 夜雨聆风
夜雨聆风最近我高强度使用 Claude Code、Codex,发现一个特别现实的问题:token 真的消耗得飞快。
以前关心的是 AI 能不能写代码、能不能修 bug。现在用得多了才发现,真正影响体验和成本的,往往是上下文。
Agent 为了完成一个任务,会不断读文件、查日志、跑测试、调用工具。能力确实更强了,但塞进模型里的内容也越来越多。
换句话说:
真正有价值的信息也许只有几行,但一次测试输出就可能占掉数千甚至数万 Token。 任务越复杂、工具调用越多,成本和延迟就越容易失控。更麻烦的是,模型吞进去的 内容越多,不代表判断一定更准,也可能只是噪音更多。
Headroom 要解决的正是这个问题。
这也是我关注 Headroom 的原因。它没有继续做“更聪明的 Agent”,而是盯上了一个 更底层的问题:模型到底有没有必要看到那么多原始输出?
它不是另一个 AI 编程助手,也不是 RAG 或记忆库,更像是放在 Agent 与模型服务 之间的一个:
它先处理工具输出、日志、文件、RAG 检索结果和对话历史,再把更短、更聚焦的内容 交给模型。这个思路并不花哨,却很符合我对 Agent 工程化的判断:与其一味扩大 上下文窗口,不如先把上下文里的废话清出去。
Headroom 值得高频 AI 编程用户试用,但不能只看压缩率。最终要看它省下 Token 之后,是否仍能保住任务成功率、缓存收益和关键线索。

Headroom 官方演示:压缩工具输出后仍保留关键错误信息
Headroom 到底是什么?
如果只看一句话介绍,Headroom 很容易被理解成“文本摘要工具”。这个理解低估了 它。
Headroom 是一个开源的 AI Agent 上下文压缩工具,采用 Apache 2.0 许可证。它会在内容进入大模型之前,尝试删除重复、模板化和低价值信息。按照官方架构, 不同内容会交给不同组件:
JSON 由 SmartCrusher 处理 代码由 AST 感知的 CodeCompressor 处理 普通文本可由 Kompress 模型处理 ContentRouter 负责识别内容类型 CCR 负责缓存原文,需要时可以取回
我比较认可的一点是,它没有把所有内容交给同一种摘要算法。代码、JSON 和普通文本 的信息结构完全不同,用同一把剪刀处理,风险很高。
所以它不是简单把内容截断到固定长度,而是尝试根据代码、日志和结构化数据的特点, 保留更可能影响模型判断的信息。
一句话理解:
它值得关注,是因为它处理了 Agent 工作流里最容易被忽略的成本来源,又不要求你 更换现有模型或重写整个应用。
适合人群: 高频运行 AI 编程 Agent、经常处理长日志或 RAG 结果,并且已经有 测试和人工 Review 链路的开发者与团队。
它真正解决的,是工具输出膨胀
我以前讨论上下文管理时,注意力更多放在对话历史上。但在真实开发任务里,真正容易 快速膨胀的,往往不是你和 Agent 说了多少句话,而是工具返回了多少内容。这也是 Headroom 最打动我的切入点:它把工具输出当成一个需要独立治理的对象。
测试和日志太长
比如你让 Agent 修复一个测试失败问题。
它执行测试后,终端可能返回大量成功用例、重复警告、依赖加载信息和调试日志。 真正关键的,也许只有一个错误堆栈和两个文件路径。
把整段输出原样交给模型会产生两笔成本:一笔是看得见的 Token 账单,另一笔是更 隐蔽的注意力成本。
Headroom 会尝试保留错误、异常和状态变化,压缩重复内容,再把结果交给模型。 这类场景也是我最想优先测试的,因为日志通常重复度高,关键线索又相对明确。
代码搜索结果太多
Agent 搜索一个函数名时,可能一次拿到几十甚至上百条结果。
其中不少只是重复引用、生成文件或无关测试代码。全部送进模型,不仅浪费 Token, 还会挤占真正相关代码的注意力。这比单纯“上下文窗口不够长”更常见。
RAG 检索结果过于冗余
很多 RAG 系统会一次召回多个文档片段。
检索系统认为“相关”,不代表每一段都值得进入模型。我更愿意把 Headroom 放在 召回和生成之间,作为二次压缩层,而不是一开始就减少召回数量。
多 Agent 工作流不断累积成本
当你开始使用 Codex、Claude Code、Cursor、Aider,或者自己搭建 LangChain、 Agno、LiteLLM 工作流时,每一步都可能产生新的上下文。
单次任务不一定明显,但每天运行几十次、几百次之后,工具输出产生的成本就会变得 肉眼可见。Headroom 真正有价值的用户,也正是这类已经把 Agent 用起来,而不是 还停留在偶尔聊天的人。
Claude Code、Cursor、Codex 怎么接入?
接入方式是我判断这类基础设施工具时最看重的部分之一。压缩率再高,如果要大改现有 工作流,我大概率不会长期使用。
Headroom 提供了包装命令、透明代理、代码库和 MCP 等多种接入方式。
最快方式:直接包装编程 Agent
如果只是想快速感受完整能力,可以先安装完整版本:
pip install "headroom-ai[all]"然后按你使用的工具启动:
headroom wrap claudeheadroom wrap codexheadroom wrap cursorheadroom wrap aiderheadroom wrap copilot官方兼容矩阵显示,Claude Code、Codex、Aider 和 Copilot CLI 可以通过包装命令 启动。Cursor 会输出一份配置,需要手动粘贴一次。
对个人开发者来说,我会优先从这种包装模式开始。它比改业务代码更容易撤销,也更 适合观察压缩前后的差异。
通用方式:作为本地代理
headroom proxy --port 8787任何支持 OpenAI 兼容接口的客户端,都可以尝试把 API 地址指向这个本地代理。
请求先经过 Headroom 完成上下文压缩,再转发给模型服务。对团队项目,我更倾向于 这种代理方式:影响范围清楚,也容易通过切换 API 地址进行回滚。
自定义 Agent:直接在代码里调用
Python 应用可以使用 compress():
from headroom import compresscompressed = compress(messages, model="your-model")项目还提供 TypeScript SDK,以及 LangChain、LiteLLM、Agno、Strands、 Vercel AI SDK 和 MCP 集成。
这意味着 Headroom 既可以服务现成的 AI 编程工具,也能放进自定义 Agent 应用。 我对它的评价因此高了一档:它不是只能跑演示的单点工具,而是有机会进入现有 Agent 工具链。
官方数据:它能省多少 Token?
这是整篇文章最容易让人兴奋,也最需要冷静的一部分。
先说明数据口径:
官方列出的真实 Agent 工作负载如下:
这组结果不能说明“Headroom 永远能省 92%”,但能说明另一件事:
内容越结构化、重复越多,Headroom 的压缩空间通常越大。
代码搜索和 SRE 排障节省了 92%,代码库探索则是 47%。我反而觉得 47% 这个数字 更值得看,因为它提醒我们:代码本身信息密度高,安全压缩空间没有日志那么夸张。
官方还公布了部分准确率结果:
这些数据说明项目团队在同时评估压缩率与任务质量,但我不会因此直接得出“任何场景 都能无损节省 60% 到 95% Token”的结论。
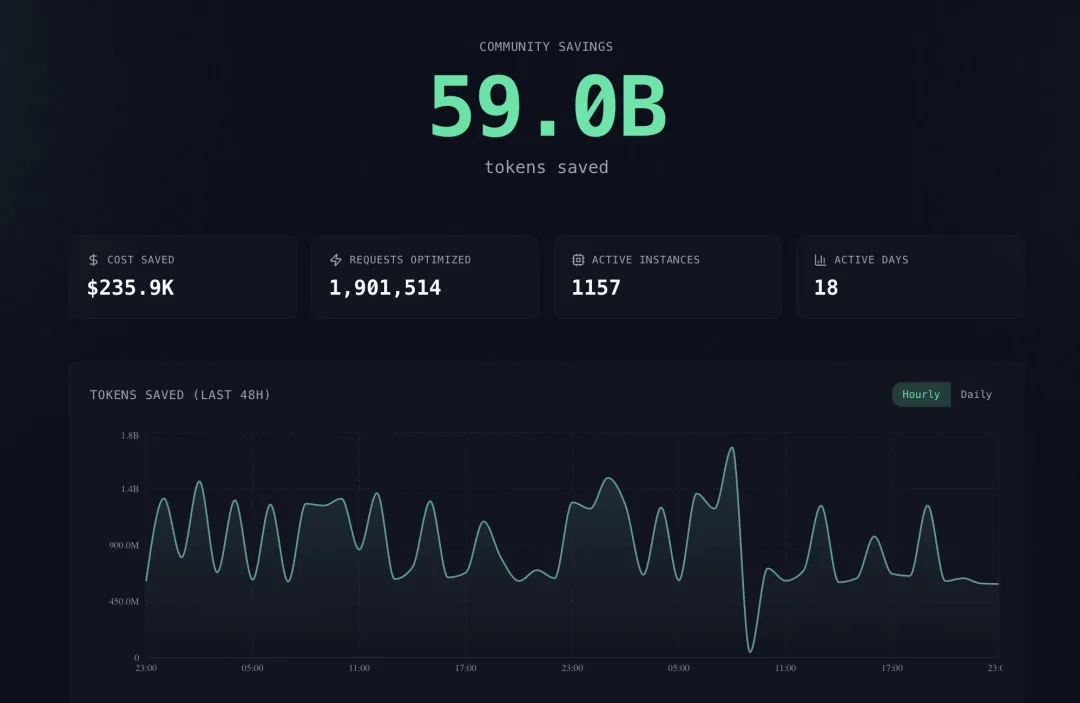
Headroom 官方社区节省数据看板
原因包括:
官方基准不等于独立第三方评测 不同代码库和日志格式差异很大 模型、算法和参数会影响结果 Token 减少不一定等于账单同比例下降 压缩过程可能增加延迟和本地资源消耗
所以在我这里,官方数据只能回答“值不值得试”,不能回答“接入后一定能省多少”。 后一个问题必须用自己的代码库、日志和模型做 A/B 测试。
最重要的指标,不是压缩率
这也是我对 Headroom 最大的顾虑。
上下文压缩工具最怕的不是压得不够多,而是把关键线索压没了。
对 AI 编程来说,下面任何一项丢失,都可能让 Agent 走错方向:
错误堆栈中的第一处异常 一个关键文件路径或行号 配置文件中的特殊字段 函数签名或 import JSON 里的异常记录 日志中的状态变化顺序
Headroom 提供 CCR 可逆压缩机制,把原始内容缓存在本地。当模型发现信息不足时, 可以通过 headroom_retrieve 取回原文。
这也是它比普通摘要工具更有价值的地方。
但“可取回”不等于“不会漏”。
模型必须先意识到自己缺少信息,才会主动请求原文。如果关键细节被压缩掉,而模型 没有发现,它仍然可能基于不完整上下文继续推理。
所以如果让我实际评测 Headroom,我不会把“节省比例”放在第一位,而会同时记录:
错误信息是否完整保留 文件路径、行号和代码结构是否还在 Agent 是否频繁重新请求原文 同一任务的最终成功率是否下降 总延迟和实际账单是否真的降低
如果 Token 省了 80%,但 Bug 修错了,那就是负优化。
放进 AI 开发工作流的正确位置
在我自己的 AI 开发工作流设想里,Headroom 最适合放在执行阶段:
需求 / PRD / Issue ↓OpenSpec 约束需求边界 ↓Superpowers 拆解任务 ↓Cursor / Codex / Claude Code 执行 ↓读取文件 / 搜索代码 / 跑测试 / 查日志 ↓Headroom 压缩工具输出和上下文 ↓LLM 继续推理并修改代码 ↓lint / test / typecheck / 人工 Review我不会让它参与需求判断,也不会让它决定 Agent 应该做什么。
它处理的是:
如果已经在使用 OpenSpec、Codex、Claude Code, 我会把 Headroom 看成一个可插拔的执行层组件,而不是另一套需要推倒重来的工作流。
接入之前,先看清这五个坑
不要安装错包
这里有个很容易踩的坑:正确的 Python 包名是:
pip install "headroom-ai[all]"不是:
pip install headroomPyPI 上的 headroom 是另一个同名命令行 AI Agent,与本文介绍的上下文压缩项目 无关。
完整安装并不轻
不同功能可能涉及 ONNX Runtime、Transformers、Hugging Face 模型、 Tree-sitter、向量检索、FastAPI 和代理服务。
企业网络还可能遇到证书检查、模型下载和 Rust 构建问题。
我的选择会更保守:先从单个 Agent 和非关键项目开始,不会第一天就把代理、记忆、 图谱和图像压缩全部打开。
本地运行不等于完全离线
Headroom 的压缩和原文缓存可以在本地完成,但压缩后的请求仍然会发送给你配置的 模型 Provider。
所以我不会因为“本地运行”四个字,就默认它解决了全部隐私问题。它减少了额外的 数据中转,却没有改变原有模型服务的数据边界。
多一层代理,就多一层故障点
代理层会带来新的配置、日志、版本兼容、安全审计和回滚需求。
v0.25.0 仍在持续增加压缩安全保护,并修复空压缩结果、工具 Schema 字段保留、 Codex 传输和 CCR 异常等问题。
这既说明项目迭代活跃,也说明它还不是可以无脑塞进生产环境的成熟基础设施。关键 链路必须锁定版本、记录压缩前后内容,并保留旁路开关。
Token 变少,不代表总成本一定更低
如果压缩导致请求前缀频繁变化,可能降低模型服务商的 Prompt Cache 或 KV Cache 命中率。
Headroom 提供 CacheAligner 来处理这个问题,但真实收益仍取决于模型、缓存定价 和调用模式。
真正需要计算的是:
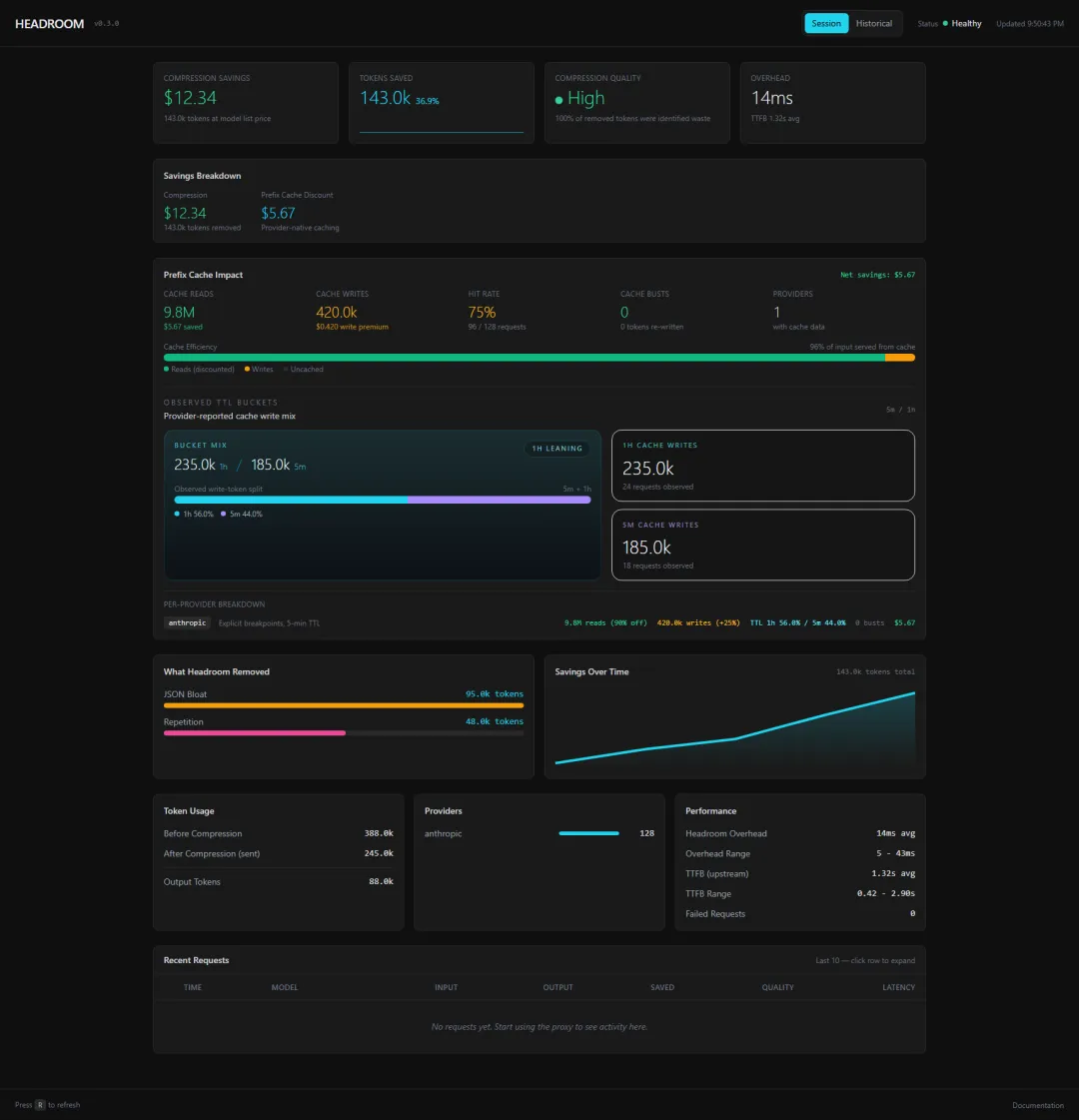
Headroom 官方仪表盘中的压缩收益与缓存影响
哪些人值得试,哪些人可以先跳过?
Headroom 比较适合:
高频使用 Claude Code、Codex、Cursor、Aider 的开发者 经常处理超长测试日志和代码搜索结果的人 正在开发多工具 Agent 的团队 有大量 RAG 检索内容的应用 有明确 LLM API 成本压力的项目 能建立任务成功率和回归测试的团队
下面这些情况可以先跳过:
只是偶尔使用 ChatGPT 的用户 没有 API 成本压力的人 项目还没跑通就开始过早优化 Token 的团队 无法保留原始数据链路的关键业务 不愿维护代理、模型和环境变量配置的人 没有 lint、测试或人工 Review 的自动化流程
尤其是生产排障、金融、医疗、合规和数据迁移场景,我不会只依赖压缩后的内容作出关键判断。
值得试,但先做小范围 A/B 测试
Headroom 不是那种打开页面就让我觉得“必须马上安装”的 AI 应用。
但我愿意持续关注它,因为它更像一个底层效率工具:不直接替我写更多代码,而是试图 减少 Agent 每次推理前需要吞下的噪音。
从官方数据看,它在代码搜索、日志排障和 Issue 分类等高冗余场景中,确实展示出了 明显的 Token 压缩空间。这些场景也最适合先试。
对 Claude Code、Codex、Cursor 和 Aider 的直接支持,也让它不再只是一个需要 自己集成的实验性库。
但我不会因为“最高节省 92%”就直接接入。它真正的价值,不能只用压缩率判断。
A/B 测试需要一起评估:
最终任务成功率 关键信息保留率 Prompt Cache 命中率 额外响应延迟 原文取回次数 接入和维护成本 失败后的回滚能力
AI Agent 下一阶段比拼的不只是模型能力。
上下文管理、成本控制、缓存利用率,以及可验证的执行链路,同样会决定一套工作流 到底是“看起来很智能”,还是“真的能长期运行”。
你在 AI 编程中遇到过最夸张的 Token 消耗是什么场景?欢迎在评论区分享。
关注「AI开源风向标」,获取持续更新的 AI 与开源开发工具 清单。
参考资料
https://github.com/chopratejas/headroom https://headroom-docs.vercel.app/docs https://headroom-docs.vercel.app/docs/benchmarks https://github.com/chopratejas/headroom/releases/tag/v0.25.0 https://pypi.org/project/headroom-ai/
