 夜雨聆风
夜雨聆风在 RAG、知识库和 Agent 工作流里,把非结构化文档变成 LLM 可读的 Markdown 往往是第一步。 MarkItDown 是微软开源的文档转换引擎;MarkItDown Desktop 则把它包装成本地、离线、可交互的跨平台桌面应用。 本文从 AI 应用落地视角,分五段介绍 Python AI 服务与 Avalonia 桌面端如何通过 Sidecar 协作,以及这套架构如何复用到其他 Python AI 能力的桌面化封装。
一、喂不好数据,大模型再强也白搭大模型应用,先卡在「喂数据」
很多企业做 AI 的第一步不是「选模型」,而是「喂数据」——合同 PDF、调研 Word、培训 PPT、扫描件图片,格式五花八门,LLM 直接吃不进去。常见路径有三条:
AI 场景 | 文档预处理的角色 |
RAG 检索增强 | 把原始文档洗净 → 切片 → Embedding → 向量库,Markdown 是最理想的切片输入 |
企业知识库 | 批量入库前需要统一格式、校验质量,避免脏数据污染检索结果 |
Agent 工具链 | Agent 读文件、写摘要、做问答时,需要 LLM 友好的结构化文本 |
Prompt 上下文 | 把本地资料快速转成可注入 Prompt 的语料,而不必手工复制粘贴 |
MarkItDown Desktop 的定位,是把「AI 文档预处理」从开发者命令行,变成业务人员也能用的本地工具:
AI 落地需求 | Desktop 的回应 |
语料本地处理,不出内网 | 全程离线,convert_local() 不访问外网 |
批量清洗文档再入库 | 拖拽/多选导入,Job 队列异步批处理 |
人工校验转换质量 | 右侧实时 Markdown 预览,确认后再导出 |
给 RAG/Agent 直接用的输出 | 一键导出 .md,或复制进下游工具链 |
非技术人员也能操作 | Avalonia 图形界面,无需懂 Python |
内嵌、Electron 还是 Sidecar?AI 能力几乎都在Python 生态,但 AI 产品需要稳定的桌面体验。三条常见路线:
方案 | 优点 | 缺点 |
Python 内嵌进 C# | 调用路径短 | GIL、依赖地狱、AI 进程崩溃会拖垮 UI |
Electron + Python 子进程 | 前端生态丰富 | 体积大、内存占用高 |
Sidecar 模式(独立子进程 + HTTP) | 语言解耦、易调试、易打包 | 多一层本机通信 |
我们选 Sidecar:桌面端管 UI 和生命周期,Python 端管 AI 转换逻辑,中间用本机 REST API 通信——把 Python 当「本地微服务」,桌面当「API Gateway + 前端」,和云上 AI 服务架构同构,只是跑在同一台机器上。
二、Python 扛引擎:本地 AI 服务四层架构
Python 端是整个应用的 AI 推理层(此处是文档理解与格式转换),职责单一:接收转换请求,调用 MarkItDown,输出 LLM 可消费的 Markdown。对外表现为一台只监听本机的 Web 服务。站在整条 AI 流水线的最前端。
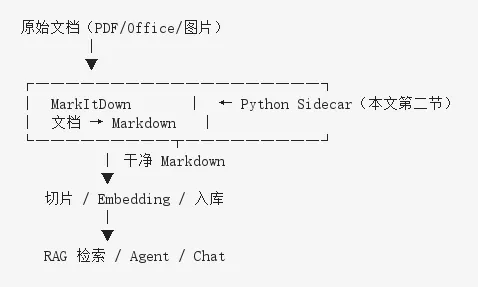

入口层 解决「桌面端如何发现 AI 服务」——动态端口、stdout 就绪信号,启动即可用。
API 层 用 FastAPI + OpenAPI,AI 服务可独立调试(Swagger / curl),不必每次拉起 GUI。这对 AI 团队迭代转换逻辑尤为重要。
业务层 处理 AI 任务的典型特征:耗时长、需异步、需进度反馈。大 PDF 转换可能数十秒,因此用 Job 队列而非同步 HTTP;信号量控制并发,线程池执行同步的 convert_local(),不阻塞事件循环。
基础层 面向 AI 场景的合规诉求:离线模式、路径白名单、日志脱敏——企业语料不能泄露。
Python 端目录长什么样

发布时用 PyInstaller 打成独立二进制,用户机器无需预装 Python——把 AI 运行时一并交付。异步 Job、只传路径、默认离线
问题 | 选择 | 对 AI 流水线的意义 |
同步还是异步? | Job 队列 + 进度 | 大批量语料预处理时 UI 不卡死 |
传文件还是传路径? | 只传本地路径 | 语料不经过 HTTP body,降低泄露面 |
进度怎么推? | SSE + 轮询兜底 | 人工盯着批量任务时可实时看进度 |
能不能上网? | 默认离线 | 金融/政务等敏感语料场景可放心用 |
输出格式? | Markdown | 直接对接 RAG 切片与 LLM Prompt |
三、Avalonia 当门面:让人真能用的语料台
桌面端不跑模型,但决定 AI 能力能否被非开发者用起来。它是 Human-in-the-loop 的语料预处理台:人负责选文件、看预览、确认质量,机器负责转换。
桌面壳在 AI 产品里干什么
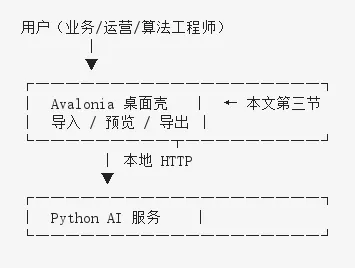
桌面端是 AI 能力的「产品化界面」:把 localhost 上的转换服务,变成双击可用的应用。视图、ViewModel、服务、核心——四层分工

视图层 承载 AI 语料工作流的关键交互:拖入待处理文档、查看转换后的 Markdown 是否符合预期、导出给下游 RAG 工具。
视图模型层 隔离 UI 与 AI 调用细节,用户点转换时,ViewModel 驱动 ConversionService 走完整 Job 流程。
核心层 是 AI 集成的枢纽: - SidecarProcessManager:AI 子进程生命周期 - MarkItDownApiClient:按 OpenAPI 契约调用 AI 服务 - Markdown 预览/导出:人工质检环节,避免脏语料流入向量库
桌面端目录长什么样

跨端共享:

导入、预览、导出——对应 AI 工作流哪几步
用户动作 | AI 流水线意义 |
拖拽导入 | 选定待入库语料 |
批量转换 | 离线批处理,适合知识库冷启动 |
实时进度 | 大批量任务可观测,便于估时 |
Markdown 预览 | 人工质检,确认标题/表格/段落结构 |
导出 .md | 直接交给切片、Embedding 脚本 |
离线模式 | 敏感语料不出本机 |
四、拖入 PDF 到导出 Markdown:两端协作全记录
从用户双击图标,到拿到可入库的 Markdown,背后是一条完整的 本地 AI 微服务调用链。
同一台电脑里的两台「逻辑服务」
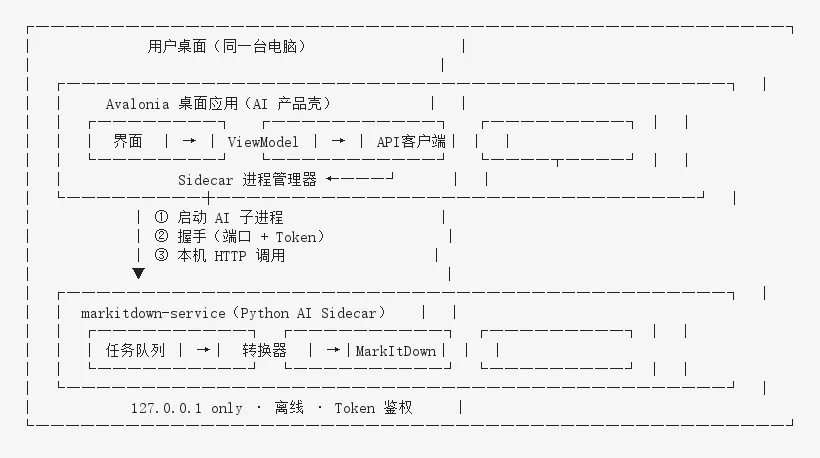
启动握手:stdout 里藏着端口和 Token

动态端口避免多实例冲突;stdout 是最轻量的「服务发现」——无需用户配置 localhost:8000。一次转换的五个瞬间。用户拖入 PDF,进入 AI 预处理流水线:

两端对齐的 API 契约:
端点 | AI 流水线作用 |
GET /health | 确认 AI 服务存活 |
GET /v1/formats | 查询可处理的语料格式 |
POST /v1/jobs | 提交预处理任务 |
GET /v1/jobs/{id} | 查询任务状态 |
GET /v1/jobs/{id}/result | 取回 Markdown 语料 |
GET /v1/jobs/{id}/events | SSE 进度流 |
POST /shutdown | 优雅关闭 AI 子进程 |
安全(AI 语料场景尤其重要):
层级 | 做法 |
网络隔离 | 只监听 127.0.0.1 |
身份校验 | 每次启动随机 Token |
输入校验 | 路径白名单、大小上限 |
数据最小化 | HTTP 不传文件内容,日志不记正文 |
PyInstaller + dotnet publish:AI 运行时与桌面壳一起交付

用户拿到的是「带 AI 引擎的桌面应用」——无需自行配置 Python 环境,双击即可开始语料预处理。下面是打包后的最终效果。
五、不止 MarkItDown:这套 Sidecar 还能包什么
MarkItDown Desktop 表面是文档转换工具,本质上是 AI 流水线最前端的本地预处理服务 + 跨平台产品壳。
要点 | 对 AI 落地的价值 |
Sidecar 解耦 | Python 跑模型/转换,桌面跑 UI,AI 崩溃不拖垮产品 |
stdout 握手 | 本地 AI 服务零配置启动 |
REST + Job | 适配 AI 长任务(推理、转换、OCR) |
安全三板斧 | 企业语料本地处理的可信基线 |
OpenAPI 契约 | AI 团队与客户端团队可并行开发 |
OCR、RAG、本地推理——照抄这张清单任何需要 Python 算力 + 桌面产品形态 的 AI 能力,都可以套用同一模板:
·文档 OCR / 版面理解
·本地 Embedding 或轻量模型推理
·RAG 语料批量预处理
·Agent 工具的本地执行器
·语音转写、图片标注等
六、总结
本项目核心旨在探索通用思路:将任意AI服务封装为可用、可落地的跨平台桌面应用。项目以Python承载各类AI核心能力,借助Avalonia搭建高颜值跨平台交互界面,并通过本地HTTP中间层实现技术解耦、独立调试与本地安全隔离,彻底解决原生AI脚本无界面、难部署、无法面向用户交付的痛点,为各类AI服务轻量化桌面化改造提供了通用、可复用的落地范式。
以上就是本次项目的完整探索与总结,这套通用AI服务桌面化封装方案实用性强、适配场景广泛。欢迎大家点赞、转发收藏,持续关注后续更多AI桌面应用开发、跨平台技术落地的干货分享与实战案例!
