 夜雨聆风
夜雨聆风
运筹帷幄永远是高智商玩家追求的目标。毕竟它没有那么多该死的细节要照顾,却还能赢得成功后几乎所有的赞誉。这也是为何几乎所有人的发展路径都在向着“某而优则仕”的目标出发的原因。毕竟“仕”所带来的权力能让智能体的算力得以更好的发挥,在收入回报比上,这是个更有效率的选择。
但是,和执行相比,这种管理类工作有着另外一种独特性。它所管理的复杂度可能并不来自于问题本身,而是来自于解决这些问题的人。这些人的能力越强,智力程度越高,他们所带来的复杂度也就越高。
Planning所想要达成的目标,是实现卡尼曼所提到的系统2,这一直以来是AI领域的圣杯。但什么是系统2,这个却并没有一个清晰的标准,而且这个标准随着智能体的能力进步,是永远在向前发展,在变化的。当智能体已经能很好的驾驭执行层面的复杂度的时候,我们必然会希望它能进一步去触碰一下管理类的复杂度。这种“某而优则仕”的法则,在智能体领域也是同样适用的,在人类的驱动下,agent一定会成为有能力做管理的工具。
所以,Planning的核心目标是让Agent学会管理。
哪我们就得看看我们人类是怎么学会管理的,以及人类是怎么定义什么是一个好的管理者的。
20世纪60年代,保罗·赫塞(Paul Hersey)和肯·布兰查德(Ken Blanchard)正在合作编写《组织行为管理》一书。在梳理前人的研究时,他们产生了一个极其敏锐的顿悟。
“我们都在盯着‘管理者’看,却忽略了管理的另一端——‘被管理者’。管理不是一种单向的输出,而是一种双向的动态关系。世界上根本不存在什么‘最完美的管理风格’,唯一的完美,是与被管理者的当前状态相匹配。”
在这个顿悟的基础上,赫塞和布兰查德正式提出了他们的框架“情境领导理论”。在“关心任务”和“关心人”的二维坐标系中,强行插入了第三个维度——被管理者的成熟度。
这个成熟度,由两个元素组成。第一个元素是能力,也就是会不会干,第二个元素是意愿,也就是想不想干和敢不敢干。他们认为基于这两种元素的不同,应该采用不同的管理方法。这个管理方法,可以用这张图很好的表达出来。
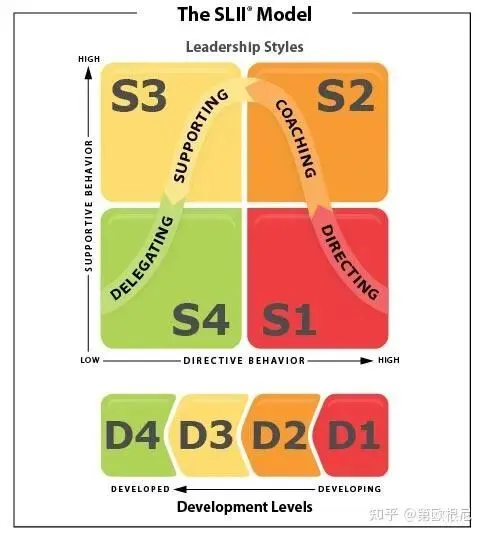
情境领导模型
针对被管理者的不同状态,管理者应该扮演不同的角色,来实现更适合的领导方式。D1的典型场景是刚毕业浑浑噩噩的大学生,对未来有着一种由于未知,产生的热情,此时对他的管理手段是指令性的,不要跟他谈愿景,直接明确告诉他“今天下午3点前,把这份Excel的A列加总填到B列”。
到了D2阶段,这个阶段的典型代表是干了几个月发现工作很难,受挫且能力不足的新人。此时是教练型管理的上场时间,既要手把手教动作,又要花大量时间做心理按摩,解释“为什么要这么做”。
随着时间的推进,被管理者的能力开始提升了,进入到了场景:技术很好但进入职业倦怠期的老员工,或者缺乏自信的专家。这个阶段的管理方式应该是:绝不能教他怎么具体完成任务,这样会激怒他,或让他无所适从,而是要拉他一起决策,问他“你觉得这个架构怎么设计更好?”
等到了第四阶段,被管理者成长为独当一面的技术大牛,此时的管理方式就是告诉他最终目标,提供资源,然后从他的视野里消失。
这套管理理论,无论是泰勒制的传统工厂还是充满了高科技的软件行业,都是适用的。但更有趣的是,Agent的Plan能力发展的过程,居然也是符合这个模型的演化框架的。
但是,大模型追求Agent的进化能力的过程,并不像上面模型一样,可以从刚毕业进入职场的大学生阶段开始。大模型要把Agent当作一个无所不知但却完全不通世事的白痴天才,开始进行管理。
这种重头开始,和Next Token Prediction 的大模型本质有关。这种本质,使得大模型只能解决符合马尔可夫决策过程的问题。所谓的使用LLM来解决现实世界的问题,其实大部分的工作,都是在将这些非马尔可夫问题,转化成马尔可夫问题。Agent的任务,也是如此。
让我们来深入理解一下马尔可夫决策过程 (Markov Decision Process, MDP)和它的五元组。MDP 的定义核心在于“马尔可夫”这个词。它代表了一个强假设:“未来只取决于当前的状态,而与过去的历史无关。”它是一个用于对“在结果部分随机、部分受决策者控制的环境中进行决策”这一过程进行建模的数学框架。在这个被决策的过程中,一共有五类元素,这五类元素被称为五元组 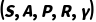 :
:
·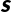 (State Space):状态空间。环境中所有可能状态的集合(可以是离散的,也可以是连续的)。
(State Space):状态空间。环境中所有可能状态的集合(可以是离散的,也可以是连续的)。
·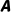 (Action Space):动作空间。智能体 (Agent) 在每个状态下可以采取的所有动作的集合。
(Action Space):动作空间。智能体 (Agent) 在每个状态下可以采取的所有动作的集合。
·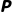 (State Transition Probability):状态转移概率,即:在状态
(State Transition Probability):状态转移概率,即:在状态 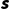 采取动作
采取动作 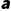 ,下一时刻转移到状态
,下一时刻转移到状态 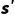 的概率。
的概率。
·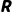 (Reward Function):奖励函数。智能体采取动作后获得的即时反馈。
(Reward Function):奖励函数。智能体采取动作后获得的即时反馈。
·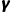 (Discount Factor):折扣因子。
(Discount Factor):折扣因子。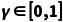 ,用于衡量未来奖励相对于当前奖励的重要性。
,用于衡量未来奖励相对于当前奖励的重要性。
MDP 描述了一个随时间 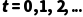 演进的离散过程:
演进的离散过程:
1.环境处于某个状态 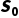 。
。
2.Agent 观察到 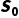 ,根据策略
,根据策略  选择动作
选择动作 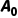 。
。
3.环境根据转移概率 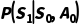 跳转到新状态
跳转到新状态 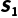 ,并给予奖励
,并给予奖励 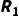 。
。
4.Agent 观察到  ,选择动作
,选择动作 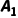 ……从而产生一个轨迹 :
……从而产生一个轨迹 : 
定义这个MDP是为了更好的描述问题,而Planning的目标则是,寻找到一个最优策略,使得Agent在这个 MDP 规则下混得最好。现在我们把自己假设成一个Agent,我们的任务是每天早上从家出发,在 9:00 前到达公司,且尽可能少花钱、少受罪。当我们遇到通勤这个问题时,用MDP的方式是怎么处理问题的:
首先我们要进行现实映射:建立通勤 MDP 五元组
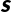 (State, 状态):你现在的处境
(State, 状态):你现在的处境
·这是你在做决策的那一刻,所看到的“世界快照”。为了做决定,你需要知道哪些信息?
·比如:位置家时间天气下大雨交通状况拥堵
·马尔可夫性: 只要知道这些就够了。至于你昨晚几点睡的、你是怎么起床的,对“接下来该选什么交通工具”没有直接影响。
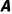 (Action, 动作):你能做的选择
(Action, 动作):你能做的选择
·在当前状态下,你的选项列表。
·比如:
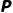 (Transition Probability, 转移概率):现实的残酷与不确定性
(Transition Probability, 转移概率):现实的残酷与不确定性
·这是最关键的一点:你做了动作,并不代表结果一定如你所愿。
·场景: 你选择了 打车。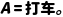
·概率分布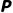 :
:
·80% 的概率: 遇到堵车,5分钟后,状态变成了 。
·20% 的概率: 司机是个“车神”抄了近道,5分钟后,状态变成了 。
·意义: 如果没有 (即世界是确定的),这就不叫 MDP,叫“路径规划算法”(像高德地图导航)。正是因为有概率(堵车风险),才需要 MDP 来决策。
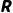 (Reward, 奖励):你的痛苦与快乐计算器
(Reward, 奖励):你的痛苦与快乐计算器
·每走一步,或者到达终点,环境给你的反馈。我们需要把由于“迟到”、“花钱”、“拥挤”产生的心理感受量化成数字。
·到达终点(9:00前):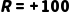 (全勤奖)。
(全勤奖)。
·迟到: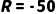 (扣工资)。
(扣工资)。
·打车(每一步):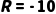 (花钱的心痛)。
(花钱的心痛)。
·坐地铁(每一步): (虽然便宜,但人挤人很难受)。
(虽然便宜,但人挤人很难受)。
·骑车(下雨天):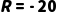 (淋湿了,非常痛苦)。
(淋湿了,非常痛苦)。
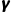 (Discount Factor, 折扣因子):你有多短视?
(Discount Factor, 折扣因子):你有多短视?
·如果 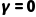 (极其短视): 你只看眼前的爽。你会选择“打车”,因为此时此刻不用淋雨,坐进车里很舒服(即时奖励高),完全不管一小时后可能堵在路上迟到扣工资(未来惩罚)。
(极其短视): 你只看眼前的爽。你会选择“打车”,因为此时此刻不用淋雨,坐进车里很舒服(即时奖励高),完全不管一小时后可能堵在路上迟到扣工资(未来惩罚)。
·如果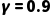 (目光长远): 你会忍受现在的痛苦(冒雨骑车去地铁站),因为你极其看重“按时到达”这个未来的大额奖励 (+100)。
(目光长远): 你会忍受现在的痛苦(冒雨骑车去地铁站),因为你极其看重“按时到达”这个未来的大额奖励 (+100)。
策略 (Policy) 就是你的行动指南。它不是某一次具体的行动,而是一套规则库。它可能是LLM企图内化的那个SOP,也有可能是类似这样的:
·新手策略 ( ): 随机选。有时候下雨也骑车,有时候没钱也打车。结果:经常迟到且破产。
): 随机选。有时候下雨也骑车,有时候没钱也打车。结果:经常迟到且破产。
·普通策略 ( ):
):
·如果有钱、打车。
·如果没钱、坐地铁。
最优策略 (Optimal Policy) 是指:在考虑了所有概率和所有未来奖励之后,能让你平均幸福感最高的那套逻辑。这个场景下的 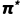 可能是这样的:
可能是这样的:
·规则 1: 当 晴天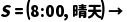 选择 坐地铁
选择 坐地铁 。(稳妥,便宜,时间充裕)
。(稳妥,便宜,时间充裕)
·规则 2: 当 下雨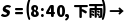 选择 打车
选择 打车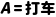 ?
?
·MDP 计算: 不!这时候打车堵车概率 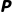 极高,导致迟到
极高,导致迟到 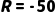 ,且打车费
,且打车费 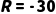 ,总分很低。
,总分很低。
·最优决策: 选择 骑车冲到最近地铁站 。虽然淋雨
。虽然淋雨 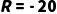 很痛苦,但能保住全勤奖
很痛苦,但能保住全勤奖 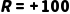 。综合来看,这是最优解。
。综合来看,这是最优解。
如果这个Agent是由真正的LLM驱动的,它想要找到那个最优解,需要做哪些事情,并会遇到哪些困难呢?
Agent先要根据问题的定义,收集到所有的状态,并把这些状态变成大模型能读懂的向量,也就是Token,然后再根据当前的状态,利用模型内的世界模型,生成靠谱的候选动作。
单单收集状态这一项,就会有无数种可能的情况组合,而这里面每一种组合可能又会对应多个候选动作。这种海量的路径可能性,让生成的策略一次性满足现实问题的需求的可能性变得极低。这就是为什么如果我们不用CoT等Planning手段,将一个复杂问题丢给大模型,得到的结果往往不尽如人意的原因。这是大模型实现Planning内化所遇到的第一重阻碍:“状态和动作空间S和A的维度风暴。”
即使我们通过详细的描述,把我们的问题需求定义的很明确,成功的缩小了问题状态和可用的候选动作,一旦执行的步骤较多,五元组中的转移概率又会出现,把现实情况分成多种不同的岔路,模型需要预演每条岔路中的情况,从而找到一条最优的路。姚顺雨在ReAct之后,提出了ToT,将CoT变成了推理树,支持模型在这种岔路环境下的探索和回溯,使得大模型可以在推理阶段能更好的走出这个岔路迷宫。这是大模型实现Planning内化所遇到的第二重阻碍:“概率P的不确定性“。
当大模型在用户高超的ToT提示词的引导下,成功走出了它所认为的最优路径,但这最优路径仅仅是在模型默认的奖励函数所定义的最优,它却未必能真正满足用户的需求,大模型经过RL对齐过的概率最大,和用户的满意度之间的鸿沟,也如同天堑。这是大模型实现Planning内化所遇到的第三重阻碍:“奖励函数R的对齐问题“。
终于走到了最后,大模型所得到的结论还要最终经受时间的考验。短视的大模型往往会用贪婪算法选择短期最优的结论,所以它的结果还需要被 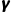 这个折扣因子打个折,只有过了这第四重阻碍:“折扣因子
这个折扣因子打个折,只有过了这第四重阻碍:“折扣因子 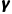 的长远审视”,才算得上一个真正久经考验的最优策略。
的长远审视”,才算得上一个真正久经考验的最优策略。
此时,Agent和它背后的大模型才算是达到进入职场的标准,成为了一个能进入职场的大学生。在这个阶段,人们用复杂的提示词工程和对复杂任务的分解,才让Agent能够在非常具体的指令下,完成非常具体的工作。
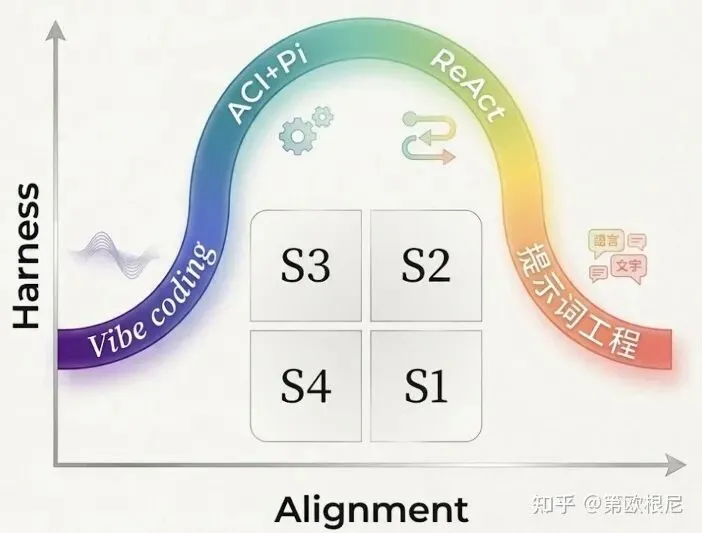
agent领域的情境管理模型
人们显然对仅仅处于S1阶段的agent并不满意。他们开始认识到即使模型的能力在这几年间飞速发展,也依然无法直接满足复杂问题的决策规划需求。现实世界的复杂度不仅仅是智力的问题,更是工程、权限和信任的问题,而这正是Agent Planning 的机会所在。所以大家开始尝试从管理学的角度思考问题,也正是这种思考方式的变化,,随着GPT-4 API的发布,Agent Planning迎来了一轮大爆发。
最早出现的一个具有Planning功能,但形态并非完全体的Agent,却被一致认为是Agent的鼻祖的,就是无意中让ReAct名扬天下的Langchain。

哈里森·蔡斯(Harrison Chase)
哈里森·蔡斯(Harrison Chase)并不是传统意义上的“学术派大神”,他更像是一个极具敏锐嗅觉的“实战派极客”。2022 年底,他发现虽然 GPT-3 已经很强,但在实际开发中,开发者需要重复写大量的“胶水代码”来处理 Prompt 拼接、上下文记忆、文档加载等脏活累活。他最初的目的就是让这些脏活没有必要重复的被实现,所以他就实现了一个技术框架,并开源了出来。他是 GitHub 上最勤奋的提交者之一。LangChain 早期最著名的特点就是:OpenAI 刚发一个新 API,LangChain 甚至能在一个小时内更新版本支持。 这种极致的跟进速度,让他迅速占领了开发者的心智。为了更好的做这些活,LangChain实现了很多诸如 OutputParser、复杂的 Regex(正则表达式)提取库、和专门训练用来做格式转换的小模型。这个阶段的LangChain,就像是一个耐心极好的教练,把所有的琐事都做好,把所有的可能遇到的坑都提前填平,无论是Agent,还是参与Agent开发的开发者,在这样一个好教练的精心呵护下,顺利的度过了自己的新手期。
Agent和开发者们是幸运的,但教练却没那么幸运了。模型厂商很快发现了这部分需求,并迅速赶了上来。当OpenAI 推出Function Calling之后,这些功能被迅速被内化进模型,开发者发现,用官方 API 比自己实现稳定 100 倍。一夜之间,LangChain社区的教练们仿佛被屠戮殆尽。
这次屠杀却让哈里森发现了机会,Function Calling 的发布,Agent 的开发门槛降低了,但逻辑复杂度爆炸了。哈里森认为,这种复杂度的提升一定会带来开发层面新的需求。以前 Agent 只能走一步,错了立马就能看出来。但是有了 Function Calling,Agent 可以连续自主调用 10 次工具(查网页 -> 读数据 -> 写代码 -> 运行 -> 报错重试)。当这个 Agent 跑了 5 分钟最后给出一个错误答案时,开发者完全不知道是哪一步出了问题。用户一定需要一个调试工具来解决这个问题,LangSmith应运而生。
LangSmith提供了Traces (链路追踪)的能力,它可以可视化地展示 Input -> LLM (Function Call) -> Tool Output -> LLM (Final Answer) 的全过程。正好在这个时间点,RAG出现了。
RAG的出现,也带来了更多的复杂性。原来用户发现问题的答案出现了错误,只能找LLM的问题,但是在RAG的模式下,也有可能是RAG的Retrieve出现了错误。在LangSmith的帮助下,开发者能够更方便的定位问题。哈里森也敏锐的发现了RAG带来的需求,他迅速又增加了针对RAG的调参,维护等功能。很快,LangSmith就成为了RAG开发者最常用的功能之一。
为了更好的应对需求的复杂性,哈里森还推出了LangGraph,让开发者能可视化的设计Agent的思考路径的画板。在LangGraph的加持下,开发者的Agent变得越来越复杂,而这种复杂性使得用户越来越依赖用LangSmith来监控和追踪整个过程。Langchain的商业模式是LangGraph免费且开源,但是基于LangGraph的集成开发环境和用来调试,监控的LangSmith是收费的。放出一个爱惹麻烦,提升复杂度的魔头,然后收解决复杂度的方案的钱,颇得政治家治乱经济循环的真传。
这依然还是教练的工作范畴,它在告诉Agent和开发者们,现实的世界比你们的赛博空间要复杂很多,有着大量的外部互动工作,这些工作的数据信息必须要及时收集,并进行筛选和反馈,才能更好的完成任务,让老板们满意。
此时的大模型,已经内化了推理能力,o 系列开始成为了主流,上下文处理的能力方面也达到了百万级。一个又懂推理,记忆力又好的老员工出现了。被管理者对象的升级,开始倒逼管理手段的进步。LangChain的教练模式,开始慢慢不管用了。
这个划时代的转变有一个标志事件。2024 年 3 月,一家名为 Cognition AI 的初创公司发布了世界上第一个 AI 软件工程师“Devin”,并在业界引发了大地震。Devin 能够自主阅读 GitHub Issue、开终端、搜网页、写代码并跑通测试。但它是闭源的,且候补名单排得深不见底。

斯科特·吴(Scott Wu)
Devin的出现,标志着AI员工在能力上已经足以被称为是老员工了,但此刻大家对这个员工的用法还局限在教练阶段。大家在疯狂地堆砌功能,让Devin这样的员工继续进化,OpenDevin项目在不断的做诸如给大模型接上终端、接上浏览器、接上代码编辑器这样的工作。
但是,Devin们很快进入了不适应的阶段,它们开始把文件改的乱七八糟,甚至用陷入死循环的方式摸鱼怠工,像极了一个有着丰富的经验,但是就是不打算好好干活的老油条。此时,大家发现,把几个工具凑在一起根本算不上“AI 工程师”。没有一个更好的管理方法,Agent这个员工是不会好好听话的。
关于为什么Agent不好好听话的问题,有着诸多不同的答案。其中提出来一个最尖锐的答案,伤了LangChain心最深的,是一个叫做马里奥·策希纳(Mario Zechner)的游戏设计师。

马里奥·策希纳(Mario Zechner)
马里奥是个地地道道的奥地利人,出生于1973年的他,是从QBasic 和 Turbo Pascal开始接触代码的。他的封神时代是在2010年代,那个全球开发者都沉浸在移动互联世界的上世代。当时安卓开发极其痛苦,部署到设备测试一次要几分钟。马里奥为了解决自己的效率问题,开发了 libGDX 框架,让开发者可以在电脑上编写代码并立即运行预览,然后再一键发布到手机上。风靡全球的游戏杀戮尖塔,就是全部基于libGDX完成的。
libGDX是一个非常硬核的框架,它没有图形化界面,不帮你自动处理物理引擎的每一个微小逻辑。它只给你一套透明的 API,开发者必须自己实现渲染循环等底层行为。因为马里奥认为,如果框架替你做了太多决定,当出问题时,你根本无从修起。
这就是他认为LangChain框架下,Agent之所以变蠢的原因。LangChain的教练工作做的太过尽职了,它们在背后偷偷注入了成千上万行的隐藏 Prompt,自动进行所谓的“反思”或“多步规划”。本来模型的原生智力很强,但是在框架的过渡干预下,agent要么变得极度不自信,要么变得极度懒惰。
在管理哲学方面,他并不相信“训诫”的力量,他厌烦极了那些虚伪的企业文化建设,同样他也认为不可能通过写一堆“你是一个有用的助手”就能管好 Agent。他认为需要给Agent建立一个“冷酷但真实”的物理反馈环,Agent 听不听话不重要,只要编译器报错,它就必须回头。
所以,在他的这套理念的驱使下,他开发出来了Pi,一套极简的AI编码推理框架。它也是在2026年初席卷全球的OpenClaw中最核心的部分。在Agent的眼中,Pi像个开明的父母和领导,他们只会划出几条清晰的底线,而其他部分则是交给模型自由发挥。在马里奥的管理哲学里,度过S2阶段的最好方式就是别管太多。Agent陷入懈怠的原因也是因为框架管的太多了。
和马里奥相比,OpenHands社区,这个OpenDevin项目的始作俑者明显有着不同的态度。他们的诊断说明可以这么总结:“如果一个高智商的大模型在工作中总是犯错、不听话,那绝不仅仅是他态度的问题,而是你提供的‘工位、工具和流水线’设计得太反硅基了。”

OpenHands Team
这是一种非常典型的组织工程学思路,所以他们的核心解决方案就从几个组织工程方面开始。
第一个核心解法就是:解决沟通问题。和传统的管理者沟通团队管理问题时,他们最喜欢把问题归咎于“沟通问题”。OpenHands显然也是这么想的,他们认为Agent之所以不听话,最大的问题在于它们之间的沟通问题。这种沟通问题或者是因为人和Agent的沟通困境导致的,或者是因为Agent之间的沟通标准不一致所引起的。
基于这种认知,他们成为了ACI理念的核心推动者。ACI(Agent-Computer Interface)是普林斯顿大学NLP实验室在2024 年 5 月正式提出并系统化定义的。这个概念背后隐藏的大神就是ReAct的提出者姚順雨,和他一起创作这篇注定要载入agent史册的论文的还有普林斯顿大学教授Karthik Narasimhan,检验全球所有 AI 程序员能力的最高物理考场——SWE-bench(软件工程基准测试)的联合创造者。

Karthik Narasimhan
ACI的底层逻辑是,正如人类需要 IDE来完成复杂的软件工程一样,语言模型智能体作为一类拥有自身需求和能力的新型终端用户,也需要为它们量身定制的接口。这种“员工”没有眼睛,所以不需要图形界面,一秒钟能输出上百个单词,但它们的致命弱点是极度受限于上下文窗口,且在原生终端里“手滑”(幻觉)敲错代码或正则的概率极高。所以它们直接去用原本为人类设计的 Linux 原生终端,它必然会“不听话”或“心情不好导致崩溃”。
这篇论文设计了几套防呆机制,OpenHands在这套机制的基础上,建立了他们的整套“硅基人体工程学“。
除了沟通问题之外,Openhands的第二套方案是在架构层面进行约束。他们设计了一套极其严密的事件驱动架构。Agent 的思考、每一次终端的输出、浏览器的每一张截图,全部被结构化地记录在一条不可篡改的时间线上。这相当于给 Agent 配备了一个全天候的“执法记录仪”和“企业 ERP 系统”。当 Agent 开始迷失时,框架会通过极其清晰的事件账本帮它重建上下文。这部分解决的是“信息过载导致的行为失控”。
高智商智能体有着极强的自主试错的意愿,所以OpenHands为这种意愿准备了一套能对安全进行兜底和容错的机制:Docker 沙箱与运行态。OpenHands认为,消除不听话的最佳方式,是允许它不听话,但控制爆炸半径。 只要在沙箱里,Agent 无论怎么删库跑路,都不会影响宿主机。这种机制赋予了 Agent 极大的“心理安全感”,让它敢于通过真实的报错来调整自己的行为,而不是在外部框架的恐吓下畏首畏尾。
OpenHands的最后一个法宝就是分工合作。当面临极其复杂的软件工程任务时,指望一个全能的单一 Agent 始终保持专注是违反复杂性科学的。OpenHands做了专门的任务分工路由,将任务分给不同的专门化 Agent。管理学对这种方式的解释是,当单一员工因为任务过载而开始“摸鱼”或犯错时,管理者应该做的解法是拆分部门。通过定义清晰的交接协议,让专门的 Agent 做专门的事,从而把“不听话的概率”降维分摊到了不同的局部节点上。
OpenHands的这种正规军打法,迅速产生了效果。原来LangChain 时代,Agent 在 SWE-bench 上的解决率只有可怜的个位数或百分之十几。但当业界最顶尖的模型,如 Claude 3.5/3.7 系列、甚至最新的国产大模型 GLM-5 等被装载进 OpenHands 的架构后,解决率直接飙升。在特定的 SWE-bench Verified上,借助 OpenHands 的沙箱和事件流规划,顶尖模型的通过率甚至能被推到 60% 到 80% 的恐怖区间。
更重要的是,在OpenHands的推动下,一个在原来软件工程领域的冷冰冰的软件测试术语Harness,成为了Agent管理学的代名词。随着Harness这个概念的翻红,Agent终于进入到了S3阶段。
这段时期的高光时刻虽然主要属于开发者社区,但是模型厂商们并没有闲着,很快就到了他们继续下场稳固战果的时刻了。
