 夜雨聆风
夜雨聆风
[阐微知界] AI-Ready数据构建平台使用教程
(https://data.nano-bd.com)
阐微知界,AI-Ready数据构建平台
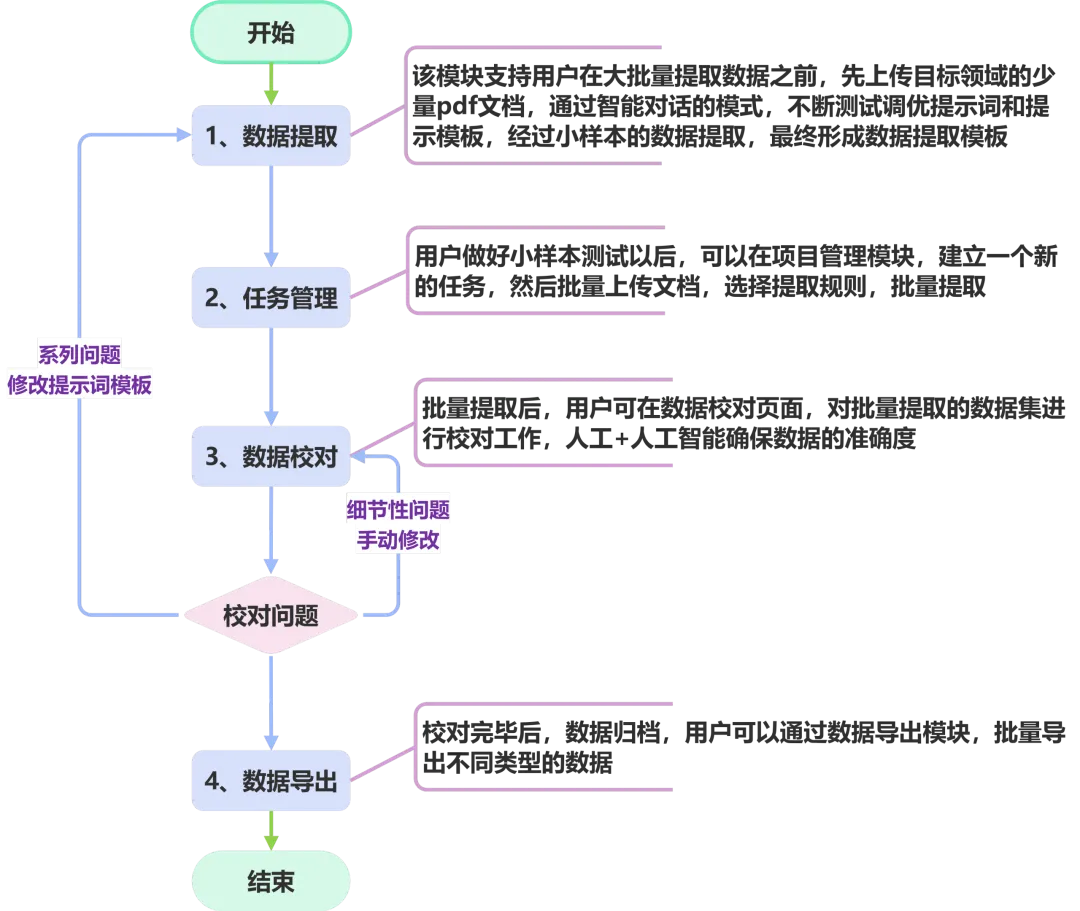 |
📌 第一步:数据提取——小样本测试,构建提取配置
在正式批量处理之前,建议先上传少量目标领域的 PDF 文献(如 3~5 篇)。通过平台的智能对话模式,测试和调优提示词及提取配置,直到调试出最适合您的研究场景的提取规则,即可将当前提取配置保存为稳定可用的“数据提取模板”。
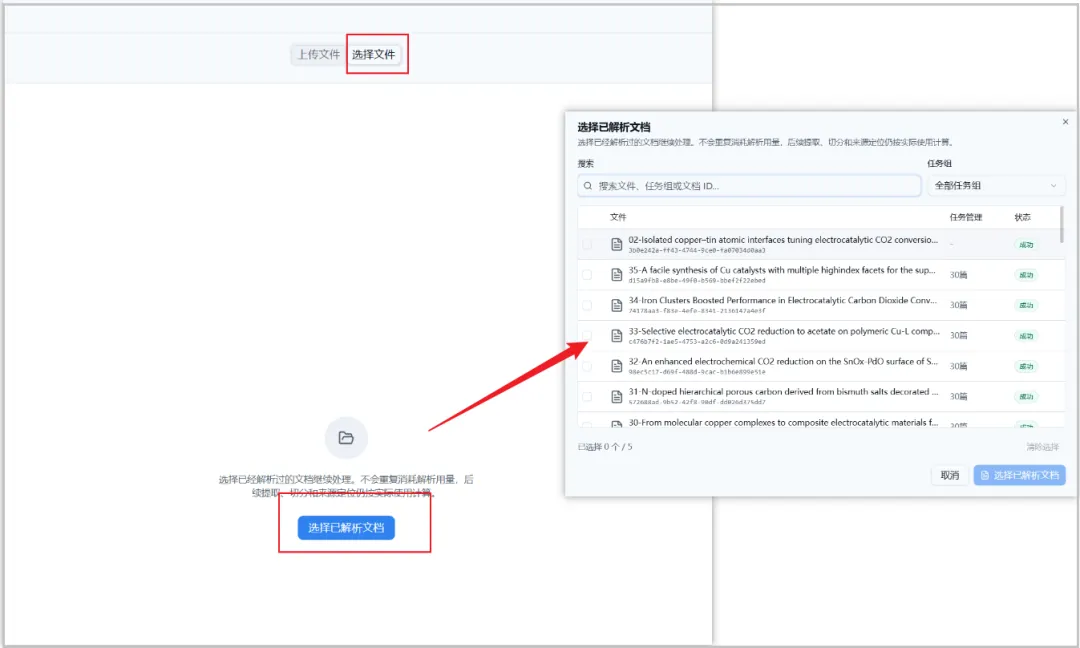
单篇 or 多篇:第一次测试,可以先上传一篇试试手,当然也支持同时上传多篇文献。 文件解析:每次通过「上传文件」上传的文件,都要先经过解析才能提取数据,如果文献已经在平台上传过,通过「选择文件」选中的文件,不用重复解析,既省时间又省费用!
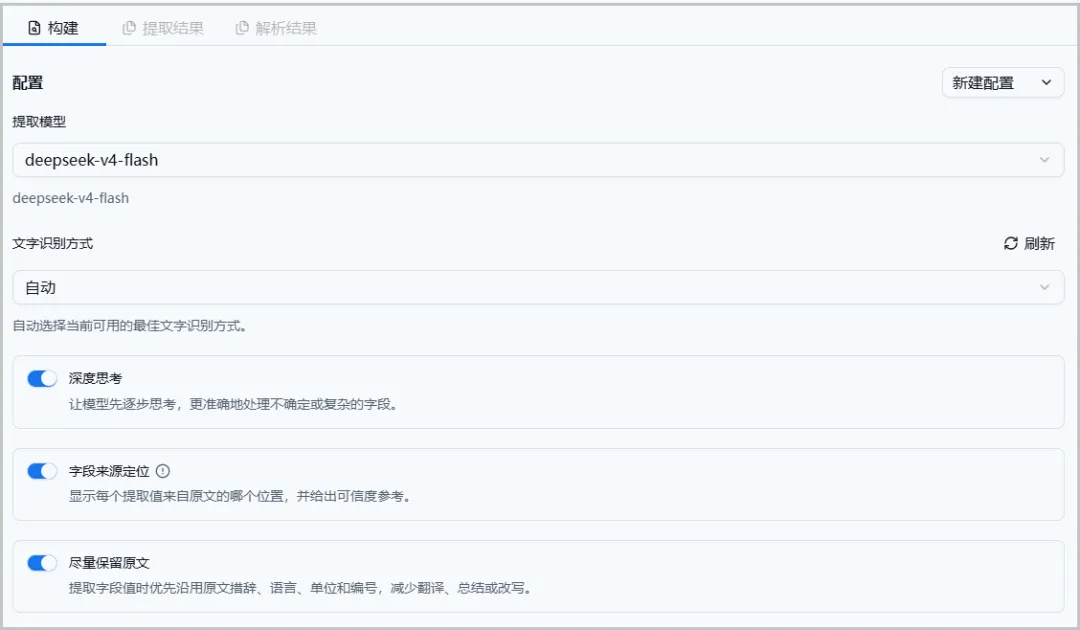
多个主流大模型,自由选择:平台接入了多个主流大模型,你可以根据需求自由切换,灵活又方便。
深度思考,打开效果更好:建议开启「深度思考」模式,输出结果更精准、更贴合你的需求。
字段来源定位,快速回溯原文:打开「字段来源定位」后,提取出的每一项数据都能快速对应到原文位置,查证、比对一目了然。
尽量保留原文语言:系统会尽量保持原文的语言风格。不过,如果提示词中出现了汉语指令(比如“字段为空值时,留‘空’”),可能会输出中文。
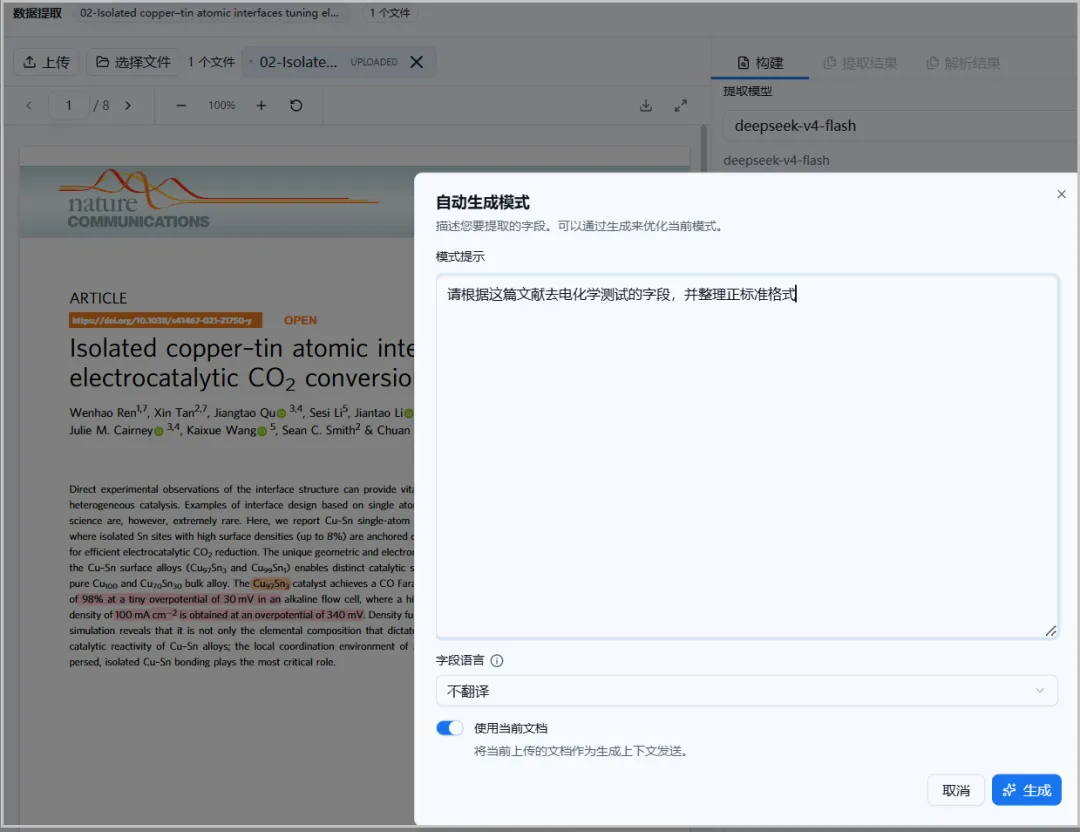
平台提供自动生成和手动配置两种模式,满足不同习惯和需求。
🤖3.1 自动生成模式:通过对话模式即可完成
对话式需求输入:你只需通过一轮或多轮简单对话,说出自己的需求,平台会自动帮你整理成结构化的字段形式。
基于标准文献生成:也可以上传一篇标准文献,平台会根据文献内容自动提取和整理字段。
无需手动编写复杂提示词,如同自然对话般轻松便捷
🛠️ 3.2手动配置模式:更自由,更精细
用户可以随时在自动生成的基础上直接切换为手动修改,两种方式任选:
可视化编辑器:像搭积木一样,自由增删字段,编辑字段内容和属性,直观方便。
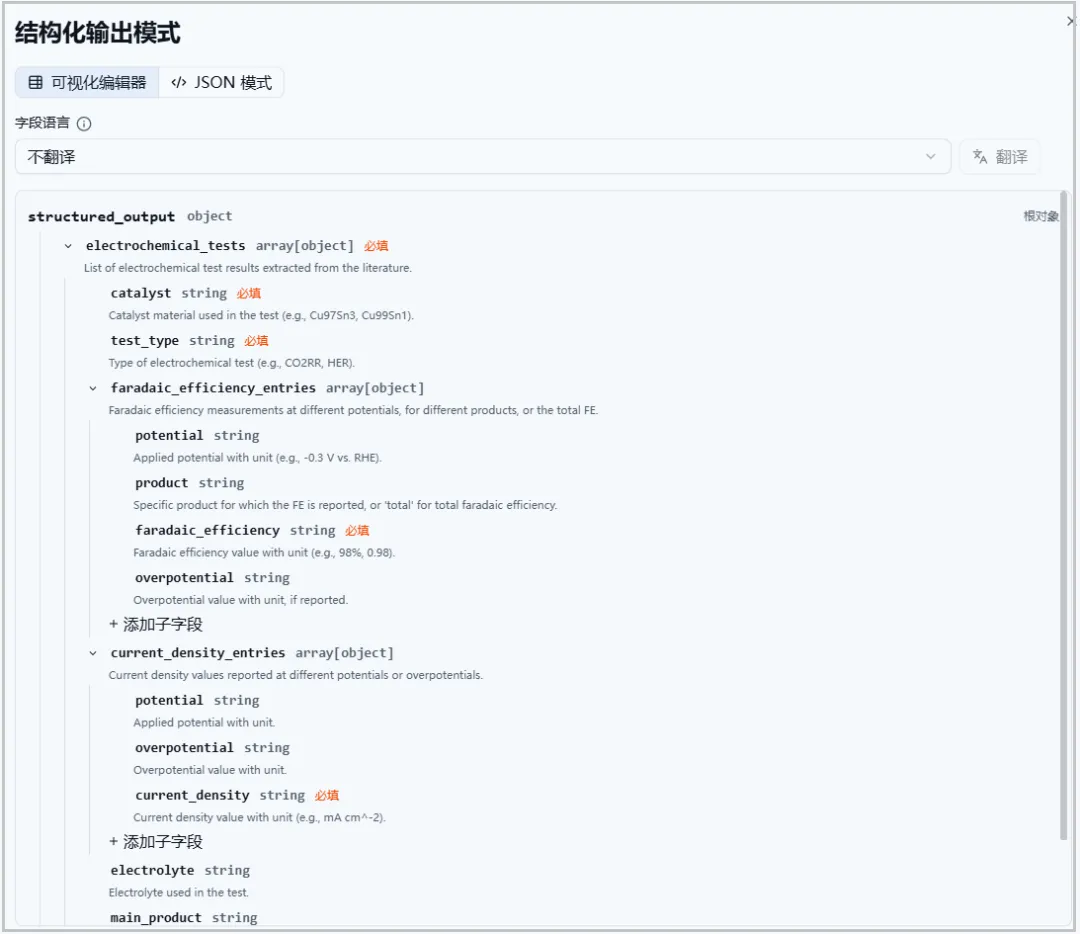
图5.自动或手动生成提示词界面(可视化编辑) JSON 模式:如果你习惯写代码,也可以直接以 JSON 格式编辑,灵活高效。
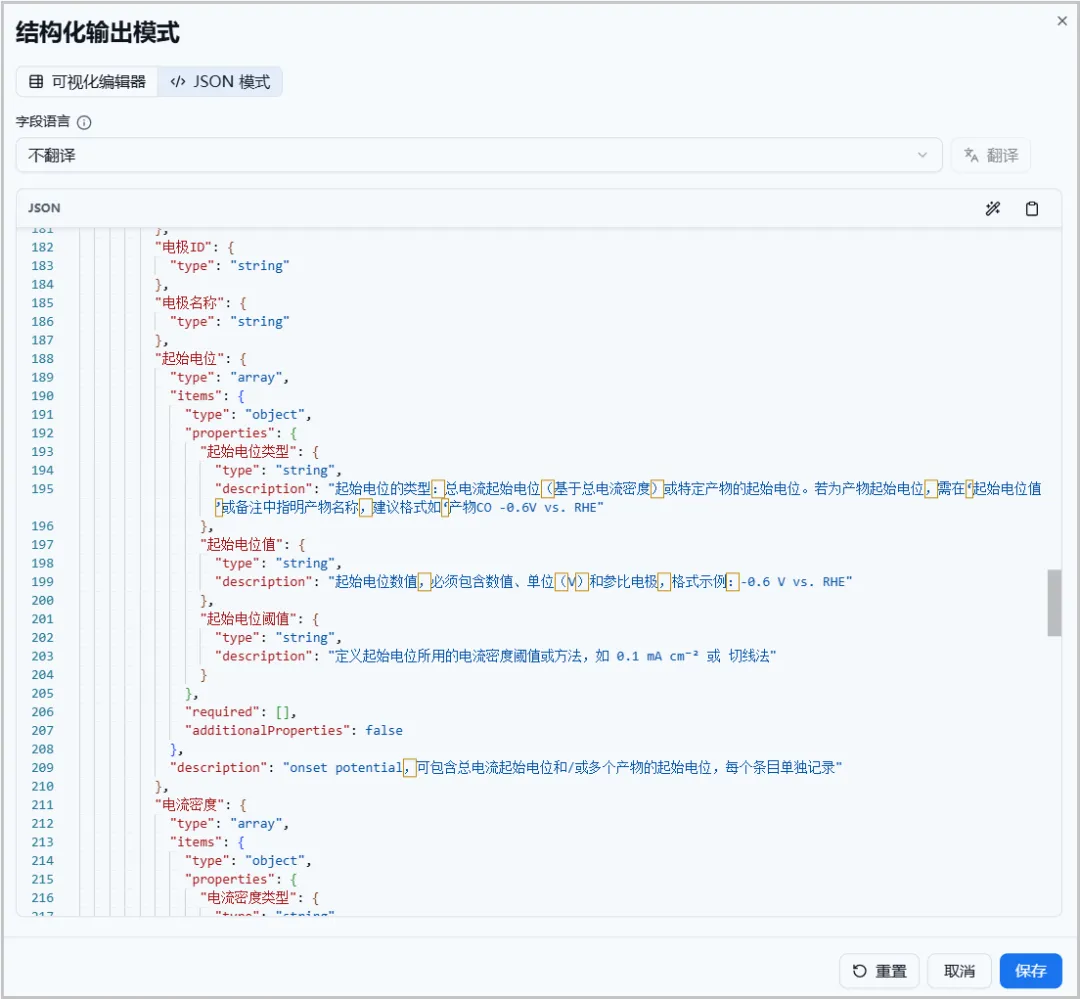
图6.自动或手动生成提示词界面(json模式)
💡小贴士:两种模式可以搭配使用——先用自动生成打个底,再用手动模式微调,省时又精准!
最后,全部改完或者退出页面时一定记得要保存/更新配置!!!
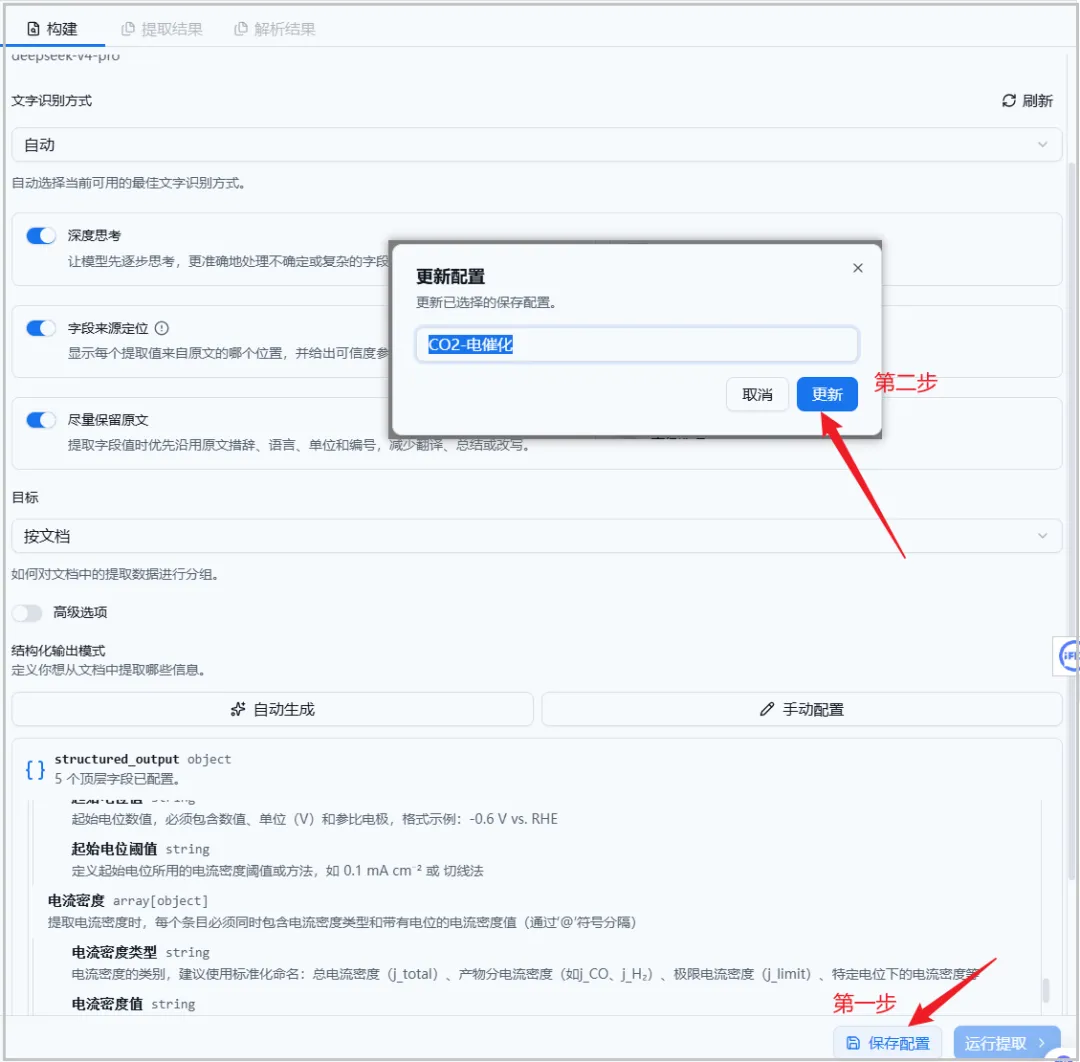
图7.保存/更新配置页面
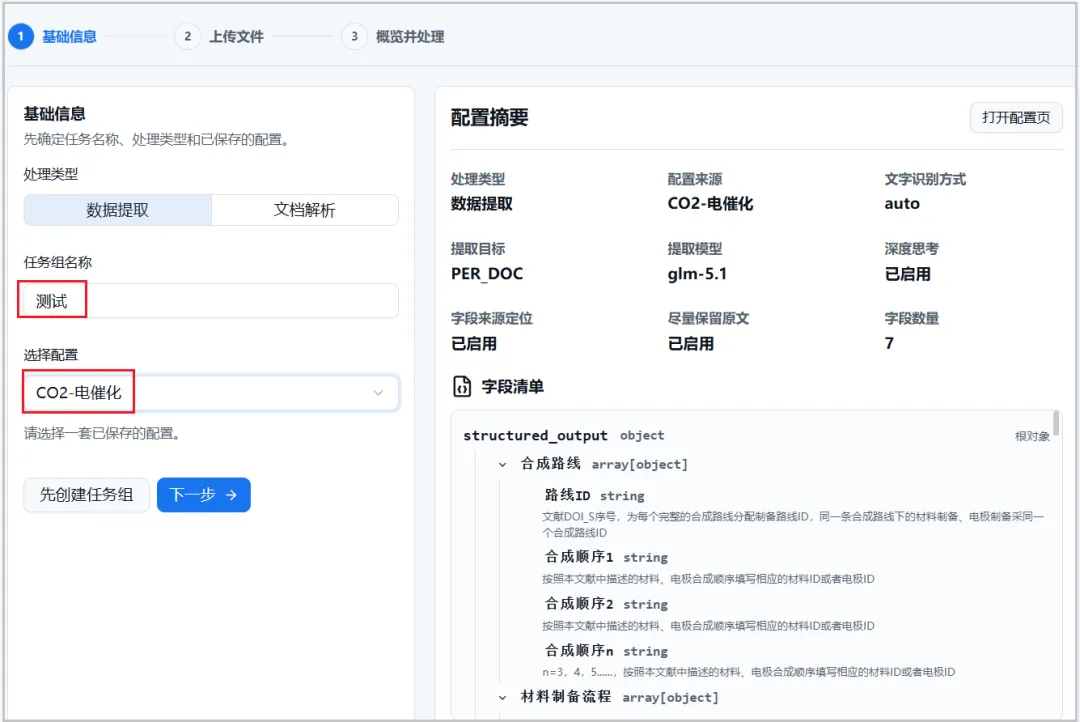
📌 第二步:任务管理——批量提取,一键自动抽取
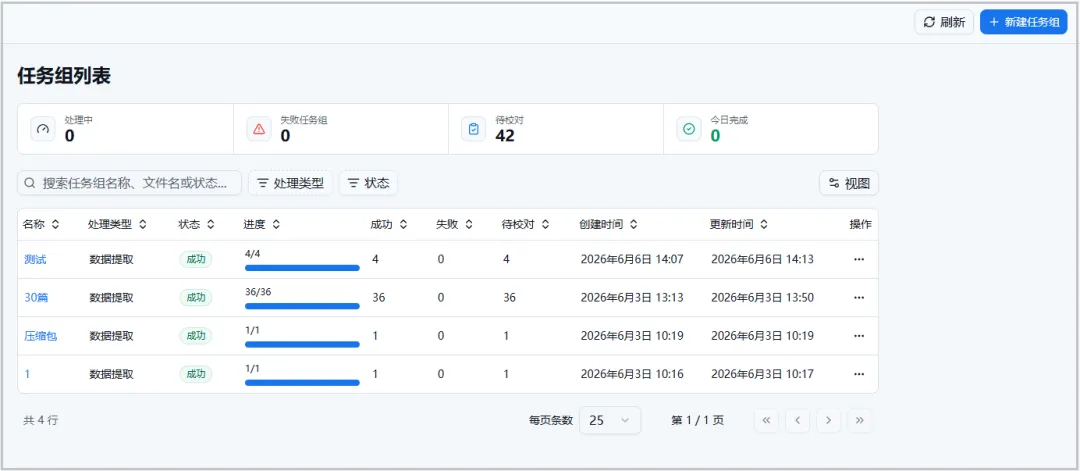
图8.任务管理页面
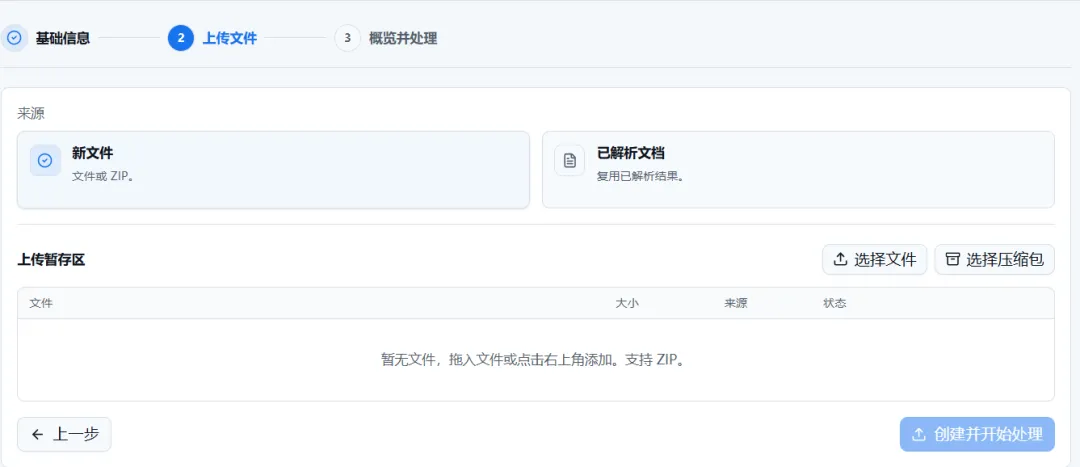 |
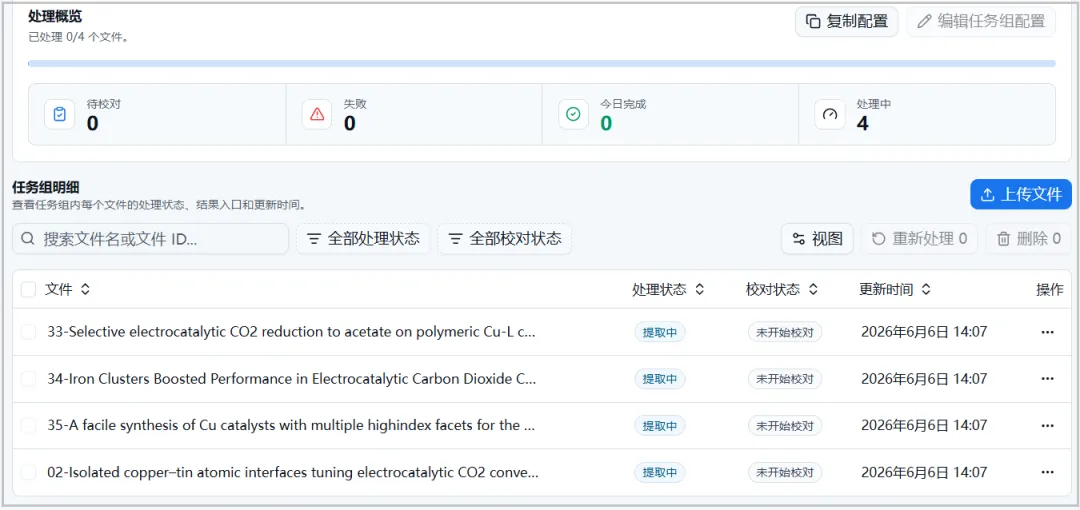
💡小贴士:任务创建后可以随时查看进度,支持断点续传。
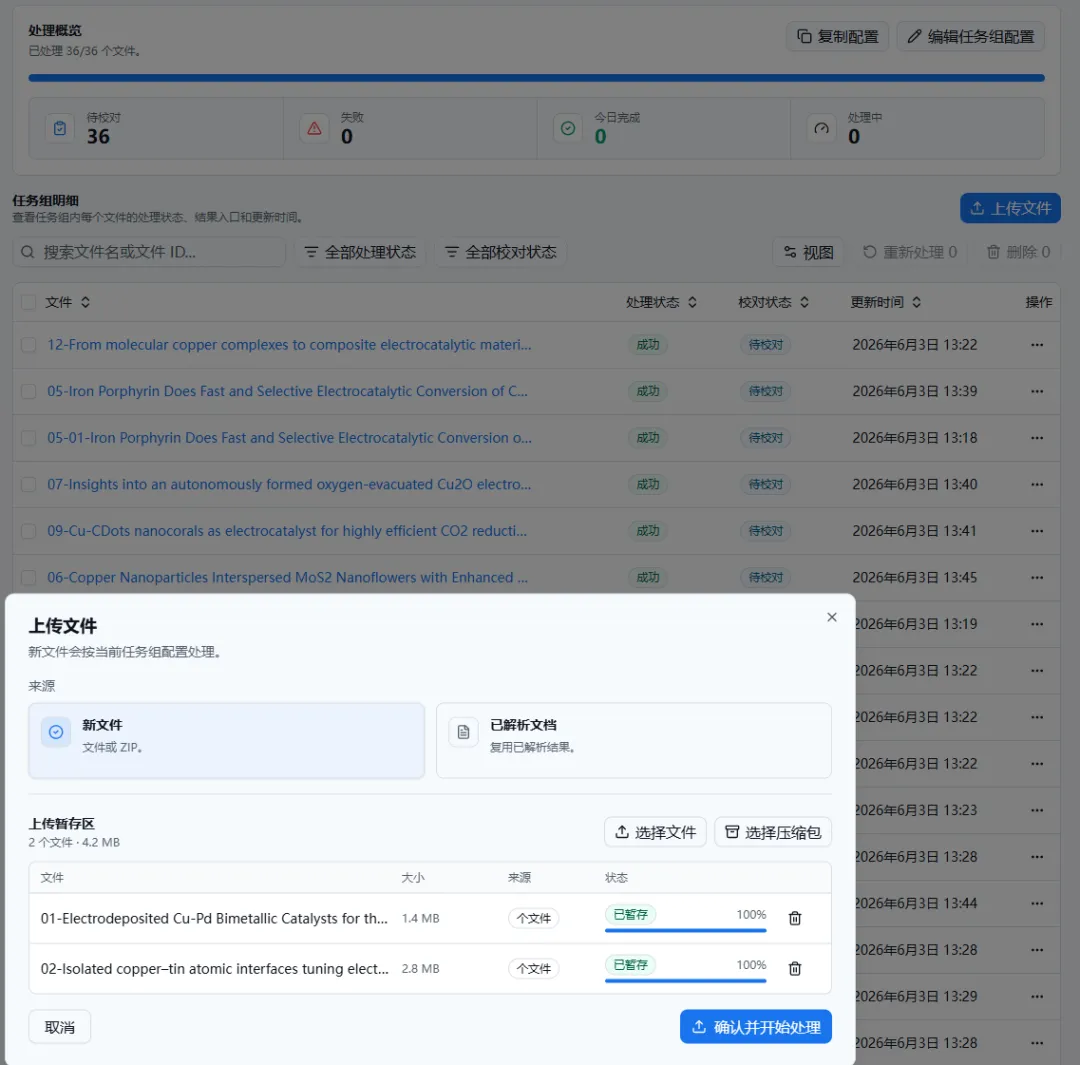 |
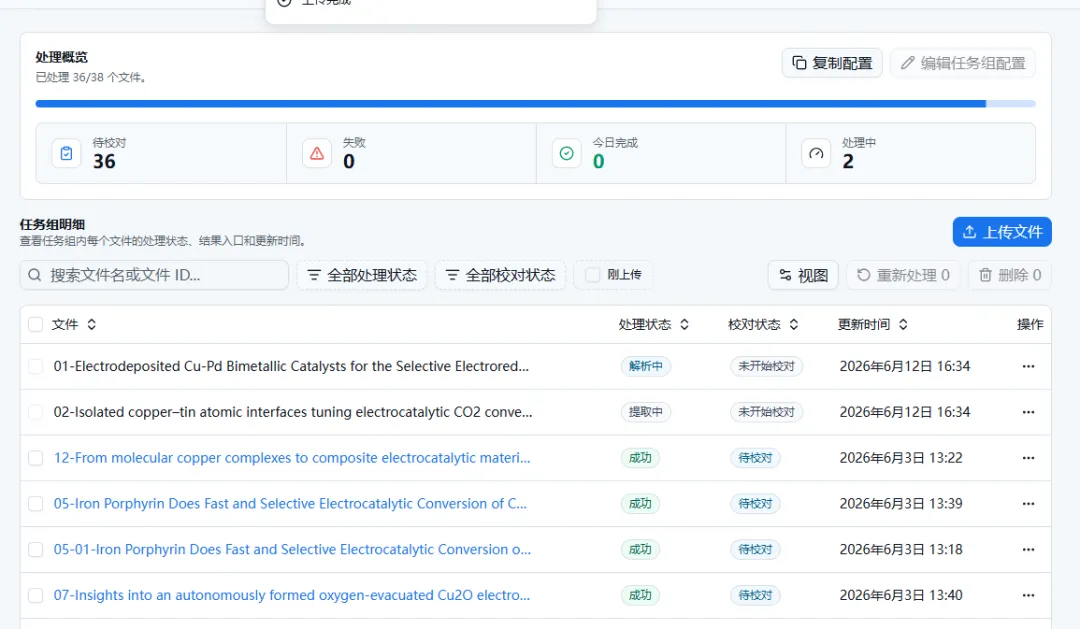 |
图12.支持断点续传的文件提取任务处理界面
📌 第三步:数据校对—— 逐条或抽检修正,形成审核闭环
批量数据抽取任务完成后,所有结果进入校对中心,用户可以根据需求对提取的数据进行逐条或抽检、修正。所有修改记录自动留存,形成“提取—校对—修正—确认”的闭环,助力团队高效协作与质量持续改进。
1️⃣ 进入「校对中心」
2️⃣ 选择需要校对的任务组
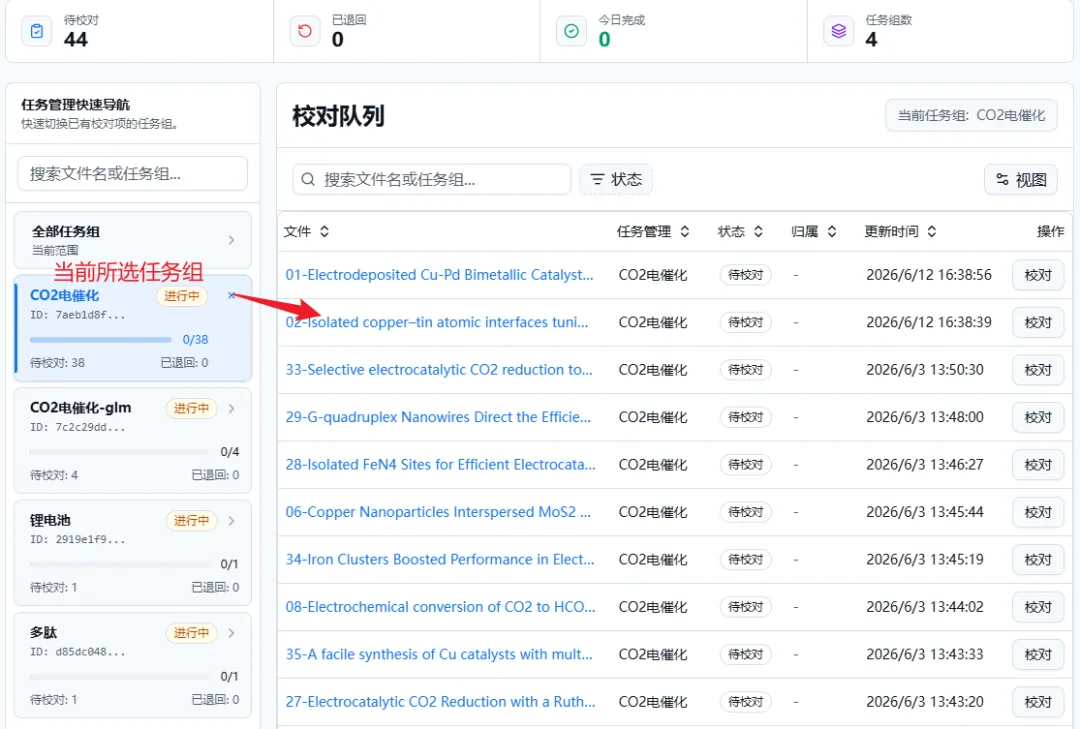 |
图13. 校对中心—待校对任务列表界面,支持按任务组筛选、查看文件校对状态与提交时间。
3️⃣ 选择具体文献
4️⃣ 核对数据并完成修正
核对时点击字段前小地图即可自动跳转到PDF原文对应位置。
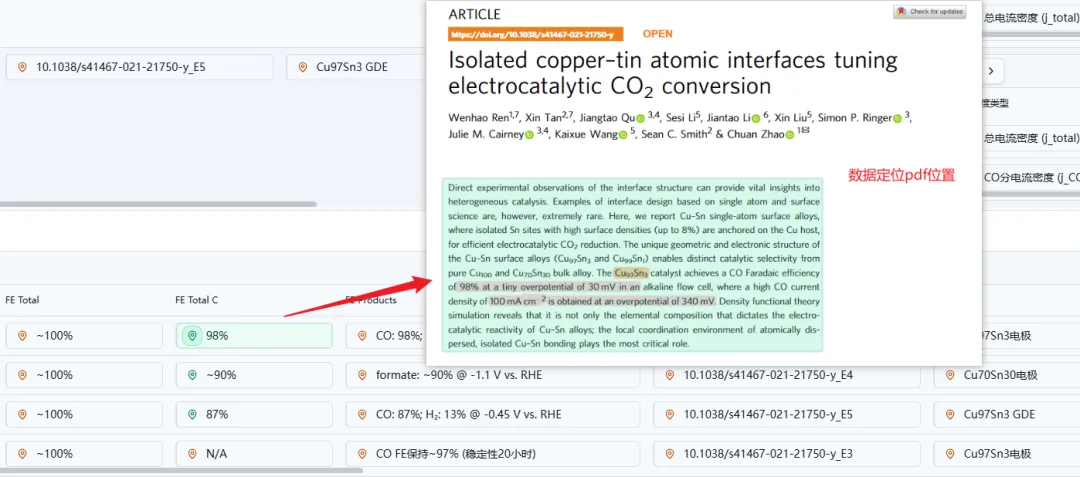 |
图14.数据定位界面
校对过程中若发现错误,无需跳转页面,直接在原位置修正即可。
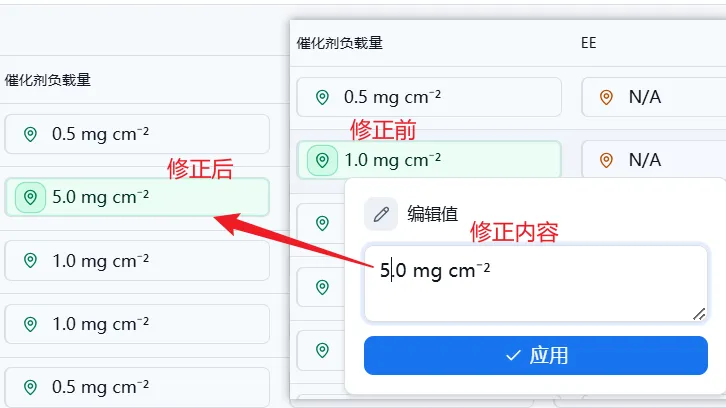 |
图15.数据修正界面
📌 第四步:数据导出——归档完成,批量获取结构化数据
1️⃣ 从「任务管理」进入数据预览;
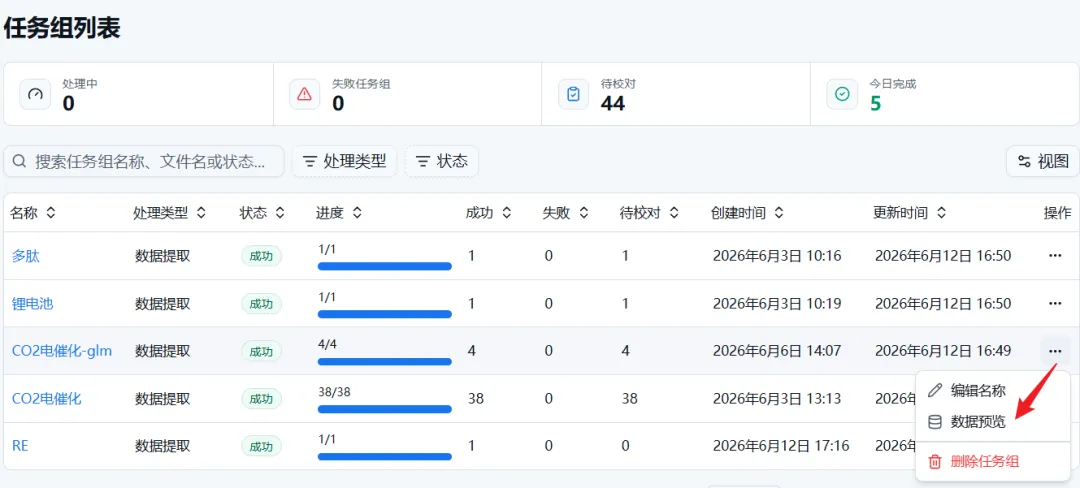 |
图16.数据预览进入通道
2️⃣ 选择导出方式:
3️⃣ 在「数据导出」模块中直接下载所需文件。
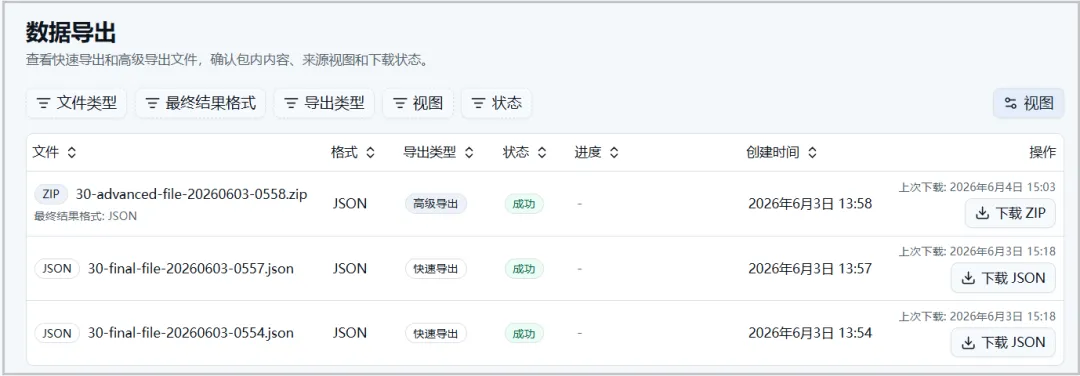
图17. 数据导出页面
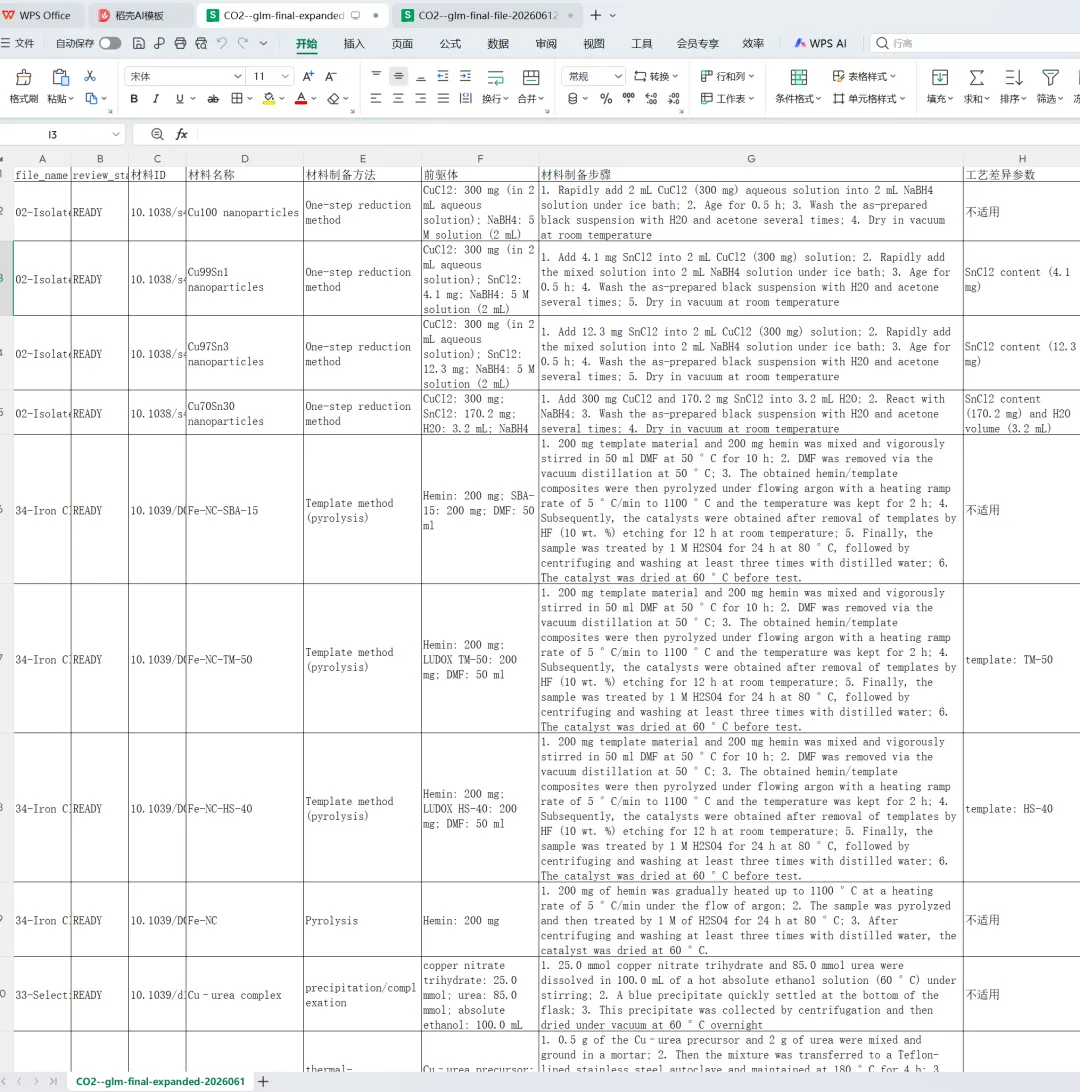 |
图18. 导出数据为csv格式
📌 关于我们
平台链接:https://data.nano-bd.com
联系邮箱:zhaoxx@nano-bd.com
联系电话:18912758985
