夜雨聆风
夜雨聆风摘要:手把手把 ccusage 成本和 GitHub PR 按"人×时间窗"JOIN,跑出 cost_per_pr、revert_rate、cache_hit_rate 报表,并设置人工核对闸门。

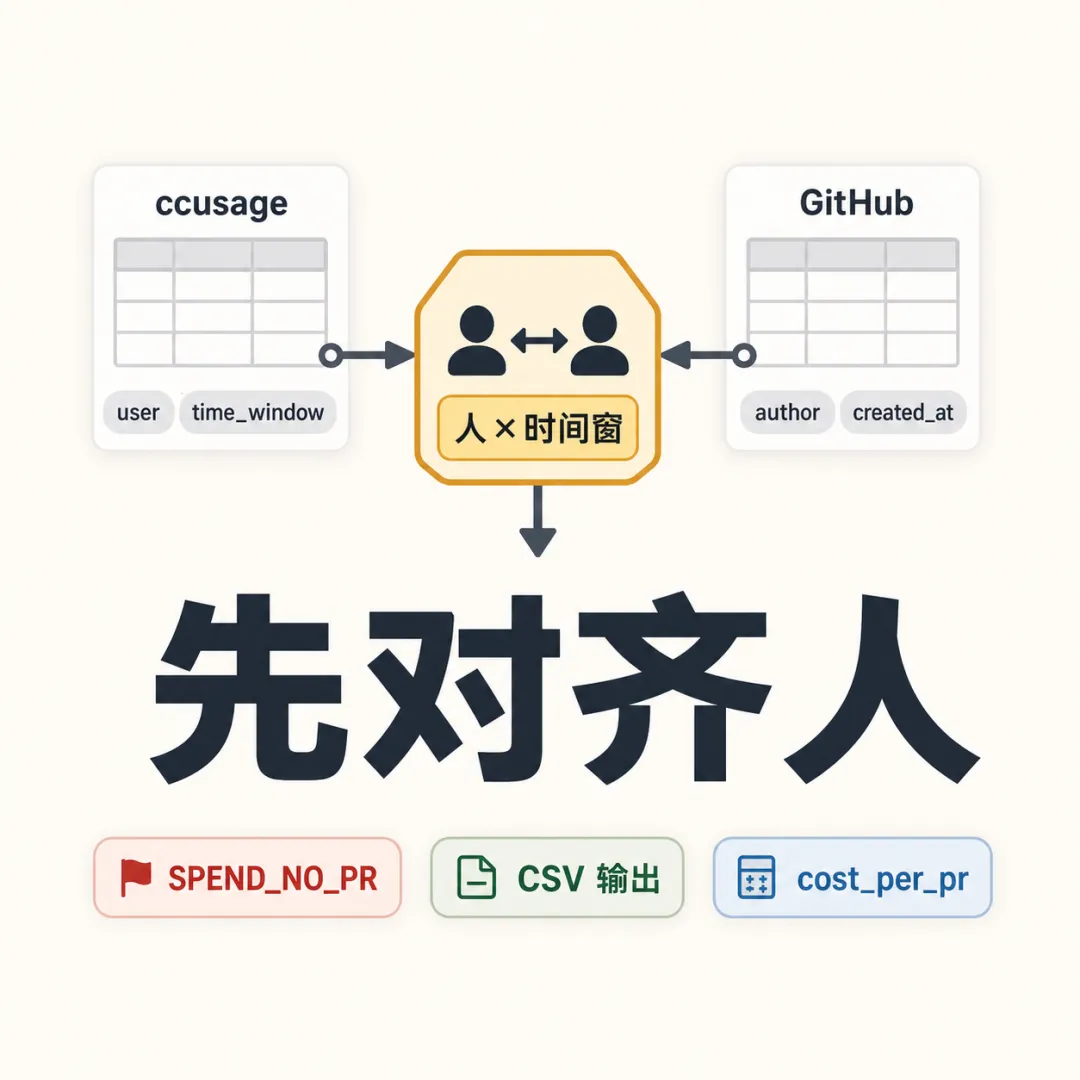
你已经有 ccusage 的 token 和美元,也有 GitHub 的 PR。
问题是:这两张表天然不在一起。
ccusage 像电表,只知道谁花了多少 token、多少美元、Cache 读写了多少;GitHub 像产出表,只知道谁合了多少 PR、有没有被回退。只看电表,"用得多"和"用得值"永远分不清。
这篇只做一件事:把两张表按同一个人、同一段时间拼起来,得到每人一行的 AI 效能报表。
没看过前两篇也能直接上手。只想跑通的,直接看「分步照做」;想以后迁移到 issue、commit、CI 质量指标的,从「先拆清楚再动手」开始读。
先看成品:最后是一张每人一行的表
脚本会输出 CSV,控制台也会打印一份表。核心列长这样:
| 人 | 成本 | PR | 关键判断 |
|---|---|---|---|
| alice | 18.50 | 11 | 便宜、稳定、Cache 高 |
| bob | 27.30 | 3 | 贵、回退高、Opus 占比高 |
| carol | 6.40 | 0 | 需人工核对 |
另一组列负责解释原因:
| 指标 | 公式口径 | 用来看 |
|---|---|---|
| cost_per_pr | cost ÷ merged_prs | 每个合入 PR 烧多少钱 |
| revert_rate | reverted_prs ÷ merged_prs | 质量刹车 |
| cache_hit_rate | cache_read ÷ (cache_read + cache_create + input) | 上下文复用 |
| opus_cost_share | cost_opus ÷ cost | 模型匹配是否过重 |
SPEND_NO_PR 不是"摸鱼"标签,只是"这行需要人看"。可能是身份没对齐,也可能这个人这段时间做的是调研、救火、设计文档,本来就不会产出 PR。
完整脚本和示例数据在本系列附带的 .context/ai-usage-metrics/ 目录里。本文不改脚本和公式,只教你怎么跑、怎么核。
先拆清楚再动手
这件事不要一上来就找脚本。先把手工流程拆成五步:
- 1. 收 ccusage 数据:读电表。
- 2. 对齐身份:把 ccusage 文件名、GitHub 登录名、邮箱归到同一个人。
- 3. 取 GitHub PR:读产出表。
- 4. JOIN 算指标:按"人×时间窗"拼两边。
- 5. 人工核对:先查异常,再谨慎使用。
这套拆法才是可迁移的部分。以后你把 PR 换成 closed issue,把 ccusage 换成 Cursor 或 Copilot 的用量导出,骨架仍然是:收数据 -> 对齐身份 -> 取产出 -> JOIN -> 人工核对。
其中最容易翻车的是第 2 步。alice-laptop、alice@corp.com、alice-gh 对人来说是一回事,对脚本来说是三个人。身份没对齐,成本和 PR 就会落到不同行,后面的 cost_per_pr 全是错账。
一次性准备
你需要三样东西:
- • Node:用
npx ccusage,不用全局安装。 - • Python 3.8+:跑 JOIN 脚本。脚本只用标准库。
- • GitHub 读权限:在线模式需要
GITHUB_TOKEN;离线模式可以直接喂prs.json。
先确认环境:
npx ccusage --version
python3 --version
echo "$GITHUB_TOKEN" # 离线模式可跳过你应该看到 ccusage 版本号、Python 版本号;在线模式下 GITHUB_TOKEN 不是空字符串。
分步照做
第1步:每人导出 ccusage
做什么:把每个人的 AI 用量导成 JSON,收进同一个目录。
怎么做:
mkdir -p ccusage
npx ccusage daily --json > ccusage/alice.json
# bob、carol 各自在自己机器上跑,把 json 收进同一个 ccusage/ 目录你会看到什么:ccusage/ 下每人一个 <名字>.json。打开文件能看到按天拆的 inputTokens、outputTokens、cacheCreationTokens、cacheReadTokens、totalTokens、totalCost,以及 modelBreakdowns。
【为什么是这步】这是在读电表。文件名就是 ccusage 侧的身份,下一步要拿它和 GitHub 身份对齐。
第2步:建 identity.json,这是命门
做什么:把同一个人的所有别名归到一个规范名。
怎么做:
{
"alice-laptop": "alice",
"alice@corp.com": "alice",
"alice-gh": "alice",
"bob-mac": "bob",
"bob-gh": "bob"
}左边写所有可能出现过的名字,右边写最终报表里要显示的名字。没写进表的名字,脚本会默认它自己就是规范名。
你会看到什么:这步本身没有输出。等第 4 步跑完,如果你还看到 alice-laptop 和 alice-gh 分成两行,就说明映射漏了。
【为什么是这步】脚本里身份归一的核心很简单:
def canon(name, idmap):
return idmap.get(name, name)ccusage 文件名和 PR 作者都先过 canon,再聚合。只有两边用同一个规范名,成本和 PR 才能 JOIN 到同一行。
第3步:准备 GitHub PR
做什么:拿到这段时间内已合入的 PR。
在线模式:第 4 步脚本会自己通过 GitHub Search API 拉,查询口径是:
repo:org/repo is:pr is:merged merged:since..until离线模式:准备一个 prs.json:
[
{"number": 101, "title": "Add login throttle",
"body": "...", "author": "alice-gh", "merged": "2026-05-12"},
{"number": 102, "title": "Revert \"Add login throttle\"",
"body": "This reverts #101", "author": "bob-gh", "merged": "2026-05-20"}
]你会看到什么:在线模式需要 token 有仓库读权限;离线模式里每条 PR 至少要有 number/title/body/author/merged 五个字段。
【为什么是这步】这是在读产出表。注意 merged:since..until 的边界,GitHub Search 会把 until 当天也算进去,月初月末排查时要记住。
第4步:跑脚本,JOIN 出表
做什么:把电表、身份表、产出表喂给脚本。
在线模式:
export GITHUB_TOKEN=ghp_xxx
python3 team_ai_metrics.py \
--ccusage-dir ./ccusage/ \
--identity identity.json \
--repo your-org/your-repo \
--since 2026-05-01 --until 2026-06-01 \
--by month \
--out report.csv离线模式:把 --repo/--since/--until 换成 --prs prs.json,其余不变。
你会看到什么:控制台打印表格,同时写出 report.csv。CSV 带 BOM,Excel 双击也能打开。
【为什么是这步】脚本做的是同一个 JOIN:
keys = set(acc) | set(pr_count)
for key in sorted(keys):
cost = acc.get(key, {})["cost"]
merged = pr_count.get(key, 0)
cost_per_pr = (cost / merged) if merged else Nonekey 是 (规范名, 时间窗)。身份没对齐,key 就对不上;时间窗切错,分子分母也会错位。
第5步:读表,但别急着下结论
核心读法很直接:
- •
cost_per_pr高:先看是不是 PR 少、跨窗,还是模型用重了。 - •
revert_rate高:说明质量层在踩刹车,不能只夸"产出多"。 - •
cache_hit_rate低:可能会话切太碎,复用差。 - •
opus_cost_share接近 1:可能简单任务也全程压 Opus。 - •
SPEND_NO_PR:先人工核对,不是直接评价人。
到这里,表已经跑通,但真正重要的是下一道闸门。
用它对人下任何判断前,先过确认闸门
这张表不是绩效排名,也不是给个人打分的尺子。它只适合当雷达:发现谁可能卡住了、哪里需要帮助、哪类习惯可能导致成本异常。
在拿结果和任何人讨论之前,强制过四问:
- 1. 身份对齐了吗?
SPEND_NO_PR可能只是 git 登录名漏进了identity.json。 - 2. revert 漏判了吗? 脚本靠标题和正文启发式识别回退,标题不规范就会漏。
- 3. 时间窗错位了吗? token 在月初,PR 在月末,按月切时容易出现假异常。
- 4. 这个人是不是在做非 PR 工作? 调研、设计、救火、帮新人搭环境都会花 token,但不一定出 PR。
四问没过,结论不许用。AI 会错,指标会骗你,脚本输出也要人审过才算数。
下面是整条流程。注意右路的人工核对闸门:没过就回去修身份或时间窗,而不是直接拿表说人。
跑通后长什么样
示例数据跑完,控制台大致是这样:
person window cost_usd merged_prs cost_per_pr revert_rate cache_hit_rate opus_cost_share flag
------------------------------------------------------------------------------------------------------
alice 2026-05 18.5 11 1.68 0.0 0.85 0.61
bob 2026-05 27.3 3 9.1 0.5 0.32 1.0
carol 2026-05 6.4 0 - - 0.71 0.55 SPEND_NO_PR这就算跑通:每个人有成本、有产出、有质量刹车、有习惯信号,异常行被标出来,等你人工核对。
读法也要克制。alice 看起来便宜、稳、复用高;bob 贵、回退高、Opus 占比高,可能需要一起看任务类型和模型选择;carol 只是需要核对,不能直接贴标签。
完整成果对照
跑完以后,你手里至少应该有三样东西:
- •
ccusage/:每个人一个 JSON,文件名能对应到身份映射。 - •
identity.json:别名到规范名的映射,所有会出现在 ccusage 和 GitHub 里的名字都能查到。 - •
report.csv:最终报表,每行是一个人一个时间窗,包含成本、PR、质量和习惯信号。
验收时不要只看有没有 CSV。真正的完成标准是:随机抽一两个人,能从 report.csv 反查到他的 ccusage 文件、GitHub PR、身份映射;看到异常 flag 时,也知道应该先查身份、时间窗、回退漏判和非 PR 工作,而不是直接下判断。
FAQ:最常见的四个坑
Q1:同一个人裂成好几行。
症状:alice-laptop 和 alice-gh 各占一行。
原因:身份映射漏了。
怎么办:补 identity.json,把 ccusage 文件名、GitHub 登录名、邮箱都映射到同一个规范名,重跑。
Q2:满屏 SPEND_NO_PR。
症状:很多人都被标"花了钱没 PR"。
原因:常见是时间窗没对齐,或者 merged: 闭区间把 until 当天多算了一天。
怎么办:核对 --since/--until 和 ccusage 天数范围;必要时用 --by week 切细,再逐个人工确认是否存在非 PR 工作。
Q3:明明有回退,revert_rate 却是 0。
症状:你知道某个 PR 被撤了,表里没体现。
原因:回退识别是启发式:标题以 Revert 开头,或正文含 Reverts #N / This reverts,再把回退归到原 PR 作者。标题乱写就会漏判。
怎么办:统一团队 revert 标题;要更准,就接 CI、缺陷或发布事故数据补质量层。
Q4:某人 cost_per_pr 高得吓人。
症状:成本明显高于同伴。
原因:可能 PR 少、跨窗,也可能 opus_cost_share 接近 1,简单活也用了重模型。
怎么办:先过确认闸门,再和本人一起看任务类型、会话习惯、模型选择。它是帮助信号,不是定罪证据。
举一反三:把这套方法迁到别处
这篇真正要带走的,不是 cost_per_pr 这一列,而是这个骨架:
把"分子(花了多少)÷ 分母(产出多少)"按"人×时间窗"拼起来,再配一个质量信号踩刹车。
你可以换三个零件:
- • 换分母:PR 换成 closed issue、story point、commit、review 通过数。
- • 换电表:ccusage 换成 Cursor、Copilot 或内部代理的用量导出,只要能归一成"人×时间×成本"。
- • 换质量刹车:revert_rate 换成 CI 失败率、线上缺陷、静态告警增量、复杂度增量。
比如你要算"每个 closed issue 的 token 成本",拆法仍然一样:
- 1. 分子:每人每周 AI 成本。
- 2. 分母:每人每周 closed issue 数。
- 3. JOIN key:规范名 + 周。
- 4. 质量刹车:issue reopen 率或线上缺陷数。
- 5. 人工闸门:确认 issue 指派、跨周关闭、非编码工作有没有造成错账。
能自己说清这五项,就说明你学到的是方法,而不只是抄了一条命令。
表跑出来之后,真正危险的是怎么用
到这里,你已经能把 ccusage 和 GitHub 拼成一份可核对的报表。
但底线要再说一次:不要把它做成个人 KPI、排行榜、绩效证据。
一旦这么用,人会立刻优化指标:拆小 PR 抬高分母,避开难题降低回退率,把本该探索的活伪装成更好看的数字。指标会失效,团队也会更保守。
正确用法是找帮助点:谁可能身份没对齐、谁可能模型用重了、谁可能 Cache 复用差、谁可能在做不出 PR 的工作但被表误伤。
下一篇继续讲这条管理红线:AI 效能度量到底怎么用,才不会把团队带进"刷指标"的坑。
完整脚本和示例数据在 .context/ai-usage-metrics/。使用前只改输入数据和身份映射,不要把脚本输出当成免审判决。