 夜雨聆风
夜雨聆风大家好我是老罗。
这个周末,微软 CEO Satya Nadella 在个人博客发了一篇长文,标题叫《A frontier without an ecosystem is not stable》——没有生态的前沿,是不稳定的。X 和朋友圈都刷屏了。
但老罗翻了翻中文圈的转发,大部分就是贴个链接、喊一句"纳德拉说得太对了"。没人告诉你,这篇东西对你这个每天和 AI 搏斗的程序员,到底意味着什么。
先把结论拍在前面。Nadella 这篇最狠的不是"AI 很重要"这种废话,而是三个反共识的判断:
第一,AI 时代真正的护城河,不是你用了多强的模型,是你能不能在模型之上搭一个"学习循环"。
第二,你的经验不但不会贬值,反而会随着你越用 AI 而越值钱。
第三,谁能搭起这个循环,谁就赢;搭不起来的,会被少数几家模型公司掏空。
这篇文章最烧脑的,是他造了一对新词——人力资本(human capital)和 Token 资本(token capital)。今天老罗带你把这套框架拆透,顺便聊一个更大的问题:微软明明是 OpenAI 最大的金主,CEO 凭什么公开唱衰"模型赢家通吃"?
01. 这次平台转变,跟以前都不一样
Nadella 开篇就撂下一句狠话:这次不一样。
过去每一次技术革命——PC、互联网、移动、云——本质都是"用数字系统增强人"。你买了电脑、连了网、上了云,你这个人变强了。
但 AI 这次不一样的地方在于:这是第一次,人和数字系统之间能形成一个真正的"认知循环"。 AI 不只是帮你干活,它会反过来吸收你和组织的经验,然后把它"商品化"——变成别人也能调用的能力。
这句话听着抽象,老罗给你翻译一下:
以前你是个资深工程师,脑子里的排障经验、架构直觉、踩坑清单,别人偷不走。现在你把这些东西写进 prompt、喂给模型、沉淀进知识库——模型学会了,下一个新人调一下就能用。 你花十年攒的东西,可能被模型一个下午"吃掉"。
这才是 Nadella 说的"利害攸关":不是某个工具好不好用,而是在 AI 能持续吸收并商品化人类经验的世界里,组织怎么继续学习、怎么保持差异化。
02. 两种资本:人力资本 vs Token 资本
Nadella 给出的答案,是他自己造的一个框架:
人力资本(human capital):知识、判断、关系、创造力、模式识别——也就是"人"脑子里那些东西。
Token 资本(token capital):企业自己构建并拥有的 AI 能力——你喂进去的数据、沉淀的 prompt、私有 eval、训练出来的专属模型。

看到这儿你可能慌了:Token 资本越强,人力资本不就被替代了吗?
Nadella 的反共识就在这里——他说恰恰相反:人力资本不但不会贬值,反而会随着 Token 资本的增长而更值钱。
为什么?因为 Token 资本的增长,是要靠人来驱动的。人去设定目标、跨领域连点成线、建立关系、识别真正重要的模式。 没有人指引方向,Nadella 的原话是——"compute running in circles",算力原地打转。
老罗深以为然。你看那些把 AI 用得最狠的团队,从来不是接上模型人就躺平了。恰恰是那些最懂业务的人,能把模糊需求翻译成精准 prompt,能把模型乱七八糟的输出纠正回来——这些"懂行的人",在 AI 时代反而更稀缺、更贵了。
03. 最值钱的一句:你能外包工作,但外包不了学习
整篇文章里,老罗最想划线的是这一句:
"You can offload a task, or even a job, but you can never offload your learning."
你可以外包一项任务,甚至一份工作,但永远不能外包你的学习。

这句话翻译成程序员的人话就是:
你可以让 AI 帮你写代码、改 bug、做测试,但你不能让 AI 替你"学会"怎么解决这类问题。 一旦你把"学习"这个动作也外包了——什么都让 AI 干,自己不思考、不复盘、不沉淀——那你的水平就永远停在"会用工具",而不是"解决问题"。而模型,恰恰最喜欢吃掉"只会用工具"的人。
Nadella 给的解法是:别想着挑最强的模型,要在模型之上搭一个"学习循环"——让人力资本和 Token 资本互相喂养、一起复利。
04. 换模型主权测试:你的"老兵经验"被锁死在哪了
这一段,老罗觉得是整篇文章对程序员最实用、最该截图保存的部分。
Nadella 提了一个非常具体的测试,他说这是 AI 时代企业"控制权和主权"的关键测试:
你应该能换掉"通用模型",而不丢失你学习系统里沉淀的"公司老兵"经验。

什么意思?今天很多团队的做法是:把所有东西都绑死在某一个模型上——prompt 为 GPT 调、工作流按 Claude 写、知识库针对某个模型优化。一旦这个模型涨价了、被封了、或者出了个更好的(这种事这两年还少吗?),你整个系统就得推倒重来。
Nadella 说的"健康"架构是这样:
• 私有 eval(评测):你得有一套自己的评测集,衡量"模型在我这个业务场景下到底有没有变好"——不是刷公开 benchmark,是测你真正在意的那个结果。 • 私有强化学习环境:让模型在你组织内部的真实数据上继续变强。 • 知识库:把你团队的机构记忆变成可查询的东西,让 token 用得更省、更准。
老罗给你翻译成一份"今天就能动手"的清单:
1. 别把 prompt 锁死在某个模型上。 写 prompt 时想着"这套东西换个模型还能不能用",而不是"怎么把 GPT 调到最优"。
2. 建一个你自己的 eval 集。 哪怕只有 20 条你业务里真实的 case,也比任何公开 benchmark 有用。
3. 把踩过的坑、架构决策、排障经验写进知识库 / CLAUDE.md。 这些是"老兵经验",模型可以换,但这层沉淀是你的。
做到了,你就拿到了 Nadella 说的"主权"——模型是可插拔的零件,经验是你不可替代的资产。
05. 学习循环 = 企业新 IP,而且会复利
把这个循环搭起来之后会发生什么?Nadella 打了个比方,老罗觉得特别准:
他把学习循环比作一台"爬山机(hill climbing machine)"。
它最大的特点是——会复利。你每改进一个工作流,就产生更好的训练信号;更好的信号让模型在你这儿更强;更强的模型让你愿意把更多活儿交给它;更多的活儿又产生更多信号……这是一个会自己越转越快的飞轮。
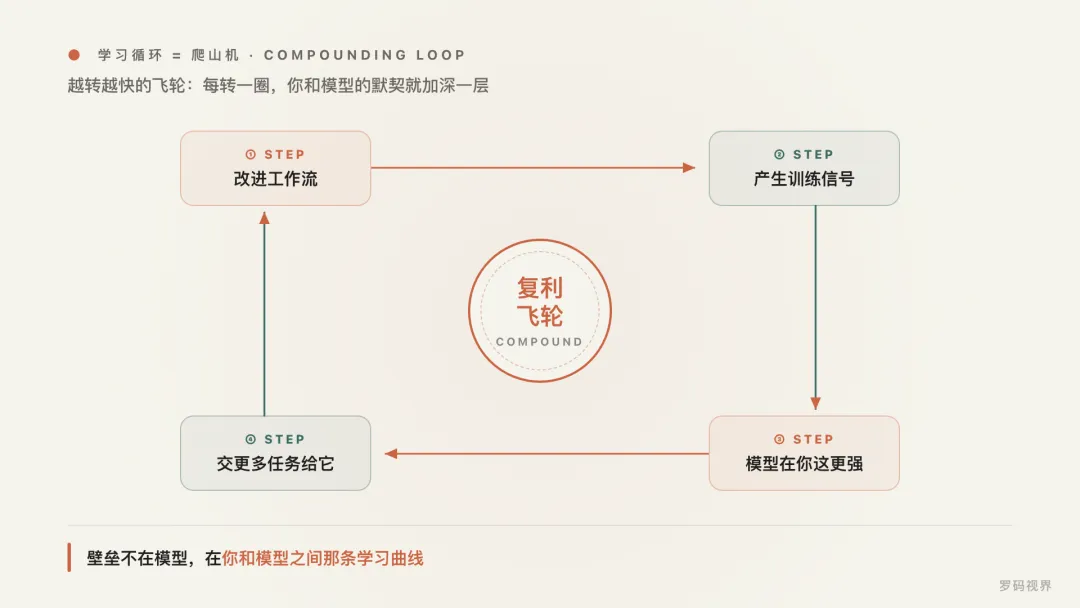
而且 Nadella 特别强调:这种优势一旦建起来,不管再来什么新模型、新能力,都动不了你。 因为你的壁垒不在模型本身,而在你和模型之间日积月累的那条"学习曲线"上。
这就是为什么老罗说,这篇不是鸡汤,是一份战略地图。 它在告诉你:别把精力全砸在"追最强模型"上——那是个无底洞,永远有更新的;要砸在"建学习循环"上——那才是会随时间增值的资产。
06. 老罗的判断:微软投了 OpenAI,CEO 凭什么唱"别让赢家通吃"
干货讲完了,老罗想跟你聊点文章背后的东西。
有没有觉得哪里怪?微软是 OpenAI 最大的投资方,OpenAI 又是目前最强的前沿模型公司之一。 按理说,Nadella 应该是"模型赢家通吃"的最大受益者才对。可他在文章里反反复复喊的是——
"别让所有价值被少数几个模型吞噬。""社会不会允许一个掏空整个产业的 AI 未来。"
一个既得利益者,为什么主动唱衰对自己有利的格局?
老罗的看法是:这恰恰说明,微软押注的根本不是"OpenAI 这个模型",而是"OpenAI 之上的整个生态"。
Nadella 全文反复用一个词——"前沿生态(frontier ecosystem)",而不是"前沿模型(frontier model)"。他要建的,是让每家企业、每个行业、每个国家都能拥有自己"学习循环"的那套基础设施(Azure、Copilot、Foundry 这些)。模型会换、会迭代,但承载学习循环的生态平台,才是他要占住的位子。
换句话说:微软不指望靠"一个最强模型"通吃,它指望靠"承载所有人学习循环的平台"通吃。 这是一种更稳、也更难被颠覆的霸权。
Nadella 还搬出"全球化"这个类比,老罗觉得很狠。他说:全球化第一阶段,整个工业经济被外包掏空——GDP 数字好看,但产业空心化的代价到现在还在还。他警告,别把这种动态带进 AI 时代,让少数 AI 系统攫取所有回报,整个行业的知识被商品化掏空。
这话,是说给政府、给社会,也给每一个从业者听的。你品,你细品。
总结:先建你自己的那条学习曲线
回到对你最有用的层面。Nadella 这篇,老罗帮你压成一句话:
模型会换,能力会过期,但你和 AI 之间日积月累的那条"学习曲线",是唯一会复利的资产。
所以别再纠结"用 Claude 还是 GPT""追不追最新模型"了。从今天起,花点心思做三件事:写一套自己的 eval、把经验沉淀进知识库、让 prompt 别锁死在某个模型上。 这就是在搭你自己的学习循环。
2026 年,能搭起学习循环的程序员,和只会换最强模型的程序员,差距会越来越大。
你现在的"老兵经验",是沉淀下来了,还是全装在脑子里、换个工作就归零?
评论区告诉我,说不定下一篇老罗就教你,怎么把这些经验搭成一个能复利的学习循环。
关于作者:
我是老罗,AI 博主,长期深度使用 Claude Code / Codex / Cursor / MCP 做真实项目。关注「罗码视界」,继续拆 AI 圈里值得想明白的事:哪些趋势是真机会,哪些是噪音,哪些坑你得自己蹚一遍才懂。
