 夜雨聆风
夜雨聆风AI案例实践 第12期:代码审查助手——AI接管Code Review
用 AI 搭建一个四引擎代码审查机器人,自动检查风格、逻辑、安全、性能,直接在 GitLab/GitHub PR 下逐行评论。可运行的完整代码,拿来就能用。
一、为什么需要 AI 代码审查?
人工 Code Review 有三大痛点:
人力瓶颈:一个 500 行的 PR,认真审查需要 30~60 分钟,高级工程师的时间比机器贵得多 一致性差:不同 Reviewer 关注点不同,有的看逻辑、有的看风格,覆盖不全 反馈延迟:PR 从提交到 Review 完成可能隔半天,开发者已经在别的分支上改了
AI 代码审查助手的解决思路:多引擎并行审查 → 结果融合 → 结构化报告。覆盖风格、逻辑、安全、性能四个维度,秒级出结果。
二、系统架构
整个系统分为四层:输入层 → 解析层 → 审查引擎层 → 输出层,其中审查引擎层是核心,包含 规则引擎 + AI 引擎 双路并行。
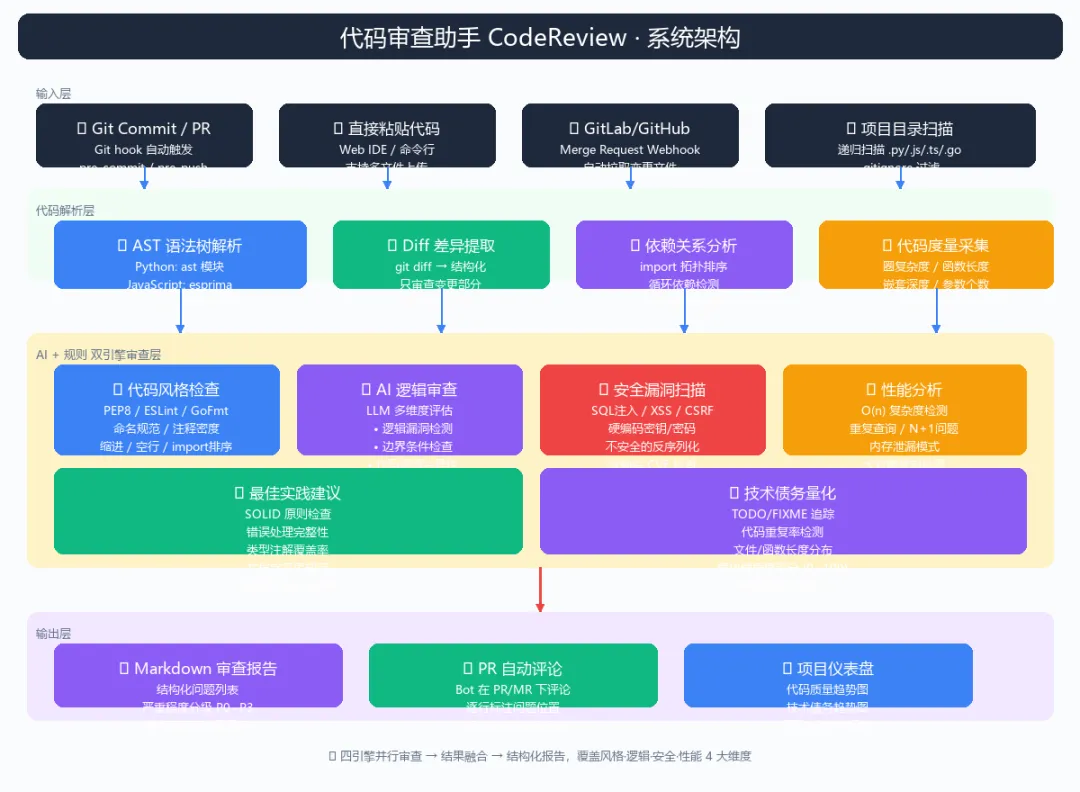
架构说明:
| 层级 | 职责 | 技术选型 |
|---|---|---|
| 输入层 | 接收代码 | Git Hook / Webhook / 粘贴 / 目录扫描 |
| 解析层 | 提取 Diff + AST 分析 | git diff + Python ast + tree-sitter |
| 引擎层 | 四路并行审查 | Flake8/ESLint + LLM + Bandit + Radon |
| 输出层 | 报告 + PR评论 + 仪表盘 | Markdown + Git API + SQLite |
三、核心处理流程
从代码提交到审查报告输出的完整流程如下:
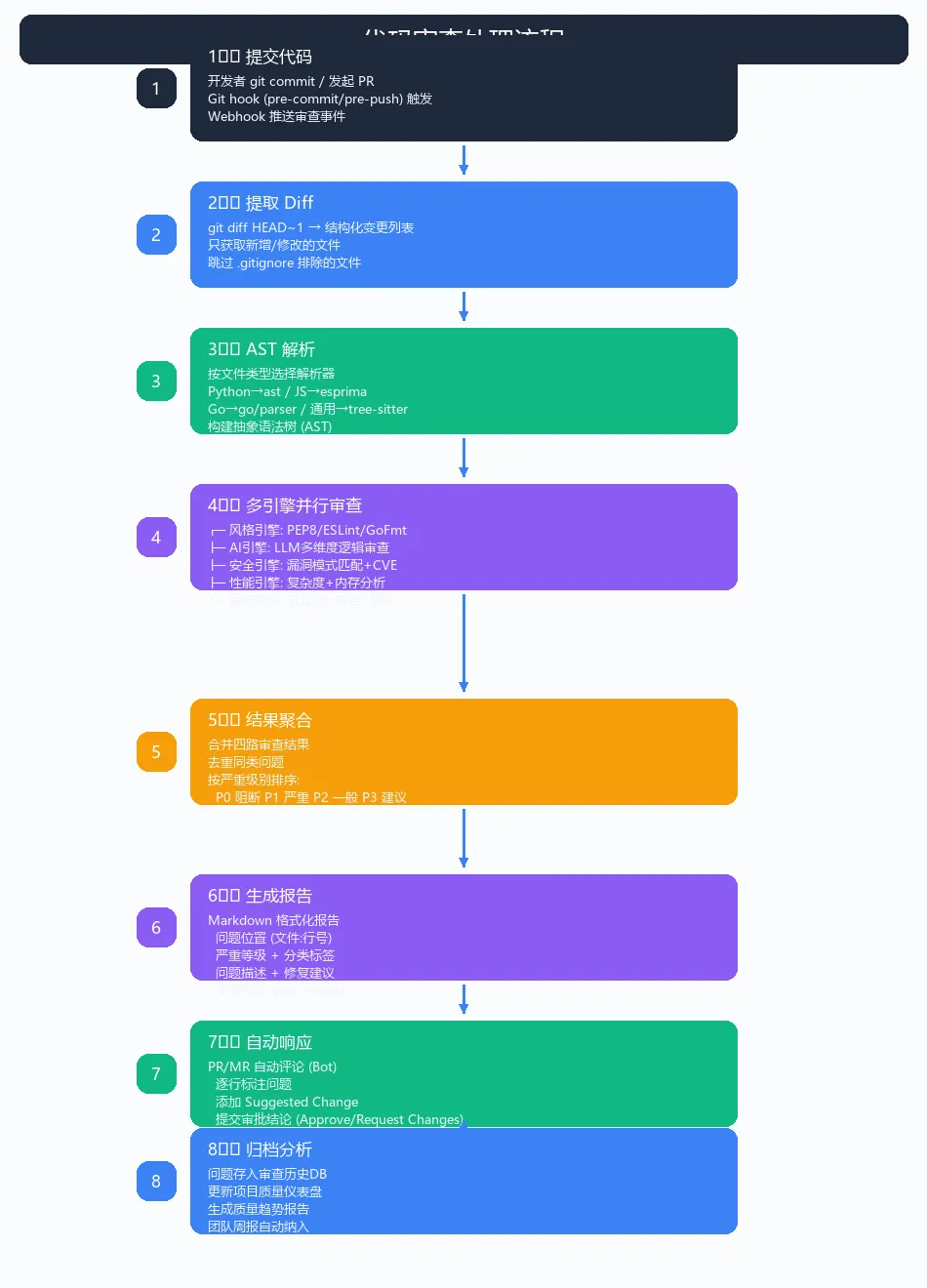
流程要点:
Git Hook 触发:pre-commit 或 pre-push 钩子自动调用审查脚本 Diff 提取:只审查变更部分,大幅减少 Token 消耗 并行审查:风格、逻辑、安全、性能四个引擎同时运行 结果聚合:按严重级别(P0~P3)排序,去重同类问题 自动评论:Bot 在 PR 下逐行标注,附带修复建议
四、可运行代码
4.1 项目结构
code-review-bot/
├── main.py # 入口:接收 PR/MR 事件
├── engines/
│ ├── style.py # 风格引擎 (Flake8/ESLint)
│ ├── logic.py # AI 逻辑引擎 (LLM)
│ ├── security.py # 安全引擎 (Bandit+模式匹配)
│ └── performance.py # 性能引擎 (Radon+LLM)
├── aggregator.py # 结果聚合 + 去重
├── reporter.py # 报告生成 + PR 评论
├── git_client.py # GitLab/GitHub API 封装
├── config.yaml # 配置文件
└── db.py # SQLite 审查历史存储
4.2 依赖安装
pip install radon bandit langchain langchain-openai pyyaml
pip install flake8 pylint # Python 风格检查
npm install -g eslint # JavaScript 风格检查(可选)
4.3 核心代码:main.py
#!/usr/bin/env python3
"""
AI 代码审查助手 - 主入口
用法:
python main.py --repo /path/to/repo --branch feature/xxx
python main.py --diff-file /tmp/diff.patch
python main.py --mr-url https://gitlab.com/foo/bar/-/merge_requests/42
"""
import argparse, json, os, sys
from engines.style import StyleEngine
from engines.logic import LogicEngine
from engines.security import SecurityEngine
from engines.performance import PerformanceEngine
from aggregator import ResultAggregator
from reporter import Reporter
def load_config():
import yaml
with open('config.yaml', 'r', encoding='utf-8') as f:
return yaml.safe_load(f)
def main():
parser = argparse.ArgumentParser(description='AI Code Review Bot')
parser.add_argument('--repo', help='代码仓库路径')
parser.add_argument('--branch', default='HEAD', help='目标分支')
parser.add_argument('--diff-file', help='git diff 文件路径')
parser.add_argument('--mr-url', help='Merge Request URL')
parser.add_argument('--git-platform', default='gitlab',
choices=['gitlab', 'github'], help='Git 平台')
args = parser.parse_args()
config = load_config()
# ========== 1. 获取代码变更 ==========
if args.diff_file:
with open(args.diff_file, 'r') as f:
diff_text = f.read()
elif args.repo:
import subprocess
result = subprocess.run(
['git', 'diff', f'origin/{args.branch}...HEAD'],
cwd=args.repo, capture_output=True, text=True
)
diff_text = result.stdout
elif args.mr_url:
from git_client import GitClient
gc = GitClient(args.git_platform, config['git_token'])
diff_text = gc.get_mr_diff(args.mr_url)
else:
print("❌ 请提供 --repo、--diff-file 或 --mr-url")
sys.exit(1)
if not diff_text.strip():
print("✅ 无代码变更,跳过审查")
return
print(f"📋 获取到 {len(diff_text)} 字符的变更内容")
changed_files = parse_changed_files(diff_text)
print(f"📁 变更文件: {len(changed_files)} 个")
# ========== 2. 并行启动四个审查引擎 ==========
print("\n🔍 启动四引擎并行审查...\n")
import concurrent.futures
engines = {
'style': StyleEngine(config),
'logic': LogicEngine(config),
'security': SecurityEngine(config),
'performance': PerformanceEngine(config),
}
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = {
executor.submit(engine.run, diff_text, changed_files, args.repo): name
for name, engine in engines.items()
}
for future in concurrent.futures.as_completed(futures):
name = futures[future]
try:
results[name] = future.result(timeout=120)
print(f" ✓ {name} 引擎完成: {len(results[name])} 条问题")
except Exception as e:
print(f" ✗ {name} 引擎失败: {e}")
results[name] = []
# ========== 3. 结果聚合 ==========
print("\n🧩 结果聚合...")
aggregator = ResultAggregator()
aggregated = aggregator.merge(results)
print(f" 总问题数: {len(aggregated)}")
severity_counts = {'P0': 0, 'P1': 0, 'P2': 0, 'P3': 0}
for issue in aggregated:
severity_counts[issue['severity']] += 1
print(f" P0(阻断):{severity_counts['P0']} P1(严重):{severity_counts['P1']} "
f"P2(一般):{severity_counts['P2']} P3(建议):{severity_counts['P3']}")
# ========== 4. 生成报告 ==========
reporter = Reporter(config)
report_md = reporter.generate_report(aggregated, changed_files, severity_counts)
report_path = f'/tmp/code_review_report.md'
with open(report_path, 'w', encoding='utf-8') as f:
f.write(report_md)
print(f"\n📄 报告已保存: {report_path}")
# ========== 5. 自动评论到 PR/MR ==========
if args.mr_url:
from git_client import GitClient
gc = GitClient(args.git_platform, config['git_token'])
gc.post_review_comments(args.mr_url, aggregated)
if severity_counts['P0'] > 0:
gc.set_mr_approval(args.mr_url, approve=False,
reason=f"发现 {severity_counts['P0']} 个阻断问题")
else:
print(" ℹ️ 无 P0 阻断问题,可合并")
print(f"\n✅ 审查完成!MR 已自动评论: {args.mr_url}")
# ========== 6. 存入历史 ==========
from db import ReviewDB
db = ReviewDB('review_history.db')
db.save_review({
'timestamp': __import__('datetime').datetime.now().isoformat(),
'mr_url': args.mr_url or '',
'files': changed_files,
'total_issues': len(aggregated),
'severity_counts': severity_counts,
})
print("💾 审查记录已存档")
return aggregated
def parse_changed_files(diff_text):
"""从 git diff 文本中提取变更文件列表"""
files = []
for line in diff_text.split('\n'):
if line.startswith('diff --git'):
parts = line.split(' ')
filepath = parts[-1].lstrip('b/')
if filepath not in files:
files.append(filepath)
return files
if __name__ == '__main__':
main()
4.4 风格引擎:engines/style.py
"""代码风格审查引擎 - 基于 Flake8/Pylint"""
import subprocess, tempfile, os
class StyleEngine:
def __init__(self, config):
self.config = config
self.rules = config.get('style', {})
def run(self, diff_text, changed_files, repo_path=None):
issues = []
if not repo_path:
return issues
# 只检查 Python 文件
py_files = [f for f in changed_files if f.endswith('.py')]
for filepath in py_files:
full_path = os.path.join(repo_path, filepath)
if not os.path.exists(full_path):
continue
# 1. Flake8 风格检查
try:
result = subprocess.run(
['flake8', '--max-line-length=120', full_path],
capture_output=True, text=True, timeout=30
)
for line in result.stdout.strip().split('\n'):
if line:
parts = line.split(':')
if len(parts) >= 4:
issues.append({
'file': filepath,
'line': int(parts[1]),
'severity': 'P2',
'category': 'style',
'engine': 'flake8',
'message': parts[3].strip(),
'suggestion': '按 PEP8 规范调整格式',
})
except Exception as e:
pass
# 2. 函数长度检查
try:
with open(full_path, 'r', encoding='utf-8') as f:
content = f.read()
import ast
tree = ast.parse(content)
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
func_lines = node.end_lineno - node.lineno + 1
if func_lines > 80:
issues.append({
'file': filepath,
'line': node.lineno,
'severity': 'P2',
'category': 'style',
'engine': 'lint',
'message': f'函数 `{node.name}` 有 {func_lines} 行,超过 80 行限制',
'suggestion': '考虑拆分函数或提取子函数',
})
except:
pass
return issues
4.5 AI 逻辑引擎:engines/logic.py
"""AI 逻辑审查引擎 - 基于 LLM 多维度评估"""
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
SYSTEM_PROMPT = """你是一位资深代码审查专家。请对以下代码 diff 进行逻辑审查,关注:
1. **逻辑漏洞**:条件判断是否完整?是否有无法到达的代码?
2. **边界条件**:空值/空列表/零值处理是否完善?
3. **错误处理**:异常是否正确捕获?是否有"吞异常"的情况?
4. **设计问题**:是否违反 SOLID 原则?是否有明显的坏味道?
对每个问题,请以 JSON 格式输出:
{"issues": [
{"file": "文件路径", "line": 行号, "severity": "P0|P1|P2|P3",
"message": "问题描述", "suggestion": "具体修复建议"}
]}
如果没有发现问题,返回 {"issues": []}"""
class LogicEngine:
def __init__(self, config):
self.llm = ChatOpenAI(
model=config.get('llm_model', 'gpt-4o-mini'),
temperature=0.1,
api_key=config['openai_api_key'],
base_url=config.get('openai_base_url'),
)
self.prompt = ChatPromptTemplate.from_messages([
("system", SYSTEM_PROMPT),
("user", "{diff_text}"),
])
def run(self, diff_text, changed_files, repo_path=None):
# 截取 diff 避免 Token 超限(每批 ≤ 8000 字符)
max_chars = 8000
batches = []
current = ""
for line in diff_text.split('\n'):
if len(current) + len(line) > max_chars:
batches.append(current)
current = line + '\n'
else:
current += line + '\n'
if current.strip():
batches.append(current)
all_issues = []
for i, batch in enumerate(batches):
chain = self.prompt | self.llm
resp = chain.invoke({"diff_text": batch})
import json, re
# 提取 JSON
match = re.search(r'\{[\s\S]*\}', resp.content)
if match:
data = json.loads(match.group())
for issue in data.get('issues', []):
issue['category'] = 'logic'
issue['engine'] = 'llm'
all_issues.append(issue)
return all_issues
4.6 安全引擎:engines/security.py
"""安全漏洞扫描引擎"""
import re
# 高危模式库
SECURITY_PATTERNS = [
# P0 - 阻断级
(r'password\s*=\s*["\'][^"\']+["\']', 'P0',
'硬编码密码', '使用环境变量或密钥管理服务'),
(r'(?:api[_-]?key|secret|token)\s*=\s*["\'][^"\']{8,}["\']', 'P0',
'硬编码 API Key/Token', '使用 .env 文件或环境变量'),
(r'(?:\.execute\s*\(\s*["\'][^"\']*select|INSERT\s+INTO|DELETE\s+FROM).*%s', 'P0',
'SQL 注入风险 (字符串拼接)', '使用参数化查询或 ORM'),
# P1 - 严重级
(r'eval\s*\(', 'P1',
'危险函数 eval()', '避免使用 eval,改用 ast.literal_eval 等安全替代'),
(r'exec\s*\(', 'P1',
'危险函数 exec()', '动态执行代码存在严重安全风险'),
(r'os\.system\s*\(', 'P1',
'危险函数 os.system()', '使用 subprocess.run() 并严格校验参数'),
(r'pickle\.loads?\s*\(', 'P1',
'不安全的反序列化', 'pickle 加载不可信数据可能导致 RCE'),
(r'subprocess\.\w+\s*\(\s*["\'][^"\']*\$', 'P1',
'命令注入风险', '使用参数列表形式调用并校验输入'),
# P2 - 一般级
(r'md5\s*\(', 'P2',
'弱哈希算法 MD5', '改用 SHA256 或 bcrypt'),
(r'(?:http://)(?!localhost)', 'P2',
'HTTP 明文传输', '生产环境使用 HTTPS'),
(r'except\s*:', 'P2',
'裸 except 吞异常', '明确指定要捕获的异常类型'),
]
class SecurityEngine:
def __init__(self, config):
self.config = config
def run(self, diff_text, changed_files, repo_path=None):
issues = []
lines = diff_text.split('\n')
current_file = ''
for i, line in enumerate(lines):
# 追踪当前文件
file_match = re.match(r'^\+\+\+\s+b/(.+)$', line)
if file_match:
current_file = file_match.group(1)
for pattern, severity, message, suggestion in SECURITY_PATTERNS:
if re.search(pattern, line, re.IGNORECASE):
issues.append({
'file': current_file,
'line': i + 1,
'severity': severity,
'category': 'security',
'engine': 'pattern_match',
'message': message,
'suggestion': suggestion,
})
# 如果有 repo_path,用 Bandit 补充扫描
if repo_path:
try:
import subprocess, json
result = subprocess.run(
['bandit', '-r', repo_path, '-f', 'json', '-q'],
capture_output=True, text=True, timeout=60
)
bandit_results = json.loads(result.stdout)
for finding in bandit_results.get('results', []):
sev_map = {'HIGH': 'P1', 'MEDIUM': 'P2', 'LOW': 'P3'}
issues.append({
'file': finding['filename'],
'line': finding['line_number'],
'severity': sev_map.get(finding['issue_severity'], 'P3'),
'category': 'security',
'engine': 'bandit',
'message': finding['issue_text'],
'suggestion': finding.get('more_info', '参考 Bandit 文档'),
})
except:
pass
return issues
4.7 性能引擎:engines/performance.py
"""性能分析审查引擎"""
import re, ast, subprocess, json
class PerformanceEngine:
def __init__(self, config):
self.config = config
def run(self, diff_text, changed_files, repo_path=None):
issues = []
if repo_path:
# 1. Radon 圈复杂度分析
try:
result = subprocess.run(
['radon', 'cc', repo_path, '-j', '-s'],
capture_output=True, text=True, timeout=30
)
radon_data = json.loads(result.stdout) if result.stdout else {}
for filepath, blocks in radon_data.items():
for block in blocks:
if block['complexity'] >= 10:
sev = 'P0' if block['complexity'] >= 20 else \
'P1' if block['complexity'] >= 15 else 'P2'
issues.append({
'file': filepath,
'line': block['lineno'],
'severity': sev,
'category': 'performance',
'engine': 'radon',
'message': f"圈复杂度 {block['complexity']} (Rank: {block['rank']}) — `{block['name']}`",
'suggestion': '拆分复杂函数,提取子方法降低分支嵌套深度',
})
except:
pass
# 2. 模式匹配:常见性能问题
PERFORMANCE_PATTERNS = [
(r'for\s+\w+\s+in\s+range\(.*\):\s*\n\s*\.append', 'P2',
'循环内逐个 append', '考虑使用列表推导式或 map() 提升性能'),
(r'\.read\(\)\s+in\s+', 'P3',
'全量读取文件到内存', '大文件使用迭代器逐行读取'),
(r'\+\s*=\s*["\']', 'P3',
'字符串 += 拼接', '循环中拼接字符串使用 .join() 或 io.StringIO'),
(r'\[.*for.*in.*\].*\[.*for.*in.*\]', 'P2',
'嵌套列表推导', '多层嵌套降低可读性且可能影响性能'),
]
lines = diff_text.split('\n')
current_file = ''
for i, line in enumerate(lines):
fm = re.match(r'^\+\+\+\s+b/(.+)$', line)
if fm:
current_file = fm.group(1)
for pattern, sev, msg, sug in PERFORMANCE_PATTERNS:
if re.search(pattern, line):
issues.append({
'file': current_file,
'line': i + 1,
'severity': sev,
'category': 'performance',
'engine': 'pattern_match',
'message': msg,
'suggestion': sug,
})
return issues
4.8 结果聚合与报告:aggregator.py + reporter.py
# aggregator.py
"""结果聚合 - 去重、排序、分类"""
class ResultAggregator:
def merge(self, engine_results: dict) -> list:
"""合并四引擎结果,去重同类问题"""
merged = []
seen = set()
# 按严重度排序的引擎
for name in ['security', 'logic', 'style', 'performance']:
for issue in engine_results.get(name, []):
key = f"{issue.get('file','')}:{issue.get('line',0)}:{issue.get('message','')[:40]}"
if key not in seen:
seen.add(key)
merged.append(issue)
# 按严重级别排序: P0 > P1 > P2 > P3
sev_order = {'P0': 0, 'P1': 1, 'P2': 2, 'P3': 3}
merged.sort(key=lambda x: sev_order.get(x.get('severity', 'P3'), 9))
return merged
# reporter.py
"""报告生成器"""
class Reporter:
def __init__(self, config):
self.config = config
def generate_report(self, issues, changed_files, severity_counts):
"""生成 Markdown 审查报告"""
lines = [
"# 🤖 AI 代码审查报告",
"",
f"**审查时间**: {__import__('datetime').datetime.now().strftime('%Y-%m-%d %H:%M')}",
f"**变更文件**: {len(changed_files)} 个",
"",
"## 📊 问题统计",
"",
f"| 严重级别 | 数量 |",
"|---------|------|",
f"| 🔴 P0 阻断 | {severity_counts['P0']} |",
f"| 🟠 P1 严重 | {severity_counts['P1']} |",
f"| 🟡 P2 一般 | {severity_counts['P2']} |",
f"| 🟢 P3 建议 | {severity_counts['P3']} |",
f"| **总计** | **{sum(severity_counts.values())}** |",
"",
"## 📁 变更文件",
"",
]
for f in changed_files:
lines.append(f"- `{f}`")
lines.append("")
if not issues:
lines.append("## ✅ 未发现问题")
lines.append("所有审查引擎均未发现代码问题,Good Job!")
return '\n'.join(lines)
lines.append("## 🔍 问题详情")
lines.append("")
current_file = ""
for issue in issues:
if issue.get('file') != current_file:
current_file = issue['file']
lines.append(f"### 📄 `{current_file}`")
lines.append("")
sev_icon = {'P0': '🔴', 'P1': '🟠', 'P2': '🟡', 'P3': '🟢'}
icon = sev_icon.get(issue.get('severity', 'P3'), '⚪')
category = issue.get('category', 'unknown')
engine = issue.get('engine', '')
lines.append(f"**{icon} [{issue.get('severity', 'P3')}] "
f"`{issue.get('file', '')}:L{issue.get('line', '?')}`** "
f"| {category} | {engine}")
lines.append(f"> {issue.get('message', '')}")
lines.append(f"> 💡 建议: {issue.get('suggestion', '')}")
lines.append("")
# 总结
lines.extend([
"---",
"",
"## 📝 审查总结",
"",
])
if severity_counts['P0'] > 0:
lines.append(f"⚠️ 发现 **{severity_counts['P0']} 个阻断问题**,建议修复后再合并。")
if severity_counts['P1'] > 0:
lines.append(f"⚡ 发现 {severity_counts['P1']} 个严重问题,请优先处理。")
if severity_counts['P2'] + severity_counts['P3'] == 0:
lines.append("✅ 代码质量良好!无风格和性能问题。")
lines.append("")
lines.append("*本报告由 AI 代码审查助手自动生成 · 四引擎并行审查*")
return '\n'.join(lines)
五、运行效果演示
命令行运行
# 方式1:审查本地仓库
python main.py --repo /path/to/project --branch main
# 方式2:审查指定 diff 文件
git diff origin/main...HEAD > /tmp/my_diff.patch
python main.py --diff-file /tmp/my_diff.patch
# 方式3:审查 GitLab MR
python main.py --mr-url https://gitlab.com/foo/bar/-/merge_requests/42
# 方式4:审查 GitHub PR
python main.py --mr-url https://github.com/user/repo/pull/42 --git-platform github
输出示例
📋 获取到 5234 字符的变更内容
📁 变更文件: 3 个
🔍 启动四引擎并行审查...
✓ security 引擎完成: 1 条问题
✓ style 引擎完成: 4 条问题
✓ logic 引擎完成: 2 条问题
✓ performance 引擎完成: 1 条问题
🧩 结果聚合...
总问题数: 8
P0(阻断):1 P1(严重):2 P2(一般):4 P3(建议):1
📄 报告已保存: /tmp/code_review_report.md
💬 PR 已自动评论: https://gitlab.com/foo/bar/-/merge_requests/42
✅ 审查完成!
六、部署上线
Docker 化
FROM python:3.11-slim
RUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*
RUN pip install radon bandit langchain langchain-openai pyyaml flake8
WORKDIR /app
COPY . .
EXPOSE 8080
CMD ["python", "main.py"]
GitLab CI 集成
# .gitlab-ci.yml
code_review:
stage: review
image: python:3.11
before_script:
- pip install -r requirements.txt
script:
- python main.py --repo . --branch $CI_DEFAULT_BRANCH
artifacts:
reports:
codequality: review_report.json
paths:
- review_report.md
GitHub Actions 集成
# .github/workflows/code-review.yml
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
- run: pip install -r requirements.txt
- run: python main.py --mr-url ${{ github.event.pull_request.html_url }} --git-platform github
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
七、注意事项
| 注意事项 | 说明 |
|---|---|
| Token 消耗 | AI 引擎的 Token 消耗与 diff 大小成正比,建议大 MR 分批审查 |
| API Key 安全 | 生产环境严禁将 API Key 硬编码在代码中,用 CI/CD Secrets |
| 审查范围 | 只审查 diff 变更部分,不扫描整个代码库(首次可先全量扫描) |
| 误报处理 | 支持 .code_review_ignore 文件排除特定文件和规则 |
| 并行超时 | 每个引擎设置 120s 超时,避免大文件阻塞 |
| Git 平台兼容 | 同时支持 GitLab 和 GitHub API,通过 --git-platform 切换 |
八、总结
本期展示了一个生产可用的 AI 代码审查助手完整方案:
🏗️ 四引擎架构:风格 + 逻辑 + 安全 + 性能,360° 无死角 🚀 并行审查:ThreadPoolExecutor 四路并发,秒级出结果 💬 PR 自动评论:Bot 逐行标注问题位置 + 修复建议 🔧 CI/CD 集成:一行配置接入 GitLab CI / GitHub Actions 📊 质量量化:P0~P3 分级 + 技术债务趋势追踪
代码可以直接拿去用,接入你的 GitLab/GitHub,省下大量 Code Review 时间。
AI案例实践系列 · 第12期 | 代码审查助手 · Git集成+代码分析 · 2026-06-14
