 夜雨聆风
夜雨聆风做法律文书脱敏这件事,我们一直在听用户的反馈。
最近被问到最多的几个问题是:
"文字遮完了,公章和身份证照片还在,能不能也一起识别掉?"
"敏感词被分页切断,识别错误或遗漏,能不能跨页补回来?"
"同一处标注冲突,每次都要手动比对挑一条,能不能一键解决?"
这些痛点从 v1.0.0、v1.1.0 一直被反馈到 v1.5.0,我们也一直在打磨。v1.6.0 版本,一次性把这几个高频问题全部补齐了。
下面是这次升级的核心内容。
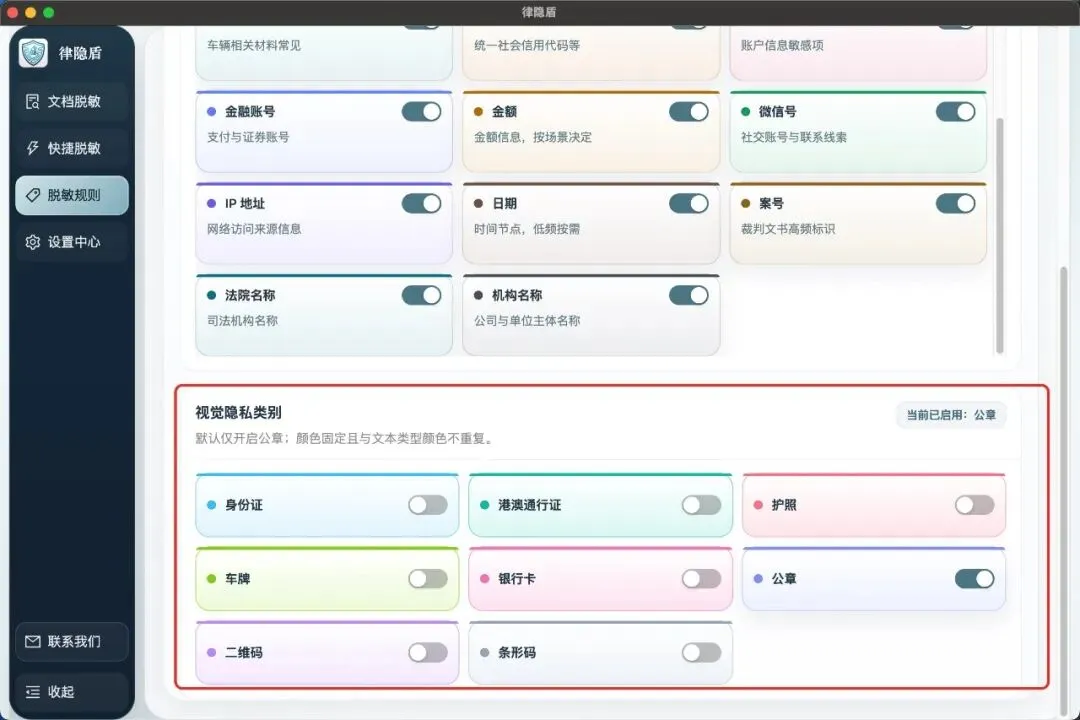
一、视觉识别上线:8 类视觉目标,图片/扫描件/PDF 全覆盖
法律文书里不只有文字,还经常出现身份证照片、护照扫描件、车牌、银行卡号、公章、二维码这些"图像形式的敏感信息"。文字模型识别不到,但客户看一眼就能拿到。
v1.6.0 引入了视觉隐私离线识别模型,图片、扫描型 PDF、文本型 PDF 都能自动识别以下 8 类视觉目标:
识别后以安全黑块方式参与预览和导出。
同时新增视觉隐私类别开关——可以按场景启停公章、证件、车牌等检测目标,灵活适配不同业务场景。

二、星号替换遮蔽样式:图片/扫描型 PDF 也能用星号脱敏
v1.5.0 之前,星号替换样式只支持文本页。v1.6.0起,图片和扫描型 PDF 也支持星号替换遮蔽,文本页和 OCR 页的导出风格可以保持统一。
这个能力对两类场景特别有用:
保留原版式语义:星号比黑块更"原汁原味",读者一眼就能看出这里是被脱敏的内容,而不至于误以为是排版错误;
喂给 AI 工具时上下文不丢:星号替换不会切断句子结构,后续给大模型做分析时仍然能理解上下文。
跨页补扫和倾斜文本区域,星号替换也能稳定导出。

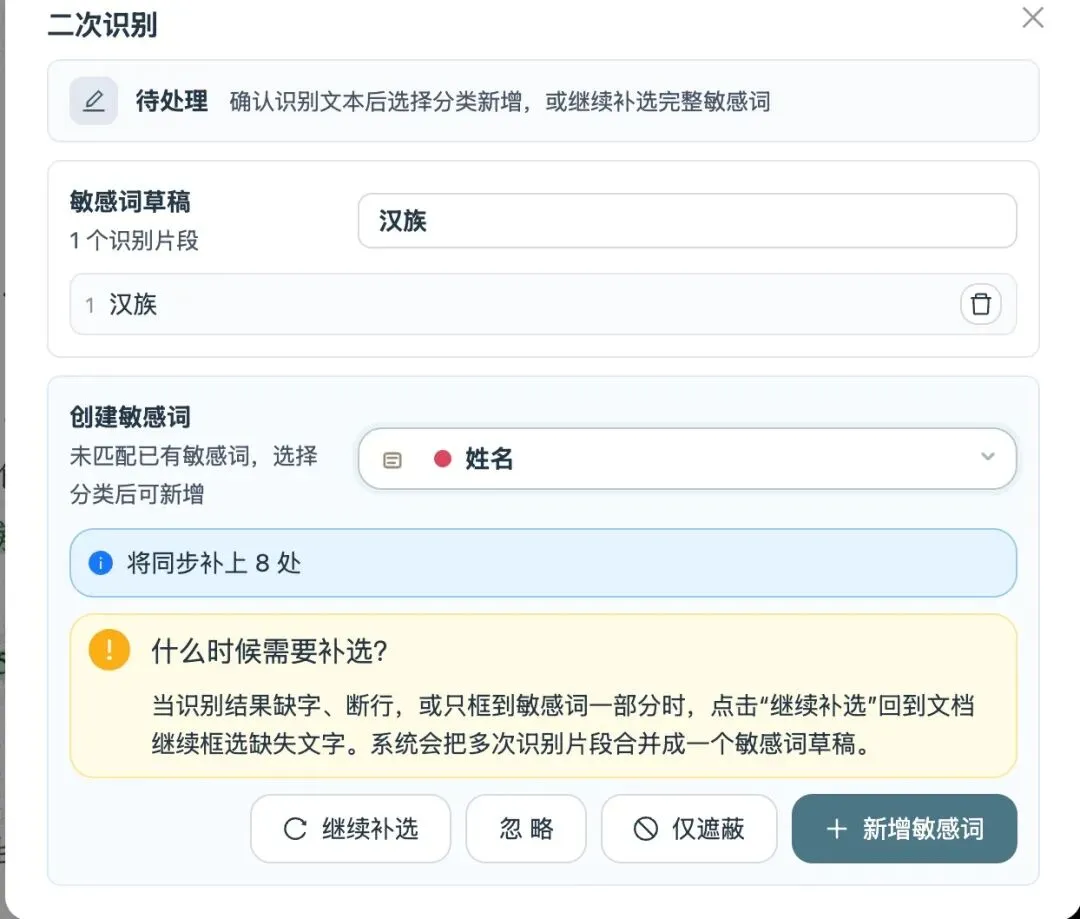
三、二次识别补漏:扫描件 OCR 漏识别的,框选就能补
扫描件质量不理想(歪斜、褶皱、模糊)的时候,OCR 不可避免会出现文字识别遗漏。
v1.6.0 新增"二次识别"入口:在扫描 PDF 的 OCR 页或图片上,框选一个局部区域,只对这个区域重新做 OCR 补标。
更省心的是——框选后会自动关联已有敏感词。如果你框选的内容刚好是已有敏感词的另一种写法或局部,系统会自动联动到对应分类,多数情况下不需要手动再选。
如果框选的内容在全文中还有其他同文位置,也能一键同步补标。
💡 小贴士:条件允许的话,建议先用全能扫描王这类工具扫描,避免歪斜和褶皱,能大幅减少 OCR 识别遗漏。
四、跨页补扫:分页切断的敏感词,自动跨页找回
法律文书里常见这种情况:一段地址、机构名跨页排版时被分页切断,切断后的两半单独识别,往往会识别错误或遗漏。
v1.6.0 在 PDF 检测中新增跨页边界增强阶段——对相邻页的页尾和页首组成语义窗口做二次检测,找回被分页切断的地址、机构名等敏感词,同时过滤页码、页眉页脚这类分页干扰。

五、标注冲突一键解决:重复/重叠标注自动处理
文档里的同一处敏感信息,可能被多个规则同时命中,产生重复标注或边界重叠的冲突。过去需要手动逐组比对,挑出保留哪一条。
v1.6.0 把标注冲突弹窗升级为处理入口:
完全重复或同类包含关系的文本标注,可直接按系统建议保留更合适的一条,并自动进入下一组
无法安全判断的冲突,仍然会引导定位做人工处理
整个流程不再需要逐条比对,重复标注处理省心很多。
六、Windows 离线安装与升级更稳
v1.6.0 把 Windows 离线资源改为组件化安装与保留策略,并修复了几个长期反馈的问题:中文路径识别,资源校验失败,启动后清理异常,发布校验问题,离线安装、升级补齐缺失资源、问题诊断的稳定性都进一步提升。
全程本机离线运行
需要再次强调的是——律隐盾的全部处理流程都在本机完成,不上传服务器,完全离线运行。
法律卷宗、客户隐私文件不会离开你的电脑。这是产品立项时就坚持的底线,v1.6.0 也是如此。
升级方式
已安装用户:打开应用,按提示一键升级即可
新用户:官网下载(https://lawsec.bugutech.cn)最新安装包,支持 macOS(arm64 / x64)和 Windows
关于律隐盾
律隐盾是一款面向法律行业的本地脱敏工具,三套 AI 模型协同:敏感词识别模型 + 视觉识别模型 + 上下文推理引擎,支持 PDF、扫描件、图片、Word 文档。本机离线运行,零数据上传。
