 夜雨聆风
夜雨聆风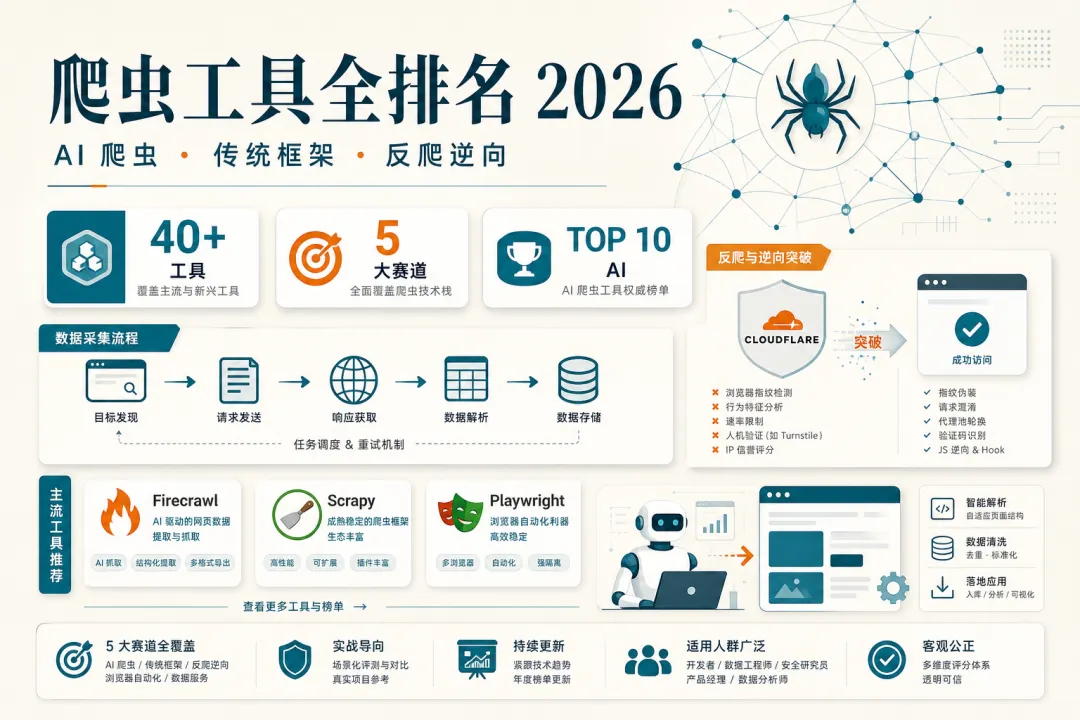
做数据采集的人大概都经历过这个循环:先用 requests 写脚本,遇到 403 换 Playwright,页面结构一变 parser 全废,再加代理、验证码、指纹伪装……最后发现选错工具比写错代码更费时间。
2026 年又多了一层变量:LLM 把「写选择器」这件事干掉了一大半。Firecrawl、Crawl4AI、ScrapeGraphAI 这类工具直接把网页变成 Markdown 或 JSON,喂给 RAG 管道就能用。但 AI 爬虫不是万能——高并发单域抓取、毫秒级价格监控、复杂登录态维护,传统方案照样能打。
这篇把国内外社区(Proxyway、Scrappey、SeekTool、看雪/DataMiner 圈、GitHub 热门项目)里反复出现的工具按赛道排名,每个都写清楚适合什么、不适合什么。排名有主观成分,但依据是 2025–2026 年多家测评的成功率、社区活跃度和实际落地反馈,不是拍脑袋。
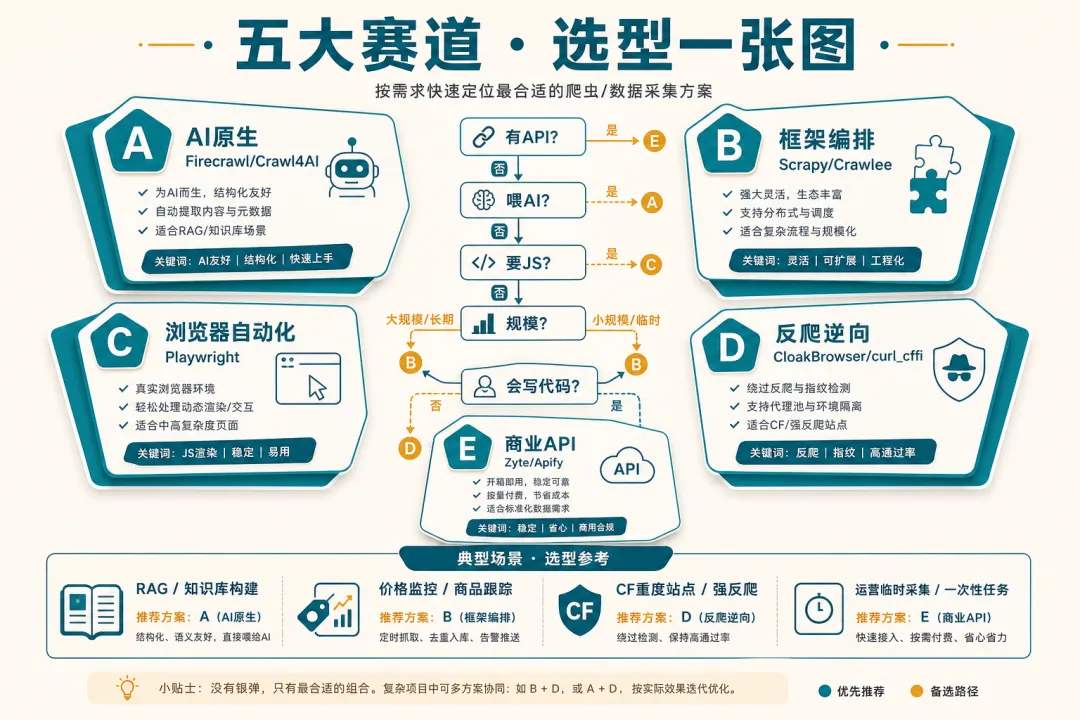
很多人一上来就问「哪个爬虫最好用」——这个问题本身就没法答。2026 年的工具按职责可以切成五块,每块里的第一名放到另一块里可能垫底:

这类工具的核心卖点:把网页洗干净,输出 LLM 能直接吃的格式。排名综合考虑 RAG 适配度、反爬能力、价格、开源程度和社区热度(参考 SeekTool.ai、Proxyway 2026、AICraftGuide 等)。
r.jina.ai/ 就返回 Markdown。不用注册 key 就能试(有限额),适合快速验证「这个页面能不能采」。
AI 再火,底层还是 HTTP 请求和浏览器驱动。这类工具不写选择器逻辑,但提供基础设施——你要自己写 parser,但框架帮你管队列、重试、并发。
| 排名 | 工具 | 语言 | 核心优势 | 主要缺点 | 最适合 |
|---|---|---|---|---|---|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 7 | |||||
| 8 | |||||
| 9 | |||||
| 10 |
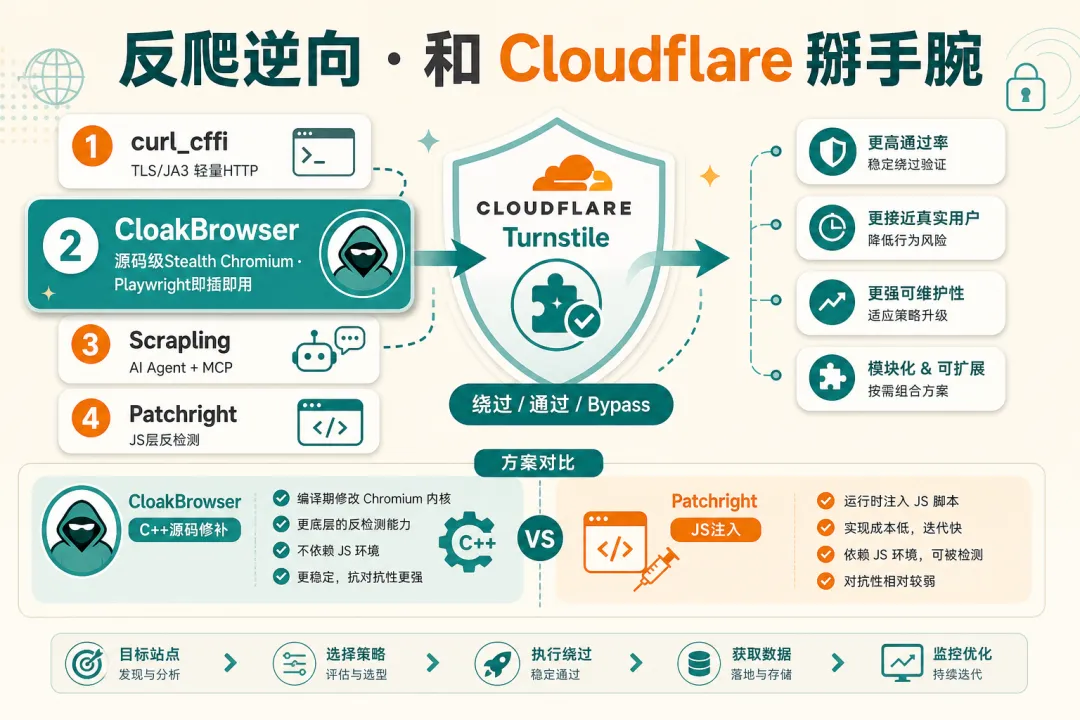
2026 年的反爬已经不是换个 User-Agent 就行的年代。Cloudflare Turnstile、Akamai、DataDome 做的是多维验证:TLS 指纹、HTTP/2 帧序、Canvas/WebGL、行为轨迹、IP 信誉。下面这些是社区实测讨论最多的逆向向工具。
今年有个绕不开的新名字:CloakBrowser。GitHub 两个月冲到 2.5 万 star,本质是改了 Chromium 源码的「真浏览器」——不是 JS 注入伪装,而是 58 处 C++ 级指纹修补,还能直接替换 Playwright 的 import。如果你已经在用 Playwright 但被 Turnstile 卡住,它值得优先试。
pip install cloakbrowser,把 from playwright... 换成 from cloakbrowser...,其余代码基本不动。底层是自编译 Chromium(当前 v146),在 C++ 层改 Canvas、WebGL、音频、字体、GPU、WebRTC、TLS(JA3/JA4)和 CDP 检测信号。可选 humanize=True 模拟贝塞尔鼠标轨迹和逐字输入。| 工具 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| curl_cffi | |||
| CloakBrowser | |||
| Scrapling | |||
| Patchright | |||
| FlareSolverr | |||
| mitmproxy |
不想自己维护浏览器集群和代理池,直接买 API。Proxyway 2025 报告测了 15 个目标、每站约 6000 URL,下面是综合解锁率、速度和价格的排名。
| 排名 | 服务商 | 解锁率* | 优势 | 劣势 | 起步价 |
|---|---|---|---|---|---|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 7 | |||||
| 8 |
不写代码也能采——但天花板明显,复杂登录、滑块、动态加载一多就吃力。适合运营、市场、小老板快速拿数据。
| 排名 | 工具 | 类型 | 优点 | 缺点 |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 |
| 场景 | 推荐方案 | 不推荐 |
|---|---|---|
| RAG 知识库灌数据 | ||
| 电商价格监控 | ||
| 招聘/地图/社交批量 | ||
| 结构多变的资讯站 | ||
| Cloudflare 重度站 | ||
| App 接口逆向 | ||
| 运营临时采一表 | ||
| 高隐私内网采集 | ||
| AI Agent 联网搜索 |
最后列几条社区里骂最多的坑,每条的解法比工具名更重要。
| 坑 | 表现 | 解法 |
|---|---|---|
| 该用 API 硬爬 | ||
| AI 爬虫包打天下 | ||
| 忽视 TLS 指纹 | ||
| 裸 Playwright 硬刚 | ||
| 数据中心代理 | ||
| 不写爬虫礼仪 | ||
| 选择器焊死在 HTML | ||
| 低估运维成本 |
2026 年的爬虫工具圈,表面是 AI 和传统两派打架,实际更像是分工细化:该用 HTTP 的用 HTTP,该用浏览器的用浏览器,该花钱买省心的就买 API,该用 AI 提取的也别手写选择器了。
如果真只记一张表:个人学习从 curl_cffi + BeautifulSoup 起步;正经项目 Playwright + Scrapy/Crawlee;Playwright 被检测换 CloakBrowser;AI 项目 Crawl4AI 或 Firecrawl;不想写代码 八爪鱼或 Thunderbit;硬骨头 Zyte / CloakBrowser + 代理。
工具更新很快——CloakBrowser 两个月冲上 GitHub 热榜、Firecrawl 的 Agent、Scrapling 的 MCP 每个月都在变。选型时去 GitHub 看最近 commit 时间,比看两年前的一篇「最全爬虫教程」靠谱得多。
