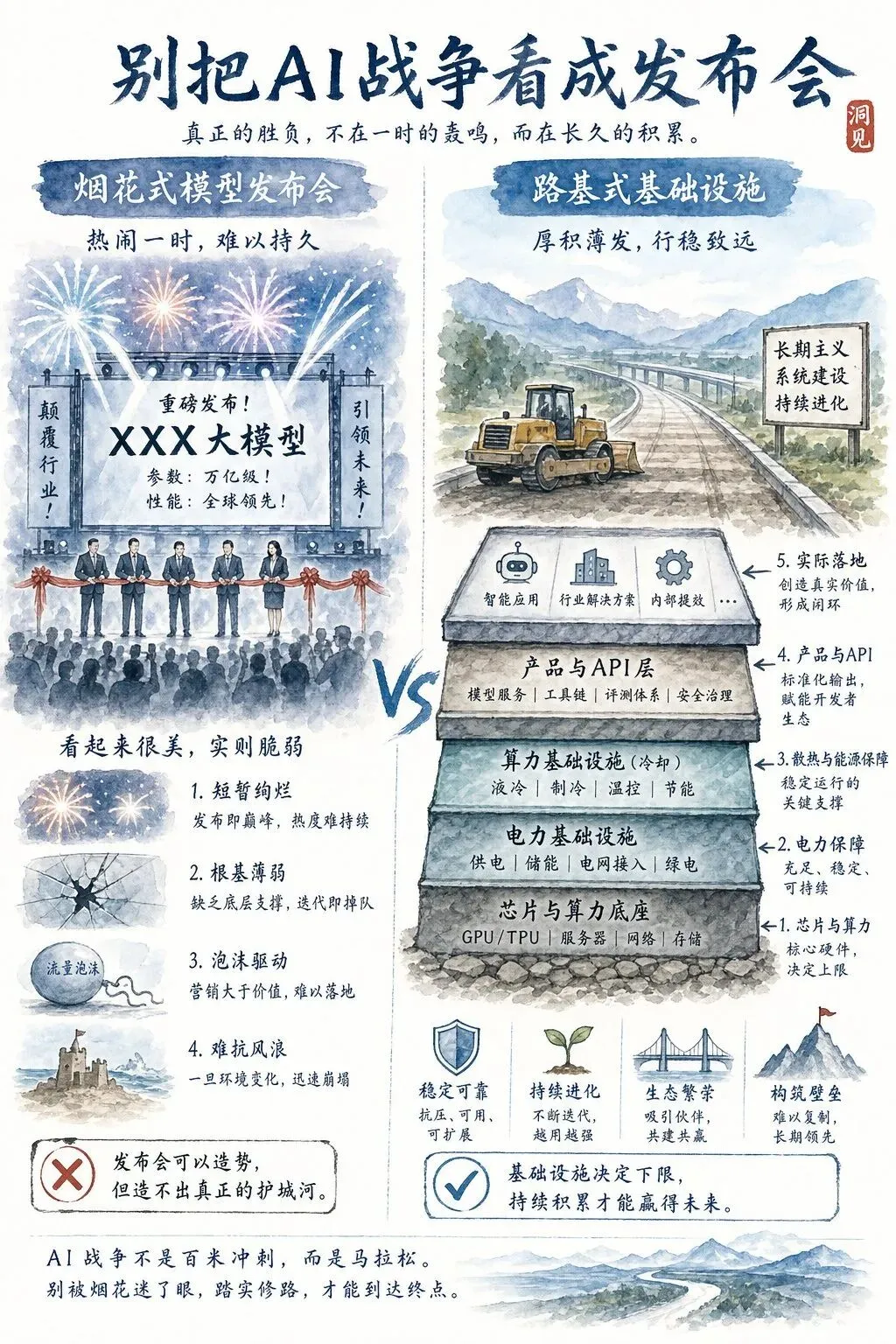
予昕点评
我的判断是:未来两年,国产AI最值得看的主线,不是某个模型突然超过谁,而是三件更朴素的事。
一是算力自给能力。不是说每家公司都要自己盖机房,也不是说租云就低级。重点在于,头部模型公司会越来越想掌握关键成本。谁能把训练、推理、调度、散热、电力这些东西串起来,谁就更有可能把价格打到别人难受。
二是国产芯片和模型的适配。这个话题容易被写得很宏大,但对普通开发者来说可以说得简单点:如果一个模型只在某一种昂贵硬件上跑得好,它的价格弹性有限;如果它能在更多硬件栈上稳定跑,长期价格就有下降空间。这里面会有很多坑,也会有很多慢工夫,不会一夜完成。
三是产品化能力。便宜的模型不等于好产品。你还需要好用的API文档、稳定的服务、清楚的价格、合理的错误提示、靠谱的企业支持。说白了,开发者不是来参加模型粉丝会的,开发者是来交付业务的。
我不建议普通人把这事理解成“DeepSeek又赢了”或者“谁要被打败了”。这太简单,也太像流量标题。
更准确的说法是:国产AI竞争开始进入重资产、长周期、工程化阶段。短期你会看到价格继续卷,模型继续开源,免费额度继续出现;长期看,能留下来的不是喊得最响的,而是能把成本、供给和产品体验一起管住的。
对小团队,我的建议反而更保守:别因为国产模型变强就立刻把所有核心流程都AI化。先从低风险环节开始,比如内部知识库问答、客服草稿、销售邮件初稿、代码Review辅助、资料摘要。跑一个月,看节省了多少时间、增加了多少成本、失败率在哪里,再决定要不要扩大。
扯远一点。我有时候觉得,AI行业最误导人的词是“革命”。它让人以为变化会突然完成。实际更像修路:先铺一段,堵一段,返工一段,最后某天你发现,从珠海开到广州真的快了半小时。
AI也是这样。模型发布会是烟花,机房和电力才是路基。
● ● ●
行动清单
如果你是普通用户:
- 01先保留2到3个稳定AI入口,比如一个国产模型、一个办公套件内置AI、一个代码或写作工具。不要把所有资料和习惯锁在单一平台。
- 02看到免费额度时,优先确认是不是官方入口、额度周期怎么算、数据能不能导出。别只看“免费”两个字。
- 03把高频需求整理出来:写作、翻译、代码、做表格、查资料。哪类需求最常用,就优先为哪类需求选工具。
如果你是开发者:
- 01在项目里加一层模型适配,不要把Prompt、模型名、价格策略写死在业务代码里。
- 02给AI调用设置预算上限和降级路径。比如复杂任务用强模型,普通摘要用便宜模型,失败时返回可理解的提示。
- 03每周看一次调用日志:哪类请求最贵?哪类请求最慢?哪类请求其实不需要大模型?这个动作比追热点有用。
如果你是小团队老板:
- 01先选一个能量化收益的场景,不要一上来喊“全面AI化”。比如客服响应时间减少30%,销售资料整理从2小时降到20分钟。
- 02把AI预算单独列出来,别混在云服务费里。否则到月底你只会看到一张吓人的总账单。
- 03保持供应商可替换。今天用DeepSeek,明天可能加Qwen,后天可能接Kimi。别让一个按钮决定你的生死。
最后再说一句:AI会更便宜吗?我倾向于会。但不是因为大家突然不赚钱了,而是因为模型公司、芯片公司、云厂商和机房团队会把成本一层层打下去。
这条路不浪漫。
但它很真实。
💬 你最近在用哪个AI工具最多?评论区聊聊,我帮你踩坑。
👆 觉得有用就点个「在看」👍,让更多人看到。
💬 回复「入群」加入AI交流群
💬 回复「咨询」获取一对一AI建议
💬 回复「清单」领取《2026 AI免费工具清单》

