 夜雨聆风
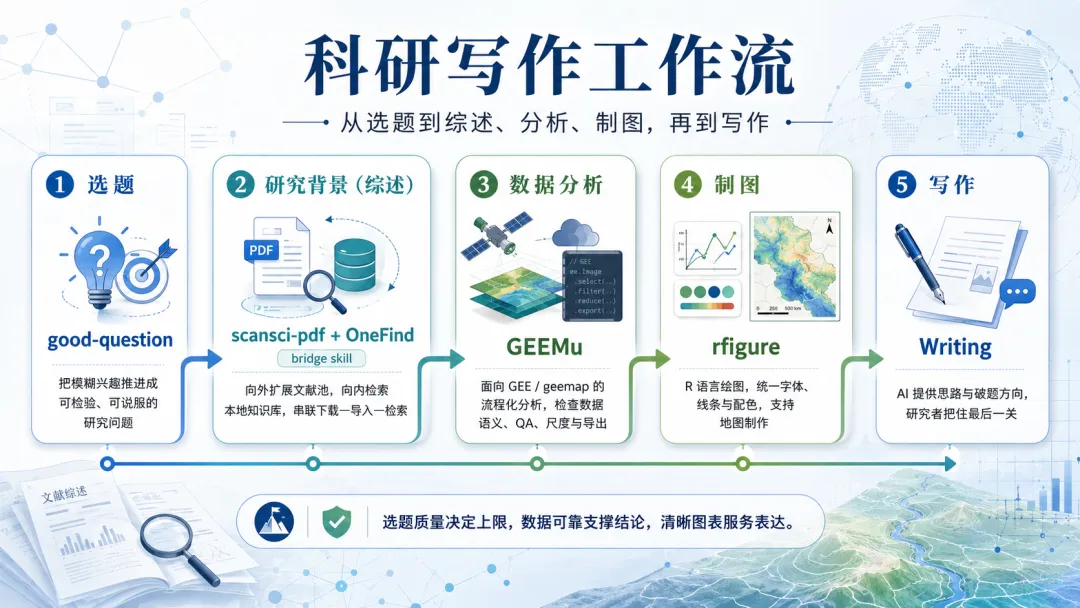
夜雨聆风AI的发展,增大了我们写论文的效率。但如何使用ai,也是一门本事,今天分享一下我正在使用从选题到写作的ai全流程科研处理链路。
1.选题-good-question
项目地址:https://github.com/Rimagination/good-question
科研写作的第一步不是动笔,而是确认问题值不值得做。
很多项目一开始看起来有方向,但其实只是一个主题,比如“气候变化与植被恢复”“微生物多样性与生态功能”“遥感监测生态系统变化”。这些还不是研究问题。
good-question 解决的就是这个问题:把一个模糊兴趣,推进成一个更清晰、更可检验、更容易说服评审的研究问题。
它会帮你追问:
这个问题为什么重要?
它挑战了什么已有假设?
竞争性解释有哪些?
什么结果会推翻你的判断?
两周内能不能做一个 pilot?
最强的评审质疑会是什么?
它的价值不是“多生成几个选题”,而是帮你避免一开始就选到一个松散、无力、后期很难写成论文的问题。
他也会给你已经有的选题方向和研究内容进行打分,并提出合理的解决方案,给你一个参考。

对科研写作来说,选题质量决定了后面所有工作的上限。一个问题如果本身不够锋利,后面文献再多、图再漂亮、语言再精致,也很难真正立住。
2.研究背景(综述)-onefind/scansci-pdf
项目链接:
https://github.com/iawnfoanaowt/OneFind
https://github.com/Rimagination/scansci-pdf
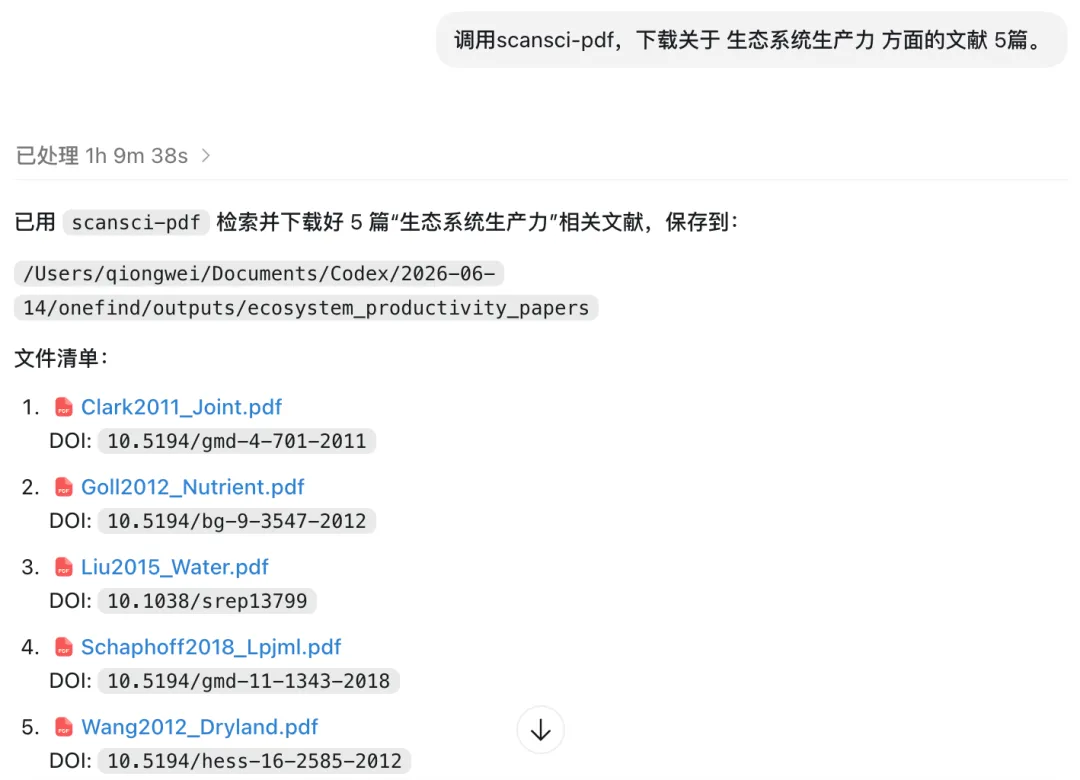
在确定了一个研究方向之后,首先第一步是要去文献综述。看看别人怎么做,别人的成果如何。我们不能一直重复造轮子,而是能参考的就一定要参考,并从已经有的研究中发现缺口,直插一刀。
在以往的流程中,这一步最费时间费力气——因为文献是看不完的,同时下文献也是十分费劲的。
scansci-pdf 负责“找和拿”。
它可以根据 DOI、arXiv ID、关键词或 BibTeX 文件检索和下载论文,也支持批量下载、补全引用信息、导出 BibTeX/RIS 等格式。遇到付费墙时,也可以配合机构登录流程处理。
它解决的是文献综述里最基础但最烦的一层:把候选论文尽快拿到手,并且把引用信息整理好。
onefind 负责“查和用”。
很多时候,我们不是没读过相关文献,而是想不起来那句话、那个方法、那个数据集到底在哪篇文章里。onefind 可以从本地知识库里检索,包括 Zotero、Obsidian、本地文件夹、Notion、Mendeley 等来源。
它更像是一个本地科研记忆系统。
当你已经积累了一批文献、笔记、PDF 标注之后,可以直接问它:
某个方向已有研究主要用什么方法?
有没有文章讨论过某个机制?
哪些论文提到了这个数据集?
我之前读过的文献里,谁做过类似实验?
某个概念在我的资料库里是怎么被定义的?
这样综述就不只是“重新搜索一遍互联网”,而是把你过去积累过的资料重新调动起来。

所以这两个 skill 的分工很清楚:
scansci-pdf 帮你扩展文献池,尽快把论文拿回来。
onefind 帮你盘活已有知识,把本地文献和笔记变成可检索的证据库。
一个向外找,一个向内查。
综述阶段最理想的状态,就是先用 scansci-pdf 快速建立候选文献池,再用 onefind 在本地知识库里反复追问、对比和归纳。这样既不会漏掉新文献,也不会浪费过去已经读过的材料。
在本人实际使用中,偏爱zotero,全链路是scansci下载,然后导入zotero,接着用onefind检索。但其中恰恰缺失关键一步:自动下载-自动导入。因此本人开发了一个bridge skill。适配zotero软件,实现下载-导入-检索的全过程。感兴趣的小伙伴可以去看看。
项目地址:https://github.com/qwlei328-maker/bridge-skill
数据分析:GEEmu
在我所在的专业里,经常会使用 Google Earth Engine 进行数据分析。
GEE 的优势很明显。它能直接调用大量遥感数据集,也能在云端完成影像筛选、时间序列处理、指数计算、区域统计和导出。对生态、地理、环境、遥感相关研究来说,它几乎已经是一个绕不开的工具。
但 GEE 的问题也很明显。
它不是简单写几行代码就结束了。很多分析看起来能跑通,但结果未必可靠。比如:
数据集选择是否合适?
时间范围和研究区是否正确?
云掩膜有没有处理?
波段、单位、比例因子有没有弄对?
空间分辨率和统计尺度是否匹配?
导出区域会不会太大?
结果到底是预览图,还是可用于论文分析的数据?
这些细节一旦出错,后面图画得再漂亮、文字写得再顺,也只是建立在错误结果之上。
GEEMu 解决的是 GEE/geemap 工作流中的这些实际问题。
它不是只帮你补代码,而是把整个分析过程流程化:先确认 Earth Engine 项目 ID 和本地环境,再根据研究区、时间范围、数据集、变量、尺度和输出目标,生成可运行的 Python/geemap 代码。同时,它会提醒你检查数据语义、边界处理、导出方式和计算成本。
这对科研分析很重要。
因为 GEE 最大的风险不是“代码报错”,而是“代码不报错但结果错了”。
比如同样是 NDVI,不同数据集的波段名称、比例因子、云质量控制方式可能都不同。再比如区域统计时,如果研究区边界复杂、尺度设置过细,导出任务可能非常慢,甚至直接失败。还有一些结果如果直接用 getInfo() 拉到本地,会很容易卡死或超限。
GEEMu 的价值就在于,它会把这些容易被忽略的问题提前放到流程里。
对我来说,它适合用在几个场景:
根据研究问题选择合适的 GEE 数据集;
编写 Earth Engine / geemap 数据处理代码;
检查云掩膜、比例因子、单位和 QA band;
按研究区做区域统计或时间序列分析;
设计安全的导出方式,比如 Drive、Asset 或本地 GeoTIFF;
记录一次 GEE 分析的参数、数据层和输出路径。
这样数据分析阶段就不会完全依赖临场写代码,而是变成一个更稳定的流程:先确认研究设计,再确认数据语义,最后再运行和导出。
这一步做好,后面的制图、结果解释和论文写作才有基础。因为论文里所有看起来漂亮的结论,最底层都来自这里的数据处理是否可靠。
4.制图:rfigure
做完分析也就该到制图了。制图是最简单的工作,在这里推荐我开发的rfigure skill,这是一款基于r语言的绘图工具,最新的版本中已经支持了中国地图的制作。
skill内置一套个人常用的方案,你可以要求ai更改为你爱用的方案。包括字体、线条、色彩搭配。
5.写作
在写作上,我不太喜欢全盘依靠ai生成。我更热衷于ai提供写作思路和破题方向,本人牢牢把住最后一关。因此在这里不推荐任何写作项目。
6.写在最后
通过上面推荐的项目,会极大地提升我们的科研效率。但请注意:ai也会犯错!请在ai完成初步探索后仔细核实每一步!特别是在代码运算。
科研工作需要对自己负责对读者负责对社会负责。在发表时切记纰漏ai使用情况!
