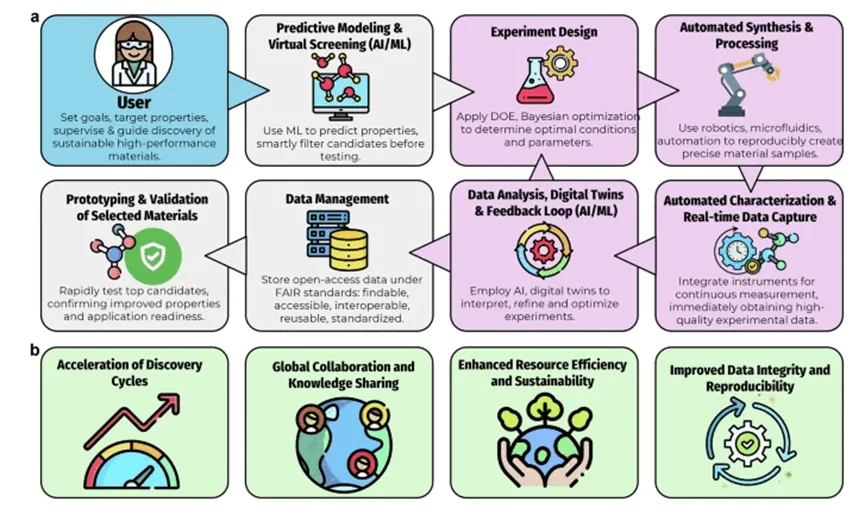
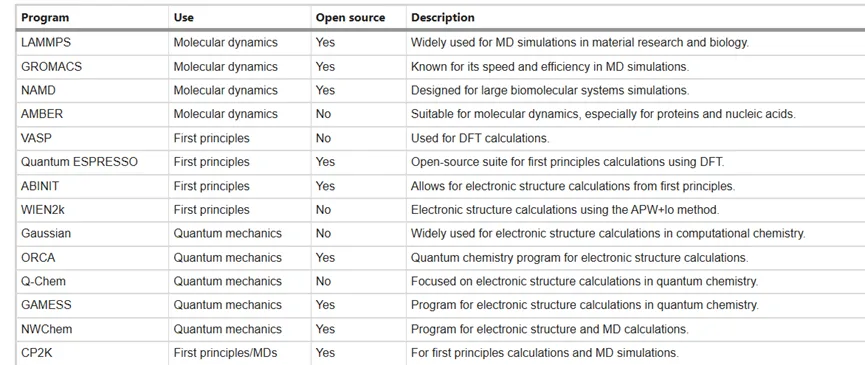
AI驱动材料发现与先进制造 1:数据采集的范式重构在传统材料发现与制造中,数据主要依赖实验室试错获得,研究人员通过反复调整成分与工艺来测定材料性能。这种方式周期长、成本高,且数据规模小、覆盖有限,同时不同实验室之间缺乏统一标准,导致数据难以比较与复用,限制了材料创新速度。随着数据科学发展,PubChem、ChEMBL、COD等开源数据库为材料研究提供了大规模结构与性能信息,推动了数据驱动研究。进一步地,软件定义实验室(SDL)通过自动化、机器人与机器学习构建“设计—合成—表征—优化”闭环,实现高通量、低干预的数据采集,大幅提升效率与一致性。结合数字孪生与物理信息机器学习(PIML),实验与模型之间实现物理约束下的协同优化,提高在复杂条件下的可靠性。同时,高性能计算模拟、生成式AI以及网络爬虫与文献自动抽取技术,进一步扩展了数据来源,使材料数据从真实实验扩展到虚拟与合成空间。整体而言,材料数据采集正由传统实验驱动,转向“实验+计算+AI”协同驱动的新范式。传统数据收集传统材料发现的数据收集主要依赖实验方法。科学家在实验室中合成材料,并通过反复试验观察其性能。这一过程涉及测试不同的化学成分、加工条件以及机械强度、热稳定性和环境影响等性能指标。通常,这些实验耗时耗力,且高度依赖研究人员的专业技能。这些实验产生的大量数据集往往需要多年积累,使得材料发现过程缓慢且成本高昂。此外,这类实验通常规模较小、数据多样性有限,限制了对更广泛材料空间的探索。此外,传统数据收集方法往往缺乏跨研究团队的统一标准,导致数据不一致且难以比较。实验条件(如温度、压力或化学品纯度)差异,也会影响结果的可重复性。学术界与工业界的数据往往相互独立,限制了合作与知识共享,而这些恰恰是加速可持续材料发现的重要基础。尽管传统方法已取得一定进展,但在应对气候变化、资源短缺和环境恶化等全球挑战方面,其速度与规模仍显不足。因此,越来越多研究开始将计算工具与大规模数据库结合传统实验方法,以实现更高效、更大规模的材料发现。开源数据集和数据库在新材料研究中发挥着关键作用。在化学与材料科学领域,这些数据库提供了大量化合物的化学、生物及结构特性信息,使研究人员能够获取原本难以获得的实验数据。这些数据资源支持复杂分析、数值模拟以及虚拟筛选,从而加速新材料、药物及其他功能材料的开发。材料研究中广泛使用多种开放数据库与专业数据库。例如,PubChem是一个综合性数据库,提供超过1.13亿种化合物的小分子化学性质与生物活性信息;ChEMBL提供具有类药特性的生物活性分子数据;晶体学开放数据库(COD)则提供有机、无机及金属有机化合物的晶体结构数据。不同数据库各有侧重,如有机分子、晶体结构或无机体系,其开放共享显著促进了可持续材料领域的合作与发展。智能系统采集自动实验室(SDL)通过整合自动化、机器学习与机器人技术,正在革新科学研究,并加速化学与材料科学等领域的发现。这些先进系统实现了实验全过程自动化,构建出无需人工干预的闭环框架,可完成实验设计、执行与优化。这种变革性能力使研究人员能够以前所未有的速度与精度探索广阔的化学与材料空间,而传统实验室方法往往需要更长时间才能达到类似突破。如图所示,SDL在迭代闭环系统中运行,由用户目标驱动,并结合机器学习预测建模、先进实验设计、自动化合成、实时表征以及数字反馈优化。这一流程不仅加速发现周期,还显著提升资源利用效率、可持续性、数据完整性与可重复性。同时,它也促进了全球协作与知识共享,对材料科学创新至关重要。数字孪生(物理实验系统的虚拟映射)的引入进一步扩展了SDL的能力,使实验能够远程监控与动态调整,从而支持跨地域协同。例如,不同国家的实验室可以通过SDL实现实时协同优化反应条件。在此基础上,遵循FAIR原则(可查找、可访问、可互操作、可复用)的数据管理方式,也显著提升了透明度与协作效率。SDL的另一优势在于自动化硬件(如机器人与3D打印设备)成本持续下降,使其逐步具备普及条件。远程控制能力的提升,也使实验室可通过互联网运行SDL系统,从而减少基础设施依赖,扩大技术可及性。在开源软件方面,Chemspyd作为Chemspeed机器人平台的Python接口,实现了对自动化实验的动态控制,并可无缝集成到现有工作流中,从而提升实验设计灵活性与可重复性。这些进展使实验室能够实现更高频率、甚至全天候运行。SDL在清洁能源材料开发中也发挥重要作用,可加速光伏与热电材料筛选。例如Ada SDL通过自动化合成与数字反馈回路优化薄膜太阳能电池,在降低资源消耗的同时提升能量转换效率,为绿色能源技术提供新路径。随着SDL与智能制造融合发展,数字孪生与机器学习被广泛用于构建预测性与自适应系统。然而,当数字孪生完全依赖数据驱动模型时,在数据稀疏或外推场景下,其可靠性可能下降,甚至出现违背物理规律的预测结果。为解决这一问题,物理信息机器学习(PIML)被提出。其核心思想是将物理定律嵌入学习过程,通过守恒律、热力学约束或结构正则化,实现实验数据、数值模拟与第一性原理的统一建模。在热传输、化学反应及结构-性能预测等问题中,PIML表现出更高的数据效率与鲁棒性,并可有效减少非物理预测。这些发展也推动SDL向更可靠的智能实验系统演进。通过将物理约束嵌入数字孪生模型,可以提升决策稳定性,降低实验失败率,并减少资源浪费。从这一意义上看,SDL成为连接智能制造与材料科学的重要桥梁。合成数据高保真计算建模(计算机模拟)已成为材料数据生成的重要来源。通过提供原子尺度到介观尺度的材料行为信息,这些模拟有效补充实验数据,并拓展可探索的设计空间。分子动力学(MD)、密度泛函理论(DFT)及量子化学方法等,可用于虚拟筛选材料、预测相稳定性与电子结构,并分析界面行为。这些数据也成为AI模型训练的重要基础。常用计算工具包括LAMMPS、GROMACS、NAMD等分子动力学软件,以及Quantum ESPRESSO、ABINIT、VASP等第一性原理框架,此外还有ORCA与Gaussian等量子化学工具。这些工具共同构成了完整的计算生态系统。在应用方面,分子动力学已用于电池电解质降解、钙钛矿太阳能电池界面分析、绿色表面活性剂以及纤维素材料等研究。同时,第一性原理计算也支持储氢材料、木质素燃料及新型光电子材料的设计。与此同时,Materials Project、OQMD与AFLOWlib等数据库整合实验与计算数据,为AI模型提供标准化训练资源。机器学习势函数与图神经网络的发展,使原子模拟能够在保持物理一致性的同时扩展到更大尺度。然而,其可靠性仍受训练数据分布限制,在未知化学空间中可能出现误差,因此仍需与高精度计算持续校验。生成式AI(如VAE、GAN等)也被用于生成合成数据,以扩展材料数据分布。但大规模计算同样带来显著能源消耗,使计算可持续性成为新的挑战。从公开数据源抓取数据数据抓取是从公开网络资源自动提取数据的方法,可用于获取材料特性、合成条件与实验结果等信息。通过解析网页结构与动态内容,可以构建大规模结构化数据集,为数据驱动研究与机器学习提供基础。常用工具包括Beautiful Soup与Scrapy(结构化网页),Selenium与Puppeteer(动态网页),以及Octoparse与ParseHub(可视化工具)。Diffbot等企业级工具则提供AI驱动的数据提取能力。从科学文献中自动提取数据随着自然语言处理与大语言模型的发展,材料数据提取正在发生变革。BERT、GPT-3与GPT-4等模型能够从非结构化文本中自动提取材料属性与结构关系,大幅降低人工整理成本。例如MaterialsBERT、ChatExtract等工具可实现高精度信息抽取;NEMAD项目则结合LLM与机器学习实现混合建模。研究表明,MaterialsBERT在材料术语识别方面优于通用模型,并可快速构建大规模结构化数据库。近年来,基于LLM的框架已能够从数十万篇文献中提取数百万条材料记录,并广泛应用于聚合物与能源材料研究。同时,结合NER与多模型融合的方法,也显著提升了数据质量与覆盖范围。此外,在聚合物太阳能电池、MOF结构数据以及图像自动标注等任务中,AI均展现出强大的自动化能力,使数据构建逐步走向半自动乃至全自动化。尽管如此,复杂表格、图像信息与跨模态数据仍然是当前挑战。同时,模型在不同材料子领域的泛化能力仍需进一步提升。总体来看,材料数据采集正从传统实验驱动,逐步走向“实验 + 计算 + AI”融合驱动的新范式,为材料发现与先进制造提供坚实的数据基础
 夜雨聆风
夜雨聆风