 夜雨聆风
夜雨聆风从五层蛋糕的宏观视角出发,先从第三层芯片层中的 GPU 开始,因为它是这一轮 AI 基建投资里最先爆发、最先验证商业价值、也最能牵引上下游变化的核心赛道。
要理解GPU领域,首先要理解各种技术的关键细节,前期花了非常多时间仍然摸不到脉络,直到最近发现高中物理学的二极管/三极管知识帮助很大!因为究其根本都是从半导体的基本原理开始演进,于是还是耐心一步步从GPU的发展历史开始琢磨,总算让学习进程重新on track。
先确认下研究对象:AI 算力芯片大概可以简单分成“GPU 和 ASIC”两类,按用途分也可以分成训练和推理。由于在这两个领域里,NVIDIA都是绝对的领先优势(尤其是在训练GPU里,市场份额>90%),所以从NVIDIA的GPU迭代历史开始:
一、初代GPU,以GeForce 256代表
在 1990 年代末,电脑游戏从 2D 走向 3D,屏幕里不再只是平面图像,而是有坐标、有角度、有光照、有纹理的三维世界;这些计算当然可以交给 CPU 做,但 CPU 更像少数几个很聪明的专家,适合复杂判断,却不适合同时处理海量重复的小任务。
1999 年,NVIDIA 发布 GeForce 256,并把它称为“世界第一颗 GPU”。这时候的 GPU,最核心的硬件可以简单理解成三部分:
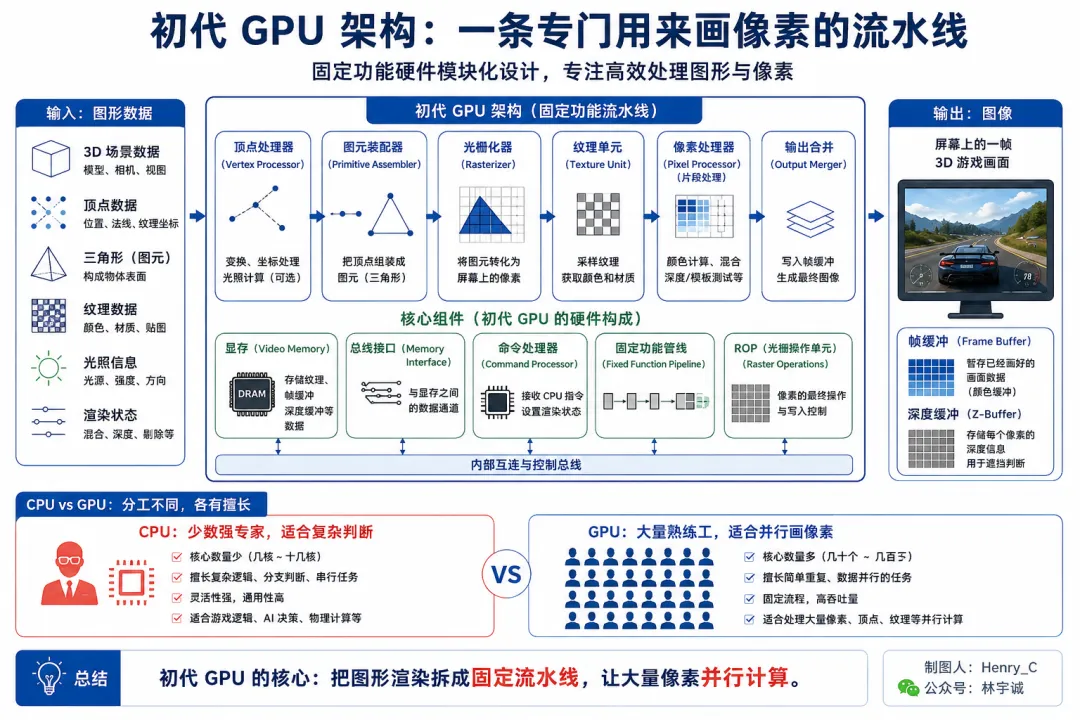
1,几何与光照引擎(包括顶点处理器、图元装配器等),它负责判断物体在屏幕上的位置,以及光照打在物体上之后应该呈现什么明暗效果。
2、纹理与像素渲染(如像素处理器),它负责把材质、颜色、深度、透明度这些信息合成到每一个像素上,让画面从几何骨架变成可见的 3D 世界。
3、显存控制器与帧缓冲,它负责把纹理数据、中间结果和最终画面放在 GPU 旁边的高速工作台里。
这三个工作组件,都需要大量、简单的并行计算(比如渲染每个图形),GPU蚂蚁雄兵般的技术架构,对比CPU要有效率得多。
二、GPU演进到现在,以Blackwell B200为代表
如果初代 GPU 处理的是一帧游戏画面,那么 Blackwell B200 处理的就是一串又一串 token。
大模型像工厂开工,用户每问一句话,模型都要读取参数、处理上下文、生成下一个 token;所以 Blackwell 的核心任务,已经不是单纯把峰值算力做高,而是尽量用更低成本、更低功耗、更高稳定性,持续生产更多 token。
用五个组件理解 Blackwell GPU到底在解决什么问题:
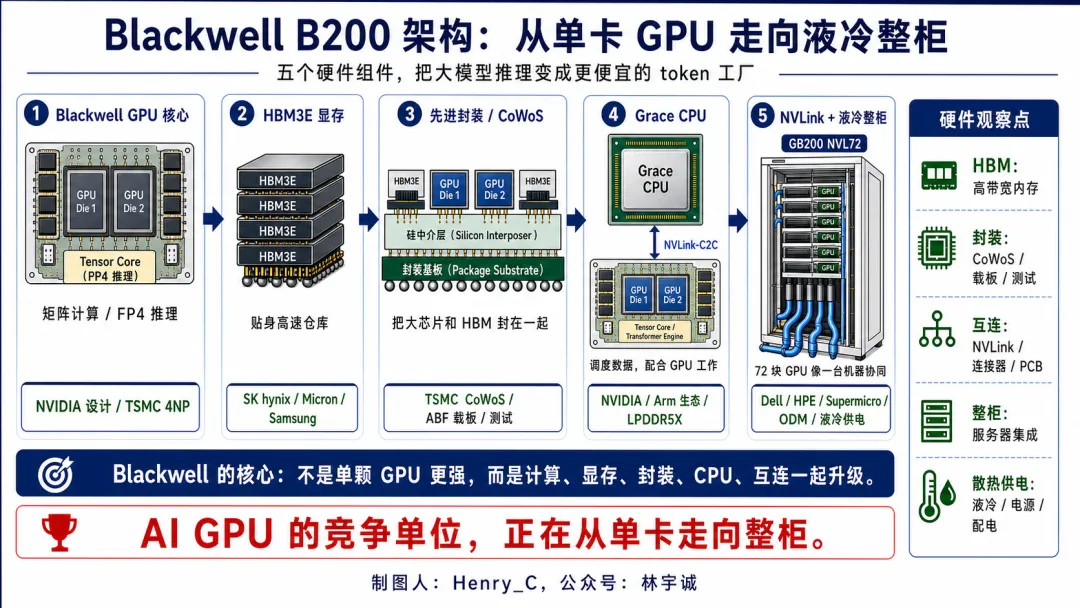
1、Blackwell GPU 核心:从通用计算走向低精度矩阵工厂
Blackwell GPU 的核心仍然是更大规模的矩阵计算单元(尤其是 Tensor Core)。这背后带动的主要是先进制程和 EDA 生态。Blackwell 数据中心 GPU 由 NVIDIA 设计,采用 TSMC 4NP 工艺制造;同时,芯片复杂度提升也会继续强化 Cadence、Synopsy等 EDA 和仿真软件的重要性。
2、HBM3E:显存从配件变成算力瓶颈,最近股市的绝对主角!
如果 Tensor Core 是机床,HBM3E 就是贴在机床旁边的高速仓库。大模型运行时,模型参数、中间结果和 KV Cache 都要不断进出显存。部分的核心供应商是大名鼎鼎的SK hynix、Micron、Samsung。
3、先进封装:GPU、HBM 和高速互连必须靠得足够近
Blackwell 的另一个关键变化,是封装重要性继续上升。NVIDIA 官方资料显示,Blackwell 架构 GPU 使用两个接近光罩极限的大 die,并通过 10TB/s 的芯片间连接组成统一 GPU;这意味着 GPU die、HBM、硅中介层、封装基板、散热结构必须在一个高度复杂的封装系统里协同工作。
4、Grace CPU:GPU 需要一个调度中心
Grace 是 NVIDIA 第一款面向数据中心、可独立作为服务器主控的完整 CPU 产品(注:官网原文),英伟达连CPU也开始自己做了!
5、NVLink + 液冷整柜:竞争单位从单卡走向整柜
Blackwell 最值得投资者重视的变化,不是 B200 单卡有多强,而是 NVIDIA 把竞争单位推到了整柜。GB200 NVL72 把 72 颗 Blackwell GPU 和 36 颗 Grace CPU 放进液冷整柜,并用第五代 NVLink 连接起来。这一变化直接带动服务器整柜、交换网络、铜缆、连接器、PCB、液冷、电源和数据中心改造。
Blackwell对比上代技术架构的核心演进逻辑是:它不是让单颗 GPU 更强,而是把计算、显存、封装、CPU、互连和整柜系统一起升级。
三、下一代GPU,Vera Rubin(预计2026年 Q3投产)
如果说 Blackwell 解决的是大模型推理成本问题,那么 2026年1月5日在CES 2026上英伟达发布的Vera Rubin 想解决的问题更大:
当 AI 进入 Agent、长上下文、多模态和持续推理阶段后,整座数据中心能不能像工厂一样稳定生产智能?
NVIDIA 在 2026 年 3 月发布 Vera Rubin 平台时,已经不只是讲一颗 Rubin GPU,而是把 Vera CPU、Rubin GPU、NVLink 6 Switch等一整套芯片和系统放在一起讲;黄仁勋的说法也很直接:这是“seven breakthrough chips, five racks, one giant supercomputer”。
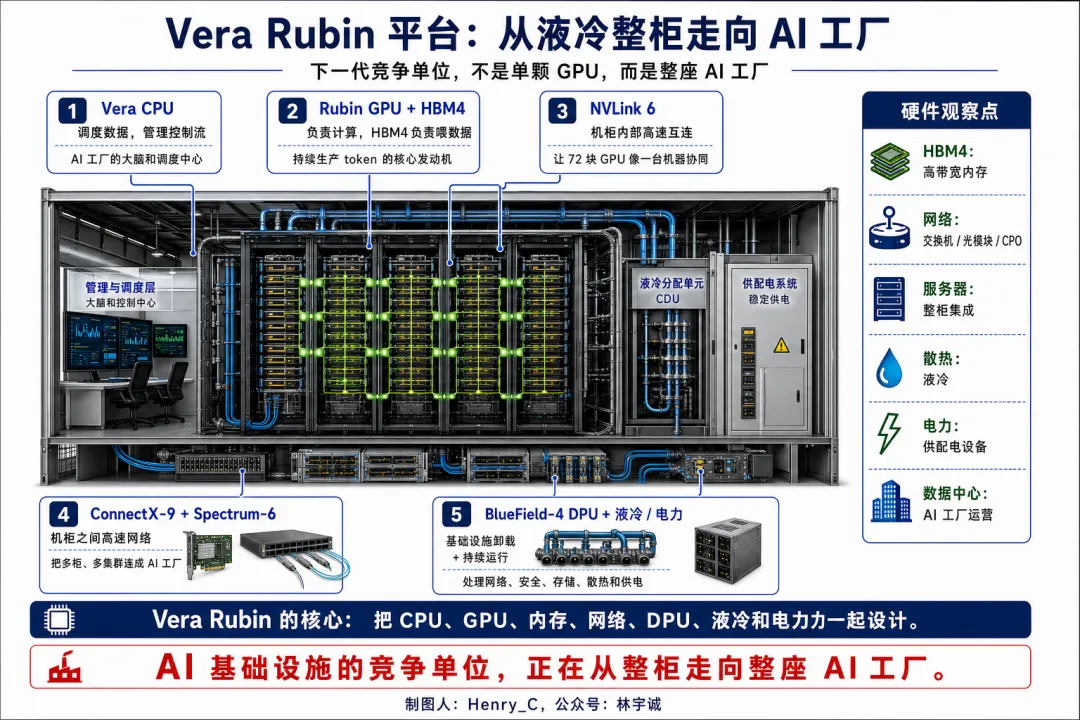
1、Rubin GPU + HBM4:显存正式站到主战场中央
焦点是产能紧缺的HBM4。公司层面仍然围绕三巨头 SK hynix、Micron、Samsung, NVIDIA 与 SK hynix 在 最近宣布多年期内存技术合作,也说明 HBM 已经从“采购零件”变成“共同定义下一代平台”的战略资源。
2、NVLink 6:GPU 之间的路,比以前更值钱
Vera Rubin 的 NVLink 6 把互连继续推高。NVIDIA 官方技术博客显示,Rubin GPU 连接 NVLink 6 后,每 GPU 双向带宽达到 3.6TB/s,是上一代的两倍;潜在要适配迭代的领域包括高速铜缆、背板、连接器、PCB、交换芯片和集群互连等
3、ConnectX-9 + Spectrum-6:网络不再只是配套设备
Vera Rubin 把 ConnectX-9 SuperNIC 和 Spectrum-6 Ethernet Switch 纳入平台叙事,这说明网络已经不是服务器旁边的配套设备,而是 AI 工厂能否规模化运行的一部分。“未来要站在光里的”包交换机、网卡、光模块、CPO、DSP、SerDes 和数据中心交换系统等众多玩家,比如通信巨头Broadcom、老二Marvell、Arista、Coherent、Lumentum、旭创科技、新易盛等
4、BlueField-4 DPU + 液冷电力:AI 工厂绕不开物理世界
BlueField-4 DPU 的角色,是把网络、存储、安全、隔离和基础设施管理这些任务从 CPU/GPU 身上卸下来;在 AI 工厂里,这类工作虽然不直接生成 token,却决定了系统能不能稳定运行更底层的问题是功耗和散热,这个产业链清单还待研究中.
Vera Rubin 对比Blackwell的核心演进逻辑是:AI 算力的竞争单位,正在从单颗 GPU 走向整柜,再从整柜走向整座 AI 工厂。
看 GPU 的迭代,现在有了一个轮廓
首先,GPU 从一开始就是为大量重复计算而生。只不过 1999 年重复的是像素和三角形,2026 年以后重复的是 Agent 工作流里不断发生的推理、记忆、调用和反馈。
第二,NVIDIA 的护城河不只是 GPU 芯片,而是它每一代平台升级,都会把硬件、软件、网络、整柜和生态一起往前推,所以也带动了每一次升级的“瓶颈”理论和大量市场火热的标的。从 GPU 核心,迁移到 HBM、先进封装、NVLink、交换网络和光模块、网络、液冷乃至电力和数据中心运营。英伟达GPU平台是其中的关键的产业迭代引领者。
下周开始看看目前对英伟达GPU造成长期威胁的ASIC芯片。
