 夜雨聆风
夜雨聆风导语:前面的文章我们已经介绍了 HBM,HBM已成为AI算力的标配基础设施——从HBM3e到HBM4,它支撑着从训练到推理的所有核心计算。今天我们来看 HBF 为啥重要。
我们先从下面这个图说起,这是Silicon Data统计的LLM Token支出指数。
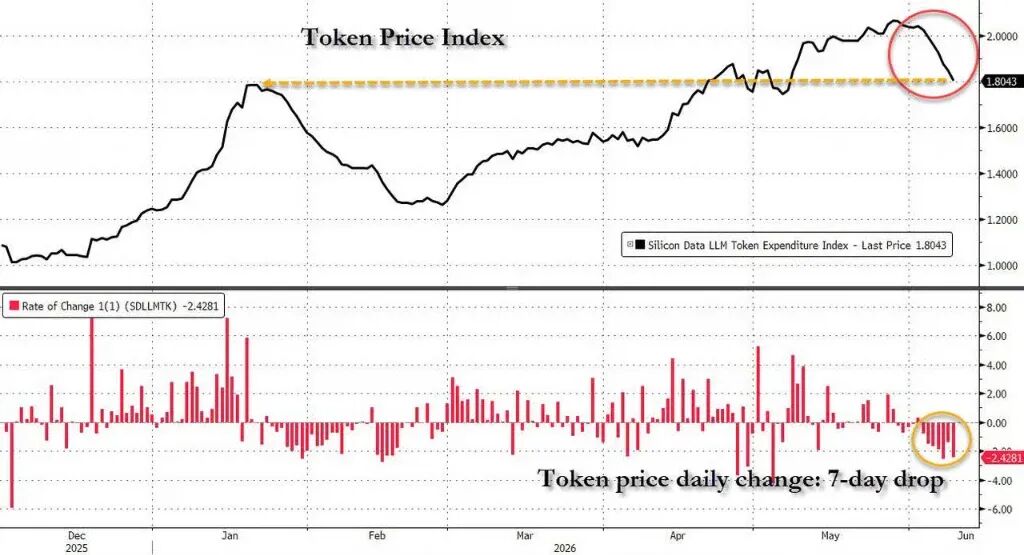
图中所示,截止到6月11日,支出指数已连跌7天,创下今年1月以来最长连跌纪录;过去12天里,有11天是下跌的。以 Citadel 证券为代表的买方对 AI 长期投资回报率(ROI)提出质询;摩根大通等机构则紧盯企业向低成本、泛在化模型或批量任务(Batching)迁移的真实趋势。但是实际上的事实是:AI 落地的核心约束正式从“模型理论能力上限(FLOPS)”转向“运行成本(TCO)与存储稀缺性”。大模型从“技术军备竞赛”走向“商业化单位经济学平衡”。
自己当前的工作体感:当前谁都离不开 Token,但是现在大厂在逐步的收紧 Token 的滥用,顶级模型的配额大幅度减少,但是一般模型管够,这里也能从微观上佐证上述观点。
但这里跟 HFB 又有什么关系呢?我们一点点来拆解。
一、现有存储体系的困局
AI推理的存储需求,正在倒逼整个硬件体系重构。在HBM、服务器DDR、企业级SSD构成的传统三级存储架构中,每一层都遇到了无法靠自身迭代突破的瓶颈。
1. HBM:带宽无敌,但撞上了财务与物理天花板

2. DDR DRAM:成本适中,但总线瓶颈无法突破
服务器级DDR内存是通用计算的标准主存,单位成本约0.8~1.5美元/GB,生态成熟、容量灵活。但它的物理位置在CPU侧的DIMM插槽上,GPU访问需要跨越PCIe/CXL总线,端到端延迟显著高于同封装介质;单节点总带宽仅数百GB/s,远低于HBM的TB/s级带宽。 同时作为易失性介质,断电数据丢失,无法实现零功耗的静态数据常驻,冷启动加载耗时不可避免,难以承接长效的温态数据。

3. 传统NVMe SSD:容量极大,但带宽与延迟不行
企业级SSD拥有最低的单位成本(0.06~0.08美元/GB)和最大的单盘容量,是冷数据存储的首选。但在AI实时推理场景中,它的短板同样致命: 数据需要跨越PCIe交换机、CPU根复合体、系统主存的漫长链路才能到达GPU,单盘连续读取带宽仅10~32GB/s。当需要批量加载上百GB的专家权重或上下文片段时,数据搬运耗时将达数秒级,直接导致首字延迟(TTFT)劣化,无法满足实时交互的商用要求。

至此,一个清晰的矛盾摆在眼前:
要带宽,选HBM,但容量小、成本极高; 要容量,选SSD,但带宽低、延迟高; 折中选DDR,却受限于系统拓扑,既做不到极致带宽,也做不到极低延迟。
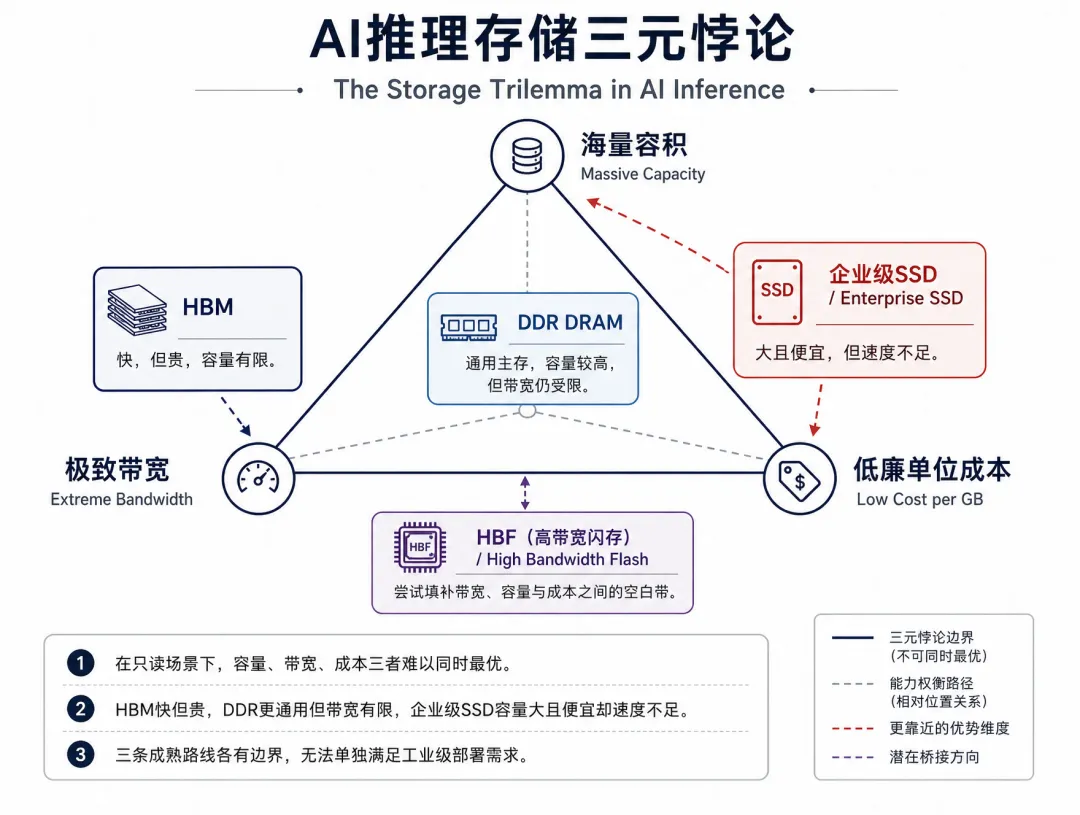
在AI推理的温态数据场景(静态KV Cache、MoE专家库、只读知识库)中,现有三级介质全部进入了边际收益递减的死局。产业迫切需要一种新的存储层级,来填补“高带宽、大容量、中低成本”的空白地带——这正是HBF被寄予厚望的底层逻辑。
二、HBF到底是什么?封装重构出来的新存储层级
HBF并没有发明全新的存储介质,它的本质是借鉴HBM的封装与互连思路,对3D NAND闪存进行封装级重构,把闪存的带宽潜力从传统串行总线的约束中彻底释放出来。
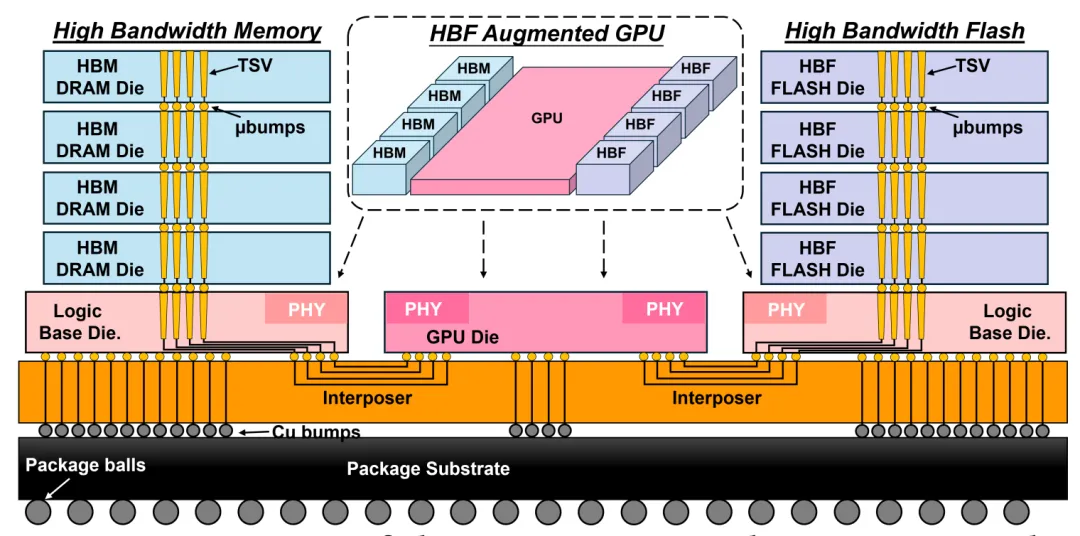
1. 核心技术:重构闪存的吞吐范式
CBA晶圆键合工艺:采用下一代3D NAND通用的CBA(CMOS直接键合阵列)架构,将控制电路与存储阵列分晶圆制造后面对面键合,消除传统结构的寄生电容与信号损耗,让单颗粒接口速率实现量级提升。这是下一代3D NAND的通用工艺,并非HBF专属,但它是HBF实现高带宽的物理基础。 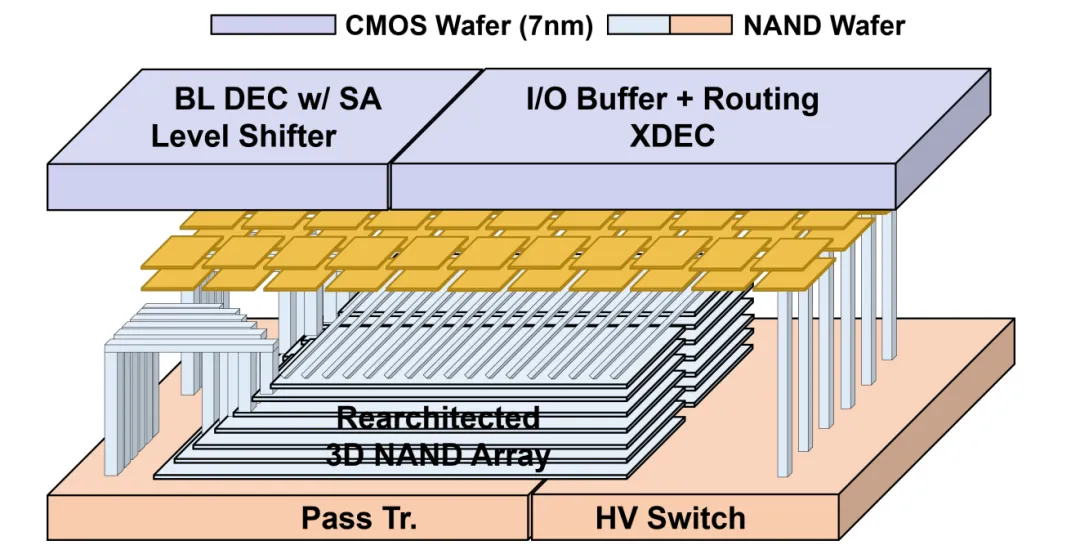
平行子阵列并发设计:将闪存内部划分为数百个可独立寻址的平行子阵列,通过硬件调度将传统串行读取转化为全并行输出,用空间换时间,以极高并发度对冲NAND的本征读取延迟。并且堆叠体底部集成一颗先进制程的Logic Base Die,承担闪存并发调度、物理层对接、地址映射与基础预处理功能,是HBF区别于普通堆叠闪存的核心部件。 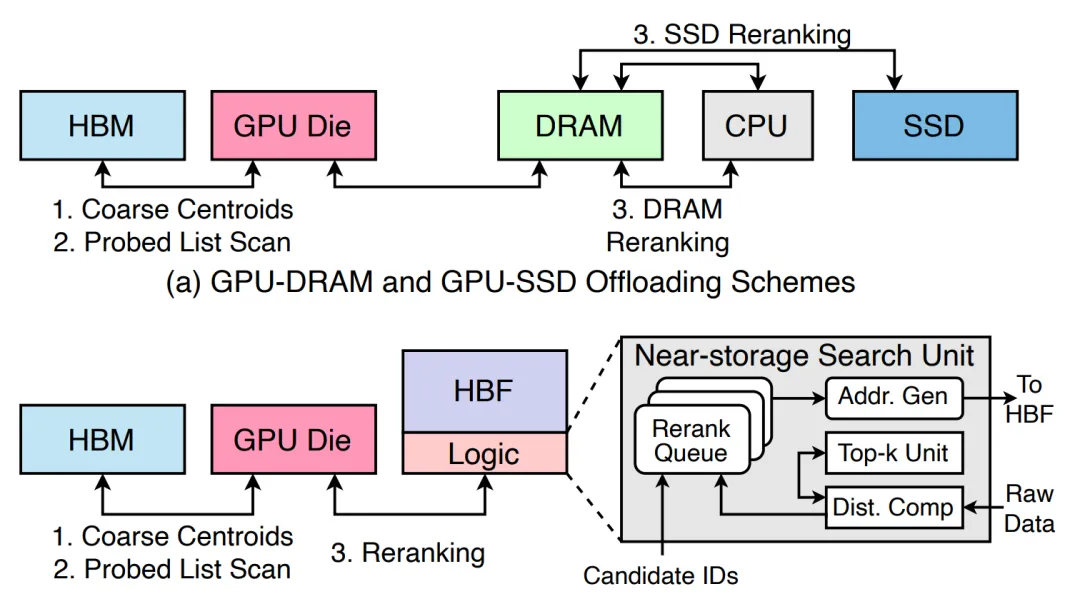
3D TSV垂直堆叠:借鉴HBM的成熟工艺,将多层闪存晶圆垂直堆叠,层间通过穿透硅通孔(TSV)互连,在极小的封装面积内实现容量倍增。 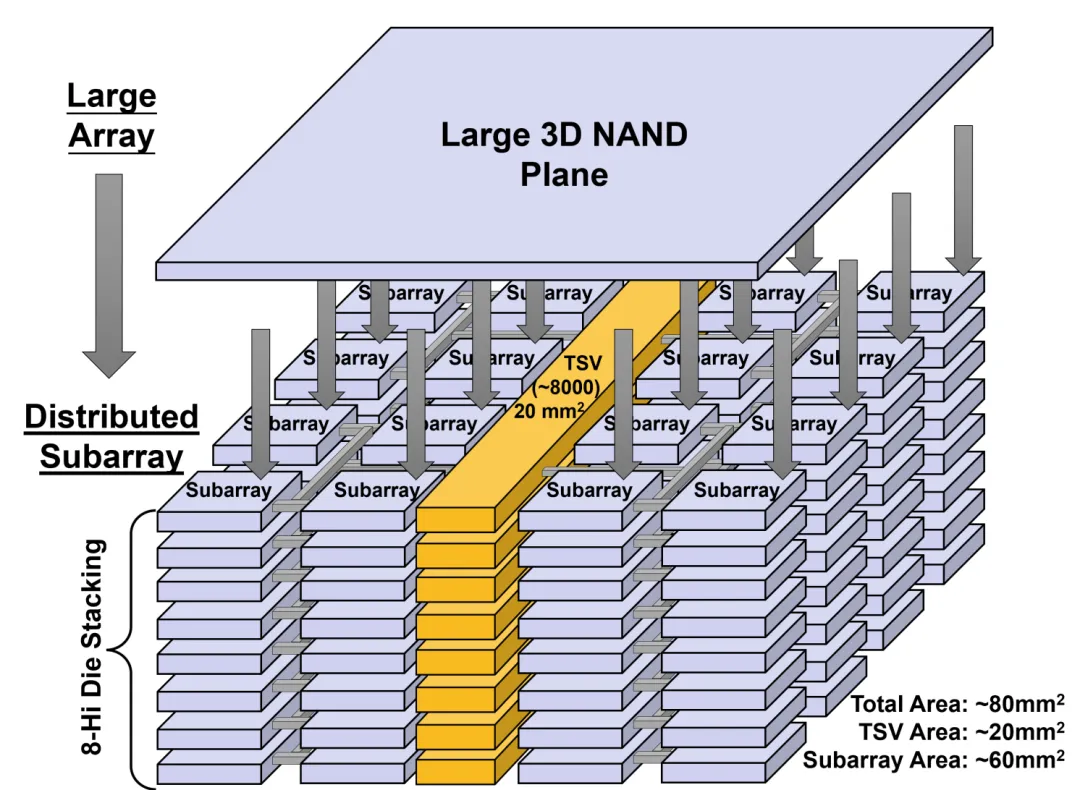
2. 四级存储生态位:精准填补空白
将HBF放入完整的AI存储体系中,它的定位非常清晰:GPU同封装内的非易失性温存储,是HBM与DDR/SSD之间的关键过渡层。
| 物理介质 | ||||
| 物理位置 | ||||
| 典型聚合带宽 | ||||
| 典型容量 | ||||
| 每GB成本 | ||||
| 核心定位 |
从参数梯度可以直观看到:HBF的带宽触及HBM的入门量级,远超节点级DDR总带宽;单堆栈容量是同尺寸HBM的8倍以上;单位成本仅为HBM的1/7~1/10,完美填补了现有体系的性能与成本空白。

3. 不可回避的天生短板
必须客观承认,HBF并未突破半导体物理的基本规律,它有两个无法消除的原生短板:
延迟鸿沟:3D NAND的页读取延迟为数十微秒级,而HBM DRAM仅为数十纳秒,两者相差上千倍。HBF靠并行架构提升了吞吐,但无法从本质上消除延迟差距,因此只能承载静态只读数据,无法替代HBM承载动态计算数据。SK海力士的H³混合架构中,专门加入了SRAM延迟隐藏缓冲区来平滑这一问题,是方案落地的必要设计。 写入限制:NAND闪存的写入速度慢、擦写寿命有限,虽然AI推理是典型的读密集负载(读写比约99:1),大幅弱化了这一短板,但并未从技术上彻底解决。频繁更新的动态数据,依然不适合放在HBF中。
三、为什么HBF会重要?三个场景下的不可替代性
HBF的重要性,从来不是因为它能替代谁,而是它能解决现有介质都解决不了的场景痛点。在AI推理的三个核心演进方向上,HBF是当前产业路径中最具可行性的破局方案。
1. MoE万亿模型:专家库的低成本“待命区”
万亿参数级MoE模型的核心特征,是“总参数量极大、单次激活占比极低”——典型如16选2、64选8,每次推理仅调用极小一部分专家权重,85%以上的参数长期处于“待命状态”。
这就带来了一个尖锐的问题:数百GB甚至数TB的非激活专家权重,放在哪里?
放HBM,容量不够且成本爆炸,单位经济模型直接崩盘; 放传统SSD,每次专家切换都要经历漫长的数据加载,推理吞吐量会断崖式下跌; 放DDR,跨总线延迟与带宽依然无法满足高频切换的性能要求。
HBF的出现,刚好命中了这个场景的核心诉求:同封装的高带宽可以支撑专家权重的快速切换,NAND介质的低成本与大容量可以承载完整的专家库,只读为主的负载特征又完美规避了NAND的写入短板。它让MoE模型可以在可控的成本下,实现更大的参数规模与更高的推理效率,这是现有任何单一介质都做不到的。
2. 长上下文推理:静态KV Cache的“蓄水池”
百万级Token长上下文与长效记忆Agent的普及,让KV Cache的存储需求呈指数级增长。而KV Cache可以分为两类:实时生成的动态KV Cache,和预计算的、可共享的静态KV Cache(如公共知识库、用户历史档案、文档片段)。
这里给两个动画,展示一下 Attention 有 KV Cache 和没有 KV Cache 的区别:
因为这里每次都把整个 tokens 序列重新送进 Transformer:
第一次算: ["<BOS>"]第二次算: ["<BOS>", "Hello"]第三次算: ["<BOS>", "Hello", "World"]第四次算: ["<BOS>", "Hello", "World", "!"]
也就是说,前面已经算过的部分,下一轮还要再算一遍。视频下面那个越来越大的方格矩阵,表现的就是这种重复计算。
在有 KV Cache 的情况下,如果你已经算过前面 token 的 Key/Value:
下次生成新 token 时 不需要再把旧 token 全部重新跑一遍 只需要: 取出历史缓存的 K/V 给当前新 token 算新的 Q/K/V 用当前 token 的 Q 去和历史 K 做 attention
当前的架构下,两类KV Cache都挤占着昂贵的HBM空间,导致GPU算力被存储容量束缚。HBF的价值,就是把静态、只读、共享的温态KV Cache从HBM中下沉出去:
HBM只承载高频更新的动态KV Cache与计算中间态,发挥极致低延迟优势; HBF承载大规模的静态共享KV Cache,以远低于HBM的成本提供TB/s级的读取带宽。
这种分层架构可以在不增加HBM容量的前提下,大幅提升单卡支持的上下文长度与并发数,直接降低单Token推理成本。根据SK海力士的仿真测试,在千万Token场景下,HBM+HBF混合架构的并发查询量可比纯HBM方案提升18.8倍,GPU利用率大幅提升。
提醒一下,KV Cache这里会有很多创业的机会出来。围绕 KV Cache 的“分层、压缩、检索、持久化”,正在重演当年互联网时代从“CPU算力争夺”向“分布式缓存(Redis/Memcached)与虚拟化(VMware)”演进的历史。这也是未来 3-5 年内,AI 基础设施领域最暴利的创业风口之一,需要持续关注一下这个领域。
3. 向量检索与RAG:近存计算的“前置站”
RAG与向量检索是长上下文Agent的核心底座,而传统架构的最大痛点,是“无效数据搬运”的浪费:每次检索都要把海量原始向量从外存搬到GPU显存,最终99.9%的数据都会被过滤掉,总线带宽和功耗大多消耗在了无用的数据传输上。
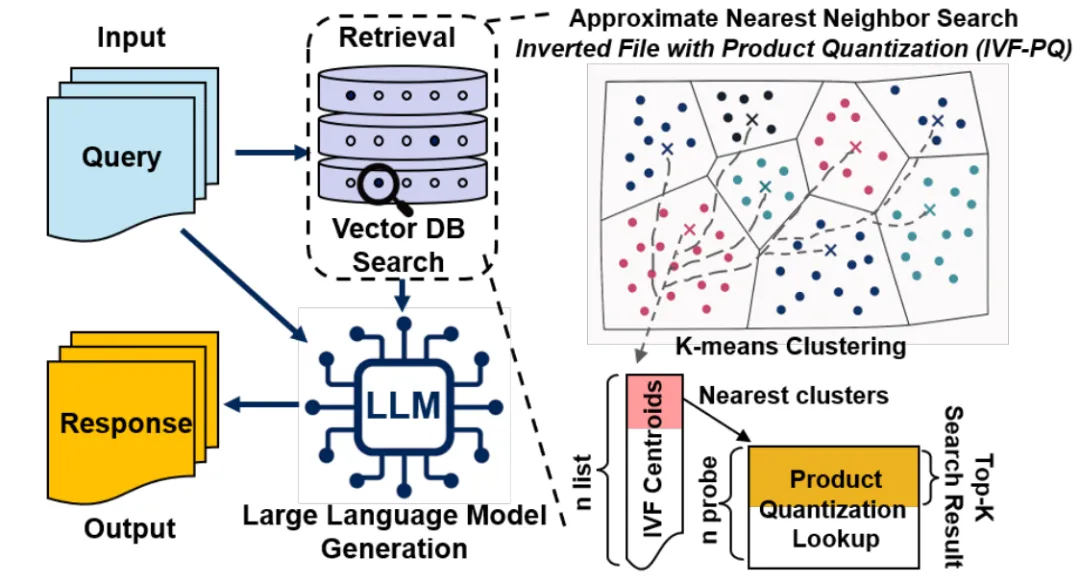
HBF的长期演进方向,就是通过底座芯片的近存计算能力,重构这一流程:把计算下沉到存储侧,在闪存内部完成向量解压缩、距离计算、Top-K初步筛选,最终只把几MB的精准结果传给GPU,实现“只搬运结果,不搬运原始数据”。
需要明确的是,初代商用HBF仅支持基础的解压缩与地址过滤,硬件级向量检索能力是第二代及以后的演进目标。但即便只有基础预处理能力,它也能显著降低总线负载;而随着近存计算能力的逐步迭代,它有望彻底重构向量检索的系统架构,带来吞吐量与能效的量级提升。
除了技术场景的适配,HBF的产业价值同样不可忽视:
降低HBM依赖:当前HBM产能高度集中在少数厂商手中,是AI产业链的核心卡脖子环节。HBF作为同封装的补充存储,可以降低系统对HBM容量的依赖,缓解产能垄断带来的成本与供给风险。 重构推理TCO:对于云厂商而言,推理服务的利润率直接取决于单位Token成本。HBF通过分层存储优化,可在同等性能下将单集群整体TCO降低19%~27%,直接决定了云厂商在价格战中的盈利空间与定价权。
从这个角度看,HBF不只是一个技术部件,更是AI推理进入成本竞争阶段后,全产业链降本增效的关键硬件支点。
四、HBF当前距离大哥HBM的地位还有点远
尽管HBF的价值逻辑清晰,但它远不是“万能解药”,更不会在短期内颠覆现有存储格局。它的落地依然面临多重关卡,同时也存在多条并行的替代技术路线。
1. 技术落地的四道坎
延迟体验关:微秒级的读取延迟,决定了HBF永远无法替代HBM承载动态计算数据,它的应用场景严格限定在静态只读领域,边界非常清晰。 生态适配关:HBF需要GPU、服务器、软件栈全链路的适配改造,无法直接兼容现有架构。从芯片设计导入到系统软件优化,需要全产业链的协同,周期漫长。 可靠性与寿命关:尽管是读密集负载,但NAND的磨损均衡、错误校验、散热设计依然是工程难题,要达到数据中心级的可靠性标准,仍需大量验证。 产能与成本关:初代产品成本较高,只有规模量产后才能逼近目标成本;而量产节奏受先进封装、逻辑代工产能约束,存在不确定性。
2. 并非唯一解:并行的替代路线
HBF不是解决存储三元悖论的唯一路径,产业界还有多条技术路线同步推进:
CXL内存池化:通过CXL协议实现内存的池化与共享,灵活扩展系统内存容量,适合多机集群的场景; 存储级内存(SCM):兼顾DRAM级性能与非易失性,定位在DDR与NAND之间,但成本与容量密度依然受限; DPU/智能SSD卸载:在机架级通过DPU与智能SSD实现数据预处理与近存计算,不用改动GPU封装架构,落地更快。
这些路线各有优劣,与HBF是互补而非完全替代的关系。不同厂商会根据自身技术路线与业务场景,选择不同的组合方案。
3. 量产节奏:远水难解近渴
根据当前产业规划,HBF的商用节奏非常清晰:
2026年下半年:工程验证样品交付,仅面向核心客户测试; 2027年:小规模试产,原型设备落地; 2028年及以后:规模量产,逐步进入主流推理集群。
也就是说,至少在未来2年内,HBF都不会成为市场主流。它是面向AI推理下半场的技术储备,而非解决当下痛点的速效药。
结论:HBF不会颠覆格局,但会成为不可或缺的一级
回到开篇的问题:HBF,在未来真的重要吗? 答案是肯定的,但它的重要性需要放在分层存储的框架下理解。它不会替代HBM,不会淘汰DDR,也不会取代SSD,而是补上了AI存储金字塔中缺失的关键一级,让整个体系在容量、带宽、成本之间找到了新的平衡点。
AI的上半场是算力的军备竞赛,比的是谁的FLOPS更高;下半场是成本的精细化竞争,比的是谁的单位Token成本更低。在这个阶段,存储架构的优化空间,甚至比单纯堆算力更大。HBF恰恰踩中了这个产业周期的核心诉求,它精准适配了MoE、长上下文、向量检索三大核心场景,用封装级的创新,在物理定律的约束内给出了兼顾成本与性能的可行方案。
短期来看,我们不用高估它的落地速度,2028年之前它都只会出现在头部厂商的定制化集群中;长期来看,我们也不用低估它的产业价值——当AI推理进入万级集群、亿级用户的规模化阶段,HBF这类近存非易失存储,会成为和HBM同等重要的基础设施。
存储三篇已经写完了,所有关于带宽、容量、成本的技术缠斗,所有从 HBM 到 HBF 的架构演进,最终都指向同一个朴素的用户终点:我们需要一个拥有长效记忆的 AI Agent。它记得你是谁,记得你说过的话,甚至记得你看过的世界;它随时在侧、召之即来、响应迅捷。而我们终将为之付费。
