 夜雨聆风
夜雨聆风点击“科技元界”关注我们

过去一年,AI行业越来越频繁地谈到一个问题:大模型已经很会说话、写代码、生成图片和视频,但它到底懂不懂真实世界?这个问题并不新。
早在上世纪,心理学家 Kenneth Craik 就提出,人脑会在内部建立一个“小模型”,用来预判外部世界会怎样变化。后来,随着大模型在一些领域应用的局限性,世界模型应运而生——真正的智能不能只会处理符号和语言,还要能理解环境、预测变化,并据此做决策。
6月12日,在北京智源大会上,智源研究院推出了世界模型最新成果,悟界·Physis-v0.1和悟界·Robo-Brain Orca。
智源研究院院长王仲远提到,为什么现在的机器人不能像人类一样到处走,执行各种各样的任务?

因为世界常识、世界物理规律是缺乏的,可以在操作台上、流水线上很好地完成一些特定的任务,但不具备泛化性和通用性。
一瓶未开封的水和盛满咖啡的杯子放在桌子旁,人类能够预测两者跌落时产生的物理状态和对真实物理世界的影响,其差异是很大的,水瓶掉下去可能只会产生撞击声音,但咖啡却会洒落一地,这就是人类的世界模型。
王仲远表示,随着Next-Token Prediction研发的深入,可以看到人工智能正在发生一场重大的范式变革。早年大语言模型处理的是文字,而多模态模型开始引入图像、音频、脑信号,接下来要解决的就是真实物理空间的时空问题、物理规律、物理常识。
所以,世界模型要解决是“AI能不能判断一个动作之后会发生什么”。机器人抓杯子,杯子会不会滑落?自动驾驶看到行人,下一秒该不该减速?智能体操作设备,按下按钮后系统会出现什么变化?这些都不是简单的文字接龙,而是对真实世界状态变化的预测。
智源研究院是国内最早提出并开展世界模型研究的科研机构。
2023年智源大会上,图灵奖得主杨立昆(Yann LeCun)就阐述了新一代世界模型的概念;2024年智源大会上,智源研究院提出的人工智能大模型技术路线预判,明确指出世界模型是下一代大模型技术;2024年发布的悟界·Emu3和2025年发布的悟界·Emu3.5,更是全球首个原生多模态世界模型。
基于在大模型领域持续的技术积累与前瞻布局,2026年悟界·Physis-v0.1的诞生正是基于智源对人工智能发展路径的判断以及从“悟道”到“悟界”的技术传承与延续。
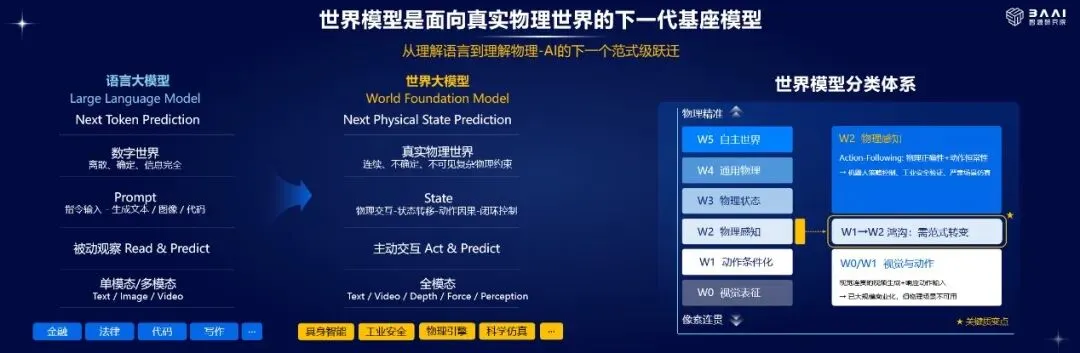
01 从“预测下一个词”到“预测下一个物理状态”
过去几年,大语言模型的核心能力可以简单理解为“预测下一个词”。你输入“今天天气很”,模型预测后面可能是“好”;你输入一段代码,它预测下一行代码;你提出一个问题,它预测最合适的回答。

这套方法推动了大模型的爆发,但它也有边界。语言只是世界的描述,不是世界本身。一个模型可以回答“苹果会从树上掉下来”,也可以生成一段杯子落地的视频,但这不代表它真正理解重力、碰撞、摩擦和因果关系。
智源认为,现有世界模型相关的技术路线可分为四类:
第一类是以语言为中心的世界模型,包括VLM、VLA,模型在文本空间中预测下一个词,学到的是语言描述的世界,并不能理解背后的物理后果;
第二类是以像素为中心的世界模型,像Sora和Seedance等视频生成类模型,在视觉空间中学习视频或图像,学到的是像素描述的世界;
第三类是以三维结构为中心的世界模型,包括3D重建以及李飞飞团队的World Labs Marble模型,不过模型重建3D空间不等于理解世界,几何结构也不代表物理状态;
第四类是以视觉表征为中心的世界模型,比如杨立昆的JEPA系列模型,预测的是视觉表征的压缩,但视觉嵌入演化不等于物理规律演化。
智源这次强调从预测下一个词,走向预测下一个物理状态,这个变化很关键。
因为AI如果只停留在屏幕里,语言和图像能力已经能解决很多问题;但一旦进入机器人、自动驾驶、工业制造、科学实验等真实场景,它就必须理解时间、空间、物体、动作和后果之间的关系。
另外,我们不能将世界模型简单地理解为视频生成模型。世界模型变热,很大程度上和视频生成模型有关。Sora、Seedance等模型出现后,很多人开始把“能生成逼真视频”直接等同于“拥有世界模型”。但这其实是一种误读。
视频生成模型确实能从大量视频中学到一些世界知识,但“画面连续”不等于“物理正确”。一个模型可以生成一群猪在天上和飞机一起飞,画面也许很真实,但这显然不符合现实物理规律。
当然,世界模型现在还处在早期阶段。行业还没有完全形成共识:它到底应该怎么训练、需要什么数据、如何评测、哪些能力才算真正理解世界。这也是智源此次发布Physis-v0.1的意义所在——试图把世界模型落到具体模型和技术路径上。
此前,悟界·Emu3和Emu3.5已经尝试把文本、图像、视频放在统一框架中,实现多模态理解和生成。到了这次大会,智源进一步推出正在研发中的悟界·Physis-v0.1,并将其定位为通用世界基座模型。
Physis的核心目标,就是围绕物理空间建模,预测下一个物理状态。它强调几个关键词:物理正确、动作因果可溯、长程一致、通用泛化。
这个状态的高级之处在于,它不能只是生成好看的画面,还要符合真实物理规律;它要知道某个结果是由哪个动作造成的;它不能只预测眼前一秒,还要能推演更长时间内的变化;它也不能只在见过的场景里有效,换个房间、换个物体、换个任务,也要尽量能用。
智源研究院还提到,Physis会把视频、深度RGB、3D点云、力触反馈等多种信息压缩到统一的物理状态空间里。这里的力触反馈,可以理解为机器人在接触、抓取、推动物体时感受到的力。人类理解世界不只靠眼睛,也靠手感和身体反馈。
AI如果要进入真实世界,也需要类似的多模态能力。
02 具身智能是世界模型最直接的应用方向
世界模型要落地,具身智能很可能是最重要的方向之一。
这次智源提到的悟界·RoboBrain Orca,就是以“预测下一个物理状态”为核心构建的具身大脑。所谓具身大脑,可以理解为机器人的“大脑系统”。它不只是识别图像,也不只是输出动作,而是要打通“认知—预测—行动”的链路。
对机器人来说,这一点尤其关键。聊天机器人说错一句话,影响还停留在信息层面;机器人在现实世界中做错一个动作,可能会打碎物品,甚至带来安全风险。因此,机器人不能只会“看见”,还要能理解自己所处的环境,预测动作后果,并根据反馈调整下一步行动。
当然,今天的世界模型还不能马上让机器人像人一样灵活。无论是悟界·Physis,还是悟界·RoboBrain Orca,都更像是一个早期但重要的方向信号。
它说明行业正在意识到:如果AI要真正走出屏幕,进入家庭、工厂、道路和实验室,世界模型大概率是绕不开的底层能力。
热闹之外,真正的难题还在后面,它接下来至少还要解决几道难题。
第一是数据。语言模型可以学习互联网文本,视频模型可以学习海量视频,但真实物理世界的数据更复杂。机器人交互数据、力触觉数据、连续状态变化数据,都不容易大规模获得。
第二是训练方法。到底该更多依赖真实数据,还是仿真数据?合成数据能用多少?仿真世界和真实世界之间的差距如何弥合?这些都还需要长期探索
第三是评测体系。过去很多评测更关注视频是否逼真,但世界模型真正要回答的是:能不能预测下一个物理状态?能不能理解动作后果?能不能在真实任务中稳定工作?
第四是安全。AI一旦进入物理世界,风险会更直接。它不仅要聪明,还必须可控、可信、可靠。
世界模型现在还远没有到“答案揭晓”的阶段,但它提出了一个足够重要的问题:AI的下一步,不能只是在屏幕里生成内容,而是要学会理解真实世界,并在真实世界中行动。
推荐阅读
